 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
Face Destylization
Feb 05, 2018
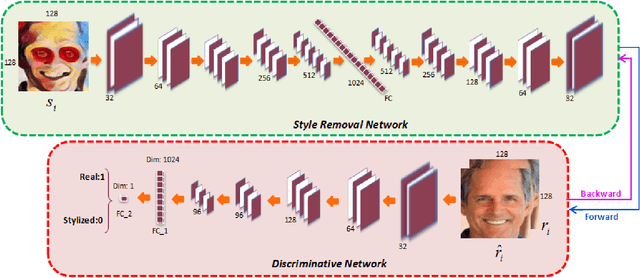


Numerous style transfer methods which produce artistic styles of portraits have been proposed to date. However, the inverse problem of converting the stylized portraits back into realistic faces is yet to be investigated thoroughly. Reverting an artistic portrait to its original photo-realistic face image has potential to facilitate human perception and identity analysis. In this paper, we propose a novel Face Destylization Neural Network (FDNN) to restore the latent photo-realistic faces from the stylized ones. We develop a Style Removal Network composed of convolutional, fully-connected and deconvolutional layers. The convolutional layers are designed to extract facial components from stylized face images. Consecutively, the fully-connected layer transfers the extracted feature maps of stylized images into the corresponding feature maps of real faces and the deconvolutional layers generate real faces from the transferred feature maps. To enforce the destylized faces to be similar to authentic face images, we employ a discriminative network, which consists of convolutional and fully connected layers. We demonstrate the effectiveness of our network by conducting experiments on an extensive set of synthetic images. Furthermore, we illustrate our network can recover faces from stylized portraits and real paintings for which the stylized data was unavailable during the training phase.
Generative Semantic Manipulation with Contrasting GAN
Aug 01, 2017Generative Adversarial Networks (GANs) have recently achieved significant improvement on paired/unpaired image-to-image translation, such as photo$\rightarrow$ sketch and artist painting style transfer. However, existing models can only be capable of transferring the low-level information (e.g. color or texture changes), but fail to edit high-level semantic meanings (e.g., geometric structure or content) of objects. On the other hand, while some researches can synthesize compelling real-world images given a class label or caption, they cannot condition on arbitrary shapes or structures, which largely limits their application scenarios and interpretive capability of model results. In this work, we focus on a more challenging semantic manipulation task, which aims to modify the semantic meaning of an object while preserving its own characteristics (e.g. viewpoints and shapes), such as cow$\rightarrow$sheep, motor$\rightarrow$ bicycle, cat$\rightarrow$dog. To tackle such large semantic changes, we introduce a contrasting GAN (contrast-GAN) with a novel adversarial contrasting objective. Instead of directly making the synthesized samples close to target data as previous GANs did, our adversarial contrasting objective optimizes over the distance comparisons between samples, that is, enforcing the manipulated data be semantically closer to the real data with target category than the input data. Equipped with the new contrasting objective, a novel mask-conditional contrast-GAN architecture is proposed to enable disentangle image background with object semantic changes. Experiments on several semantic manipulation tasks on ImageNet and MSCOCO dataset show considerable performance gain by our contrast-GAN over other conditional GANs. Quantitative results further demonstrate the superiority of our model on generating manipulated results with high visual fidelity and reasonable object semantics.
Fashioning with Networks: Neural Style Transfer to Design Clothes
Jul 31, 2017
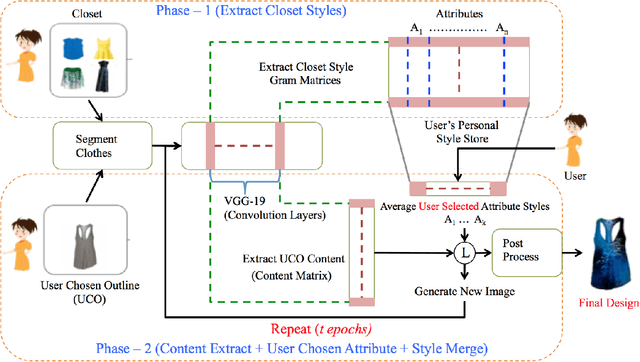
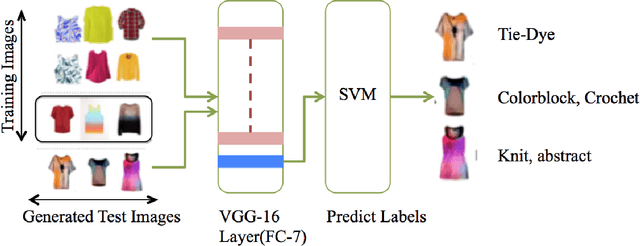

Convolutional Neural Networks have been highly successful in performing a host of computer vision tasks such as object recognition, object detection, image segmentation and texture synthesis. In 2015, Gatys et. al [7] show how the style of a painter can be extracted from an image of the painting and applied to another normal photograph, thus recreating the photo in the style of the painter. The method has been successfully applied to a wide range of images and has since spawned multiple applications and mobile apps. In this paper, the neural style transfer algorithm is applied to fashion so as to synthesize new custom clothes. We construct an approach to personalize and generate new custom clothes based on a users preference and by learning the users fashion choices from a limited set of clothes from their closet. The approach is evaluated by analyzing the generated images of clothes and how well they align with the users fashion style.
Content Aware Neural Style Transfer
Jan 18, 2016

