 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Repetition for Mitigating Position Bias in LLM-Based Ranking
Jul 23, 2025



When using LLMs to rank items based on given criteria, or evaluate answers, the order of candidate items can influence the model's final decision. This sensitivity to item positioning in a LLM's prompt is known as position bias. Prior research shows that this bias exists even in large models, though its severity varies across models and tasks. In addition to position bias, LLMs also exhibit varying degrees of low repetition consistency, where repeating the LLM call with the same candidate ordering can lead to different rankings. To address both inconsistencies, a common approach is to prompt the model multiple times with different candidate orderings and aggregate the results via majority voting. However, this repetition strategy, significantly increases computational costs. Extending prior findings, we observe that both the direction -- favoring either the earlier or later candidate in the prompt -- and magnitude of position bias across instances vary substantially, even within a single dataset. This observation highlights the need for a per-instance mitigation strategy. To this end, we introduce a dynamic early-stopping method that adaptively determines the number of repetitions required for each instance. Evaluating our approach across three LLMs of varying sizes and on two tasks, namely re-ranking and alignment, we demonstrate that transitioning to a dynamic repetition strategy reduces the number of LLM calls by an average of 81%, while preserving the accuracy. Furthermore, we propose a confidence-based adaptation to our early-stopping method, reducing LLM calls by an average of 87% compared to static repetition, with only a slight accuracy trade-off relative to our original early-stopping method.
Contextualizing Spotify's Audiobook List Recommendations with Descriptive Shelves
Apr 18, 2025In this paper, we propose a pipeline to generate contextualized list recommendations with descriptive shelves in the domain of audiobooks. By creating several shelves for topics the user has an affinity to, e.g. Uplifting Women's Fiction, we can help them explore their recommendations according to their interests and at the same time recommend a diverse set of items. To do so, we use Large Language Models (LLMs) to enrich each item's metadata based on a taxonomy created for this domain. Then we create diverse descriptive shelves for each user. A/B tests show improvements in user engagement and audiobook discovery metrics, demonstrating benefits for users and content creators.
Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval
Mar 31, 2025



In recent years, Large Language Models (LLMs) have enabled users to provide highly specific music recommendation requests using natural language prompts (e.g. "Can you recommend some old classics for slow dancing?"). In this setup, the recommended tracks are predicted by the LLM in an autoregressive way, i.e. the LLM generates the track titles one token at a time. While intuitive, this approach has several limitation. First, it is based on a general purpose tokenization that is optimized for words rather than for track titles. Second, it necessitates an additional entity resolution layer that matches the track title to the actual track identifier. Third, the number of decoding steps scales linearly with the length of the track title, slowing down inference. In this paper, we propose to address the task of prompt-based music recommendation as a generative retrieval task. Within this setting, we introduce novel, effective, and efficient representations of track identifiers that significantly outperform commonly used strategies. We introduce Text2Tracks, a generative retrieval model that learns a mapping from a user's music recommendation prompt to the relevant track IDs directly. Through an offline evaluation on a dataset of playlists with language inputs, we find that (1) the strategy to create IDs for music tracks is the most important factor for the effectiveness of Text2Tracks and semantic IDs significantly outperform commonly used strategies that rely on song titles as identifiers (2) provided with the right choice of track identifiers, Text2Tracks outperforms sparse and dense retrieval solutions trained to retrieve tracks from language prompts.
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
Oct 22, 2024



