 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Can GAN originate new electronic dance music genres? -- Generating novel rhythm patterns using GAN with Genre Ambiguity Loss
Nov 25, 2020
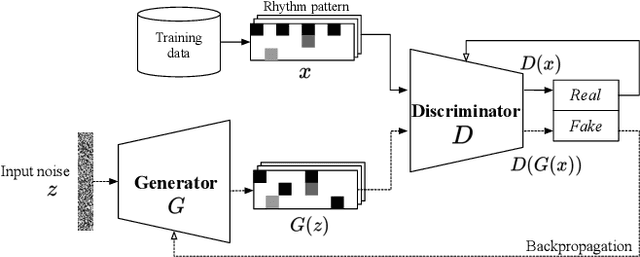

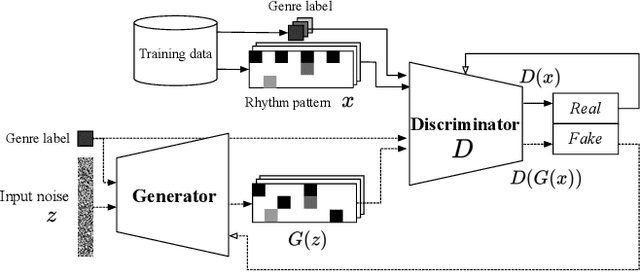
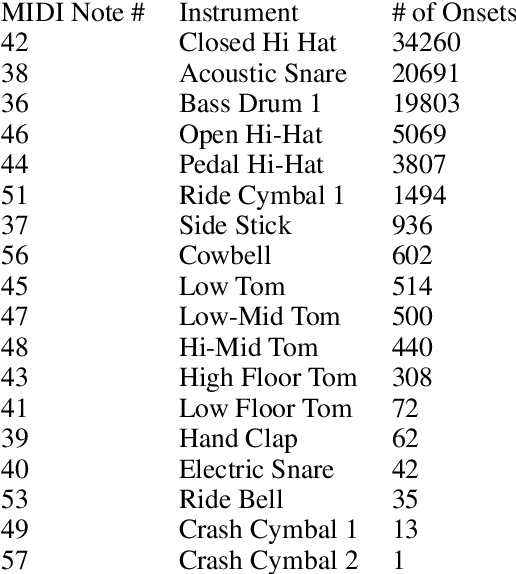
Since the introduction of deep learning, researchers have proposed content generation systems using deep learning and proved that they are competent to generate convincing content and artistic output, including music. However, one can argue that these deep learning-based systems imitate and reproduce the patterns inherent within what humans have created, instead of generating something new and creative. This paper focuses on music generation, especially rhythm patterns of electronic dance music, and discusses if we can use deep learning to generate novel rhythms, interesting patterns not found in the training dataset. We extend the framework of Generative Adversarial Networks(GAN) and encourage it to diverge from the dataset's inherent distributions by adding additional classifiers to the framework. The paper shows that our proposed GAN can generate rhythm patterns that sound like music rhythms but do not belong to any genres in the training dataset. The source code, generated rhythm patterns, and a supplementary plugin software for a popular Digital Audio Workstation software are available on our website.
Modelling Emotion Dynamics in Song Lyrics with State Space Models
Oct 17, 2022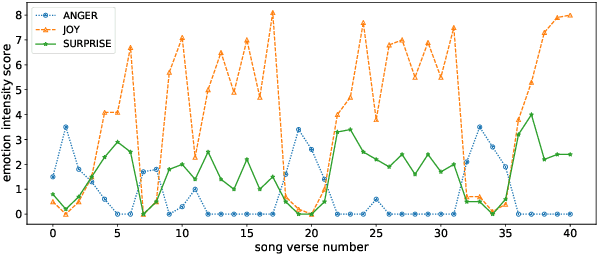
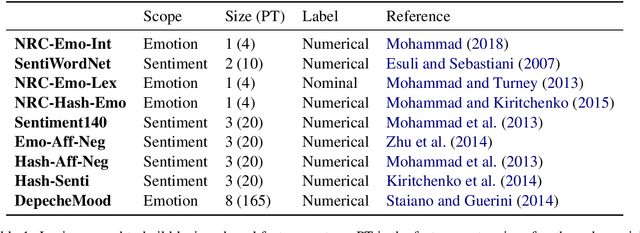
Most previous work in music emotion recognition assumes a single or a few song-level labels for the whole song. While it is known that different emotions can vary in intensity within a song, annotated data for this setup is scarce and difficult to obtain. In this work, we propose a method to predict emotion dynamics in song lyrics without song-level supervision. We frame each song as a time series and employ a State Space Model (SSM), combining a sentence-level emotion predictor with an Expectation-Maximization (EM) procedure to generate the full emotion dynamics. Our experiments show that applying our method consistently improves the performance of sentence-level baselines without requiring any annotated songs, making it ideal for limited training data scenarios. Further analysis through case studies shows the benefits of our method while also indicating the limitations and pointing to future directions.
