 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Transportation Pruning
Jul 31, 2023Deep learning algorithms are increasingly employed at the edge. However, edge devices are resource constrained and thus require efficient deployment of deep neural networks. Pruning methods are a key tool for edge deployment as they can improve storage, compute, memory bandwidth, and energy usage. In this paper we propose a novel accurate pruning technique that allows precise control over the output network size. Our method uses an efficient optimal transportation scheme which we make end-to-end differentiable and which automatically tunes the exploration-exploitation behavior of the algorithm to find accurate sparse sub-networks. We show that our method achieves state-of-the-art performance compared to previous pruning methods on 3 different datasets, using 5 different models, across a wide range of pruning ratios, and with two types of sparsity budgets and pruning granularities.
Distilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Dec 16, 2020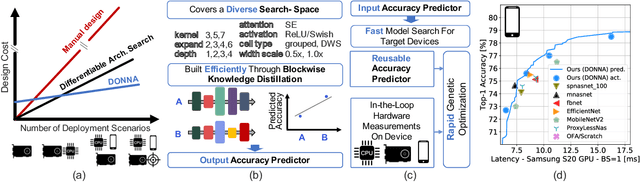



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.
BinarEye: An Always-On Energy-Accuracy-Scalable Binary CNN Processor With All Memory On Chip in 28nm CMOS
Apr 16, 2018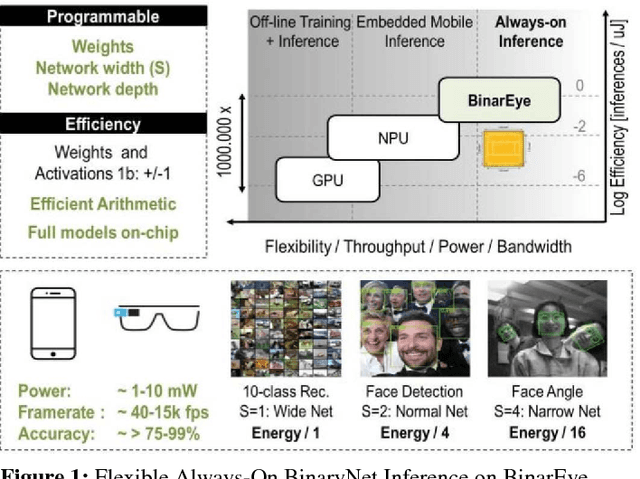
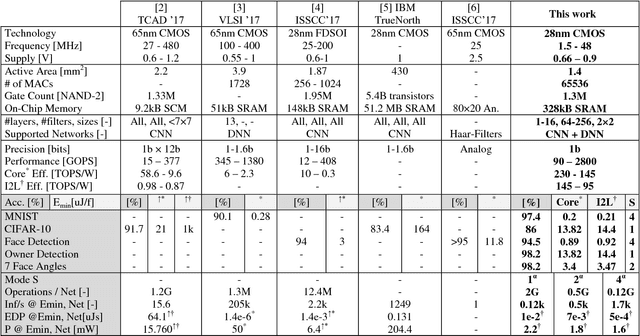
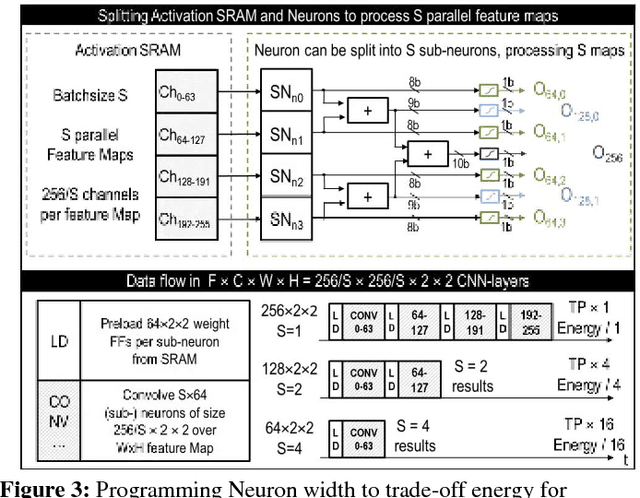
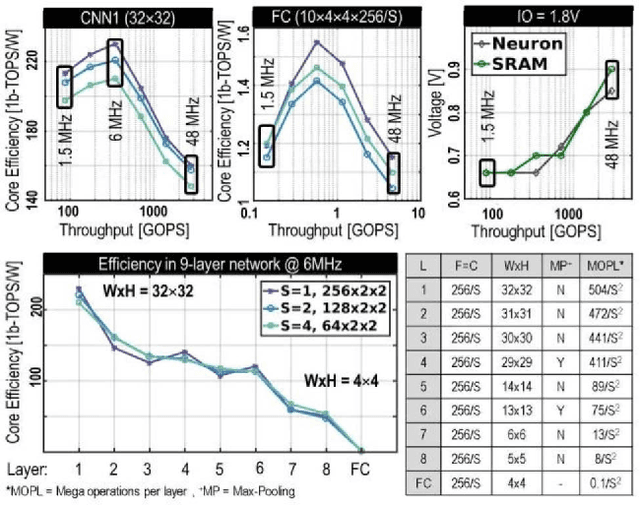
This paper introduces BinarEye: a digital processor for always-on Binary Convolutional Neural Networks. The chip maximizes data reuse through a Neuron Array exploiting local weight Flip-Flops. It stores full network models and feature maps and hence requires no off-chip bandwidth, which leads to a 230 1b-TOPS/W peak efficiency. Its 3 levels of flexibility - (a) weight reconfiguration, (b) a programmable network depth and (c) a programmable network width - allow trading energy for accuracy depending on the task's requirements. BinarEye's full system input-to-label energy consumption ranges from 14.4uJ/f for 86% CIFAR-10 and 98% owner recognition down to 0.92uJ/f for 94% face detection at up to 1700 frames per second. This is 3-12-70x more efficient than the state-of-the-art at on-par accuracy.