Generative retrieval for search and recommendation is a promising paradigm for retrieving items, offering an alternative to traditional methods that depend on external indexes and nearest-neighbor searches. Instead, generative models directly associate inputs with item IDs. Given the breakthroughs of Large Language Models (LLMs), these generative systems can play a crucial role in centralizing a variety of Information Retrieval (IR) tasks in a single model that performs tasks such as query understanding, retrieval, recommendation, explanation, re-ranking, and response generation. Despite the growing interest in such a unified generative approach for IR systems, the advantages of using a single, multi-task model over multiple specialized models are not well established in the literature. This paper investigates whether and when such a unified approach can outperform task-specific models in the IR tasks of search and recommendation, broadly co-existing in multiple industrial online platforms, such as Spotify, YouTube, and Netflix. Previous work shows that (1) the latent representations of items learned by generative recommenders are biased towards popularity, and (2) content-based and collaborative-filtering-based information can improve an item's representations. Motivated by this, our study is guided by two hypotheses: [H1] the joint training regularizes the estimation of each item's popularity, and [H2] the joint training regularizes the item's latent representations, where search captures content-based aspects of an item and recommendation captures collaborative-filtering aspects. Our extensive experiments with both simulated and real-world data support both [H1] and [H2] as key contributors to the effectiveness improvements observed in the unified search and recommendation generative models over the single-task approaches.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Improving Content Retrievability in Search with Controllable Query Generation
Mar 21, 2023An important goal of online platforms is to enable content discovery, i.e. allow users to find a catalog entity they were not familiar with. A pre-requisite to discover an entity, e.g. a book, with a search engine is that the entity is retrievable, i.e. there are queries for which the system will surface such entity in the top results. However, machine-learned search engines have a high retrievability bias, where the majority of the queries return the same entities. This happens partly due to the predominance of narrow intent queries, where users create queries using the title of an already known entity, e.g. in book search 'harry potter'. The amount of broad queries where users want to discover new entities, e.g. in music search 'chill lyrical electronica with an atmospheric feeling to it', and have a higher tolerance to what they might find, is small in comparison. We focus here on two factors that have a negative impact on the retrievability of the entities (I) the training data used for dense retrieval models and (II) the distribution of narrow and broad intent queries issued in the system. We propose CtrlQGen, a method that generates queries for a chosen underlying intent-narrow or broad. We can use CtrlQGen to improve factor (I) by generating training data for dense retrieval models comprised of diverse synthetic queries. CtrlQGen can also be used to deal with factor (II) by suggesting queries with broader intents to users. Our results on datasets from the domains of music, podcasts, and books reveal that we can significantly decrease the retrievability bias of a dense retrieval model when using CtrlQGen. First, by using the generated queries as training data for dense models we make 9% of the entities retrievable (go from zero to non-zero retrievability). Second, by suggesting broader queries to users, we can make 12% of the entities retrievable in the best case.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021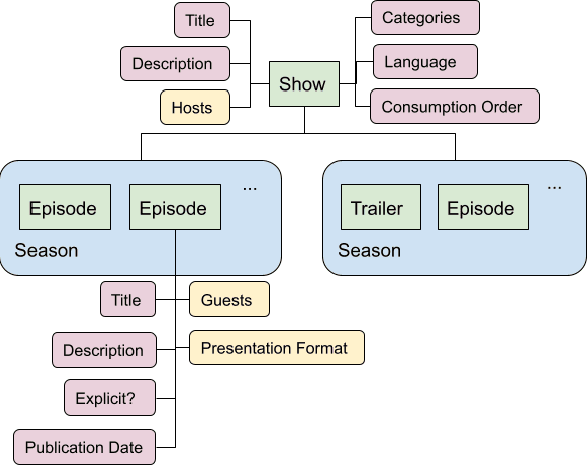
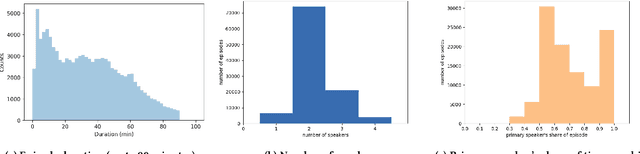
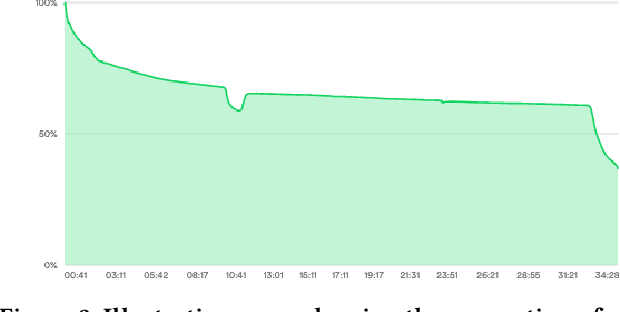
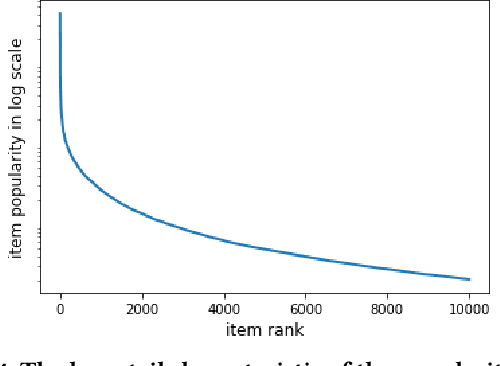
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.