 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Crossing You in Style: Cross-modal Style Transfer from Music to Visual Arts
Sep 17, 2020

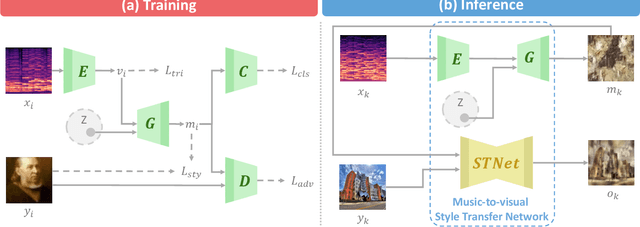

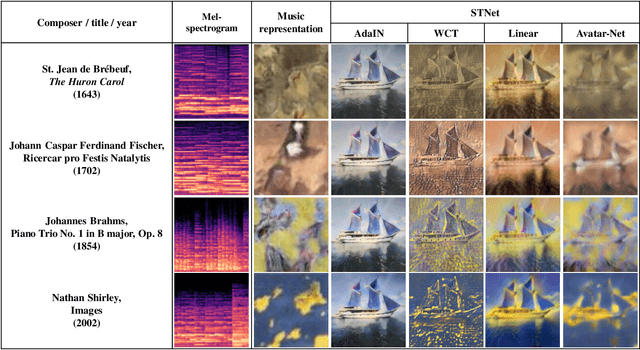
Music-to-visual style transfer is a challenging yet important cross-modal learning problem in the practice of creativity. Its major difference from the traditional image style transfer problem is that the style information is provided by music rather than images. Assuming that musical features can be properly mapped to visual contents through semantic links between the two domains, we solve the music-to-visual style transfer problem in two steps: music visualization and style transfer. The music visualization network utilizes an encoder-generator architecture with a conditional generative adversarial network to generate image-based music representations from music data. This network is integrated with an image style transfer method to accomplish the style transfer process. Experiments are conducted on WikiArt-IMSLP, a newly compiled dataset including Western music recordings and paintings listed by decades. By utilizing such a label to learn the semantic connection between paintings and music, we demonstrate that the proposed framework can generate diverse image style representations from a music piece, and these representations can unveil certain art forms of the same era. Subjective testing results also emphasize the role of the era label in improving the perceptual quality on the compatibility between music and visual content.
ReconVAT: A Semi-Supervised Automatic Music Transcription Framework for Low-Resource Real-World Data