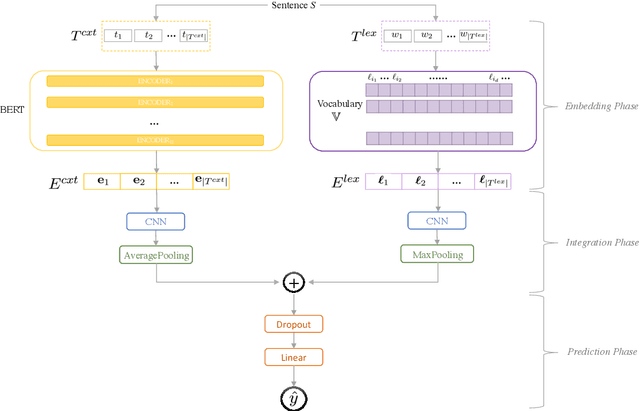
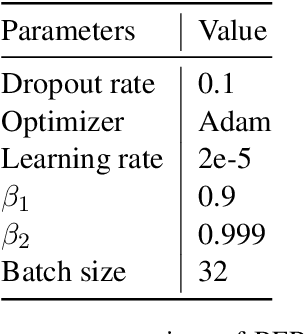
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022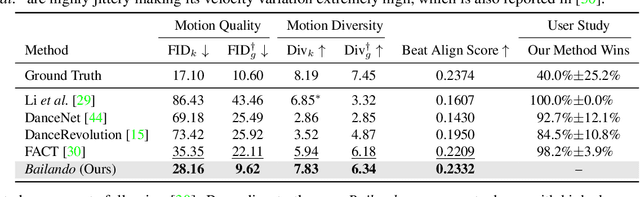
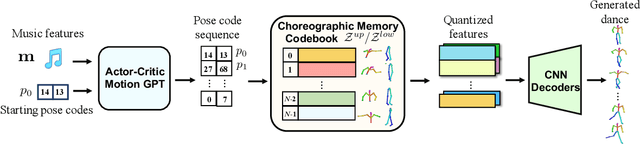
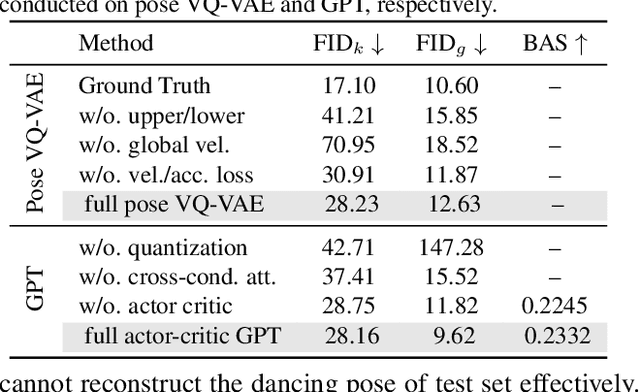
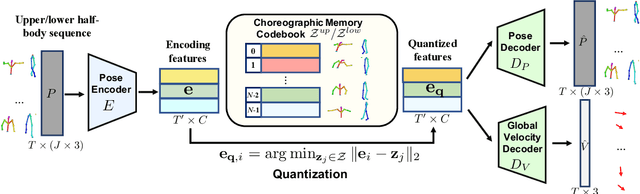
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
ADTOF: A large dataset of non-synthetic music for automatic drum transcription
Nov 23, 2021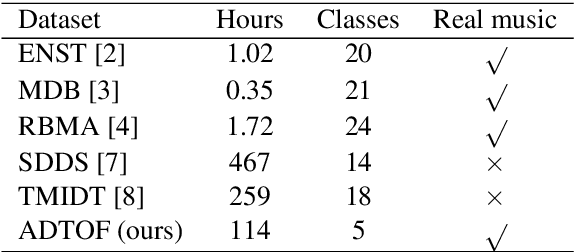

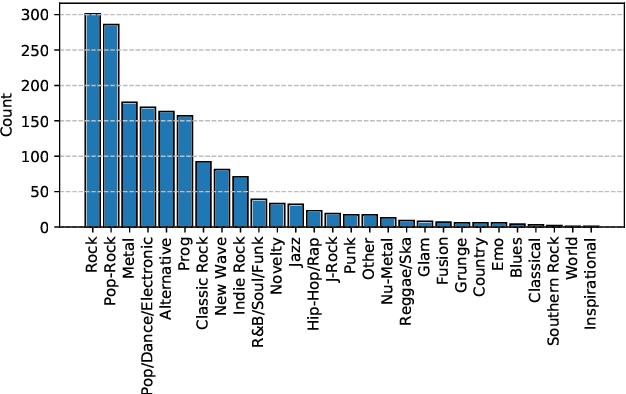
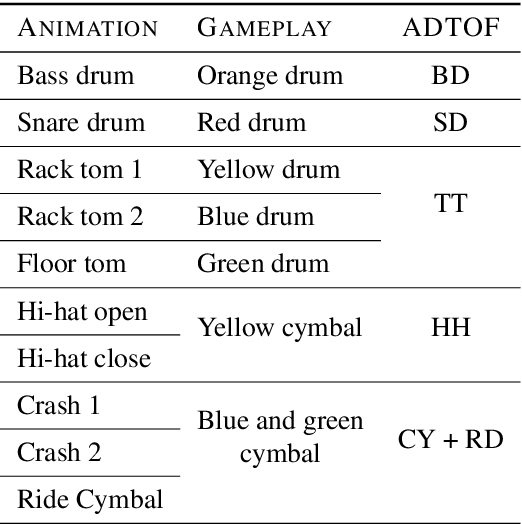
The state-of-the-art methods for drum transcription in the presence of melodic instruments (DTM) are machine learning models trained in a supervised manner, which means that they rely on labeled datasets. The problem is that the available public datasets are limited either in size or in realism, and are thus suboptimal for training purposes. Indeed, the best results are currently obtained via a rather convoluted multi-step training process that involves both real and synthetic datasets. To address this issue, starting from the observation that the communities of rhythm games players provide a large amount of annotated data, we curated a new dataset of crowdsourced drum transcriptions. This dataset contains real-world music, is manually annotated, and is about two orders of magnitude larger than any other non-synthetic dataset, making it a prime candidate for training purposes. However, due to crowdsourcing, the initial annotations contain mistakes. We discuss how the quality of the dataset can be improved by automatically correcting different types of mistakes. When used to train a popular DTM model, the dataset yields a performance that matches that of the state-of-the-art for DTM, thus demonstrating the quality of the annotations.
