 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
CLAP: Learning Audio Concepts From Natural Language Supervision
Jun 09, 2022
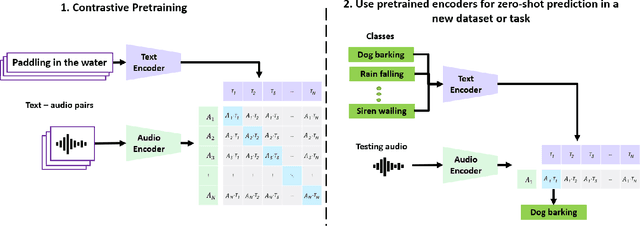
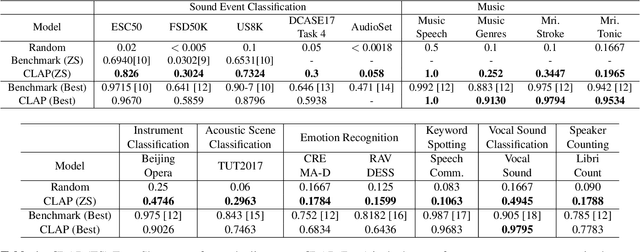
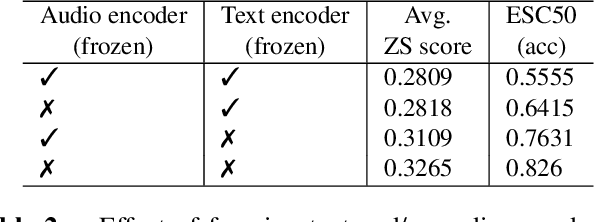
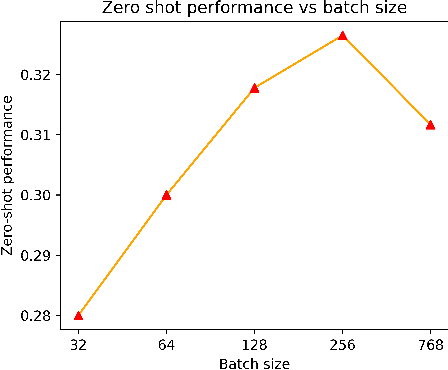
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for training and can only predict the predefined categories. Instead, we propose to learn audio concepts from natural language supervision. We call our approach Contrastive Language-Audio Pretraining (CLAP), which learns to connect language and audio by using two encoders and a contrastive learning to bring audio and text descriptions into a joint multimodal space. We trained CLAP with 128k audio and text pairs and evaluated it on 16 downstream tasks across 8 domains, such as Sound Event Classification, Music tasks, and Speech-related tasks. Although CLAP was trained with significantly less pairs than similar computer vision models, it establishes SoTA for Zero-Shot performance. Additionally, we evaluated CLAP in a supervised learning setup and achieve SoTA in 5 tasks. Hence, CLAP's Zero-Shot capability removes the need of training with class labels, enables flexible class prediction at inference time, and generalizes to multiple downstream tasks.