Jul 29, 2021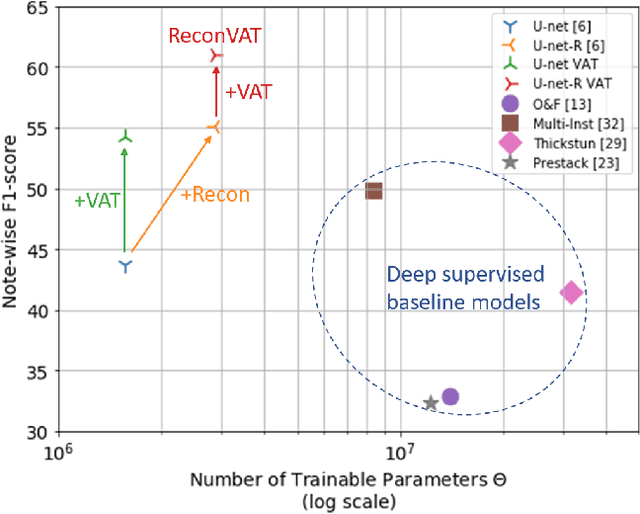
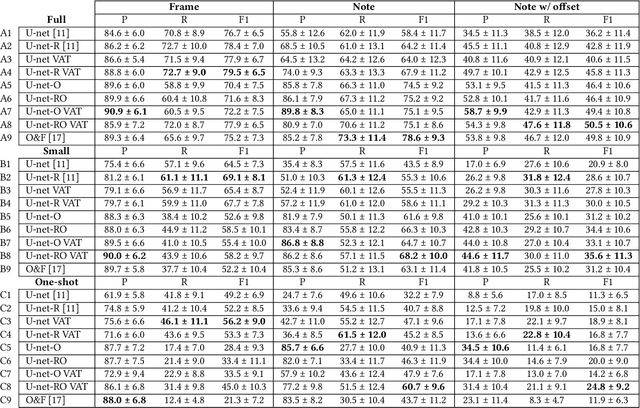
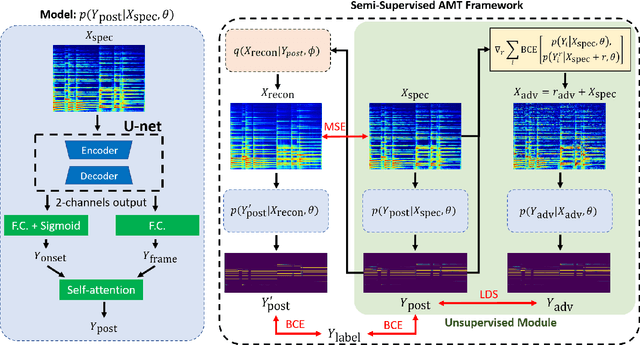
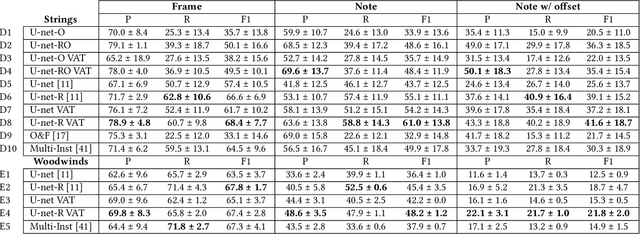
Most of the current supervised automatic music transcription (AMT) models lack the ability to generalize. This means that they have trouble transcribing real-world music recordings from diverse musical genres that are not presented in the labelled training data. In this paper, we propose a semi-supervised framework, ReconVAT, which solves this issue by leveraging the huge amount of available unlabelled music recordings. The proposed ReconVAT uses reconstruction loss and virtual adversarial training. When combined with existing U-net models for AMT, ReconVAT achieves competitive results on common benchmark datasets such as MAPS and MusicNet. For example, in the few-shot setting for the string part version of MusicNet, ReconVAT achieves F1-scores of 61.0% and 41.6% for the note-wise and note-with-offset-wise metrics respectively, which translates into an improvement of 22.2% and 62.5% compared to the supervised baseline model. Our proposed framework also demonstrates the potential of continual learning on new data, which could be useful in real-world applications whereby new data is constantly available.
Listener Modeling and Context-aware Music Recommendation Based on Country Archetypes
Sep 11, 2020

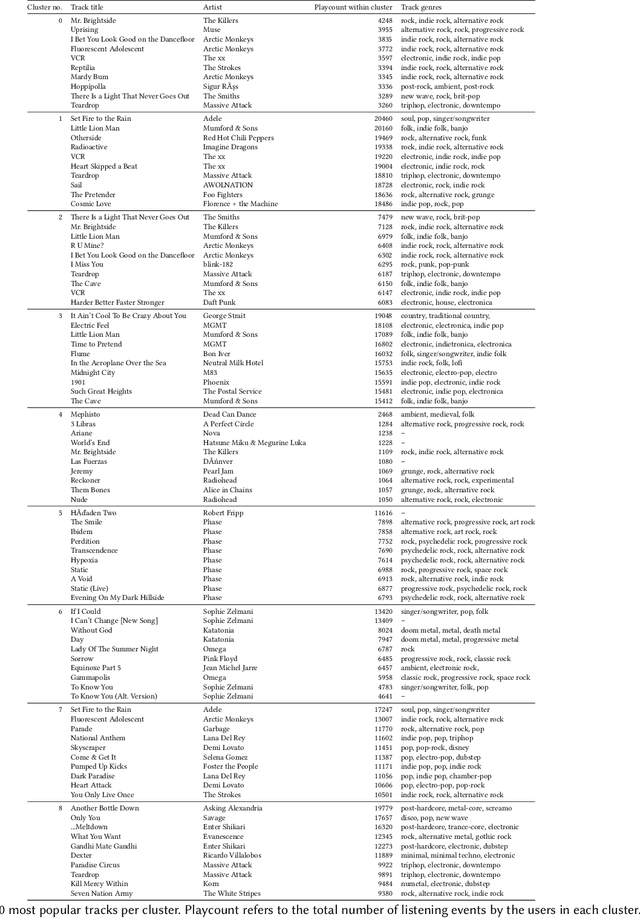
Music preferences are strongly shaped by the cultural and socio-economic background of the listener, which is reflected, to a considerable extent, in country-specific music listening profiles. Previous work has already identified several country-specific