 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Fully Convolutional Speech Recognition
Dec 17, 2018
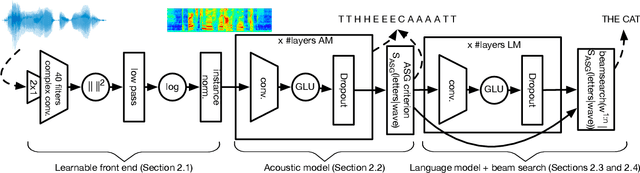

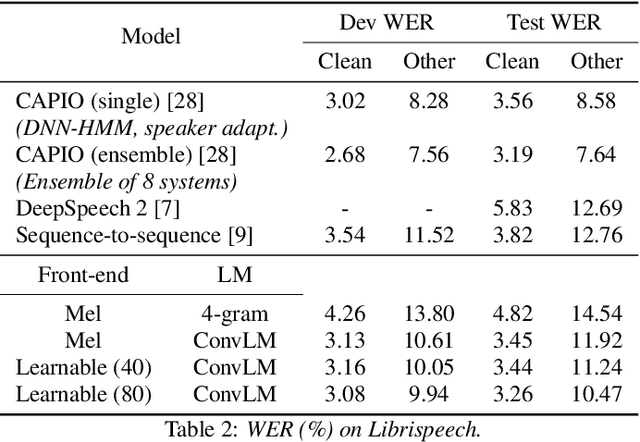
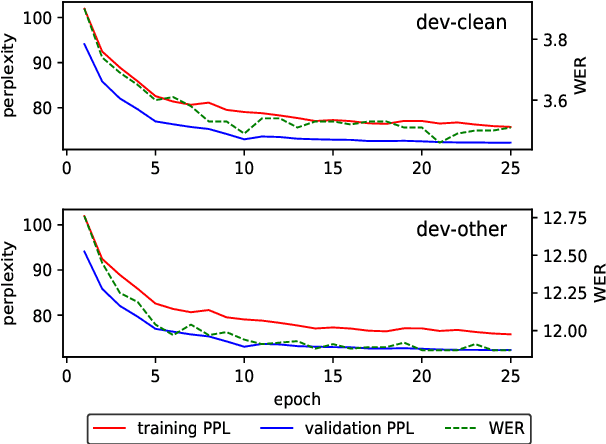
Current state-of-the-art speech recognition systems build on recurrent neural networks for acoustic and/or language modeling, and rely on feature extraction pipelines to extract mel-filterbanks or cepstral coefficients. In this paper we present an alternative approach based solely on convolutional neural networks, leveraging recent advances in acoustic models from the raw waveform and language modeling. This fully convolutional approach is trained end-to-end to predict characters from the raw waveform, removing the feature extraction step altogether. An external convolutional language model is used to decode words. On Wall Street Journal, our model matches the current state-of-the-art. On Librispeech, we report state-of-the-art performance among end-to-end models, including Deep Speech 2 trained with 12 times more acoustic data and significantly more linguistic data.