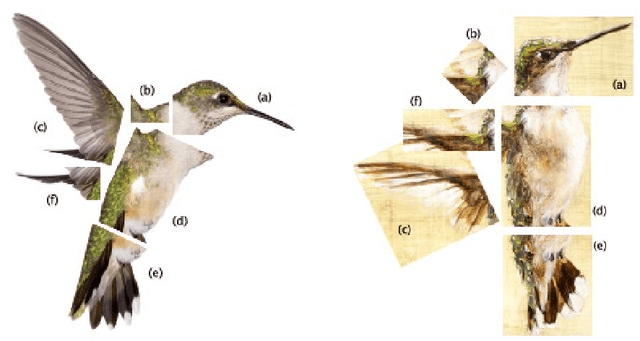

This paper presents a content-aware style transfer algorithm for paintings and photos of similar content using pre-trained neural network, obtaining better results than the previous work. In addition, the numerical experiments show that the style pattern and the content information is not completely separated by neural network.
Visual Attribute Transfer through Deep Image Analogy
Jun 06, 2017

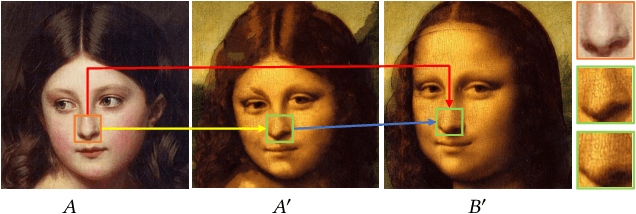

We propose a new technique for visual attribute transfer across images that may have very different appearance but have perceptually similar semantic structure. By visual attribute transfer, we mean transfer of visual information (such as color, tone, texture, and style) from one image to another. For example, one image could be that of a painting or a sketch while the other is a photo of a real scene, and both depict the same type of scene. Our technique finds semantically-meaningful dense correspondences between two input images. To accomplish this, it adapts the notion of "image analogy" with features extracted from a Deep Convolutional Neutral Network for matching; we call our technique Deep Image Analogy. A coarse-to-fine strategy is used to compute the nearest-neighbor field for generating the results. We validate the effectiveness of our proposed method in a variety of cases, including style/texture transfer, color/style swap, sketch/painting to photo, and time lapse.
Learning to Sketch Human Facial Portraits using Personal Styles by Case-Based Reasoning
Sep 13, 2016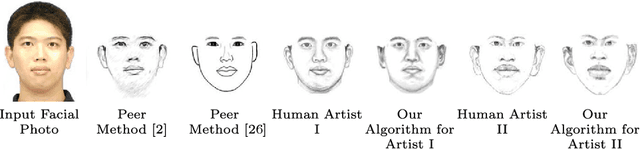
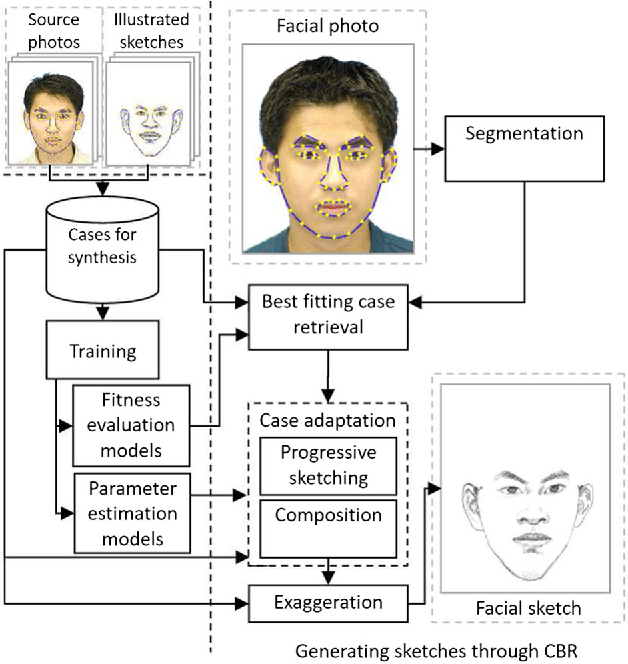
This paper employs case-based reasoning (CBR) to capture the personal styles of individual artists and generate the human facial portraits from photos accordingly. For each human artist to be mimicked, a series of cases are firstly built-up from her/his exemplars of source facial photo and hand-drawn sketch, and then its stylization for facial photo is transformed as a style-transferring process of iterative refinement by looking-for and applying best-fit cases in a sense of style optimization. Two models, fitness evaluation model and parameter estimation model, are learned for case retrieval and adaptation respectively from these cases. The fitness evaluation model is to decide which case is best-fitted to the sketching of current interest, and the parameter estimation model is to automate case adaptation. The resultant sketch is synthesized progressively with an iterative loop of retrieval and adaptation of candidate cases until the desired aesthetic style is achieved. To explore the effectiveness and advantages of the novel approach, we experimentally compare the sketch portraits generated by the proposed method with that of a state-of-the-art example-based facial sketch generation algorithm as well as a couple commercial software packages. The comparisons reveal that our CBR based synthesis method for facial portraits is superior both in capturing and reproducing artists' personal illustration styles to the peer methods.
How to Make an Image More Memorable? A Deep Style Transfer Approach
Apr 06, 2017
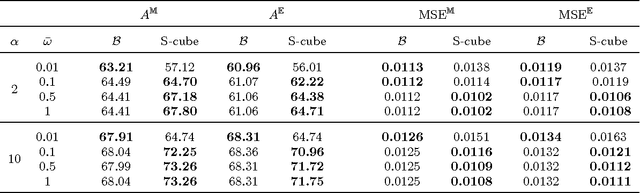
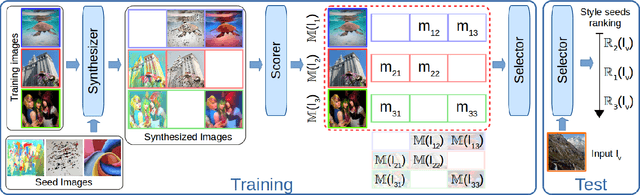
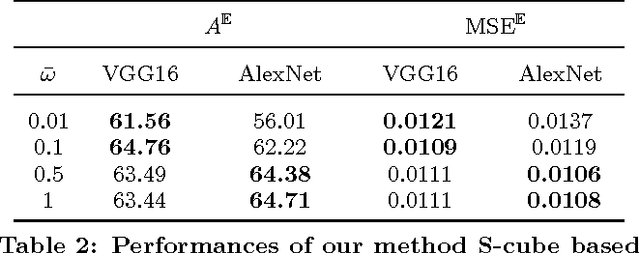
Recent works have shown that it is possible to automatically predict intrinsic image properties like memorability. In this paper, we take a step forward addressing the question: "Can we make an image more memorable?". Methods for automatically increasing image memorability would have an impact in many application fields like education, gaming or advertising. Our work is inspired by the popular editing-by-applying-filters paradigm adopted in photo editing applications, like Instagram and Prisma. In this context, the problem of increasing image memorability maps to that of retrieving "memorabilizing" filters or style "seeds". Still, users generally have to go through most of the available filters before finding the desired solution, thus turning the editing process into a resource and time consuming task. In this work, we show that it is possible to automatically retrieve the best style seeds for a given image, thus remarkably reducing the number of human attempts needed to find a good match. Our approach leverages from recent advances in the field of image synthesis and adopts a deep architecture for generating a memorable picture from a given input image and a style seed. Importantly, to automatically select the best style a novel learning-based solution, also relying on deep models, is proposed. Our experimental evaluation, conducted on publicly available benchmarks, demonstrates the effectiveness of the proposed approach for generating memorable images through automatic style seed selection
Automatic Content-Aware Color and Tone Stylization
Nov 12, 2015