differences in the popularity distribution of music artists listened to. In particular, what constitutes the "music mainstream" strongly varies between countries. To complement and extend these results, the article at hand delivers the following major contributions: First, using state-of-the-art unsupervised learning techniques, we identify and thoroughly investigate (1) country profiles of music preferences on the fine-grained level of music tracks (in contrast to earlier work that relied on music preferences on the artist level) and (2) country archetypes that subsume countries sharing similar patterns of listening preferences. Second, we formulate four user models that leverage the user's country information on music preferences. Among others, we propose a user modeling approach to describe a music listener as a vector of similarities over the identified country clusters or archetypes. Third, we propose a context-aware music recommendation system that leverages implicit user feedback, where context is defined via the four user models. More precisely, it is a multi-layer generative model based on a variational autoencoder, in which contextual features can influence recommendations through a gating mechanism. Fourth, we thoroughly evaluate the proposed recommendation system and user models on a real-world corpus of more than one billion listening records of users around the world (out of which we use 369 million in our experiments) and show its merits vis-a-vis state-of-the-art algorithms that do not exploit this type of context information.
Heaps' Law and Vocabulary Richness in the History of Classical Music Harmony
Apr 09, 2021
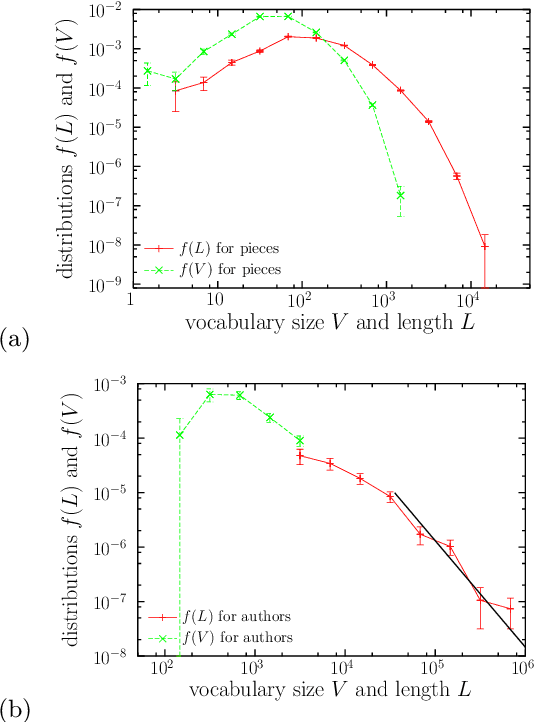
