 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning from Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations
Paper and Code
May 08, 2018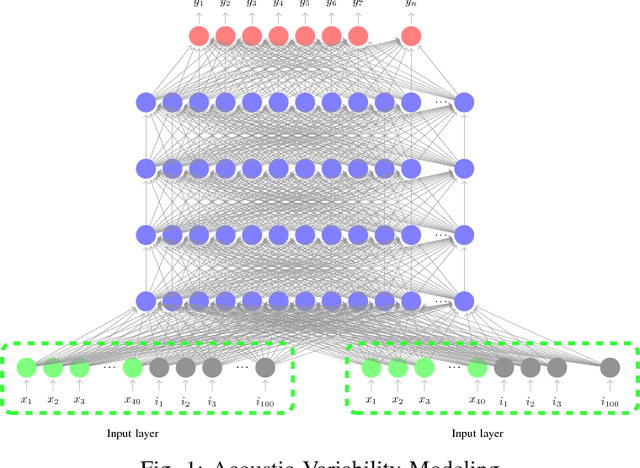
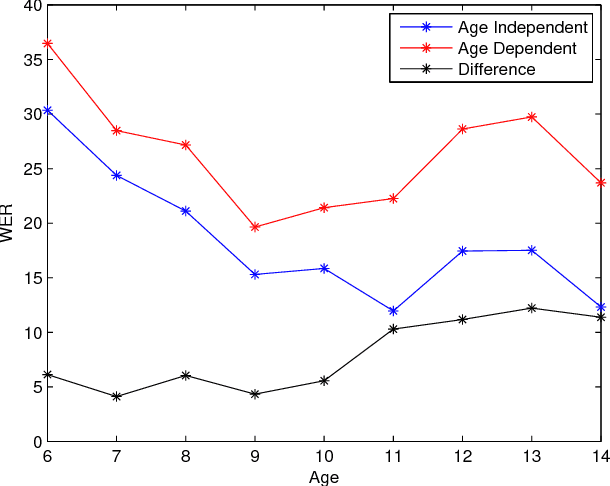
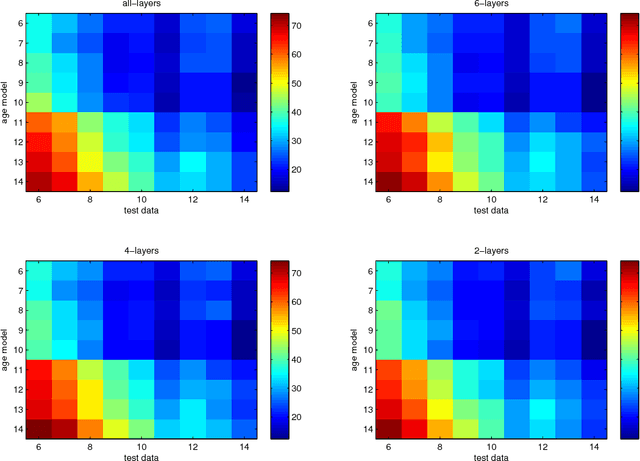
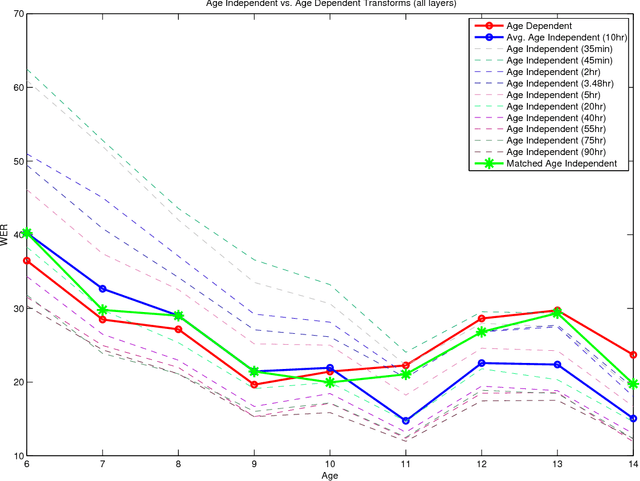
Children speech recognition is challenging mainly due to the inherent high variability in children's physical and articulatory characteristics and expressions. This variability manifests in both acoustic constructs and linguistic usage due to the rapidly changing developmental stage in children's life. Part of the challenge is due to the lack of large amounts of available children speech data for efficient modeling. This work attempts to address the key challenges using transfer learning from adult's models to children's models in a Deep Neural Network (DNN) framework for children's Automatic Speech Recognition (ASR) task evaluating on multiple children's speech corpora with a large vocabulary. The paper presents a systematic and an extensive analysis of the proposed transfer learning technique considering the key factors affecting children's speech recognition from prior literature. Evaluations are presented on (i) comparisons of earlier GMM-HMM and the newer DNN Models, (ii) effectiveness of standard adaptation techniques versus transfer learning, (iii) various adaptation configurations in tackling the variabilities present in children speech, in terms of (a) acoustic spectral variability, and (b) pronunciation variability and linguistic constraints. Our Analysis spans over (i) number of DNN model parameters (for adaptation), (ii) amount of adaptation data, (iii) ages of children, (iv) age dependent-independent adaptation. Finally, we provide Recommendations on (i) the favorable strategies over various aforementioned - analyzed parameters, and (ii) potential future research directions and relevant challenges/problems persisting in DNN based ASR for children's speech.