 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Face Photos
Mar 15, 2020


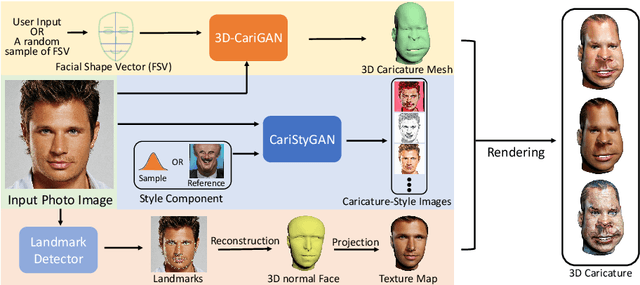
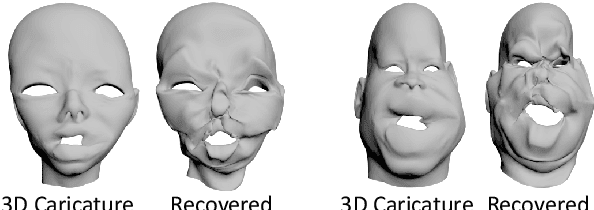
Caricature is a kind of artistic style of human faces that attracts considerable research in computer vision. So far all existing 3D caricature generation methods require some information related to caricature as input, e.g., a caricature sketch or 2D caricature. However, this kind of input is difficult to provide by non-professional users. In this paper, we propose an end-to-end deep neural network model to generate high-quality 3D caricature with a simple face photo as input. The most challenging issue in our system is that the source domain of face photos (characterized by 2D normal faces) is significantly different from the target domain of 3D caricatures (characterized by 3D exaggerated face shapes and texture). To address this challenge, we (1) build a large dataset of 6,100 3D caricature meshes and use it to establish a PCA model in the 3D caricature shape space and (2) detect landmarks in the input face photo and use them to set up correspondence between 2D caricature and 3D caricature shape. Our system can automatically generate high-quality 3D caricatures. In many situations, users want to control the output by a simple and intuitive way, so we further introduce a simple-to-use interactive control with three horizontal and one vertical lines. Experiments and user studies show that our system is easy to use and can generate high-quality 3D caricatures.
Synthesize-It-Classifier: Learning a Generative Classifier through RecurrentSelf-analysis
Mar 26, 2021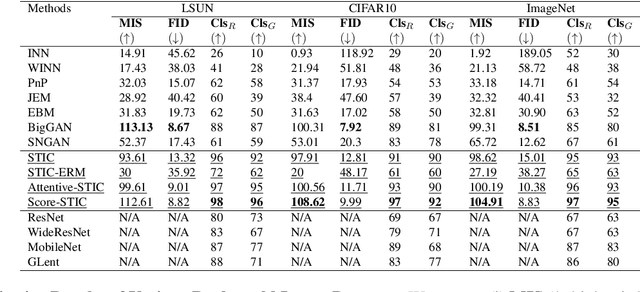
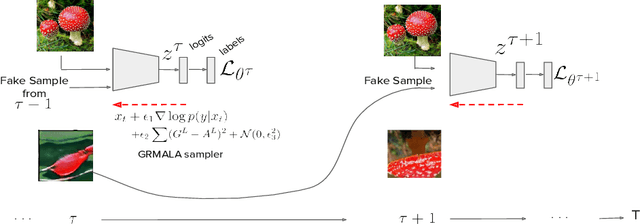


In this work, we show the generative capability of an image classifier network by synthesizing high-resolution, photo-realistic, and diverse images at scale. The overall methodology, called Synthesize-It-Classifier (STIC), does not require an explicit generator network to estimate the density of the data distribution and sample images from that, but instead uses the classifier's knowledge of the boundary to perform gradient ascent w.r.t. class logits and then synthesizes images using Gram Matrix Metropolis Adjusted Langevin Algorithm (GRMALA) by drawing on a blank canvas. During training, the classifier iteratively uses these synthesized images as fake samples and re-estimates the class boundary in a recurrent fashion to improve both the classification accuracy and quality of synthetic images. The STIC shows the mixing of the hard fake samples (i.e. those synthesized by the one hot class conditioning), and the soft fake samples (which are synthesized as a convex combination of classes, i.e. a mixup of classes) improves class interpolation. We demonstrate an Attentive-STIC network that shows an iterative drawing of synthesized images on the ImageNet dataset that has thousands of classes. In addition, we introduce the synthesis using a class conditional score classifier (Score-STIC) instead of a normal image classifier and show improved results on several real-world datasets, i.e. ImageNet, LSUN, and CIFAR 10.
SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
Mar 23, 2021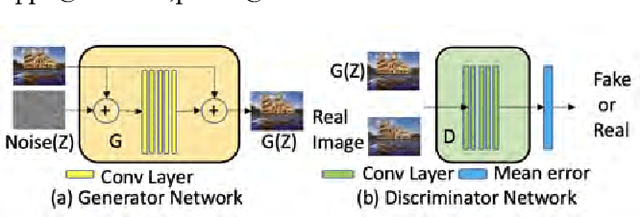