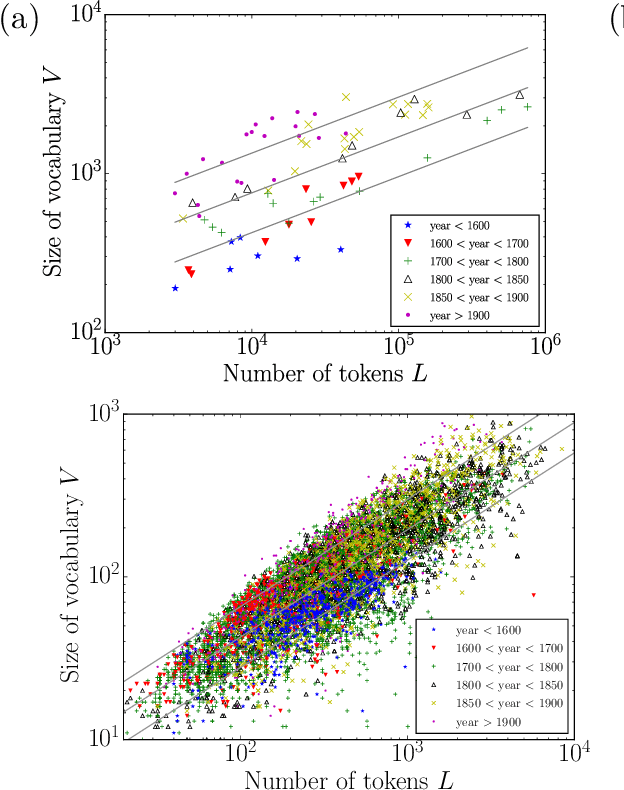
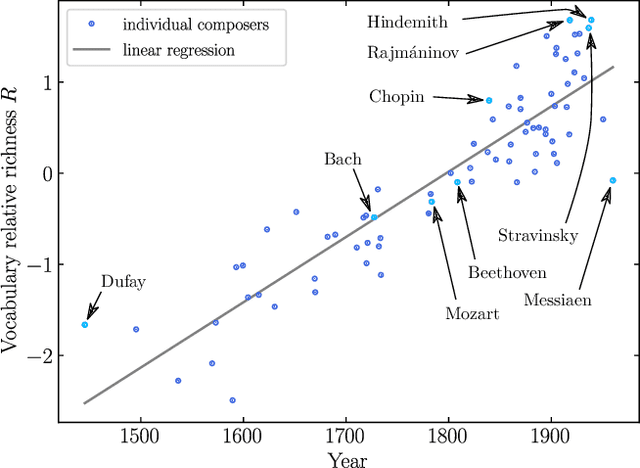
Music is a fundamental human construct, and harmony provides the building blocks of musical language. Using the Kunstderfuge corpus of classical music, we analyze the historical evolution of the richness of harmonic vocabulary of 76 classical composers, covering almost 6 centuries. Such corpus comprises about 9500 pieces, resulting in more than 5 million tokens of music codewords. The fulfilment of Heaps' law for the relation between the size of the harmonic vocabulary of a composer (in codeword types) and the total length of his works (in codeword tokens), with an exponent around 0.35, allows us to define a relative measure of vocabulary richness that has a transparent interpretation. When coupled with the considered corpus, this measure allows us to quantify harmony richness across centuries, unveiling a clear increasing linear trend. In this way, we are able to rank the composers in terms of richness of vocabulary, in the same way as for other related metrics, such as entropy. We find that the latter is particularly highly correlated with our measure of richness. Our approach is not specific for music and can be applied to other systems built by tokens of different types, as for instance natural language.
Investigating self-supervised learning for lyrics recognition
Sep 28, 2022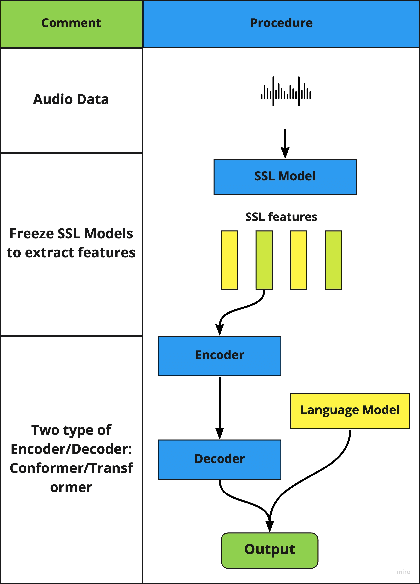
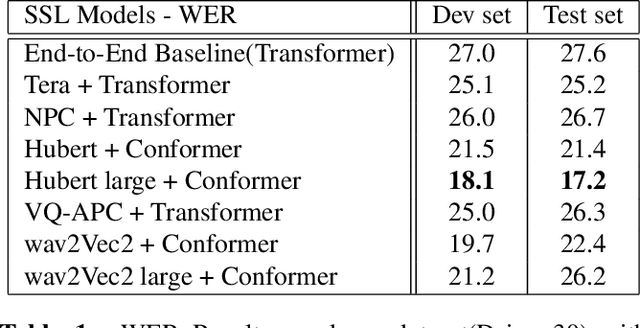
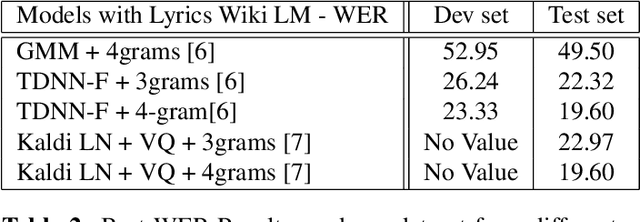
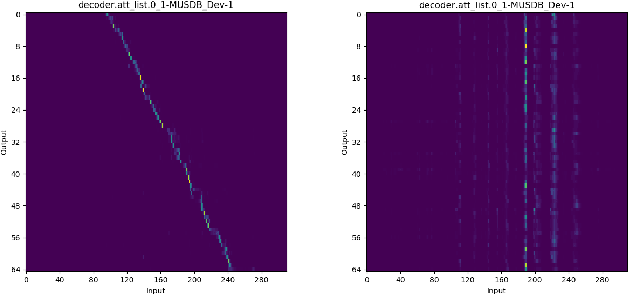