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Jun 09, 2022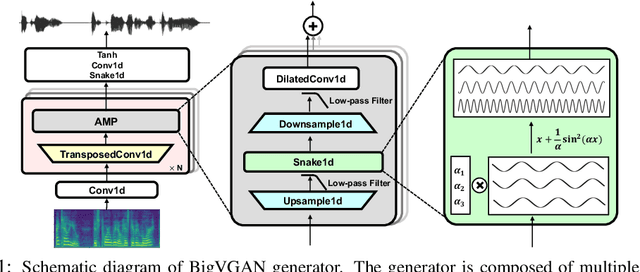

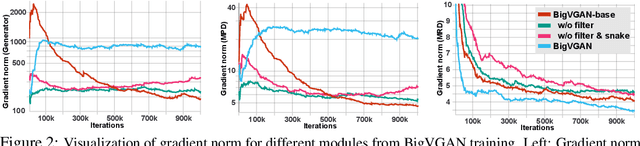

Despite recent progress in generative adversarial network(GAN)-based vocoders, where the model generates raw waveform conditioned on mel spectrogram, it is still challenging to synthesize high-fidelity audio for numerous speakers across varied recording environments. In this work, we present BigVGAN, a universal vocoder that generalizes well under various unseen conditions in zero-shot setting. We introduce periodic nonlinearities and anti-aliased representation into the generator, which brings the desired inductive bias for waveform synthesis and significantly improves audio quality. Based on our improved generator and the state-of-the-art discriminators, we train our GAN vocoder at the largest scale up to 112M parameters, which is unprecedented in the literature. In particular, we identify and address the training instabilities specific to such scale, while maintaining high-fidelity output without over-regularization. Our BigVGAN achieves the state-of-the-art zero-shot performance for various out-of-distribution scenarios, including new speakers, novel languages, singing voices, music and instrumental audio in unseen (even noisy) recording environments. We will release our code and model at: https://github.com/NVIDIA/BigVGAN
The "Horse'' Inside: Seeking Causes Behind the Behaviours of Music Content Analysis Systems
Jun 09, 2016
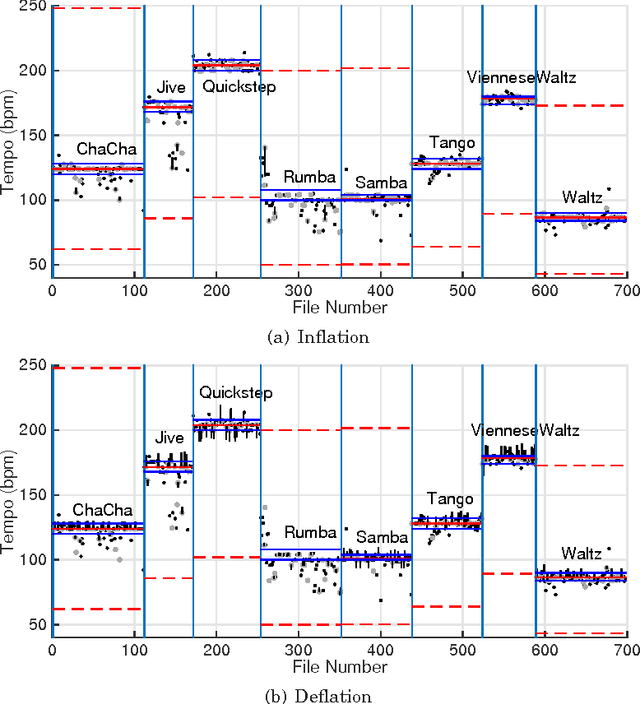
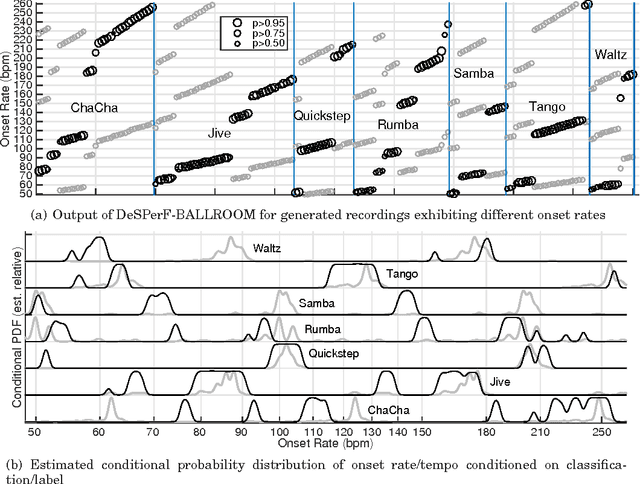
Building systems that possess the sensitivity and intelligence to identify and describe high-level attributes in music audio signals continues to be an elusive goal, but one that surely has broad and deep implications for a wide variety of applications. Hundreds of papers have so far been published toward this goal, and great progress appears to have been made. Some systems produce remarkable accuracies at recognising high-level semantic concepts, such as music style, genre and mood. However, it might be that these numbers do not mean what they seem. In this paper, we take a state-of-the-art music content analysis system and investigate what causes it to achieve exceptionally high performance in a benchmark music audio dataset. We dissect the system to understand its operation, determine its sensitivities and limitations, and predict the kinds of knowledge it could and could not possess about music. We perform a series of experiments to illuminate what the system has actually learned to do, and to what extent it is performing the intended music listening task. Our results demonstrate how the initial manifestation of music intelligence in this state-of-the-art can be deceptive. Our work provides constructive directions toward developing music content analysis systems that can address the music information and creation needs of real-world users.