Deep Watershed Detector for Music Object Recognition
May 26, 2018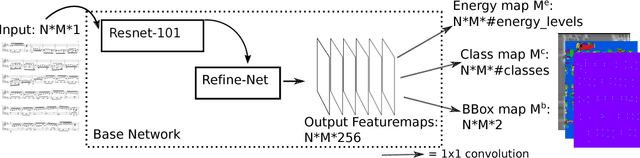
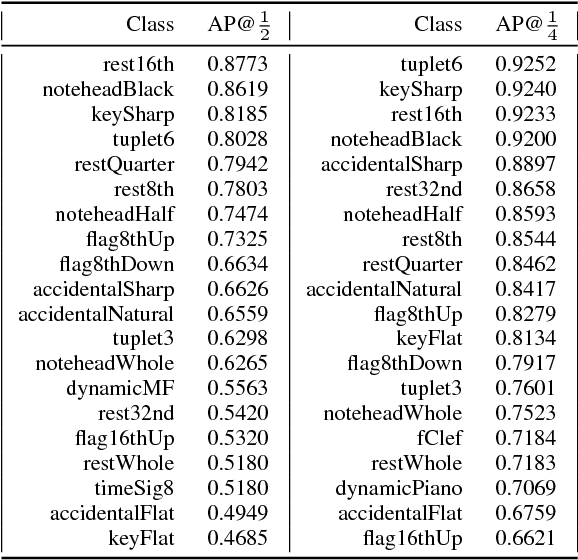
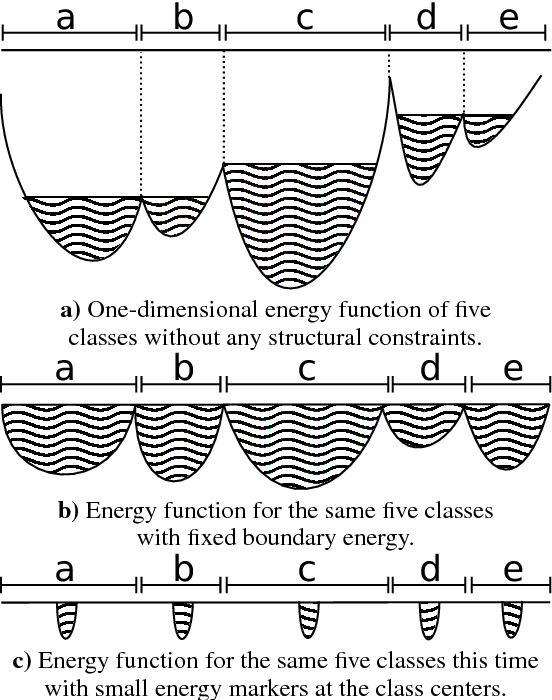
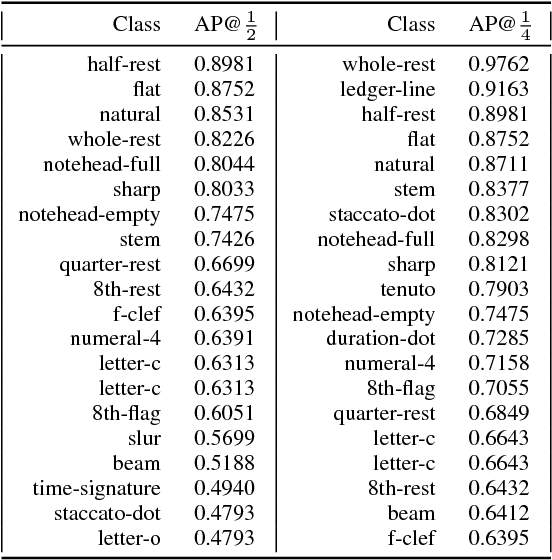
Optical Music Recognition (OMR) is an important and challenging area within music information retrieval, the accurate detection of music symbols in digital images is a core functionality of any OMR pipeline. In this paper, we introduce a novel object detection method, based on synthetic energy maps and the watershed transform, called Deep Watershed Detector (DWD). Our method is specifically tailored to deal with high resolution images that contain a large number of very small objects and is therefore able to process full pages of written music. We present state-of-the-art detection results of common music symbols and show DWD's ability to work with synthetic scores equally well as on handwritten music.
CLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos
Dec 14, 2022
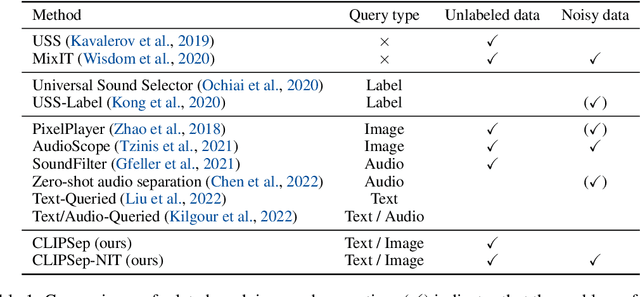
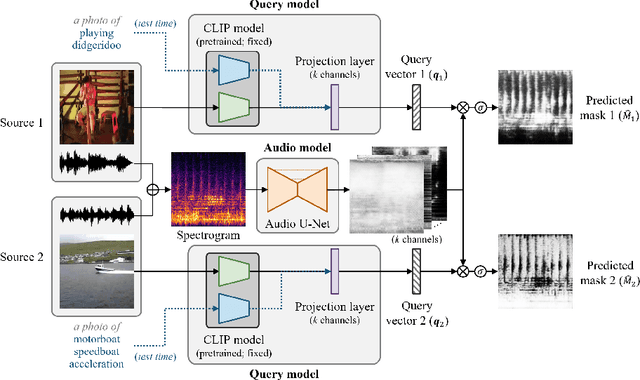
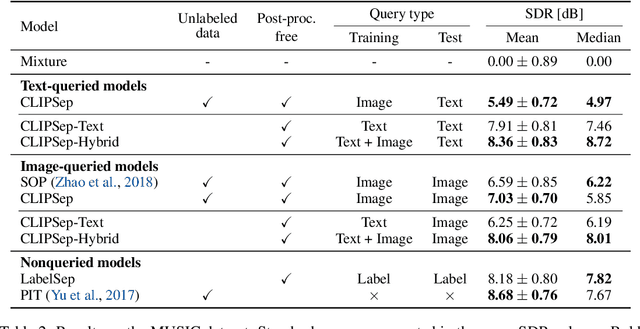
Recent years have seen progress beyond domain-specific sound separation for speech or music towards universal sound separation for arbitrary sounds. Prior work on universal sound separation has investigated separating a target sound out of an audio mixture given a text query. Such text-queried sound separation systems provide a natural and scalable interface for specifying arbitrary target sounds. However, supervised text-queried sound separation systems require costly labeled audio-text pairs for training. Moreover, the audio