Lyrics recognition is an important task in music processing. Despite the great number of traditional algorithms such as the hybrid HMM-TDNN model achieving good performance, studies on applying end-to-end models and self-supervised learning (SSL) are limited. In this paper, we first establish an end-to-end baseline for lyrics recognition and then explore the performance of SSL models. We evaluate four upstream SSL models based on their training method (masked reconstruction, masked prediction, autoregressive reconstruction, contrastive model). After applying the SSL model, the best performance improved by 5.23% for the dev set and 2.4% for the test set compared with the previous state-of-art baseline system even without a language model trained by a large corpus. Moreover, we study the generalization ability of the SSL features considering that those models were not trained on music datasets.
Music Generation with Temporal Structure Augmentation
Apr 21, 2020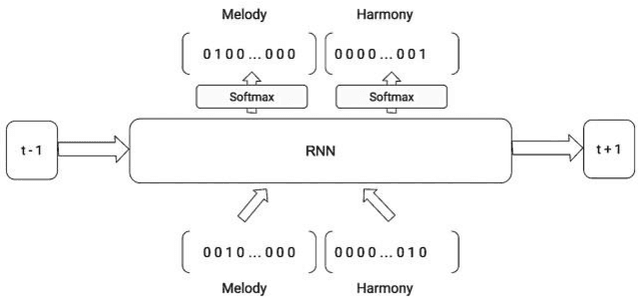
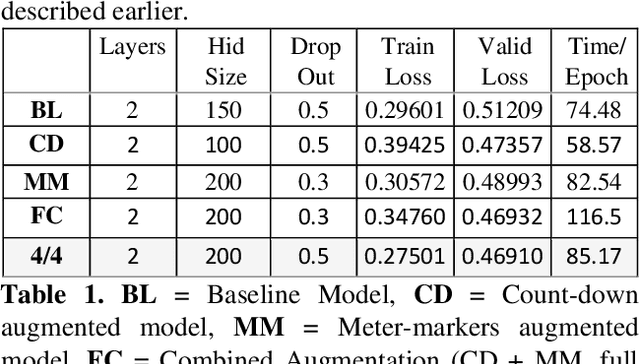
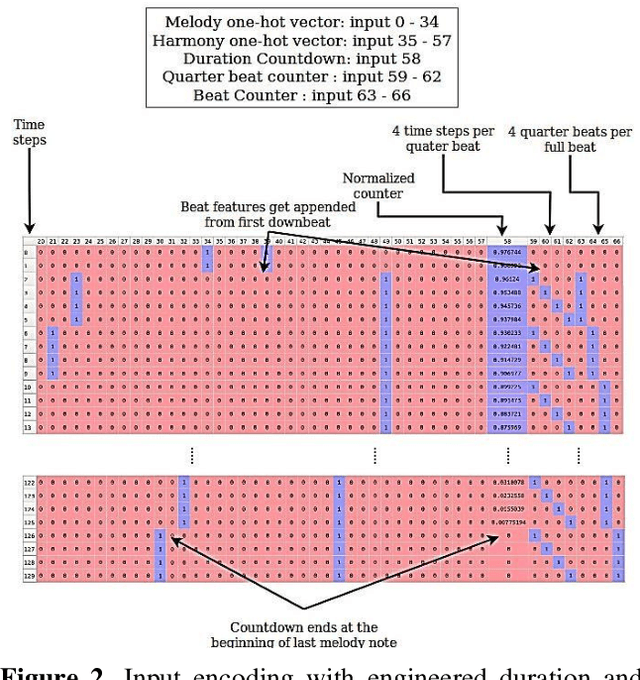
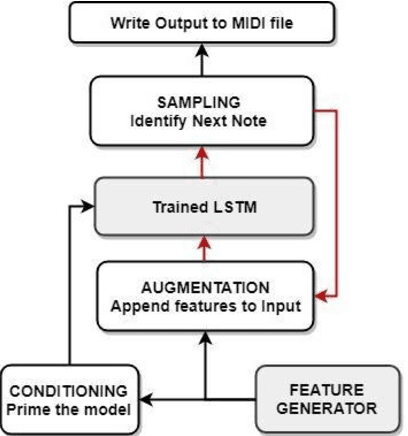
In this paper we introduce a novel feature augmentation approach for generating structured musical compositions comprising melodies and harmonies. The proposed method augments a connectionist generation model with count-down to song conclusion and meter markers as extra input features to study whether neural networks can learn to produce more aesthetically pleasing and structured musical output as a consequence of augmenting the input data with structural features. An RNN architecture with LSTM cells is trained on the Nottingham folk music dataset in a supervised sequence learning setup, following a Music Language Modelling approach, and then applied to generation of harmonies