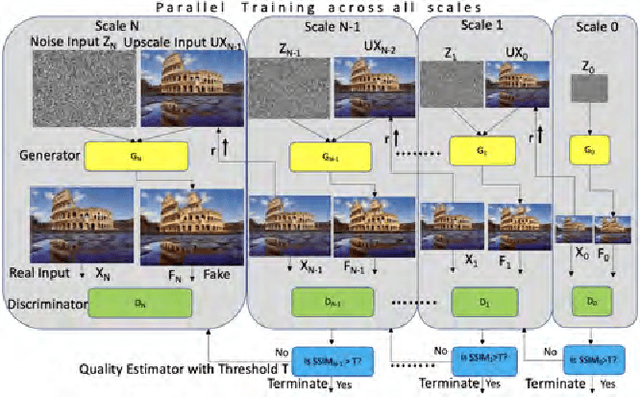
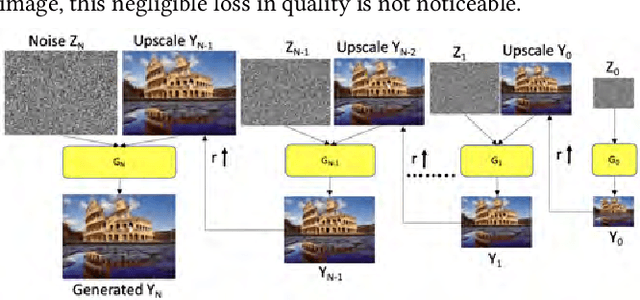
We consider the task of photo-realistic unconditional image generation (generate high quality, diverse samples that carry the same visual content as the image) on mobile platforms using Generative Adversarial Networks (GANs). In this paper, we propose a novel approach to trade-off image generation accuracy of a GAN for the energy consumed (compute) at run-time called Scale-Energy Tradeoff GAN (SETGAN). GANs usually take a long time to train and consume a huge memory hence making it difficult to run on edge devices. The key idea behind SETGAN for an image generation task is for a given input image, we train a GAN on a remote server and use the trained model on edge devices. We use SinGAN, a single image unconditional generative model, that contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. During the training process, we determine the optimal number of scales for a given input image and the energy constraint from the target edge device. Results show that with SETGAN's unique client-server-based architecture, we were able to achieve a 56% gain in energy for a loss of 3% to 12% SSIM accuracy. Also, with the parallel multi-scale training, we obtain around 4x gain in training time on the server.
Zooming SlowMo: An Efficient One-Stage Framework for Space-Time Video Super-Resolution
Apr 15, 2021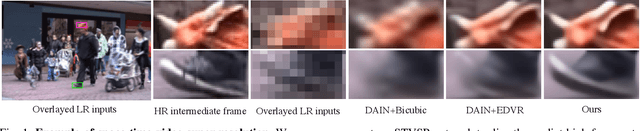
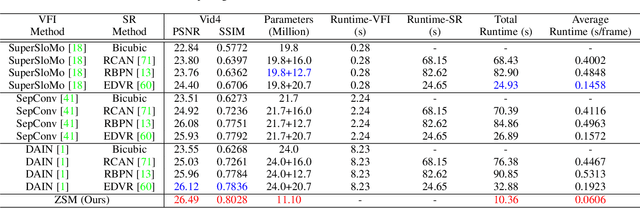
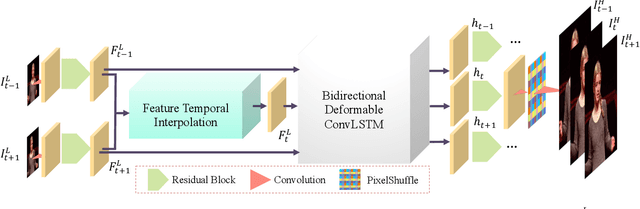
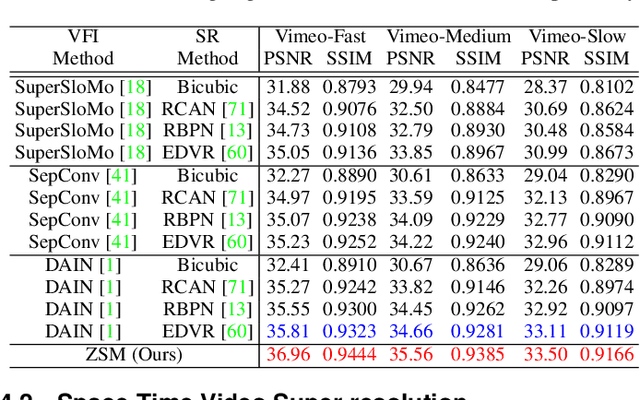
In this paper, we address the space-time video super-resolution, which aims at generating a high-resolution (HR) slow-motion video from a low-resolution (LR) and low frame rate (LFR) video sequence. A na\"ive method is to decompose it into two sub-tasks: video frame interpolation (VFI) and video super-resolution (VSR). Nevertheless, temporal interpolation and spatial upscaling are intra-related in this problem. Two-stage approaches cannot fully make use of this natural property. Besides, state-of-the-art VFI or VSR deep networks usually have a large frame reconstruction module in order to obtain high-quality photo-realistic video frames, which makes the two-stage approaches have large models and thus be relatively time-consuming. To overcome the issues, we present a one-stage space-time video super-resolution framework, which can directly reconstruct an HR slow-motion video sequence from an input LR and LFR video. Instead of reconstructing missing LR intermediate frames as VFI models do, we temporally interpolate LR frame features of the missing LR frames capturing local temporal contexts by a feature temporal interpolation module. Extensive experiments on widely used benchmarks demonstrate that the proposed framework not only achieves better qualitative and quantitative performance on both clean and noisy LR frames but also is several times faster than recent state-of-the-art two-stage networks. The source code is released in https://github.com/Mukosame/Zooming-Slow-Mo-CVPR-2020 .
An Image Forensic Technique Based on JPEG Ghosts
Jun 11, 2021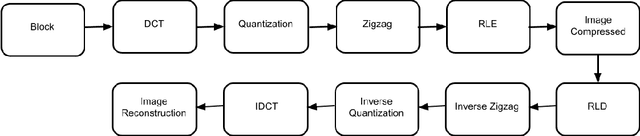
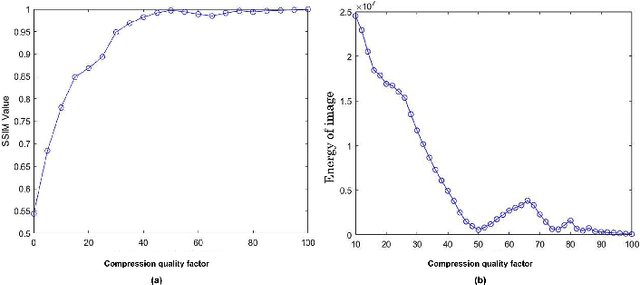


