 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Space-Efficient Representation of Entity-centric Query Language Models
Jun 29, 2022
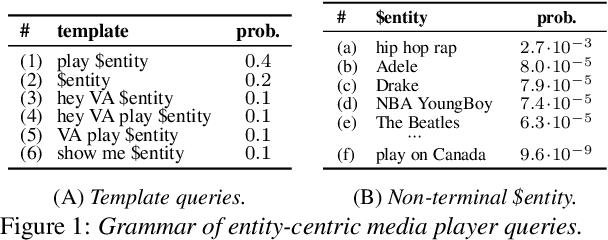

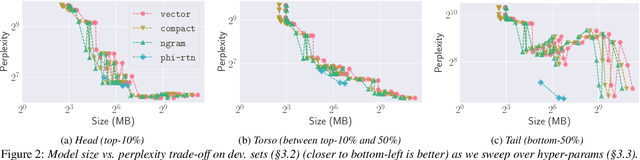
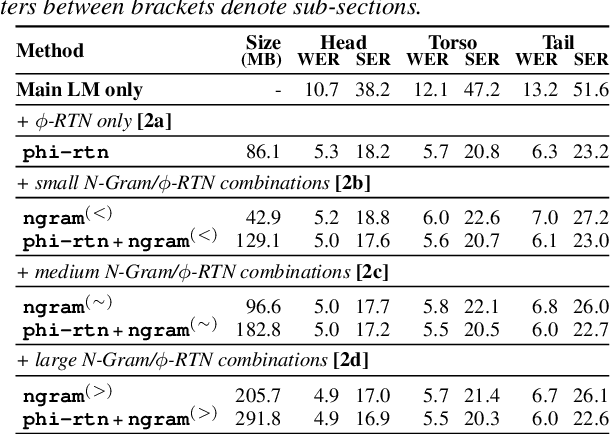
Virtual assistants make use of automatic speech recognition (ASR) to help users answer entity-centric queries. However, spoken entity recognition is a difficult problem, due to the large number of frequently-changing named entities. In addition, resources available for recognition are constrained when ASR is performed on-device. In this work, we investigate the use of probabilistic grammars as language models within the finite-state transducer (FST) framework. We introduce a deterministic approximation to probabilistic grammars that avoids the explicit expansion of non-terminals at model creation time, integrates directly with the FST framework, and is complementary to n-gram models. We obtain a 10% relative word error rate improvement on long tail entity queries compared to when a similarly-sized n-gram model is used without our method.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jun 05, 2019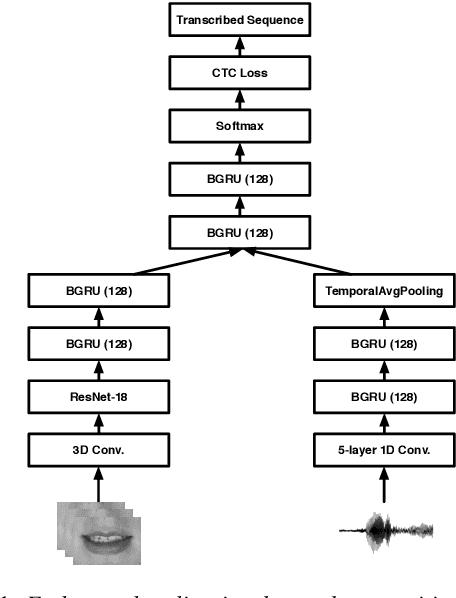

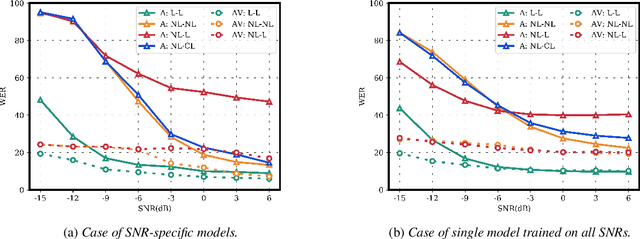
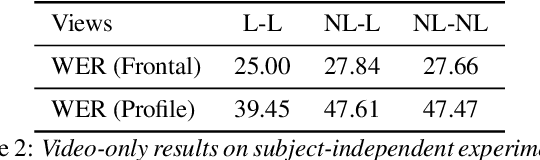
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the present of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.