and melodies. Our experiments show an improved prediction performance for both types of annotation. The generated music was also subjectively evaluated using an on-line Turing style listening test which confirms a substantial improvement in the aesthetic quality and in the perceived structure of the music generated using the temporal structure.
DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer
Mar 25, 2021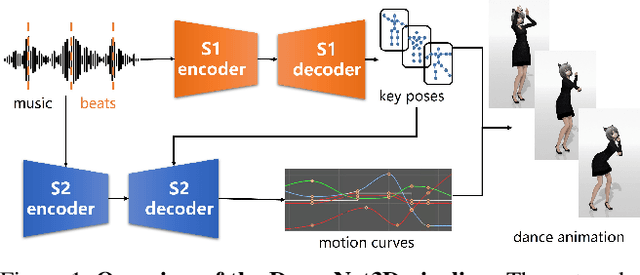

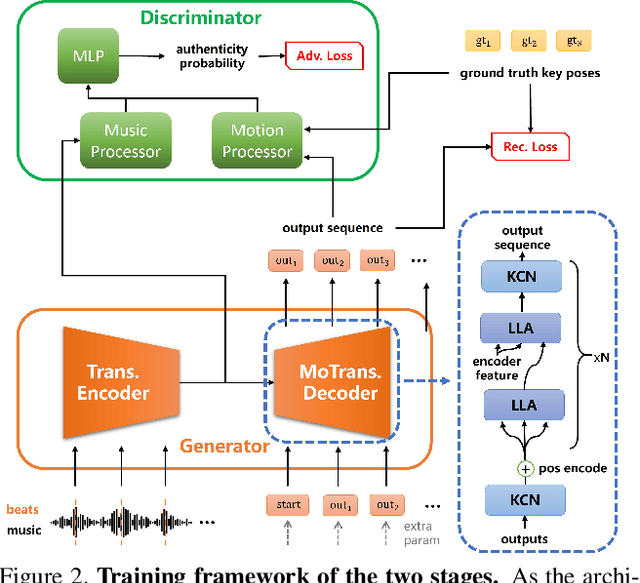
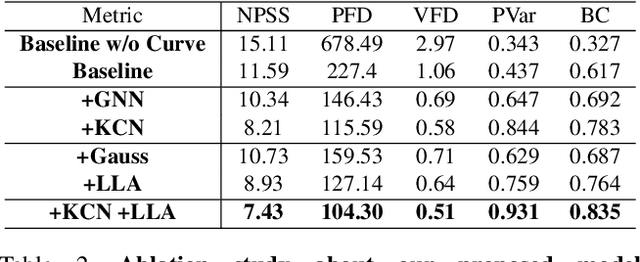
In this work, we propose a novel deep learning framework that can generate a vivid dance from a whole piece of music. In contrast to previous works that define the problem as generation of frames of motion state parameters, we formulate the task as a prediction of motion curves between key poses, which is inspired by the animation industry practice. The proposed framework, named DanceNet3D, first generates key poses on beats of the given music and then predicts the in-between motion curves. DanceNet3D adopts the encoder-decoder architecture and the adversarial schemes for training. The decoders in DanceNet3D are constructed on MoTrans, a transformer tailored for motion generation. In MoTrans we introduce the kinematic correlation by the Kinematic Chain Networks, and we also propose the Learned Local Attention module to take the temporal local correlation of human motion into consideration. Furthermore, we propose PhantomDance, the first large-scale dance dataset produced by professional animatiors, with accurate synchronization with music. Extensive experiments demonstrate that the proposed approach can generate fluent, elegant, performative and beat-synchronized 3D dances, which significantly surpasses previous works quantitatively and qualitatively.