A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
Nov 19, 2017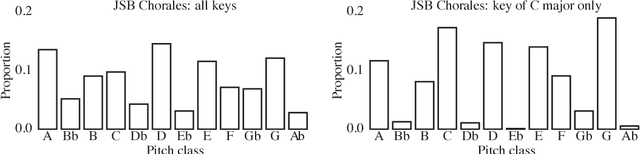
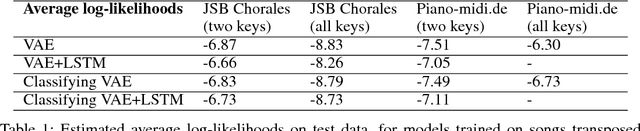
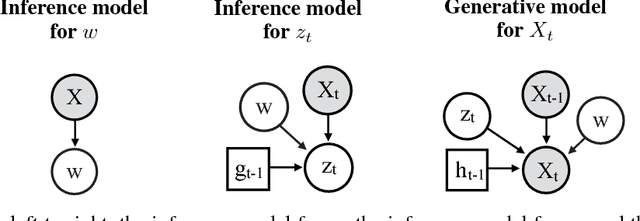
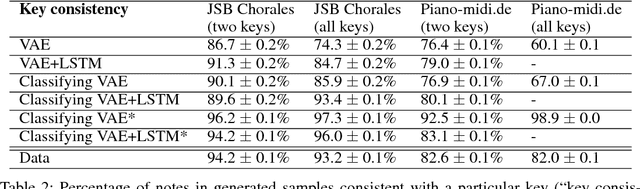
The variational autoencoder (VAE) is a popular probabilistic generative model. However, one shortcoming of VAEs is that the latent variables cannot be discrete, which makes it difficult to generate data from different modes of a distribution. Here, we propose an extension of the VAE framework that incorporates a classifier to infer the discrete class of the modeled data. To model sequential data, we can combine our Classifying VAE with a recurrent neural network such as an LSTM. We apply this model to algorithmic music generation, where our model learns to generate musical sequences in different keys. Most previous work in this area avoids modeling key by transposing data into only one or two keys, as opposed to the 10+ different keys in the original music. We show that our Classifying VAE and Classifying VAE+LSTM models outperform the corresponding non-classifying models in generating musical samples that stay in key. This benefit is especially apparent when trained on untransposed music data in the original keys.
Deep convolutional neural networks for predominant instrument recognition in polyphonic music
Dec 26, 2016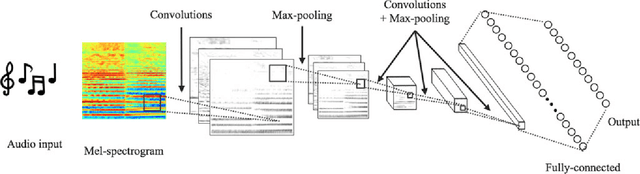
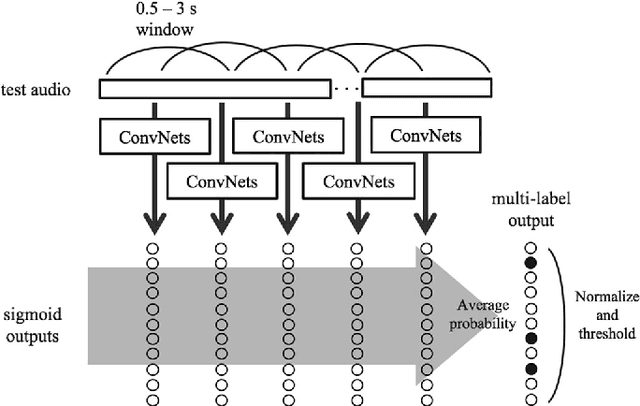
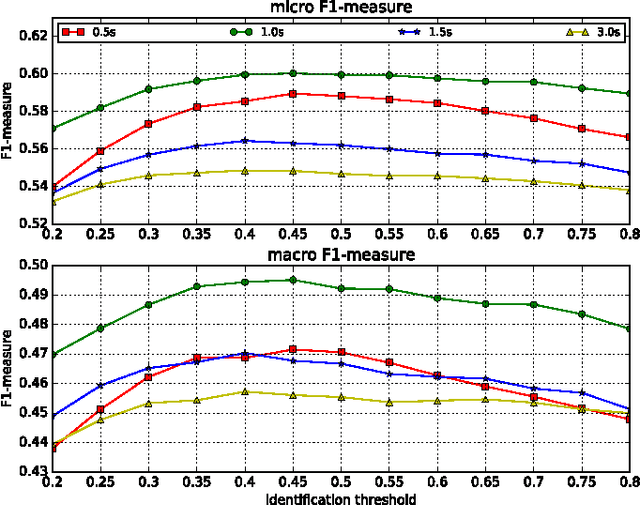
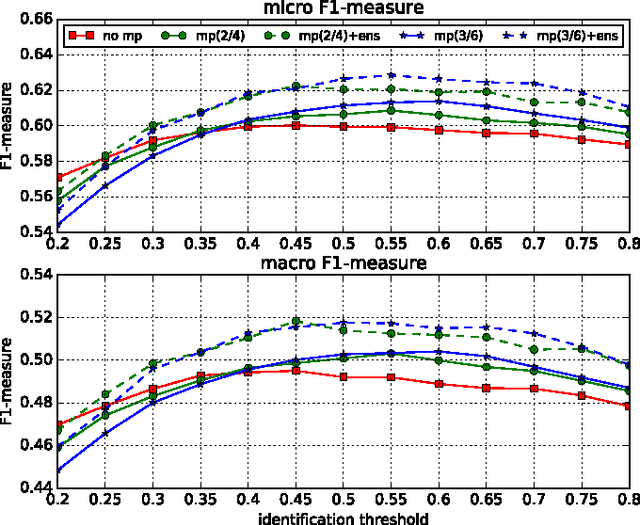
Identifying musical instruments in polyphonic music recordings is a challenging but important problem in the field of music information retrieval. It enables music search by instrument, helps recognize musical genres, or can make music transcription easier and more accurate. In this paper, we present a convolutional neural network framework for predominant instrument recognition in real-world polyphonic music. We train our network from fixed-length music excerpts with a single-labeled predominant instrument and estimate an arbitrary number of predominant instruments from an audio signal with a variable length. To obtain the audio-excerpt-wise result, we aggregate multiple outputs from sliding windows over the test audio. In doing so, we investigated two different aggregation methods: one takes the average for each instrument and the other takes the instrument-wise sum followed by normalization. In addition, we conducted extensive experiments on several important factors that affect the performance, including analysis window size, identification threshold, and activation functions for neural networks to find the optimal set of parameters. Using a dataset of 10k audio excerpts from 11 instruments for evaluation, we found that convolutional neural networks are more robust than conventional methods that exploit spectral features and source separation with support vector machines. Experimental results showed that the proposed convolutional network architecture obtained an F1 measure of 0.602 for micro and 0.503 for macro, respectively, achieving 19.6% and 16.4% in performance improvement compared with other state-of-the-art algorithms.
