 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024
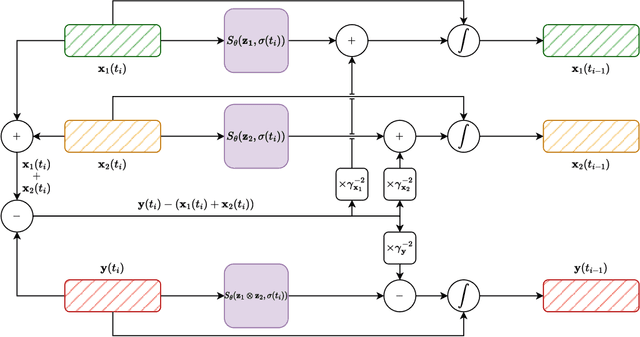
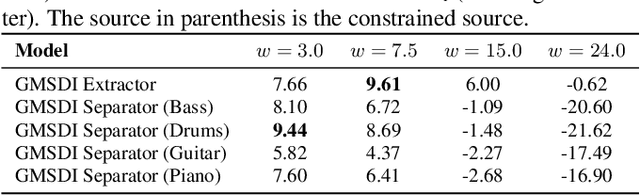
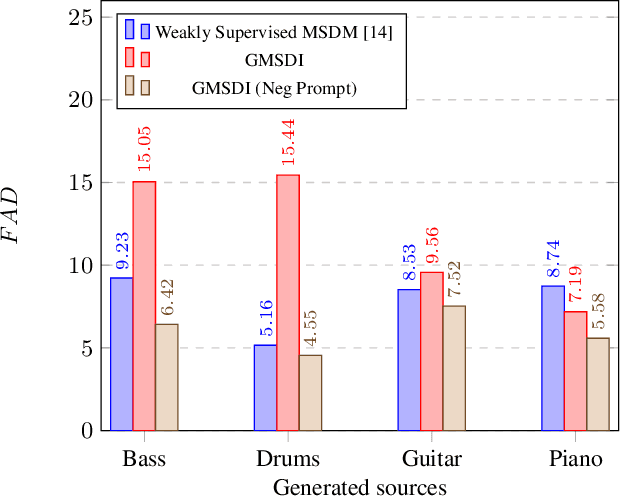
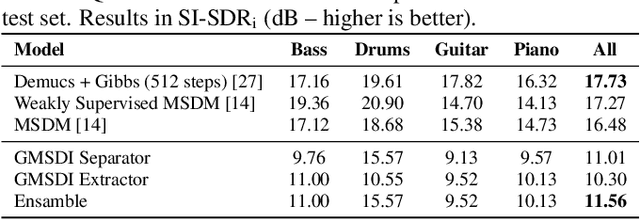
Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
Maximum Likelihood Alternating Summation for Multistatic Angle-based Multitarget Localization
Mar 20, 2024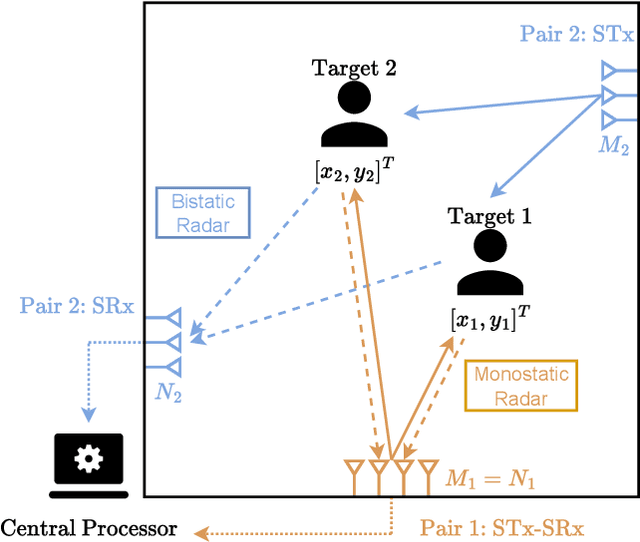
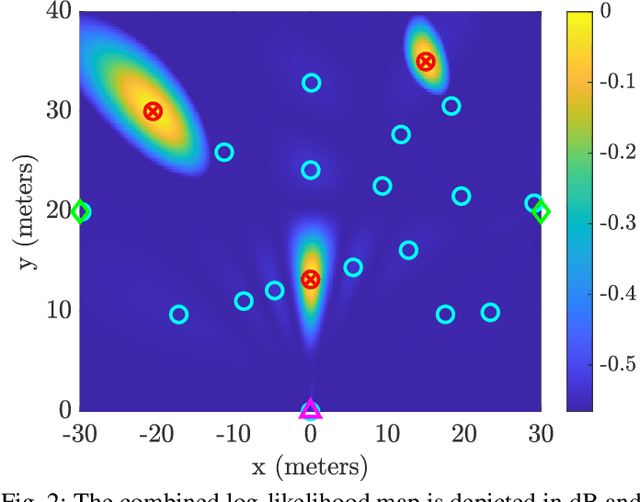
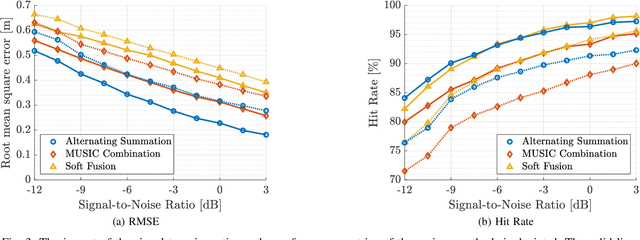
Recent advancements in Wi-Fi sensing have sparked interest in exploiting OFDM modulated communication signals for target detection and tracking. In this study, we address the angle-based localization of multiple targets using a multistatic OFDM radar. While the maximum likelihood approach optimally merges data from each radar pair comprised by the system, it entails a complex multi-dimensional search process. Leveraging pre-estimation of the targets' parameters obtained via the MUSIC algorithm, our method decouples this multi-dimensional search into a single two-dimensional estimator per target. The proposed alternating summation method allows the computation of a combined likelihood map aggregating contributions from each radar pair, enabling target detection via peak selection. Besides reducing computational complexity, the method effectively captures target interactions and accommodates varying radar pair localization abilities. Also, it requires transmitting only the estimated channel covariance matrices of each radar pair to the central processor. Numerical simulations demonstrate superior performance over existing approaches.
Capturing Cancer as Music: Cancer Mechanisms Expressed through Musification
Feb 09, 2024The development of cancer is difficult to express on a simple and intuitive level due to its complexity. Since cancer is so widespread, raising public awareness about its mechanisms can help those affected cope with its realities, as well as inspire others to make lifestyle adjustments and screen for the disease. Unfortunately, studies have shown that cancer literature is too technical for the general public to understand. We found that musification, the process of turning data into music, remains an unexplored avenue for conveying this information. We explore the pedagogical effectiveness of musification through the use of an algorithm that manipulates a piece of music in a manner analogous to the development of cancer. We conducted two lab studies and found that our approach is marginally more effective at promoting cancer literacy when accompanied by a text-based article than text-based articles alone.