Resource aware design of a deep convolutional-recurrent neural network for speech recognition through audio-visual sensor fusion
Mar 13, 2018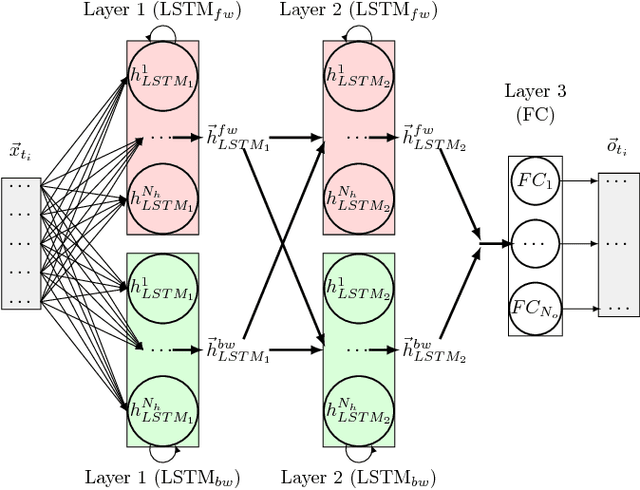
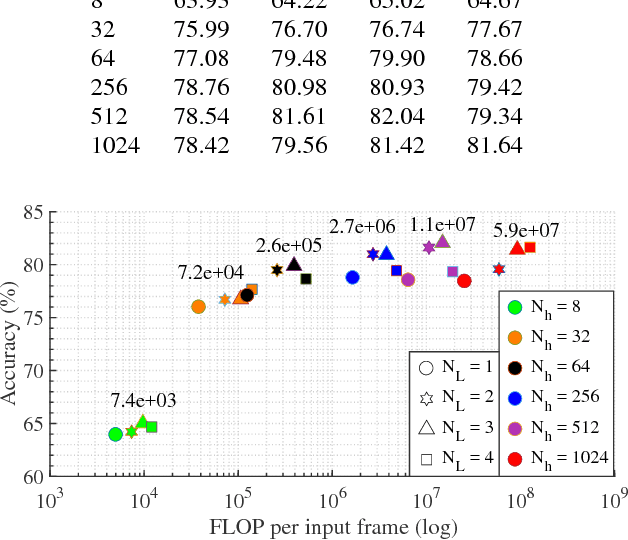
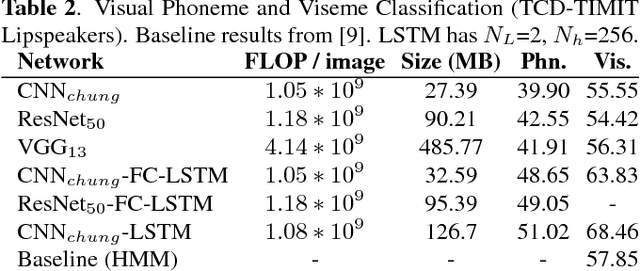
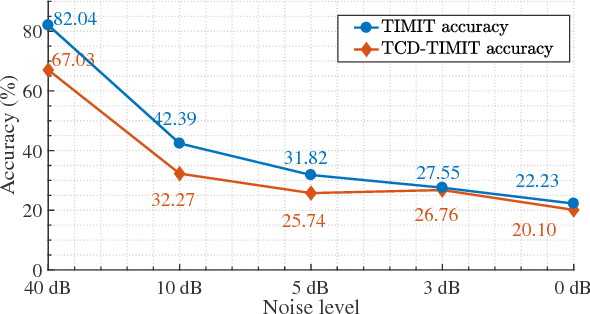
Today's Automatic Speech Recognition systems only rely on acoustic signals and often don't perform well under noisy conditions. Performing multi-modal speech recognition - processing acoustic speech signals and lip-reading video simultaneously - significantly enhances the performance of such systems, especially in noisy environments. This work presents the design of such an audio-visual system for Automated Speech Recognition, taking memory and computation requirements into account. First, a Long-Short-Term-Memory neural network for acoustic speech recognition is designed. Second, Convolutional Neural Networks are used to model lip-reading features. These are combined with an LSTM network to model temporal dependencies and perform automatic lip-reading on video. Finally, acoustic-speech and visual lip-reading networks are combined to process acoustic and visual features simultaneously. An attention mechanism ensures performance of the model in noisy environments. This system is evaluated on the TCD-TIMIT 'lipspeaker' dataset for audio-visual phoneme recognition with clean audio and with additive white noise at an SNR of 0dB. It achieves 75.70% and 58.55% phoneme accuracy respectively, over 14 percentage points better than the state-of-the-art for all noise levels.