provided in existing datasets is often recorded in a controlled environment, causing a considerable generalization gap to noisy audio in the wild. In this work, we aim to approach text-queried universal sound separation by using only unlabeled data. We propose to leverage the visual modality as a bridge to learn the desired audio-textual correspondence. The proposed CLIPSep model first encodes the input query into a query vector using the contrastive language-image pretraining (CLIP) model, and the query vector is then used to condition an audio separation model to separate out the target sound. While the model is trained on image-audio pairs extracted from unlabeled videos, at test time we can instead query the model with text inputs in a zero-shot setting, thanks to the joint language-image embedding learned by the CLIP model. Further, videos in the wild often contain off-screen sounds and background noise that may hinder the model from learning the desired audio-textual correspondence. To address this problem, we further propose an approach called noise invariant training for training a query-based sound separation model on noisy data. Experimental results show that the proposed models successfully learn text-queried universal sound separation using only noisy unlabeled videos, even achieving competitive performance against a supervised model in some settings.
Computer-Generated Music for Tabletop Role-Playing Games
Aug 16, 2020In this paper we present Bardo Composer, a system to generate background music for tabletop role-playing games. Bardo Composer uses a speech recognition system to translate player speech into text, which is classified according to a model of emotion. Bardo Composer then uses Stochastic