 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Speech Recognition with Corpus Relatedness Sampling
Paper and Code
Aug 02, 2019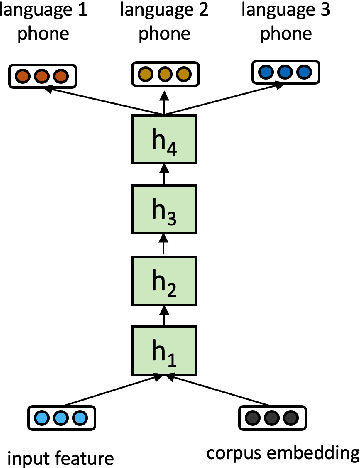
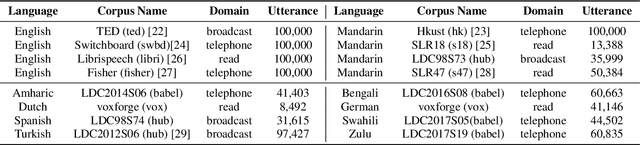
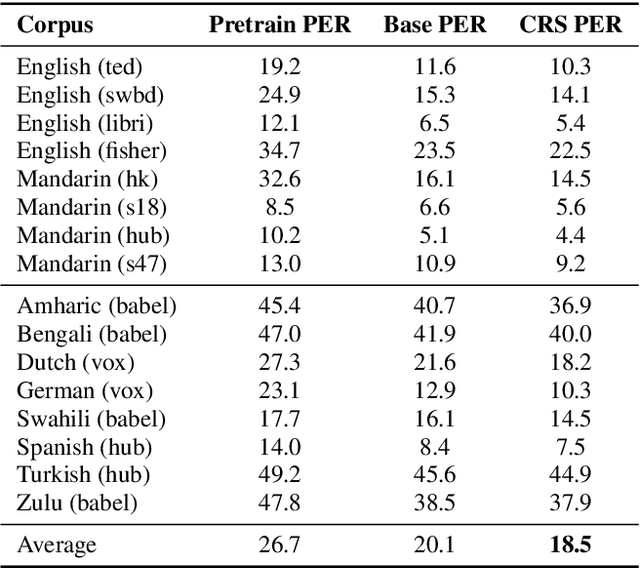
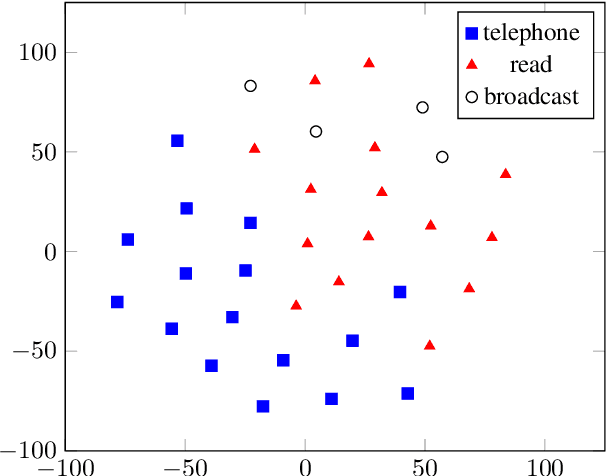
Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.