Multilingual Speech Recognition with Corpus Relatedness Sampling
Aug 02, 2019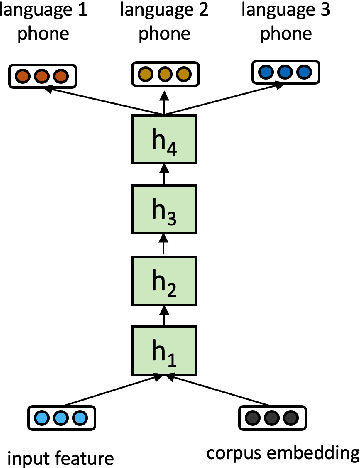
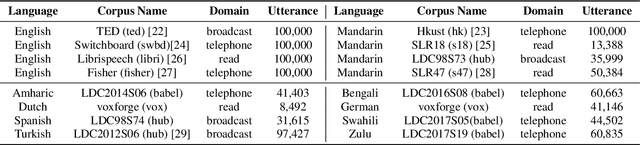
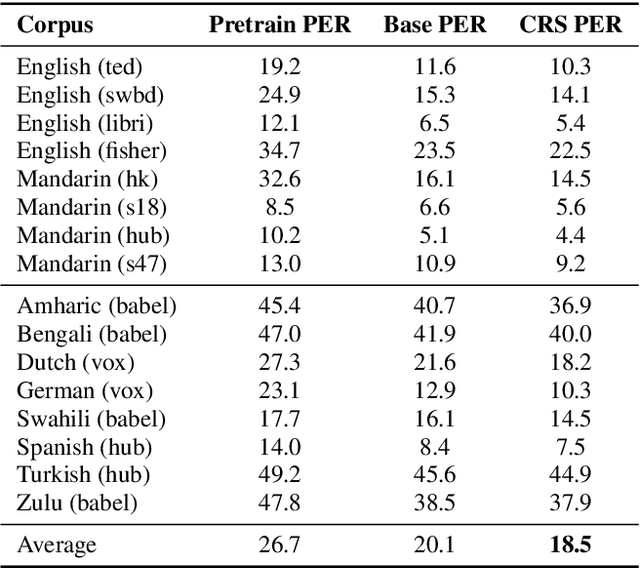
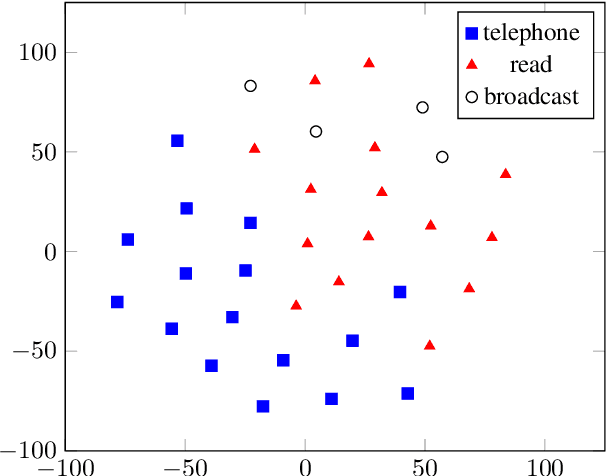
Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.