Neural Remixer: Learning to Remix Music with Interactive Control
Jul 28, 2021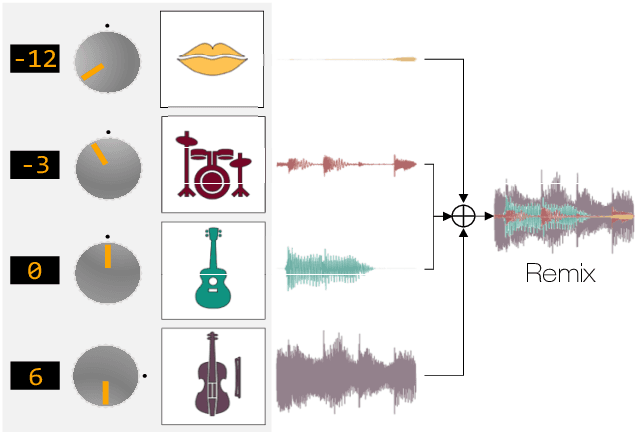
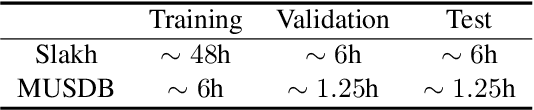
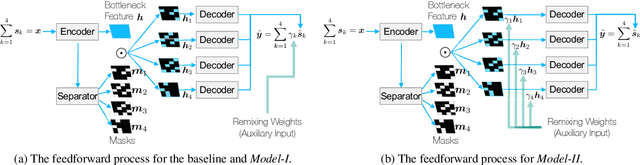
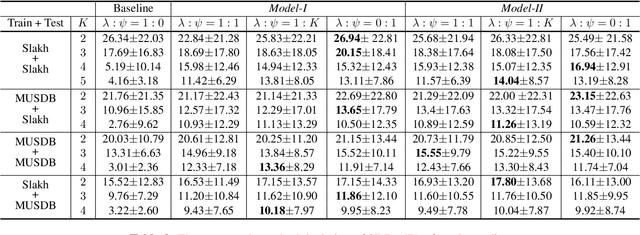
The task of manipulating the level and/or effects of individual instruments to recompose a mixture of recording, or remixing, is common across a variety of applications such as music production, audio-visual post-production, podcasts, and more. This process, however, traditionally requires access to individual source recordings, restricting the creative process. To work around this, source separation algorithms can separate a mixture into its respective components. Then, a user can adjust their levels and mix them back together. This two-step approach, however, still suffers from audible artifacts and motivates further work. In this work, we seek to learn to remix music directly. To do this, we propose two neural remixing architectures that extend Conv-TasNet to either remix via a) source estimates directly or b) their latent representations. Both methods leverage a remixing data augmentation scheme as well as a mixture reconstruction loss to achieve an end-to-end separation and remixing process. We evaluate our methods using the Slakh and MUSDB datasets and report both source separation performance and the remixing quality. Our results suggest learning-to-remix significantly outperforms a strong separation baseline, is particularly useful for small changes, and can provide interactive user-controls.