* 13 pages, 7 figures, accepted for publication in IEEE/ACM Transactions on Audio, Speech, and Language Processing on 16-Nov-2016. This is initial submission version. Fully edited version is available at http://ieeexplore.ieee.org/document/7755799/
Automatic Music Highlight Extraction using Convolutional Recurrent Attention Networks
Dec 16, 2017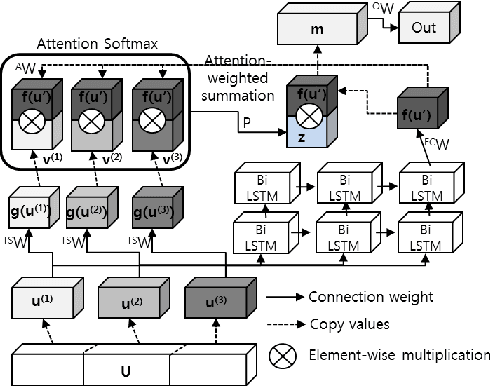
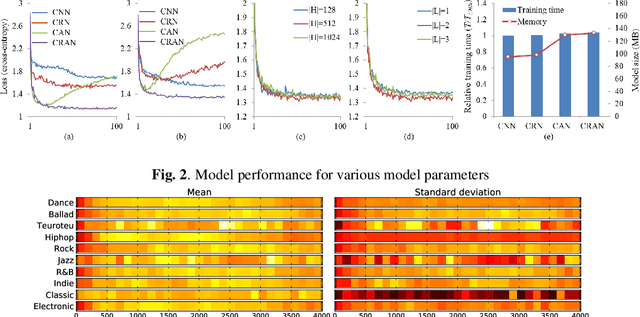
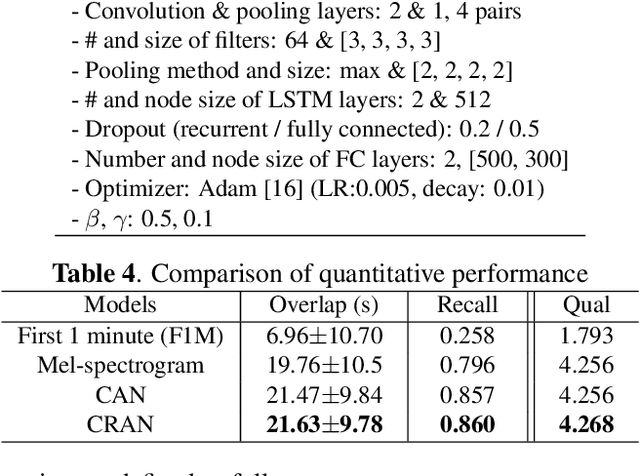
Music highlights are valuable contents for music services. Most methods focused on low-level signal features. We propose a method for extracting highlights using high-level features from convolutional recurrent attention networks (CRAN). CRAN utilizes convolution and recurrent layers for sequential learning with an attention mechanism. The attention allows CRAN to capture significant snippets for distinguishing between genres, thus being used as a high-level feature. CRAN was evaluated on over 32,000 popular tracks in Korea for two months. Experimental results show our method outperforms three baseline methods through quantitative and qualitative evaluations. Also, we analyze the effects of attention and sequence information on performance.
A Critical Look at the Applicability of Markov Logic Networks for Music Signal Analysis
Jan 16, 2020
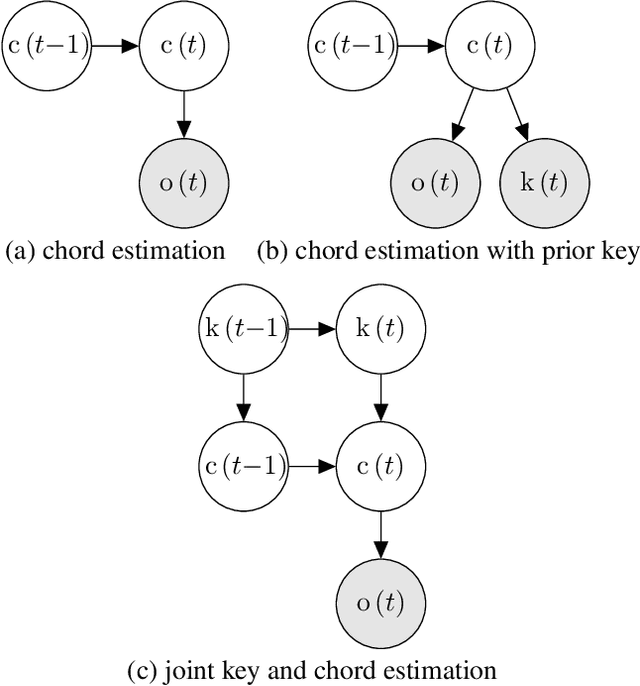
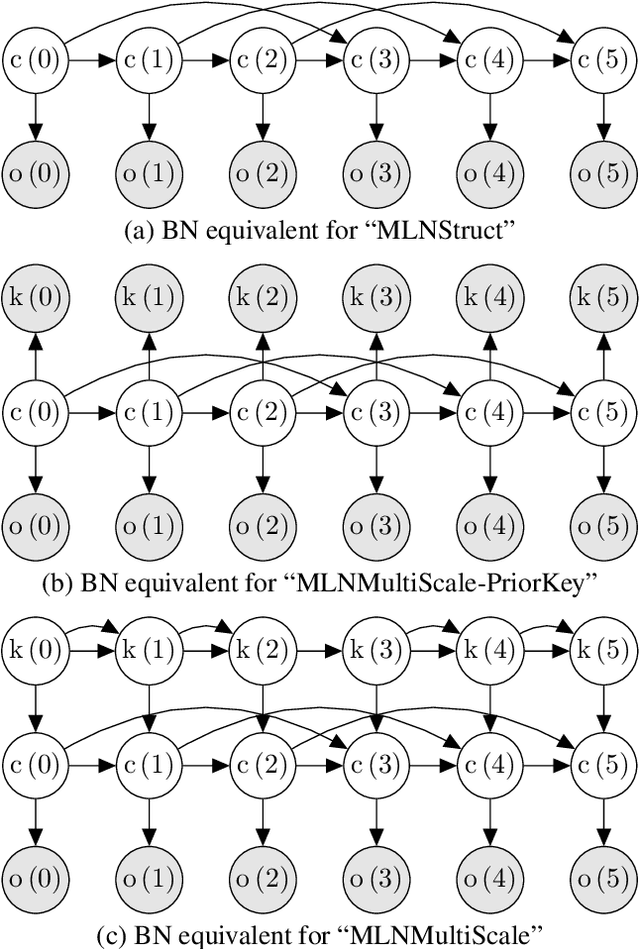
In recent years, Markov logic networks (MLNs) have been proposed as a potentially useful paradigm for music signal analysis. Because all hidden Markov models can be reformulated as MLNs, the latter can provide an all-encompassing framework that reuses and extends previous work in the field. However, just because it is theoretically possible to reformulate previous work as MLNs, does not mean that it is advantageous. In this paper, we analyse some proposed examples of MLNs for musical analysis and consider their