Large-Scale Label Interpretation Learning for Few-Shot Named Entity Recognition
Mar 21, 2024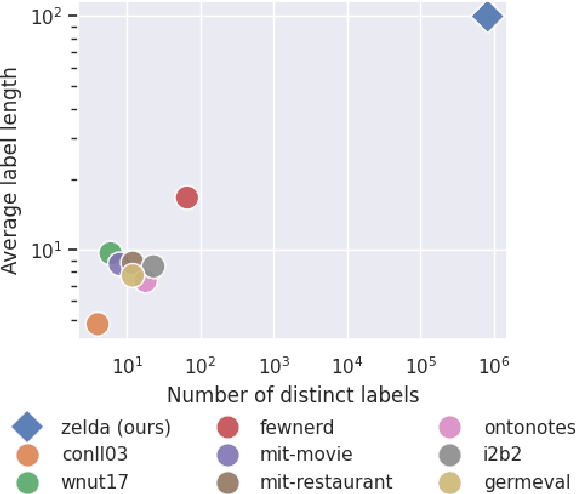
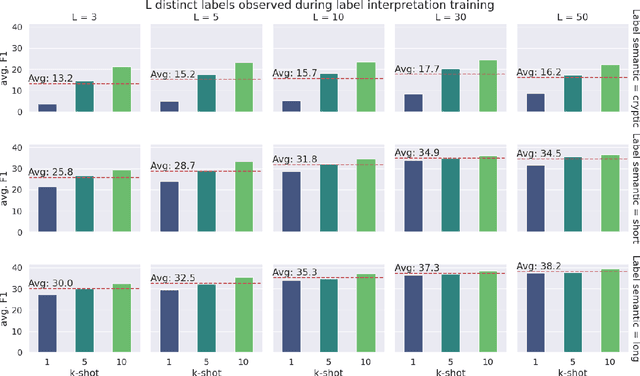
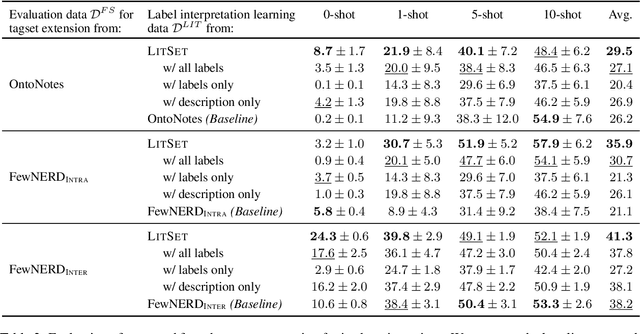
Few-shot named entity recognition (NER) detects named entities within text using only a few annotated examples. One promising line of research is to leverage natural language descriptions of each entity type: the common label PER might, for example, be verbalized as ''person entity.'' In an initial label interpretation learning phase, the model learns to interpret such verbalized descriptions of entity types. In a subsequent few-shot tagset extension phase, this model is then given a description of a previously unseen entity type (such as ''music album'') and optionally a few training examples to perform few-shot NER for this type. In this paper, we systematically explore the impact of a strong semantic prior to interpret verbalizations of new entity types by massively scaling up the number and granularity of entity types used for label interpretation learning. To this end, we leverage an entity linking benchmark to create a dataset with orders of magnitude of more distinct entity types and descriptions as currently used datasets. We find that this increased signal yields strong results in zero- and few-shot NER in in-domain, cross-domain, and even cross-lingual settings. Our findings indicate significant potential for improving few-shot NER through heuristical data-based optimization.