Resource aware design of a deep convolutional-recurrent neural network for speech recognition through audio-visual sensor fusion
Mar 13, 2018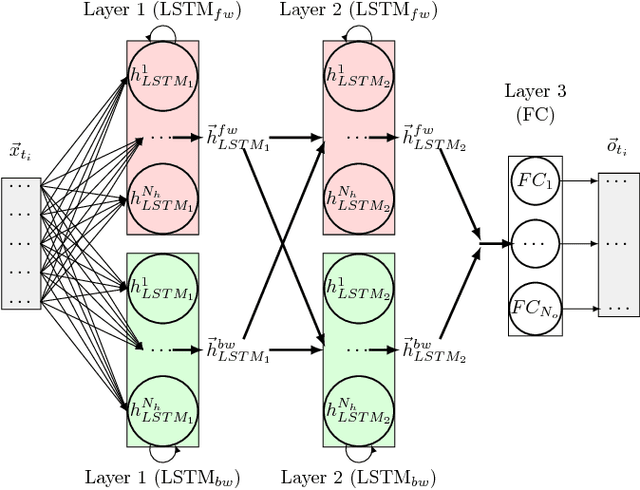
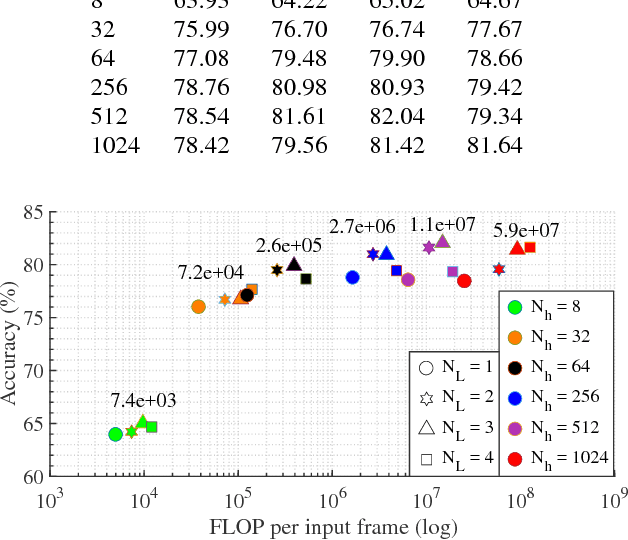
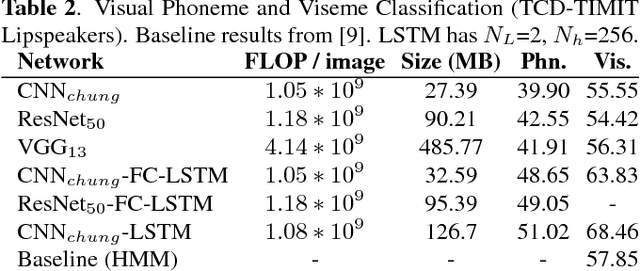
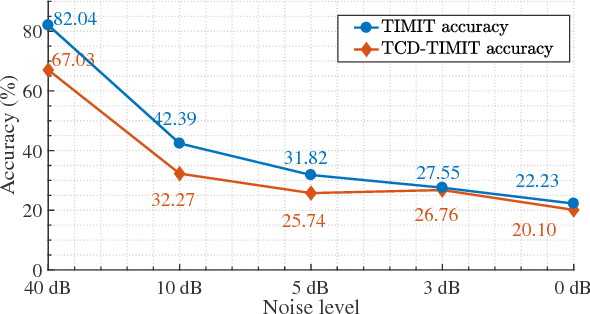
Today's Automatic Speech Recognition systems only rely on acoustic signals and often don't perform well under noisy conditions. Performing multi-modal speech recognition - processing acoustic speech signals and lip-reading video simultaneously - significantly enhances the performance of such systems, especially in noisy environments. This work presents the design of such an audio-visual system for Automated Speech Recognition, taking memory and computation requirements into account. First, a Long-Short-Term-Memory neural network for acoustic speech recognition is designed. Second, Convolutional Neural Networks are used to model lip-reading features. These are combined with an LSTM network to model temporal dependencies and perform automatic lip-reading on video. Finally, acoustic-speech and visual lip-reading networks are combined to process acoustic and visual features simultaneously. An attention mechanism ensures