Separator-Transducer-Segmenter: Streaming Recognition and Segmentation of Multi-party Speech
May 10, 2022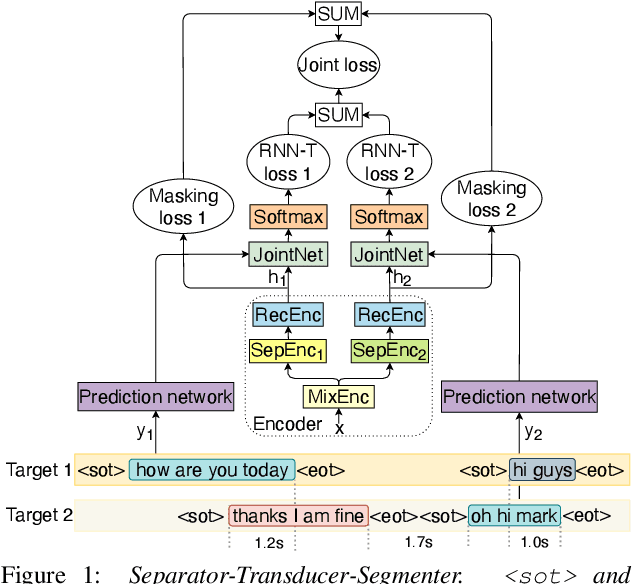
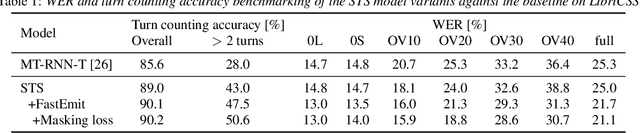

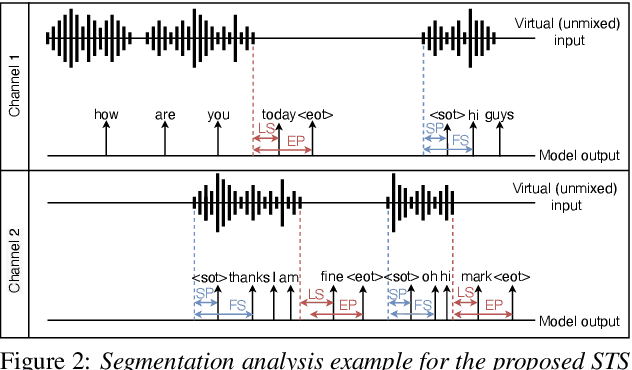
Streaming recognition and segmentation of multi-party conversations with overlapping speech is crucial for the next generation of voice assistant applications. In this work we address its challenges discovered in the previous work on multi-turn recurrent neural network transducer (MT-RNN-T) with a novel approach, separator-transducer-segmenter (STS), that enables tighter integration of speech separation, recognition and segmentation in a single model. First, we propose a new segmentation modeling strategy through start-of-turn and end-of-turn tokens that improves segmentation without recognition accuracy degradation. Second, we further improve both speech recognition and segmentation accuracy through an emission regularization method, FastEmit, and multi-task training with speech activity information as an additional training signal. Third, we experiment with end-of-turn emission latency penalty to improve end-point detection for each speaker turn. Finally, we establish a novel framework for segmentation analysis of multi-party conversations through emission latency metrics. With our best model, we report 4.6% abs. turn counting accuracy improvement and 17% rel. word error rate (WER) improvement on LibriCSS dataset compared to the previously published work.
UniSpeech at scale: An Empirical Study of Pre-training Method on Large-Scale Speech Recognition Dataset
Jul 12, 2021
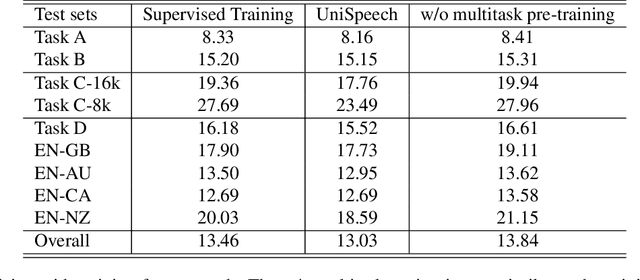
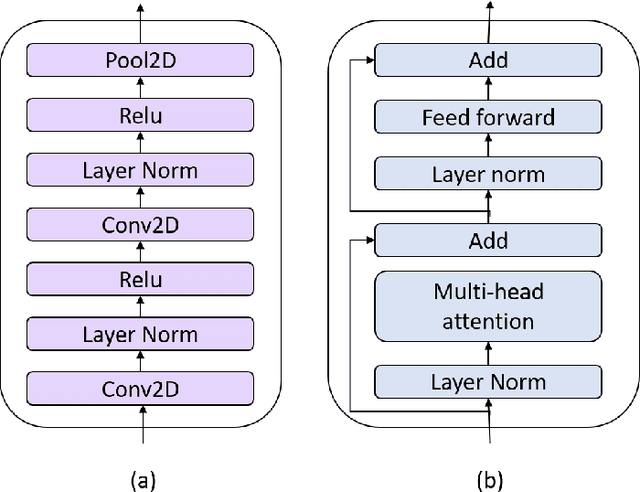
Recently, there has been a vast interest in self-supervised learning (SSL) where the model is pre-trained on large scale unlabeled data and then fine-tuned on a small labeled dataset. The common wisdom is that SSL helps resource-limited tasks in which only a limited amount of labeled data is available. The benefit of SSL keeps diminishing when the labeled training data amount increases. To our best knowledge, at most a few thousand hours of labeled data was used in the study of SSL. In contrast, the industry usually uses tens of thousands of hours of labeled data to build high-accuracy speech recognition (ASR) systems for resource-rich languages. In this study, we take the challenge to investigate whether and how SSL can improve the ASR accuracy of a state-of-the-art production-scale Transformer-Transducer model, which was built with 65 thousand hours of anonymized labeled EN-US data.