We introduce a new technique that automatically generates diverse, visually compelling stylizations for a photograph in an unsupervised manner. We achieve this by learning style ranking for a given input using a large photo collection and selecting a diverse subset of matching styles for final style transfer. We also propose a novel technique that transfers the global color and tone of the chosen exemplars to the input photograph while avoiding the common visual artifacts produced by the existing style transfer methods. Together, our style selection and transfer techniques produce compelling, artifact-free results on a wide range of input photographs, and a user study shows that our results are preferred over other techniques.
Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks
Apr 15, 2016
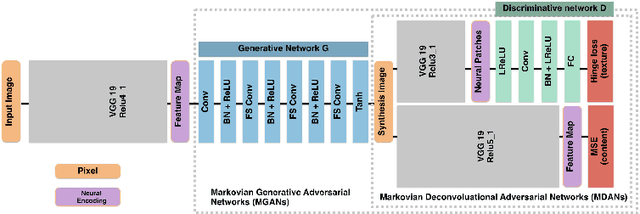


This paper proposes Markovian Generative Adversarial Networks (MGANs), a method for training generative neural networks for efficient texture synthesis. While deep neural network approaches have recently demonstrated remarkable results in terms of synthesis quality, they still come at considerable computational costs (minutes of run-time for low-res images). Our paper addresses this efficiency issue. Instead of a numerical deconvolution in previous work, we precompute a feed-forward, strided convolutional network that captures the feature statistics of Markovian patches and is able to directly generate outputs of arbitrary dimensions. Such network can directly decode brown noise to realistic texture, or photos to artistic paintings. With adversarial training, we obtain quality comparable to recent neural texture synthesis methods. As no optimization is required any longer at generation time, our run-time performance (0.25M pixel images at 25Hz) surpasses previous neural texture synthesizers by a significant margin (at least 500 times faster). We apply this idea to texture synthesis, style transfer, and video stylization.