Harmonious Group Choreography with Trajectory-Controllable Diffusion
Mar 10, 2024
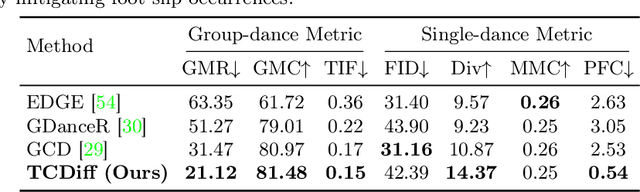
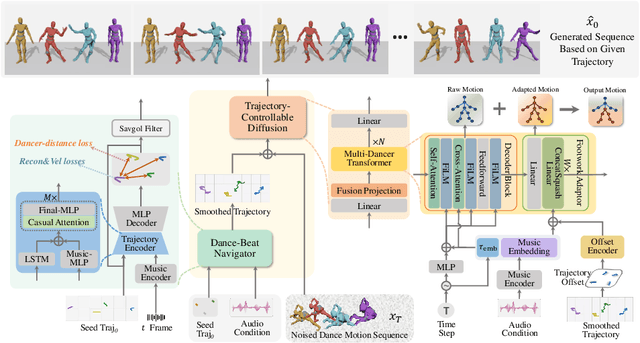
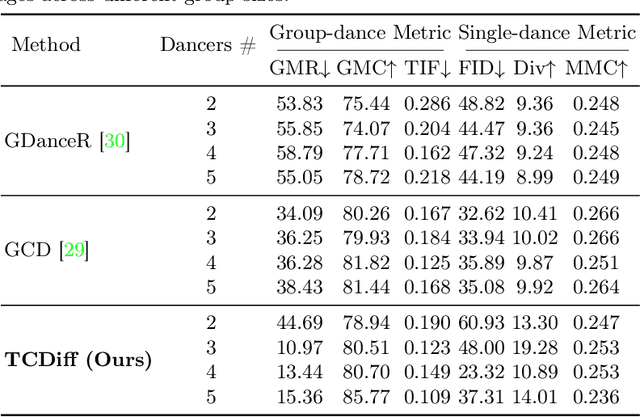
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024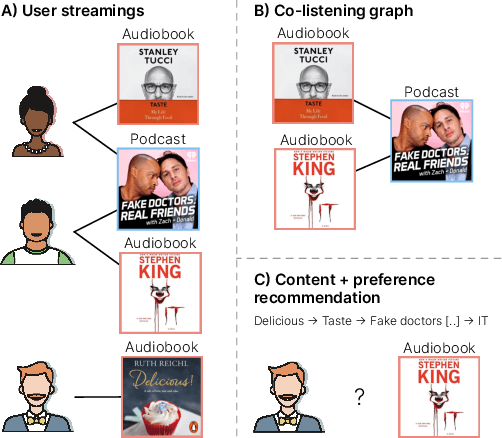
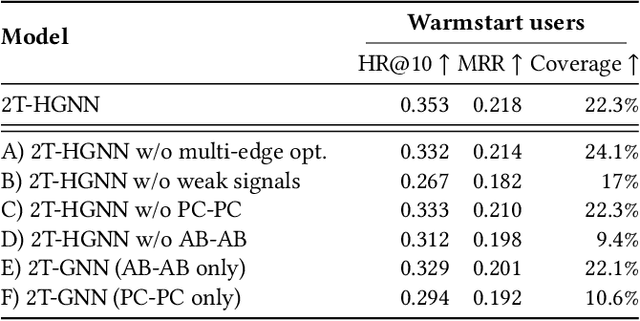
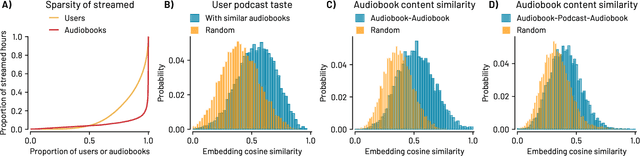
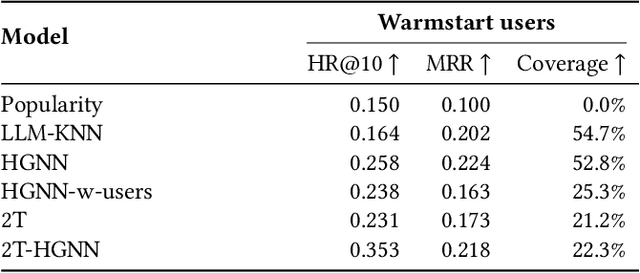
In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Dance-to-Music Generation with Encoder-based Textual Inversion of Diffusion Models
Jan 31, 2024The harmonious integration of music with dance movements is pivotal in vividly conveying the artistic essence of dance. This alignment also significantly elevates the immersive quality of gaming experiences and animation productions. While there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly concentrate on modulating overarching characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique for augmenting text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to the classical textual inversion method, which directly updates text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. To achieve a more accurate evaluation, we propose improved evaluation metrics for rhythm alignment. We demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method seamlessly adapts to in-the-wild data and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Samples are available at \url{https://youtu.be/D7XDwtH1YwE}.