A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions
Nov 13, 2020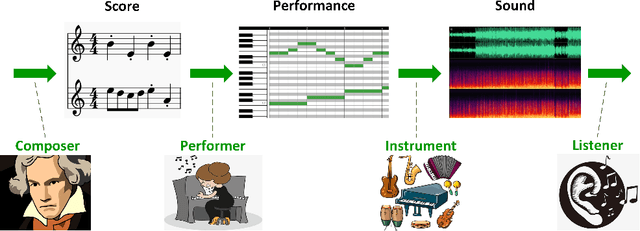
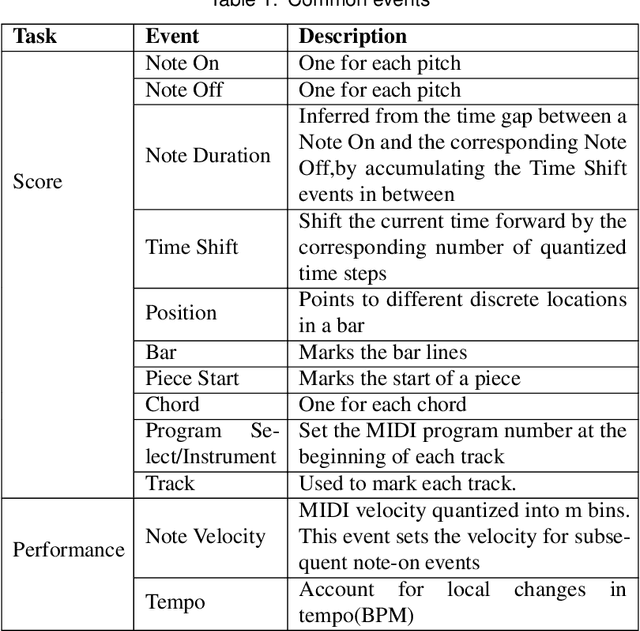
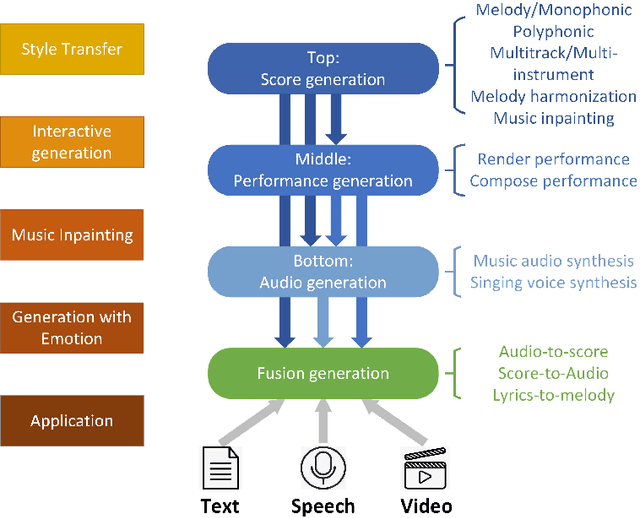

The utilization of deep learning techniques in generating various contents (such as image, text, etc.) has become a trend. Especially music, the topic of this paper, has attracted widespread attention of countless researchers.The whole process of producing music can be divided into three stages, corresponding to the three levels of music generation: score generation produces scores, performance generation adds performance characteristics to the scores, and audio generation converts scores with performance characteristics into audio by assigning timbre or generates music in audio format directly. Previous surveys have explored the network models employed in the field of automatic music generation. However, the development history, the model evolution, as well as the pros and cons of same music generation task have not been clearly illustrated. This paper attempts to provide an overview of various composition tasks under different music generation levels, covering most of the currently popular music generation tasks using deep learning. In addition, we summarize the datasets suitable for diverse tasks, discuss the music representations, the evaluation methods as well as the challenges under different levels, and finally point out several future directions.