performance of the model in noisy environments. This system is evaluated on the TCD-TIMIT 'lipspeaker' dataset for audio-visual phoneme recognition with clean audio and with additive white noise at an SNR of 0dB. It achieves 75.70% and 58.55% phoneme accuracy respectively, over 14 percentage points better than the state-of-the-art for all noise levels.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022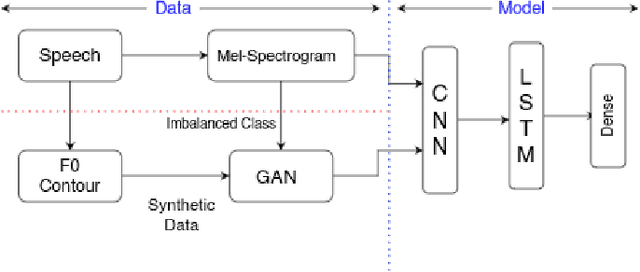
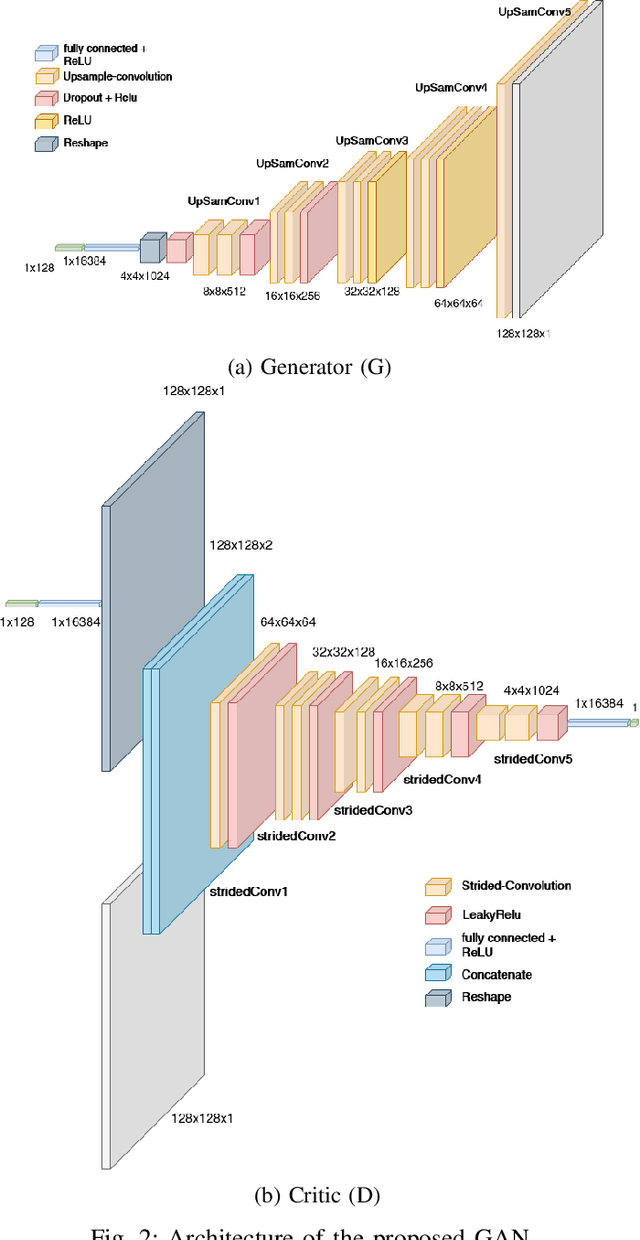
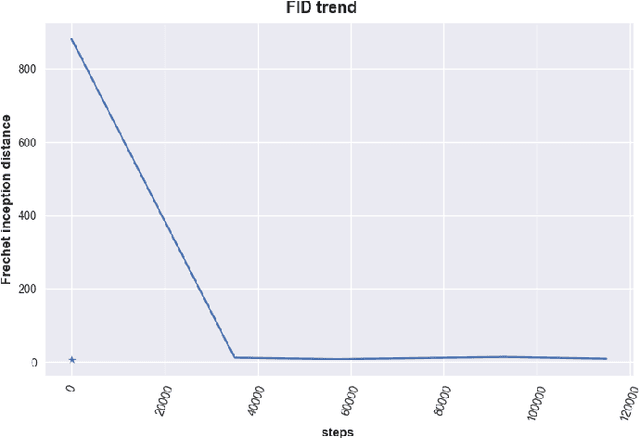
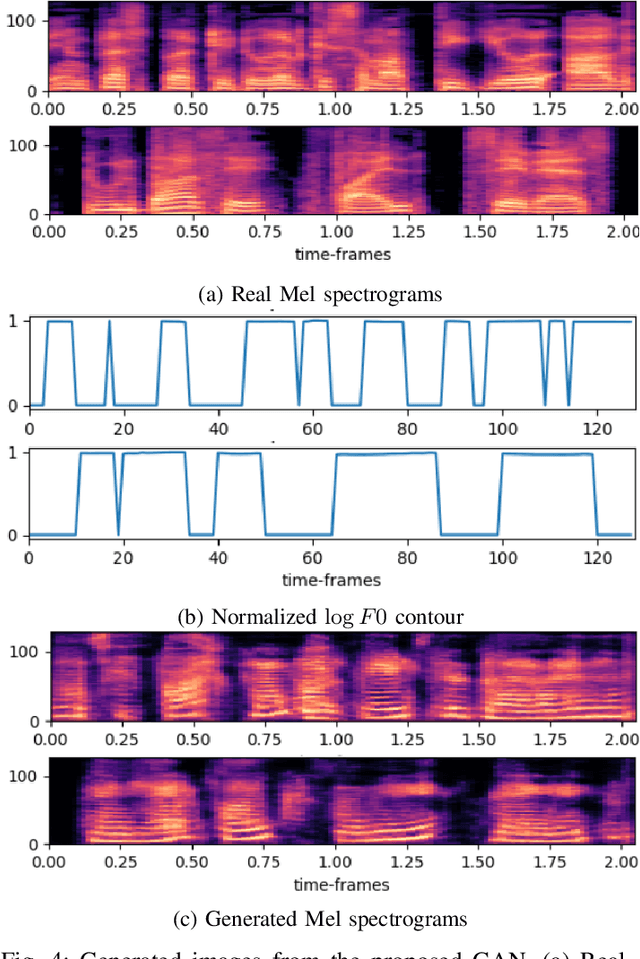
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
Transfer Learning from Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations
May 08, 2018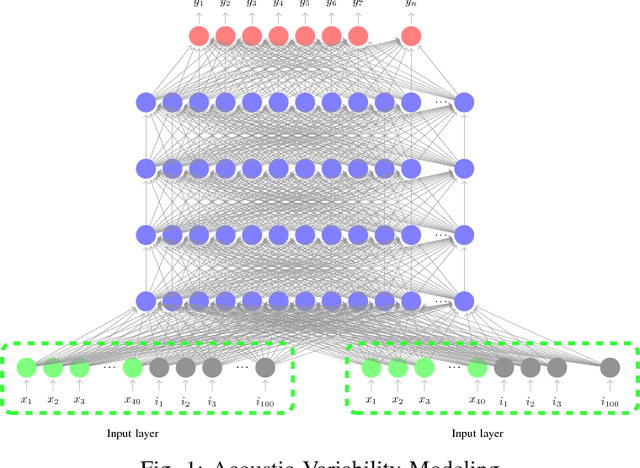
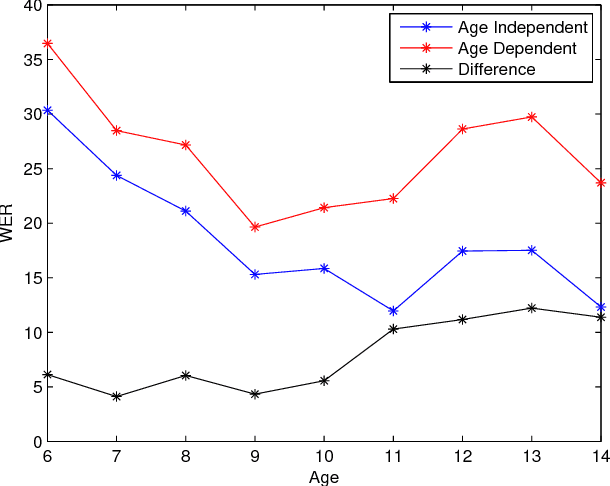
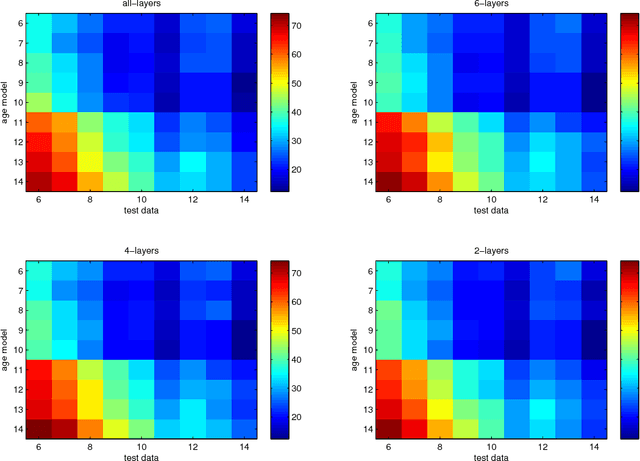
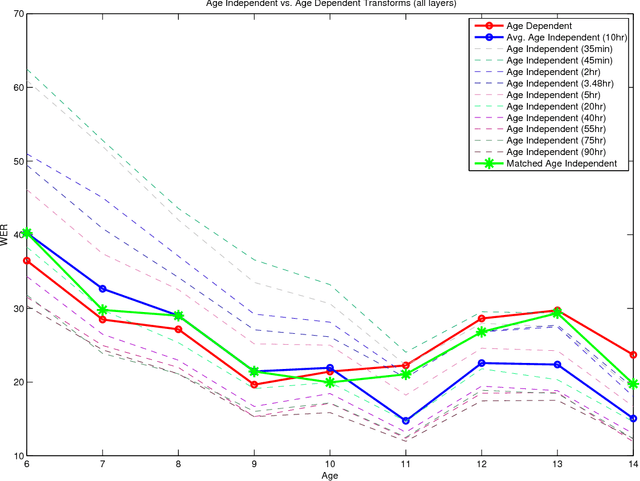
Children speech recognition is challenging mainly due to the inherent high variability in children's physical and articulatory characteristics and expressions. This variability manifests in both acoustic constructs and linguistic usage due to the rapidly changing developmental stage in children's life. Part of the challenge is due to the lack of large