Minimum Energy Quantized Neural Networks
Nov 23, 2017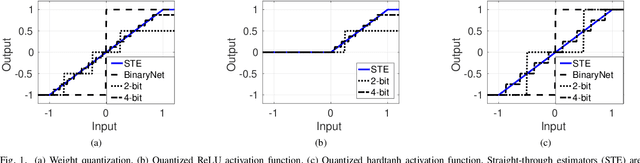
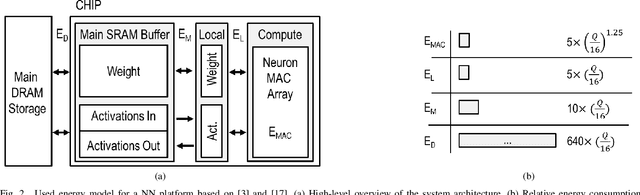
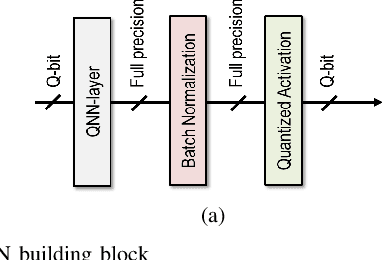
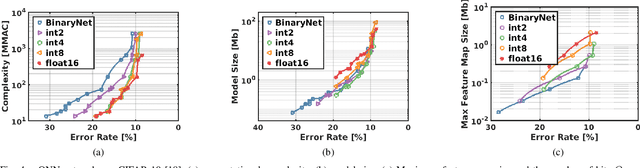
This work targets the automated minimum-energy optimization of Quantized Neural Networks (QNNs) - networks using low precision weights and activations. These networks are trained from scratch at an arbitrary fixed point precision. At iso-accuracy, QNNs using fewer bits require deeper and wider network architectures than networks using higher precision operators, while they require less complex arithmetic and less bits per weights. This fundamental trade-off is analyzed and quantified to find the minimum energy QNN for any benchmark and hence optimize energy-efficiency. To this end, the energy consumption of inference is modeled for a generic hardware platform. This allows drawing several conclusions across different benchmarks. First, energy consumption varies orders of magnitude at iso-accuracy depending on the number of bits used in the QNN. Second, in a typical system, BinaryNets or int4 implementations lead to the minimum energy solution, outperforming int8 networks up to 2-10x at iso-accuracy. All code used for QNN training is available from https://github.com/BertMoons.