Bi-Objective Beam Search, a variant of Stochastic Beam Search that we introduce in this paper, with a neural model to generate musical pieces conveying the desired emotion. We performed a user study with 116 participants to evaluate whether people are able to correctly identify the emotion conveyed in the pieces generated by the system. In our study we used pieces generated for Call of the Wild, a Dungeons and Dragons campaign available on YouTube. Our results show that human subjects could correctly identify the emotion of the generated music pieces as accurately as they were able to identify the emotion of pieces written by humans.
An Initial study on Birdsong Re-synthesis Using Neural Vocoders
Sep 21, 2022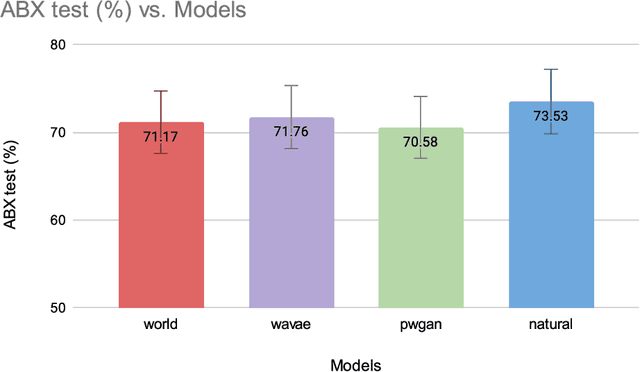
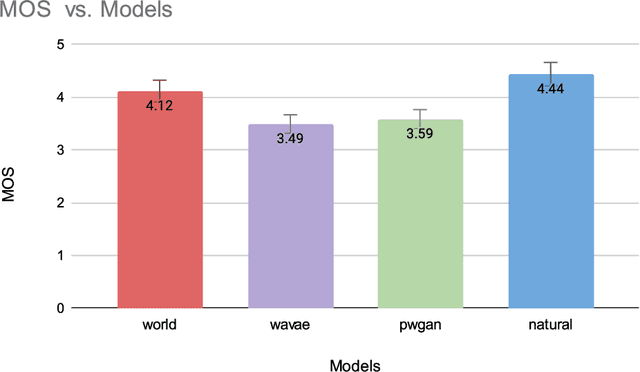
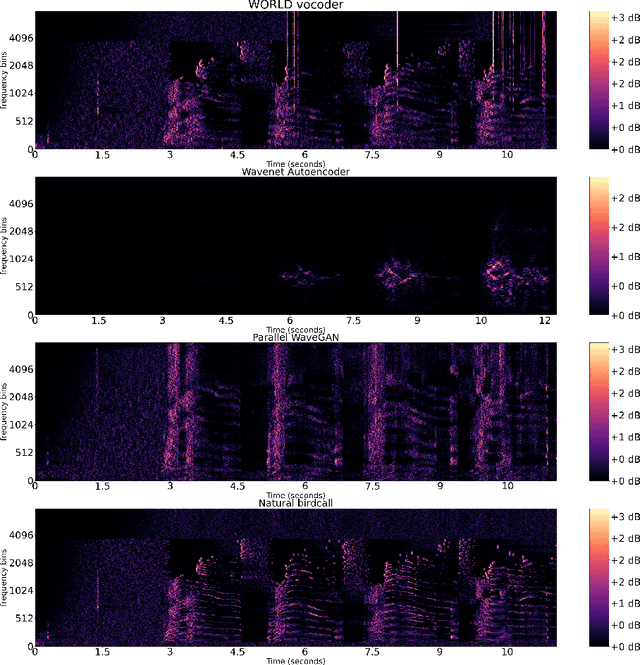
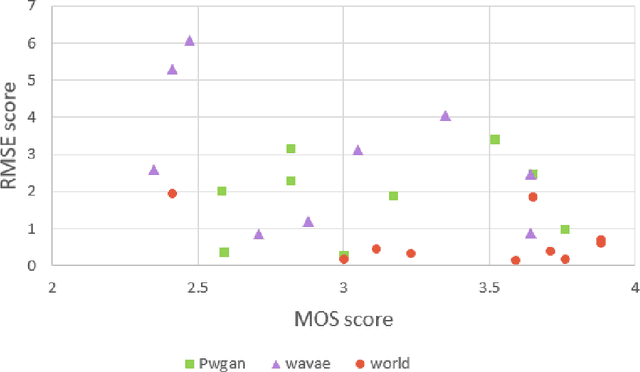
Modern speech synthesis uses neural vocoders to model raw waveform samples directly. This increased versatility has expanded the scope of vocoders from speech to other domains, such as music. We address another interesting domain of bio-acoustics. We provide initial comparative analysis-resynthesis experiments of birdsong using traditional (WORLD) and two neural (WaveNet autoencoder, parallel WaveGAN) vocoders. Our subjective results indicate no difference in the three vocoders in terms of species discrimination (ABX test). Nonetheless, the WORLD vocoder samples were rated higher in terms of retaining bird-like qualities (MOS test). All vocoders faced issues with pitch and voicing. Our results indicate some of the challenges in processing low-quality wildlife audio data.
LSTM Based Music Generation System
Aug 02, 2019
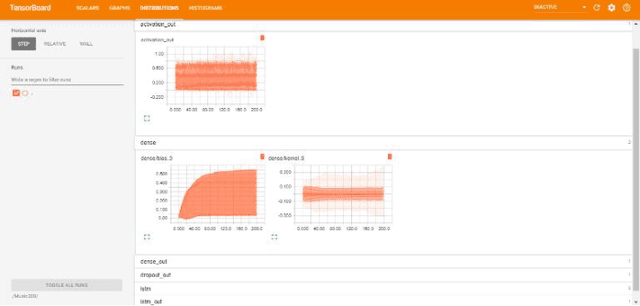