amounts of available children speech data for efficient modeling. This work attempts to address the key challenges using transfer learning from adult's models to children's models in a Deep Neural Network (DNN) framework for children's Automatic Speech Recognition (ASR) task evaluating on multiple children's speech corpora with a large vocabulary. The paper presents a systematic and an extensive analysis of the proposed transfer learning technique considering the key factors affecting children's speech recognition from prior literature. Evaluations are presented on (i) comparisons of earlier GMM-HMM and the newer DNN Models, (ii) effectiveness of standard adaptation techniques versus transfer learning, (iii) various adaptation configurations in tackling the variabilities present in children speech, in terms of (a) acoustic spectral variability, and (b) pronunciation variability and linguistic constraints. Our Analysis spans over (i) number of DNN model parameters (for adaptation), (ii) amount of adaptation data, (iii) ages of children, (iv) age dependent-independent adaptation. Finally, we provide Recommendations on (i) the favorable strategies over various aforementioned - analyzed parameters, and (ii) potential future research directions and relevant challenges/problems persisting in DNN based ASR for children's speech.
Distributed Training of Deep Neural Network Acoustic Models for Automatic Speech Recognition
Feb 24, 2020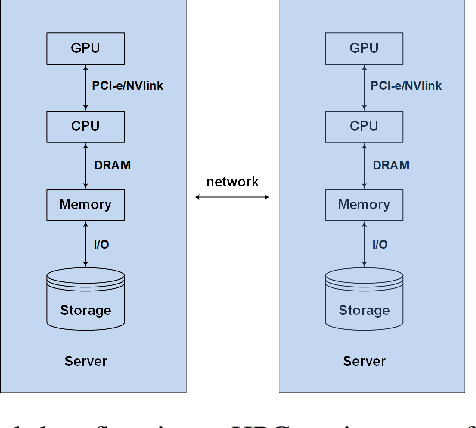
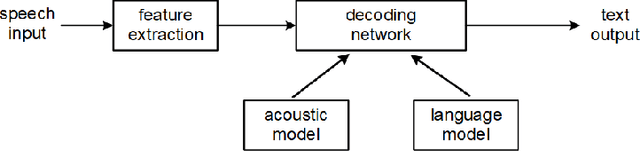
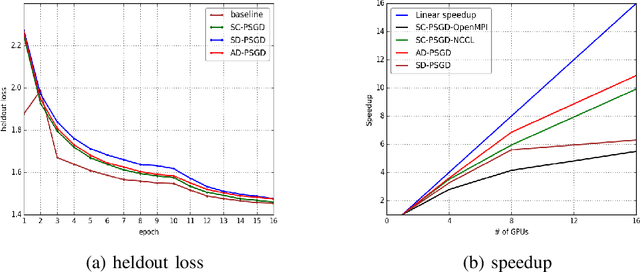
The past decade has witnessed great progress in Automatic Speech Recognition (ASR) due to advances in deep learning. The improvements in performance can be attributed to both improved models and large-scale training data. Key to training such models is the employment of efficient distributed learning techniques. In this article, we provide an overview of distributed training techniques for deep neural network acoustic models for ASR. Starting with the fundamentals of data parallel stochastic gradient descent (SGD) and ASR acoustic modeling, we will investigate various distributed training strategies and their realizations in high performance computing (HPC) environments with an emphasis on striking the balance between communication and computation. Experiments are carried out on a popular public benchmark to study the convergence, speedup and recognition performance of the investigated strategies.