More than words: Advancements and challenges in speech recognition for singing
Mar 14, 2024This paper addresses the challenges and advancements in speech recognition for singing, a domain distinctly different from standard speech recognition. Singing encompasses unique challenges, including extensive pitch variations, diverse vocal styles, and background music interference. We explore key areas such as phoneme recognition, language identification in songs, keyword spotting, and full lyrics transcription. I will describe some of my own experiences when performing research on these tasks just as they were starting to gain traction, but will also show how recent developments in deep learning and large-scale datasets have propelled progress in this field. My goal is to illuminate the complexities of applying speech recognition to singing, evaluate current capabilities, and outline future research directions.
Interactive Melody Generation System for Enhancing the Creativity of Musicians
Mar 06, 2024

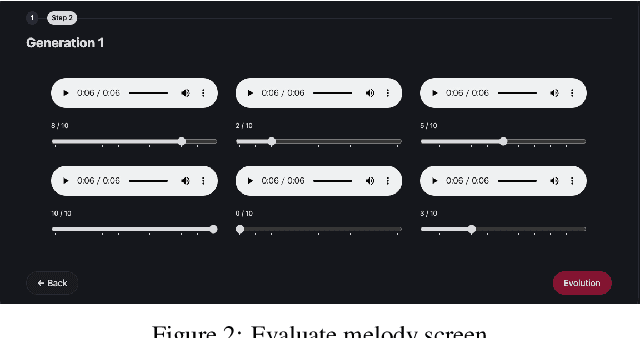
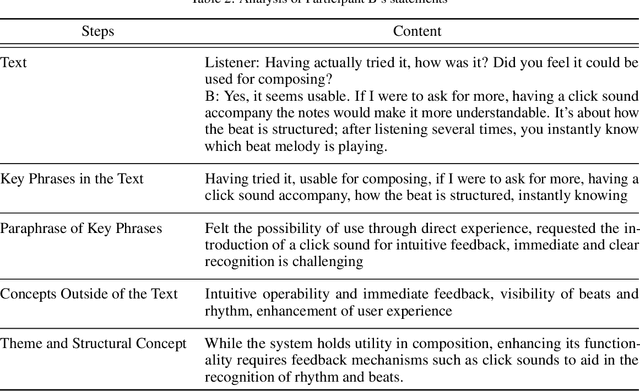
This study proposes a system designed to enumerate the process of collaborative composition among humans, using automatic music composition technology. By integrating multiple Recurrent Neural Network (RNN) models, the system provides an experience akin to collaborating with several composers, thereby fostering diverse creativity. Through dynamic adaptation to the user's creative intentions, based on feedback, the system enhances its capability to generate melodies that align with user preferences and creative needs. The system's effectiveness was evaluated through experiments with composers of varying backgrounds, revealing its potential to facilitate musical creativity and suggesting avenues for further refinement. The study underscores the importance of interaction between the composer and AI, aiming to make music composition more accessible and personalized. This system represents a step towards integrating AI into the creative process, offering a new tool for composition support and collaborative artistic exploration.
Remixing Music for Hearing Aids Using Ensemble of Fine-Tuned Source Separators
Feb 01, 2024This paper introduces our system submission for the Cadenza ICASSP 2024 Grand Challenge, which presents the problem of remixing and enhancing music for hearing aid users. Our system placed first in the challenge, achieving the best average Hearing-Aid Audio Quality Index (HAAQI) score on the evaluation data set. We describe the system, which uses an ensemble of deep learning music source separators that are fine tuned on the challenge data. We demonstrate the effectiveness of our system through the challenge results and analyze the importance of different system aspects through ablation studies.