Listen with Intent: Improving Speech Recognition with Audio-to-Intent Front-End
May 14, 2021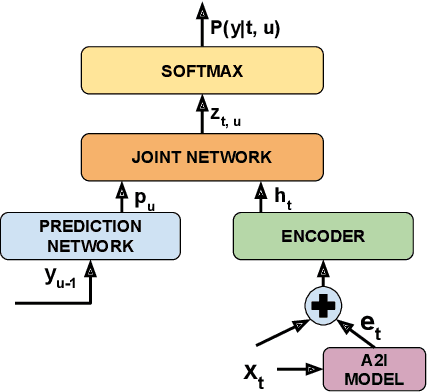
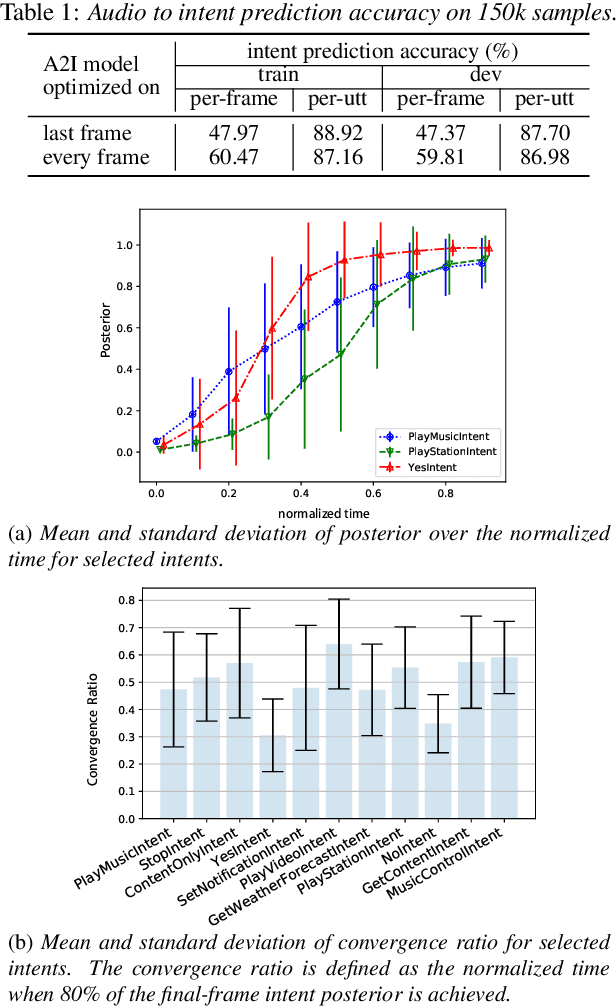
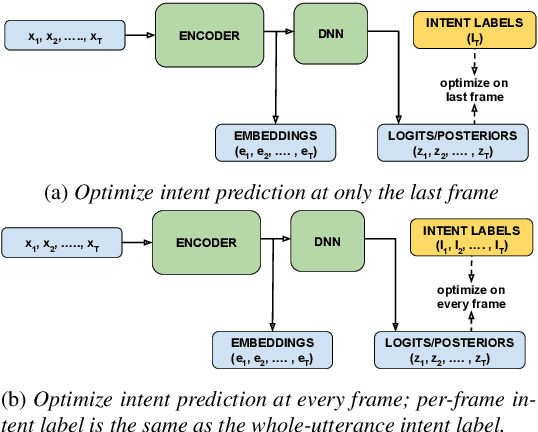
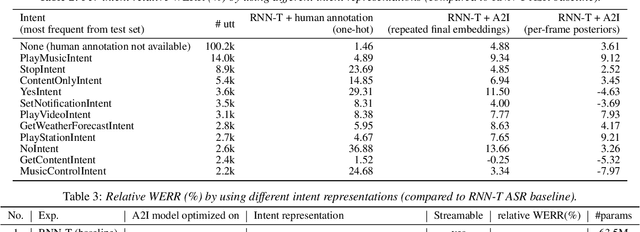
Comprehending the overall intent of an utterance helps a listener recognize the individual words spoken. Inspired by this fact, we perform a novel study of the impact of explicitly incorporating intent representations as additional information to improve a recurrent neural network-transducer (RNN-T) based automatic speech recognition (ASR) system. An audio-to-intent (A2I) model encodes the intent of the utterance in the form of embeddings or posteriors, and these are used as auxiliary inputs for RNN-T training and inference. Experimenting with a 50k-hour far-field English speech corpus, this study shows that when running the system in non-streaming mode, where intent representation is extracted from the entire utterance and then used to bias streaming RNN-T search from the start, it provides a 5.56% relative word error rate reduction (WERR). On the other hand, a streaming system using per-frame intent posteriors as extra inputs for the RNN-T ASR system yields a 3.33% relative WERR. A further detailed analysis of the streaming system indicates that our proposed method brings especially good gain on media-playing related intents (e.g. 9.12% relative WERR on PlayMusicIntent).