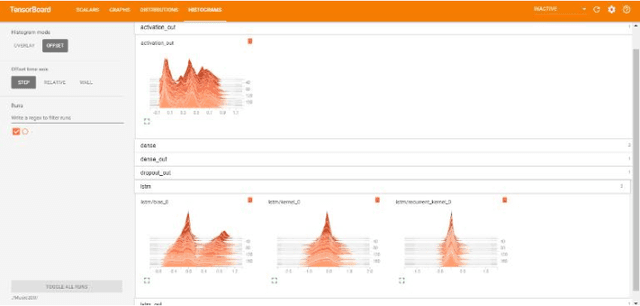
Traditionally, music was treated as an analogue signal and was generated manually. In recent years, music is conspicuous to technology which can generate a suite of music automatically without any human intervention. To accomplish this task, we need to overcome some technical challenges which are discussed descriptively in this paper. A brief introduction about music and its components is provided in the paper along with the citation and analysis of related work accomplished by different authors in this domain. Main objective of this paper is to propose an algorithm which can be used to generate musical notes using Recurrent Neural Networks (RNN), principally Long Short-Term Memory (LSTM) networks. A model is designed to execute this algorithm where data is represented with the help of musical instrument digital interface (MIDI) file format for easier access and better understanding. Preprocessing of data before feeding it into the model, revealing methods to read, process and prepare MIDI files for input are also discussed. The model used in this paper is used to learn the sequences of polyphonic musical notes over a single-layered LSTM network. The model must have the potential to recall past details of a musical sequence and its structure for better learning. Description of layered architecture used in LSTM model and its intertwining connections to develop a neural network is presented in this work. This paper imparts a peek view of distributions of weights and biases in every layer of the model along with a precise representation of losses and accuracy at each step and batches. When the model was thoroughly analyzed, it produced stellar results in composing new melodies.