practical disadvantages when compared to formulating the same musical dependence relationships as (dynamic) Bayesian networks. We argue that a number of practical hurdles such as the lack of support for sequences and for arbitrary continuous probability distributions make MLNs less than ideal for the proposed musical applications, both in terms of easy of formulation and computational requirements due to their required inference algorithms. These conclusions are not specific to music, but apply to other fields as well, especially when sequential data with continuous observations is involved. Finally, we show that the ideas underlying the proposed examples can be expressed perfectly well in the more commonly used framework of (dynamic) Bayesian networks.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
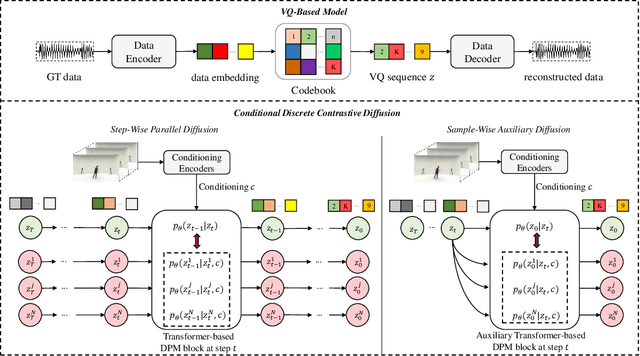

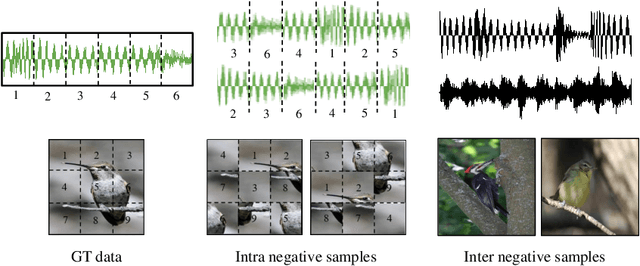
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
Learning a Predictive Model for Music Using PULSE
Sep 26, 2017

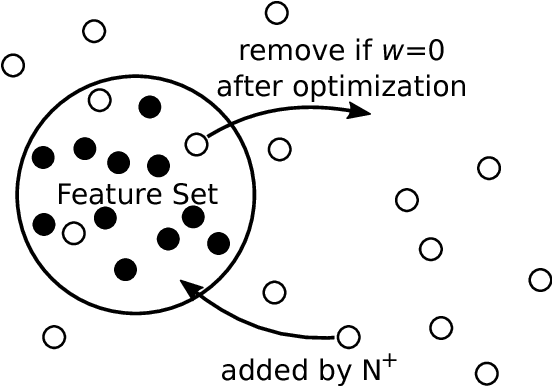
Predictive models for music are studied by researchers of algorithmic composition, the cognitive sciences and machine learning. They serve as base models for composition, can simulate human prediction and provide a multidisciplinary application domain for learning algorithms. A particularly well established and constantly advanced subtask is the prediction of monophonic melodies. As melodies typically involve non-Markovian dependencies their prediction requires a capable learning algorithm. In this thesis, I apply the recent feature discovery and learning method PULSE to the realm of symbolic music modeling. PULSE is comprised of a feature generating operation and L1-regularized optimization. These are used to iteratively expand and cull the feature set, effectively exploring feature spaces that are too large for common feature selection approaches. I