Improved Conformer-based End-to-End Speech Recognition Using Neural Architecture Search
Apr 13, 2021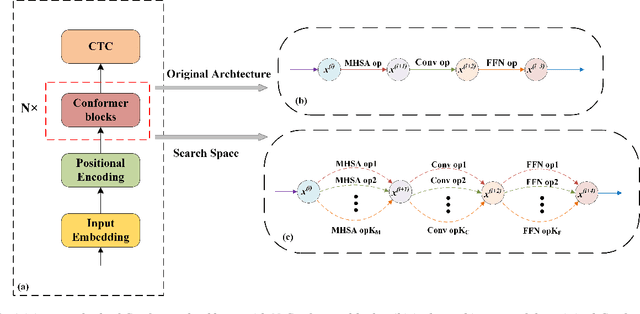

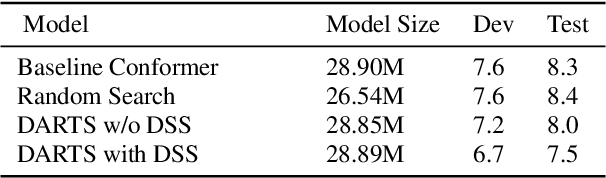
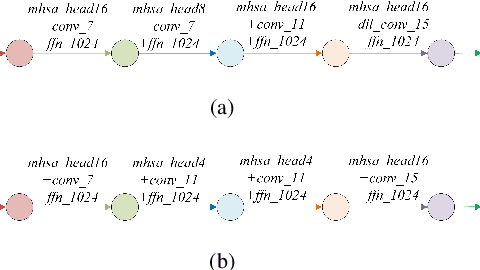
Recently neural architecture search(NAS) has been successfully used in image classification, natural language processing, and automatic speech recognition(ASR) tasks for finding the state-of-the-art(SOTA) architectures than those human-designed architectures. NAS can derive a SOTA and data-specific architecture over validation data from a pre-defined search space with a search algorithm. Inspired by the success of NAS in ASR tasks, we propose a NAS-based ASR framework containing one search space and one differentiable search algorithm called Differentiable Architecture Search(DARTS). Our search space follows the convolution-augmented transformer(Conformer) backbone, which is a more expressive ASR architecture than those used in existing NAS-based ASR frameworks. To improve the performance of our method, a regulation method called Dynamic Search Schedule(DSS) is employed. On a widely used Mandarin benchmark AISHELL-1, our best-searched architecture outperforms the baseline Conform model significantly with about 11% CER relative improvement, and our method is proved to be pretty efficient by the search cost comparisons.