Energy-Efficient ConvNets Through Approximate Computing
Mar 22, 2016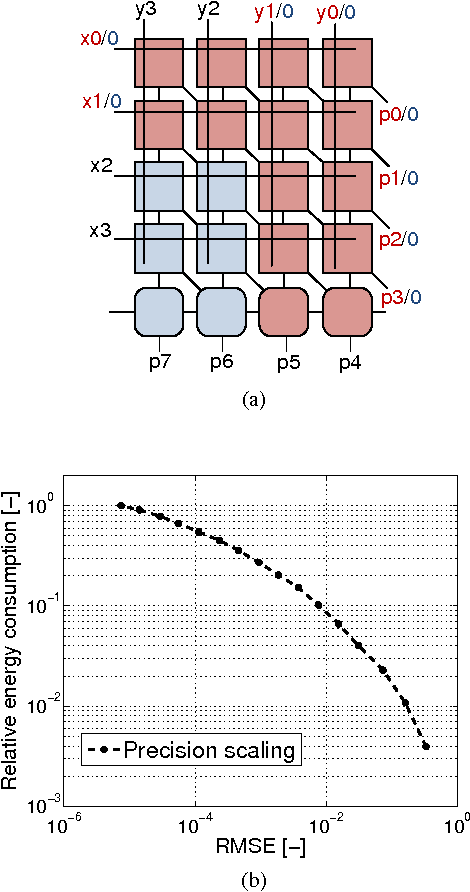
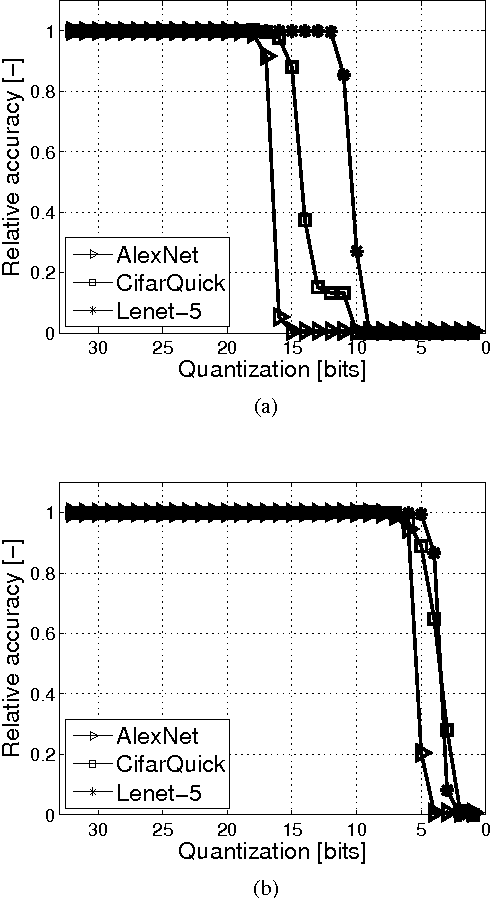
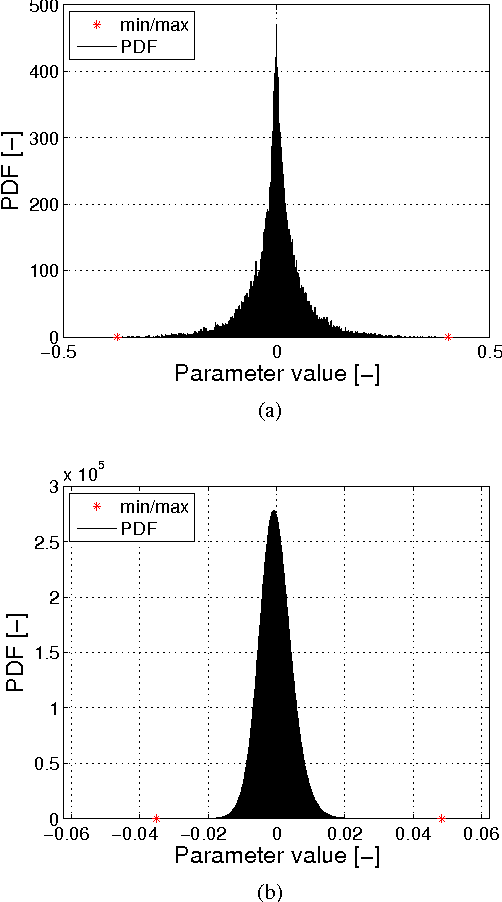
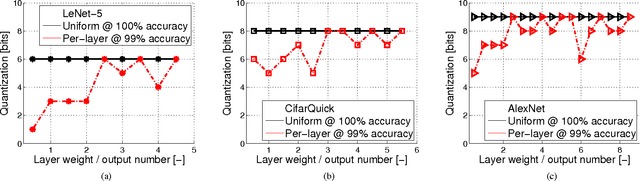
Recently ConvNets or convolutional neural networks (CNN) have come up as state-of-the-art classification and detection algorithms, achieving near-human performance in visual detection. However, ConvNet algorithms are typically very computation and memory intensive. In order to be able to embed ConvNet-based classification into wearable platforms and embedded systems such as smartphones or ubiquitous electronics for the internet-of-things, their energy consumption should be reduced drastically. This paper proposes methods based on approximate computing to reduce energy consumption in state-of-the-art ConvNet accelerators. By combining techniques both at the system- and circuit level, we can gain energy in the systems arithmetic: up to 30x without losing classification accuracy and more than 100x at 99% classification accuracy, compared to the commonly used 16-bit fixed point number format.