The unprecedented growth in the easy availability of photo-editing tools has endangered the power of digital images.An image was supposed to be worth more than a thousand words,but now this can be said only if it can be authenticated orthe integrity of the image can be proved to be intact. In thispaper, we propose a digital image forensic technique for JPEG images. It can detect any forgery in the image if the forged portion called a ghost image is having a compression quality different from that of the cover image. It is based on resaving the JPEG image at different JPEG qualities, and the detection of the forged portion is maximum when it is saved at the same JPEG quality as the cover image. Also, we can precisely predictthe JPEG quality of the cover image by analyzing the similarity using Structural Similarity Index Measure (SSIM) or the energyof the images. The first maxima in SSIM or the first minima inenergy correspond to the cover image JPEG quality. We created adataset for varying JPEG compression qualities of the ghost and the cover images and validated the scalability of the experimental results.We also, experimented with varied attack scenarios, e.g. high-quality ghost image embedded in low quality of cover image,low-quality ghost image embedded in high-quality of cover image,and ghost image and cover image both at the same quality.The proposed method is able to localize the tampered portions accurately even for forgeries as small as 10x10 sized pixel blocks.Our technique is also robust against other attack scenarios like copy-move forgery, inserting text into image, rescaling (zoom-out/zoom-in) ghost image and then pasting on cover image.
On adversarial patches: real-world attack on ArcFace-100 face recognition system
Oct 15, 2019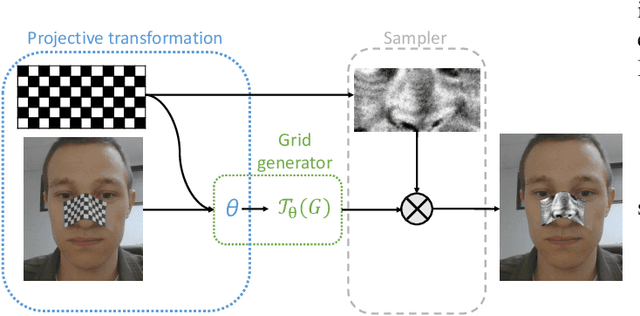
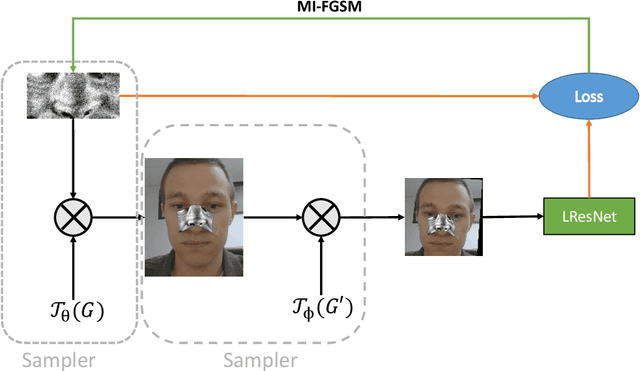