Can we use Common Voice to train a Multi-Speaker TTS system?
Oct 12, 2022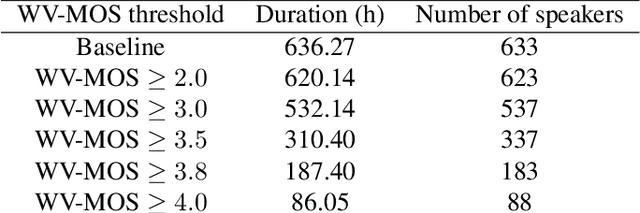
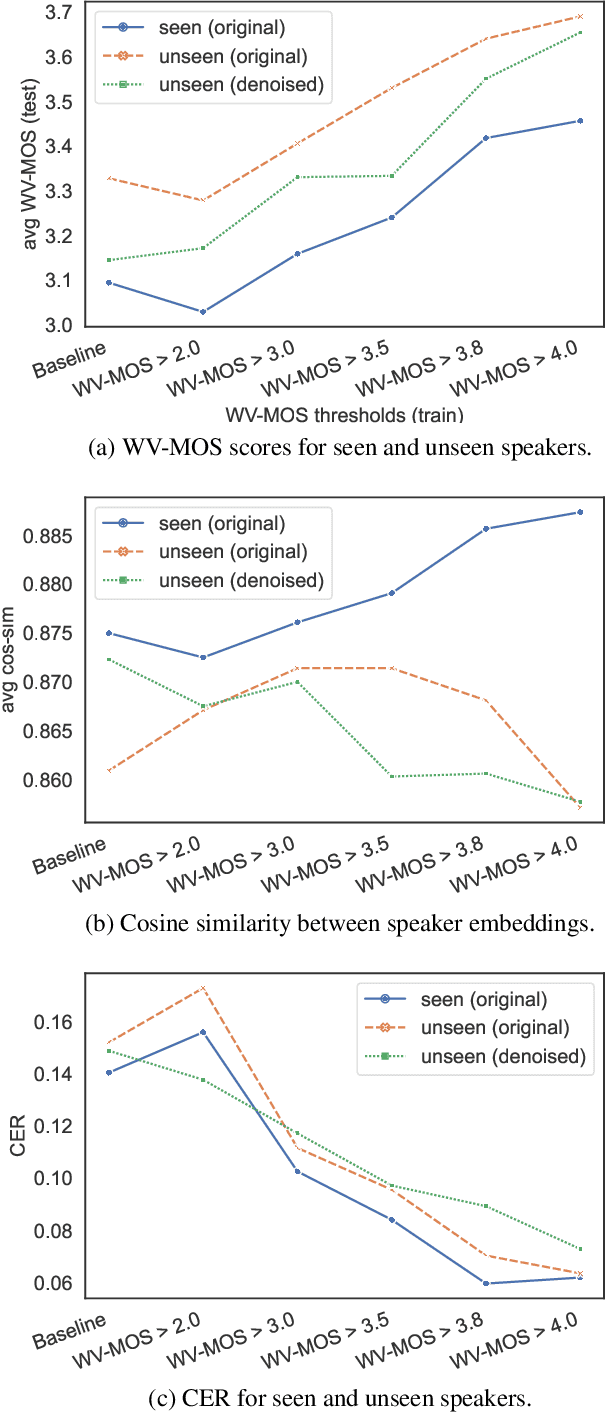
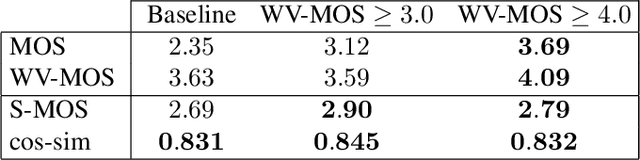
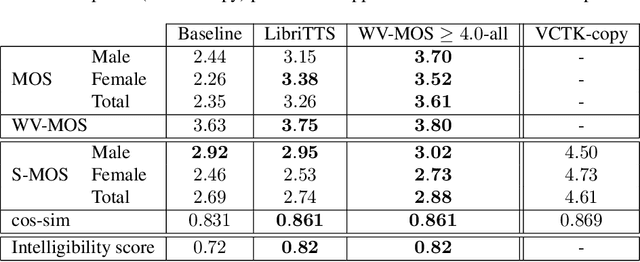
Training of multi-speaker text-to-speech (TTS) systems relies on curated datasets based on high-quality recordings or audiobooks. Such datasets often lack speaker diversity and are expensive to collect. As an alternative, recent studies have leveraged the availability of large, crowdsourced automatic speech recognition (ASR) datasets. A major problem with such datasets is the presence of noisy and/or distorted samples, which degrade TTS quality. In this paper, we propose to automatically select high-quality training samples using a non-intrusive mean opinion score (MOS) estimator, WV-MOS. We show the viability of this approach for training a multi-speaker GlowTTS model on the Common Voice English dataset. Our approach improves the overall quality of generated utterances by 1.26 MOS point with respect to training on all the samples and by 0.35 MOS point with respect to training on the LibriTTS dataset. This opens the door to automatic TTS dataset curation for a wider range of languages.
A context-aware knowledge transferring strategy for CTC-based ASR