Augmenting Bottleneck Features of Deep Neural Network Employing Motor State for Speech Recognition at Humanoid Robots
Aug 27, 2018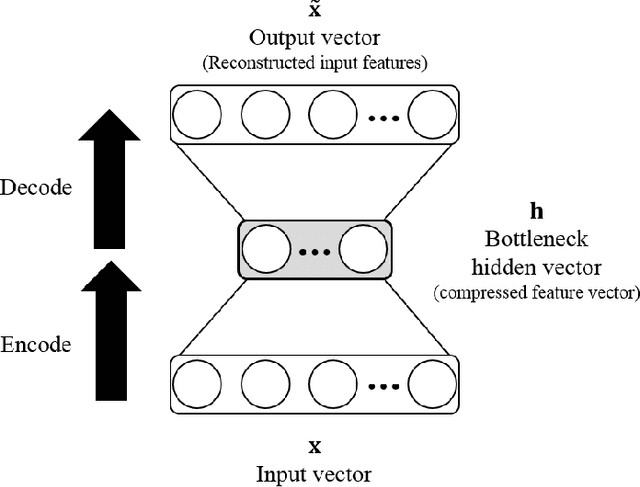
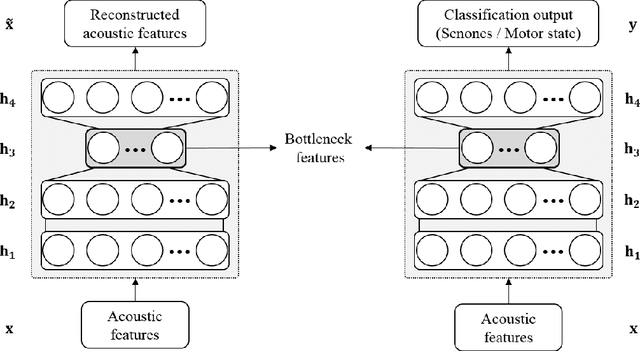
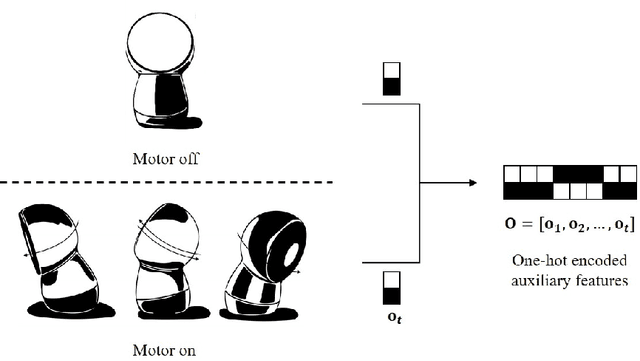
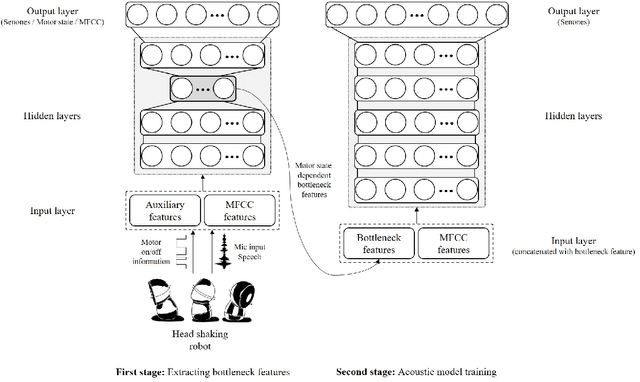
As for the humanoid robots, the internal noise, which is generated by motors, fans and mechanical components when the robot is moving or shaking its body, severely degrades the performance of the speech recognition accuracy. In this paper, a novel speech recognition system robust to ego-noise for humanoid robots is proposed, in which on/off state of the motor is employed as auxiliary information for finding the relevant input features. For this, we consider the bottleneck features, which have been successfully applied to deep neural network (DNN) based automatic speech recognition (ASR) system. When learning the bottleneck features to catch, we first exploit the motor on/off state data as supplementary information in addition to the acoustic features as the input of the first deep neural network (DNN) for preliminary acoustic modeling. Then, the second DNN for primary acoustic modeling employs both the bottleneck features tossed from the first DNN and the acoustics features. When the proposed method is evaluated in terms of phoneme error rate (PER) on TIMIT database, the experimental results show that achieve obvious improvement (11% relative) is achieved by our algorithm over the conventional systems.
Transformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment
May 06, 2022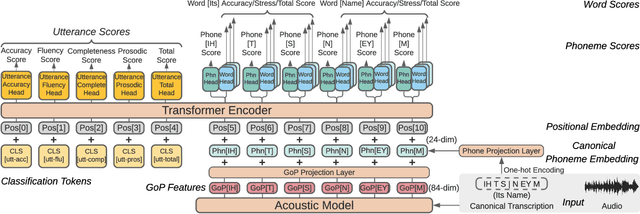
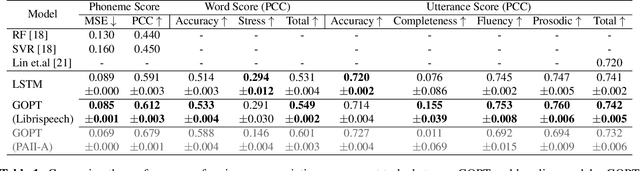
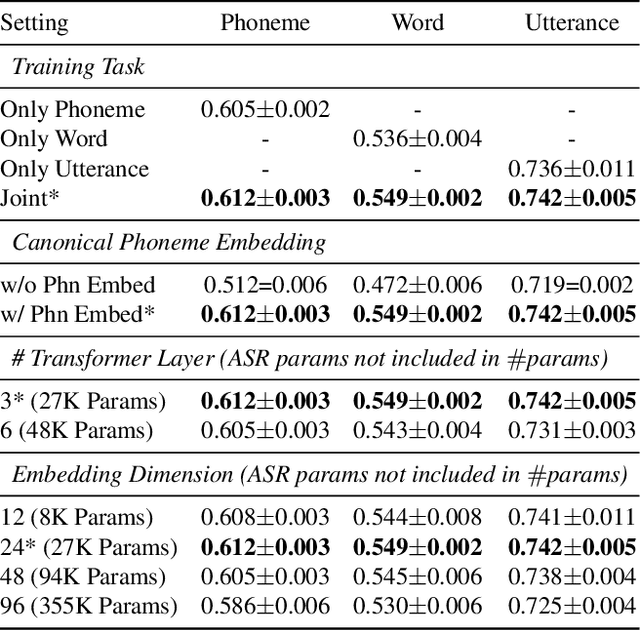

Automatic pronunciation assessment is an important technology to help self-directed language learners. While pronunciation quality has multiple aspects including accuracy, fluency, completeness, and prosody, previous efforts typically only model one aspect (e.g., accuracy) at one granularity (e.g., at the phoneme-level). In this work, we explore modeling multi-aspect pronunciation assessment at multiple granularities. Specifically, we train a Goodness Of Pronunciation feature-based Transformer (GOPT) with multi-task learning. Experiments show that GOPT achieves the best results on speechocean762 with a public automatic speech recognition (ASR) acoustic model trained on Librispeech.
Manifold-Kernels Comparison in MKPLS for Visual Speech Recognition
Jan 22, 2016
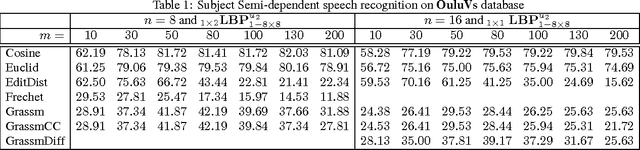
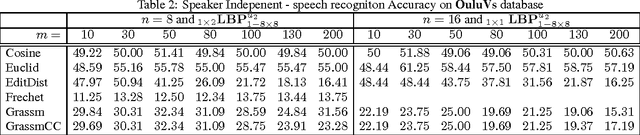
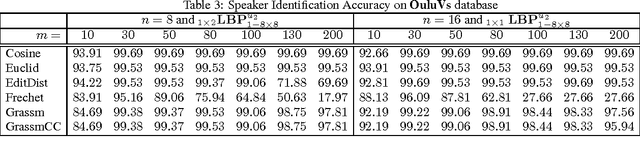
Speech recognition is a challenging problem. Due to the acoustic limitations, using visual information is essential for improving the recognition accuracy in real-life unconstraint situations. One common approach is to model the visual recognition as nonlinear optimization problem. Measuring the distances between visual units is essential for solving this problem. Embedding the visual units on a manifold and using manifold kernels is one way to measure these distances. This work is intended to evaluate the performance of several manifold kernels for solving the problem of visual speech recognition. We show the theory behind each kernel. We apply manifold kernel partial least squares framework to OuluVs and AvLetters databases, and show empirical comparison between all kernels. This framework provides convenient way to explore different kernels.