 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurn After Reading: Do Multimodal Large Language Models Truly Capture Order of Events in Image Sequences?
Jun 12, 2025This paper introduces the TempVS benchmark, which focuses on temporal grounding and reasoning capabilities of Multimodal Large Language Models (MLLMs) in image sequences. TempVS consists of three main tests (i.e., event relation inference, sentence ordering and image ordering), each accompanied with a basic grounding test. TempVS requires MLLMs to rely on both visual and linguistic modalities to understand the temporal order of events. We evaluate 38 state-of-the-art MLLMs, demonstrating that models struggle to solve TempVS, with a substantial performance gap compared to human capabilities. We also provide fine-grained insights that suggest promising directions for future research. Our TempVS benchmark data and code are available at https://github.com/yjsong22/TempVS.
Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
Aug 12, 2024



Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.
Modelling Emotion Dynamics in Song Lyrics with State Space Models
Oct 17, 2022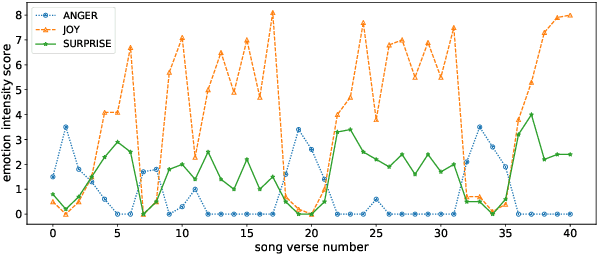
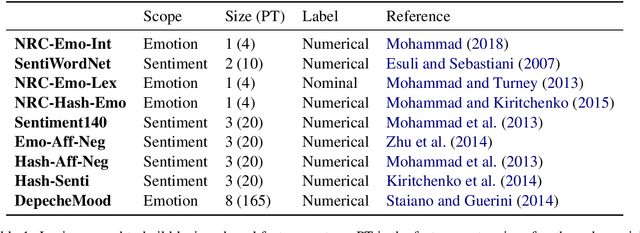
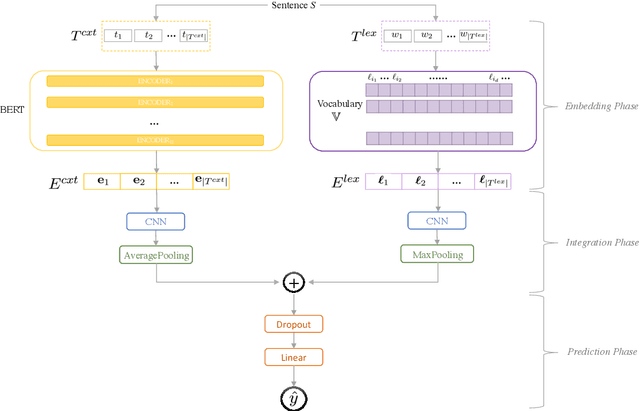
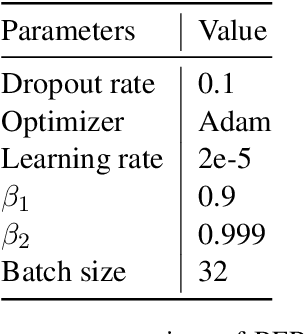
Most previous work in music emotion recognition assumes a single or a few song-level labels for the whole song. While it is known that different emotions can vary in intensity within a song, annotated data for this setup is scarce and difficult to obtain. In this work, we propose a method to predict emotion dynamics in song lyrics without song-level supervision. We frame each song as a time series and employ a State Space Model (SSM), combining a sentence-level emotion predictor with an Expectation-Maximization (EM) procedure to generate the full emotion dynamics. Our experiments show that applying our method consistently improves the performance of sentence-level baselines without requiring any annotated songs, making it ideal for limited training data scenarios. Further analysis through case studies shows the benefits of our method while also indicating the limitations and pointing to future directions.