Oct 12, 2022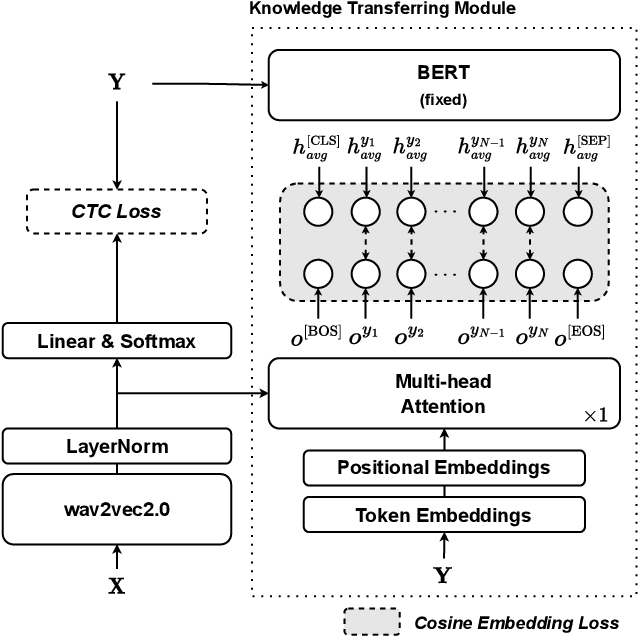
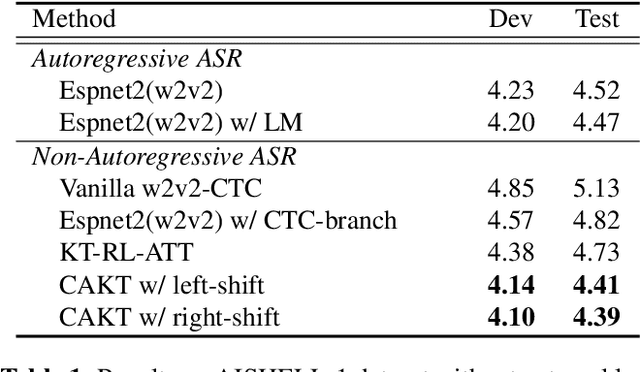
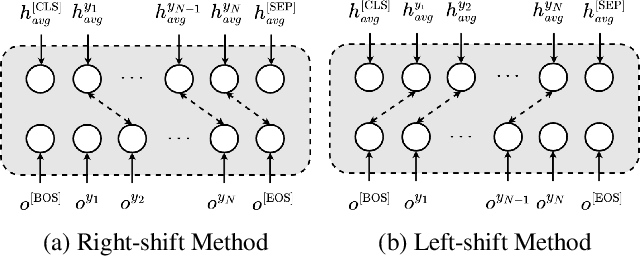
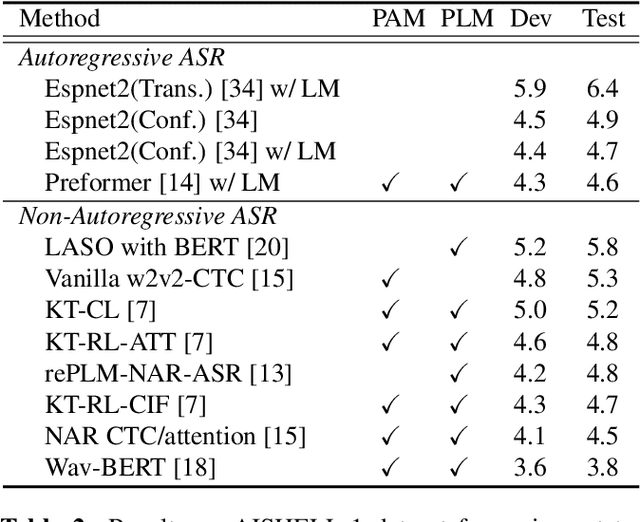
Non-autoregressive automatic speech recognition (ASR) modeling has received increasing attention recently because of its fast decoding speed and superior performance. Among representatives, methods based on the connectionist temporal classification (CTC) are still a dominating stream. However, the theoretically inherent flaw, the assumption of independence between tokens, creates a performance barrier for the school of works. To mitigate the challenge, we propose a context-aware knowledge transferring strategy, consisting of a knowledge transferring module and a context-aware training strategy, for CTC-based ASR. The former is designed to distill linguistic information from a pre-trained language model, and the latter is framed to modulate the limitations caused by the conditional independence assumption. As a result, a knowledge-injected context-aware CTC-based ASR built upon the wav2vec2.0 is presented in this paper. A series of experiments on the AISHELL-1 and AISHELL-2 datasets demonstrate the effectiveness of the proposed method.