design a general Python framework for PULSE, propose task-optimized feature generating operations and various music-theoretically motivated features that are evaluated on a standard corpus of monophonic folk and chorale melodies. The proposed method significantly outperforms comparable state-of-the-art models. I further discuss the free parameters of the learning algorithm and analyze the feature composition of the learned models. The models learned by PULSE afford an easy inspection and are musicologically interpreted for the first time.
A Unit Selection Methodology for Music Generation Using Deep Neural Networks
Dec 12, 2016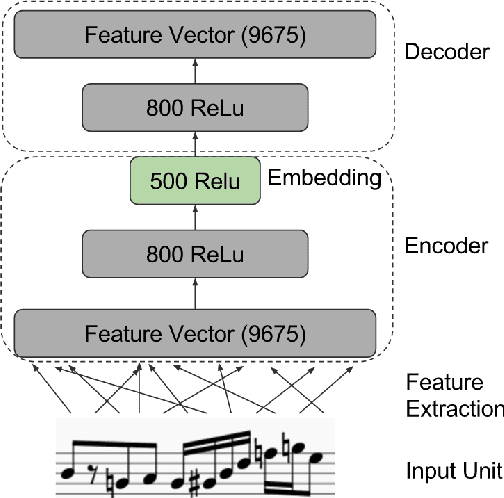
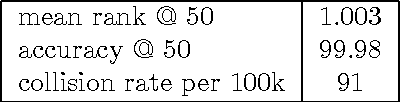

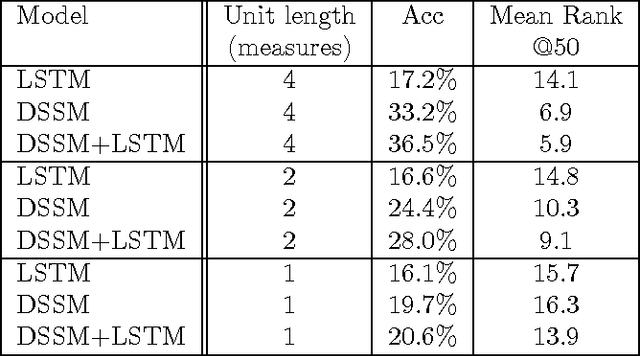
Several methods exist for a computer to generate music based on data including Markov chains, recurrent neural networks, recombinancy, and grammars. We explore the use of unit selection and concatenation as a means of generating music using a procedure based on ranking, where, we consider a unit to be a variable length number of measures of music. We first examine whether a unit selection method, that is restricted to a finite size unit library, can be sufficient for encompassing a wide spectrum of music. We do this by developing a deep autoencoder that encodes a musical input and reconstructs the input by selecting from the library. We then describe a generative model that combines a deep structured semantic model (DSSM) with an LSTM to predict the next unit, where units consist of four, two, and one measures of music. We evaluate the generative model using objective metrics including mean rank and accuracy and with a subjective listening test in which expert musicians are asked to complete a forced-choiced ranking task. We compare our model to a note-level generative baseline that consists of a stacked LSTM trained to predict forward by one note.