* 6 pages, 11 figures
Deep Segment Hash Learning for Music Generation
May 30, 2018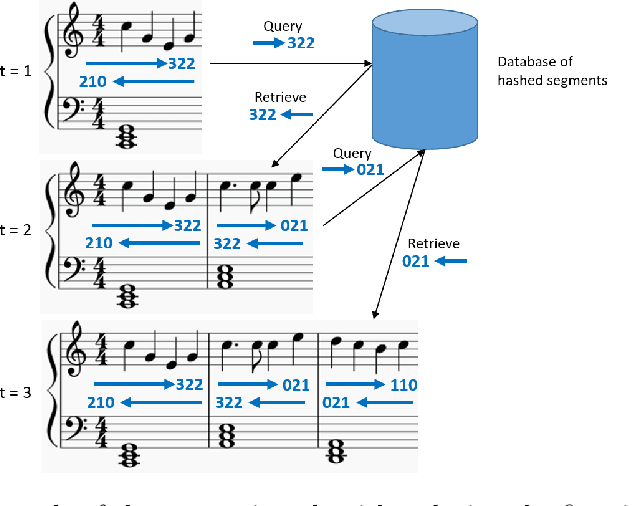
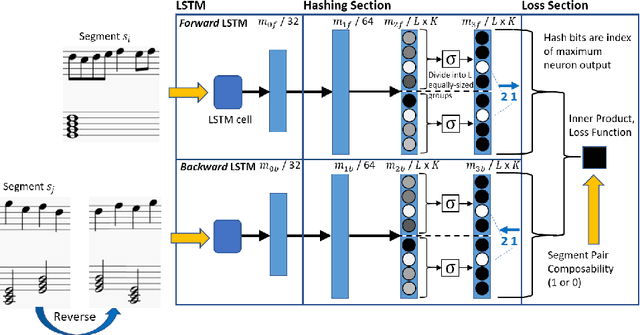
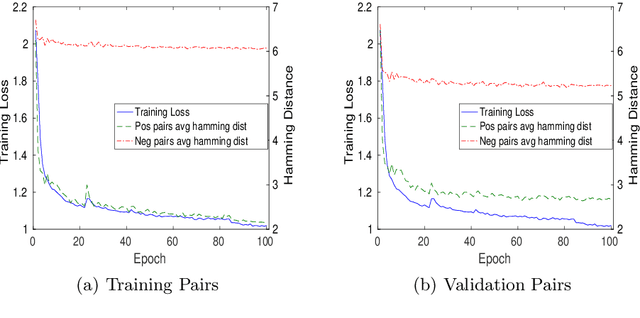

Music generation research has grown in popularity over the past decade, thanks to the deep learning revolution that has redefined the landscape of artificial intelligence. In this paper, we propose a novel approach to music generation inspired by musical segment concatenation methods and hash learning algorithms. Given a segment of music, we use a deep recurrent neural network and ranking-based hash learning to assign a forward hash code to the segment to retrieve candidate segments for continuation with matching backward hash codes. The proposed method is thus called Deep Segment Hash Learning (DSHL). To the best of our knowledge, DSHL is the first end-to-end segment hash learning method for music generation, and the first to use pair-wise training with segments of music. We demonstrate that this method is capable of generating music which is both original and enjoyable, and that DSHL offers a promising new direction for music generation research.