Gradient-Adjusted Neuron Activation Profiles for Comprehensive Introspection of Convolutional Speech Recognition Models
Feb 19, 2020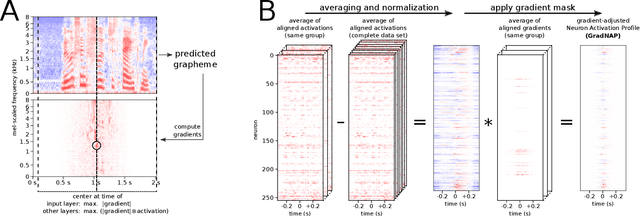
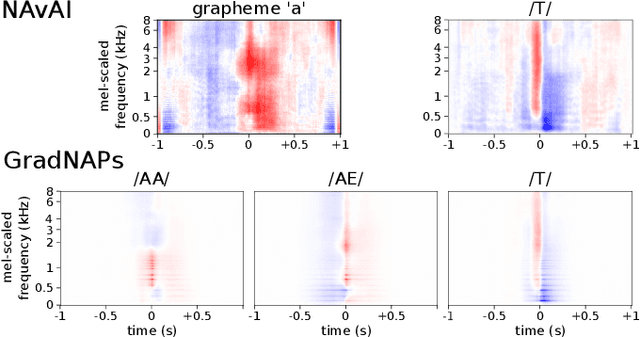
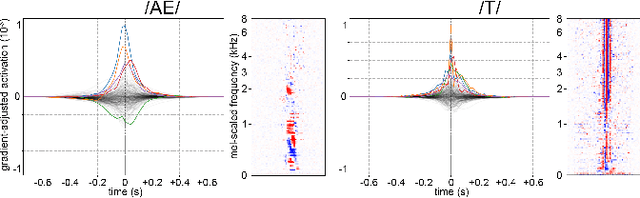
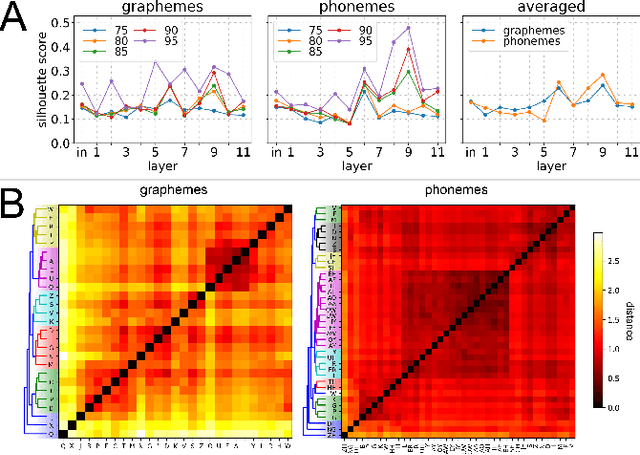
Deep Learning based Automatic Speech Recognition (ASR) models are very successful, but hard to interpret. To gain better understanding of how Artificial Neural Networks (ANNs) accomplish their tasks, introspection methods have been proposed. Adapting such techniques from computer vision to speech recognition is not straight-forward, because speech data is more complex and less interpretable than image data. In this work, we introduce Gradient-adjusted Neuron Activation Profiles (GradNAPs) as means to interpret features and representations in Deep Neural Networks. GradNAPs are characteristic responses of ANNs to particular groups of inputs, which incorporate the relevance of neurons for prediction. We show how to utilize GradNAPs to gain insight about how data is processed in ANNs. This includes different ways of visualizing features and clustering of GradNAPs to compare embeddings of different groups of inputs in any layer of a given network. We demonstrate our proposed techniques using a fully-convolutional ASR model.