Recent works showed the vulnerability of image classifiers to adversarial attacks in the digital domain. However, the majority of attacks involve adding small perturbation to an image to fool the classifier. Unfortunately, such procedures can not be used to conduct a real-world attack, where adding an adversarial attribute to the photo is a more practical approach. In this paper, we study the problem of real-world attacks on face recognition systems. We examine security of one of the best public face recognition systems, LResNet100E-IR with ArcFace loss, and propose a simple method to attack it in the physical world. The method suggests creating an adversarial patch that can be printed, added as a face attribute and photographed; the photo of a person with such attribute is then passed to the classifier such that the classifier's recognized class changes from correct to the desired one. Proposed generating procedure allows projecting adversarial patches not only on different areas of the face, such as nose or forehead but also on some wearable accessory, such as eyeglasses.
Head2Head: Video-based Neural Head Synthesis
May 22, 2020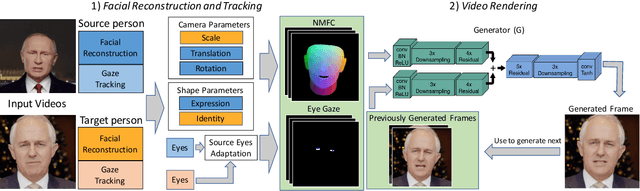

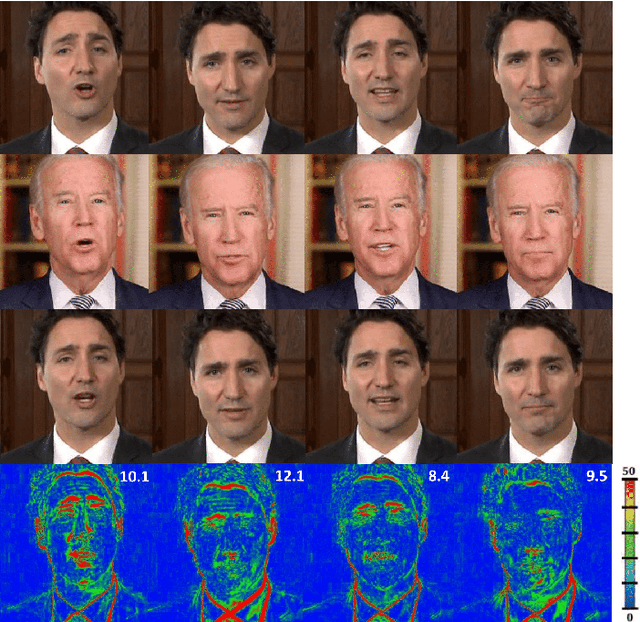

In this paper, we propose a novel machine learning architecture for facial reenactment. In particular, contrary to the model-based approaches or recent frame-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames, we propose a novel method that (a) exploits the special structure of facial motion (paying particular attention to mouth motion) and (b) enforces temporal consistency. We demonstrate that the proposed method can transfer facial expressions, pose and gaze of a source actor to a target video in a photo-realistic fashion more accurately than state-of-the-art methods.
Large Scale Photometric Bundle Adjustment
Sep 10, 2020
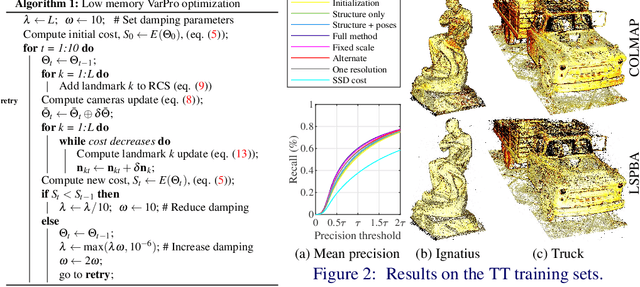