Comparison of Soft and Hard Target RNN-T Distillation for Large-scale ASR
Oct 11, 2022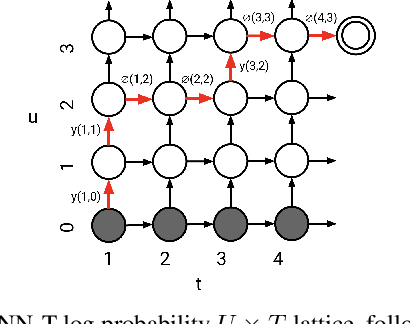
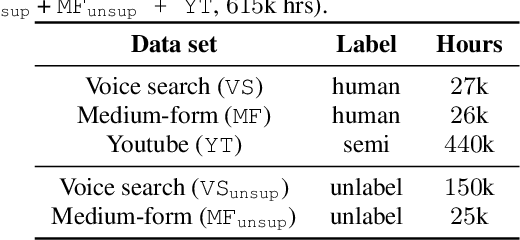

Knowledge distillation is an effective machine learning technique to transfer knowledge from a teacher model to a smaller student model, especially with unlabeled data. In this paper, we focus on knowledge distillation for the RNN-T model, which is widely used in state-of-the-art (SoTA) automatic speech recognition (ASR). Specifically, we compared using soft and hard target distillation to train large-scaleRNN-T models on the LibriSpeech/LibriLight public dataset (60k hours) and our in-house data (600k hours). We found that hard tar-gets are more effective when the teacher and student have different architecture, such as large teacher and small streaming student. On the other hand, soft target distillation works better in self-training scenario like iterative large teacher training. For a large model with0.6B weights, we achieve a new SoTA word error rate (WER) on LibriSpeech (8% relative improvement on dev-other) using Noisy Student Training with soft target distillation. It also allows our production teacher to adapt new data domain continuously.