Direct methods have shown promise on visual odometry and SLAM, leading to greater accuracy and robustness over feature-based methods. However, offline 3-d reconstruction from internet images has not yet benefited from a joint, photometric optimization over dense geometry and camera parameters. Issues such as the lack of brightness constancy, and the sheer volume of data, make this a more challenging task. This work presents a framework for jointly optimizing millions of scene points and hundreds of camera poses and intrinsics, using a photometric cost that is invariant to local lighting changes. The improvement in metric reconstruction accuracy that it confers over feature-based bundle adjustment is demonstrated on the large-scale Tanks & Temples benchmark. We further demonstrate qualitative reconstruction improvements on an internet photo collection, with challenging diversity in lighting and camera intrinsics.
Self-Supervised Shadow Removal
Oct 22, 2020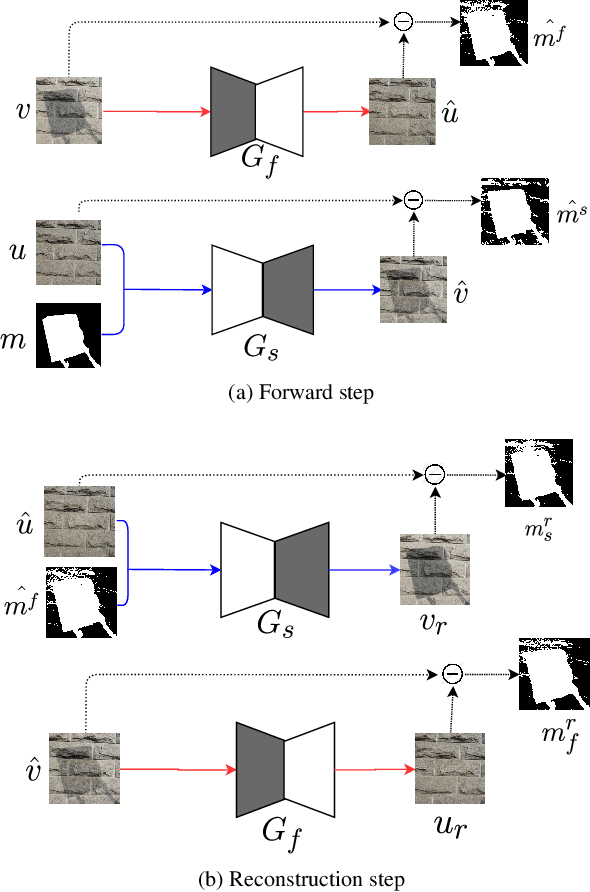



Shadow removal is an important computer vision task aiming at the detection and successful removal of the shadow produced by an occluded light source and a photo-realistic restoration of the image contents. Decades of re-search produced a multitude of hand-crafted restoration techniques and, more recently, learned solutions from shad-owed and shadow-free training image pairs. In this work,we propose an unsupervised single image shadow removal solution via self-supervised learning by using a conditioned mask. In contrast to existing literature, we do not require paired shadowed and shadow-free images, instead we rely on self-supervision and jointly learn deep models to remove and add shadows to images. We validate our approach on the recently introduced ISTD and USR datasets. We largely improve quantitatively and qualitatively over the compared methods and set a new state-of-the-art performance in single image shadow removal.
Photo-Realistic Facial Details Synthesis from Single Immage
Mar 26, 2019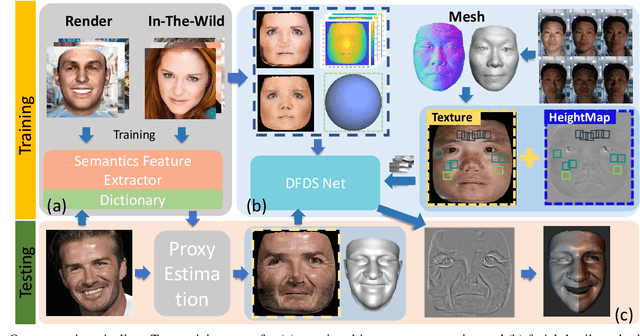

We present a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. Our technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, we conduct emotion prediction to determine a new expression-informed proxy. On detail synthesis, we present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, we capture 366 high-quality 3D scans from 122 different subjects under 3 facial expressions. For appearance, we use additional 20K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that our framework can produce high-quality 3D faces with realistic details under challenging facial expressions.