 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaps' Law and Vocabulary Richness in the History of Classical Music Harmony
Apr 09, 2021
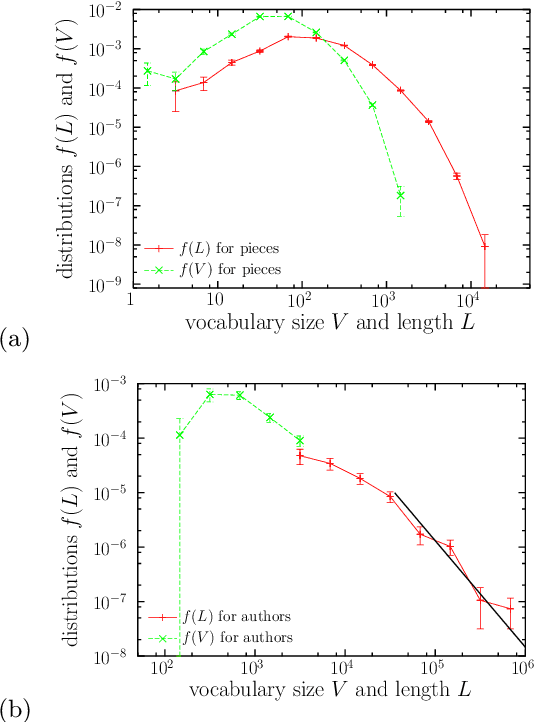
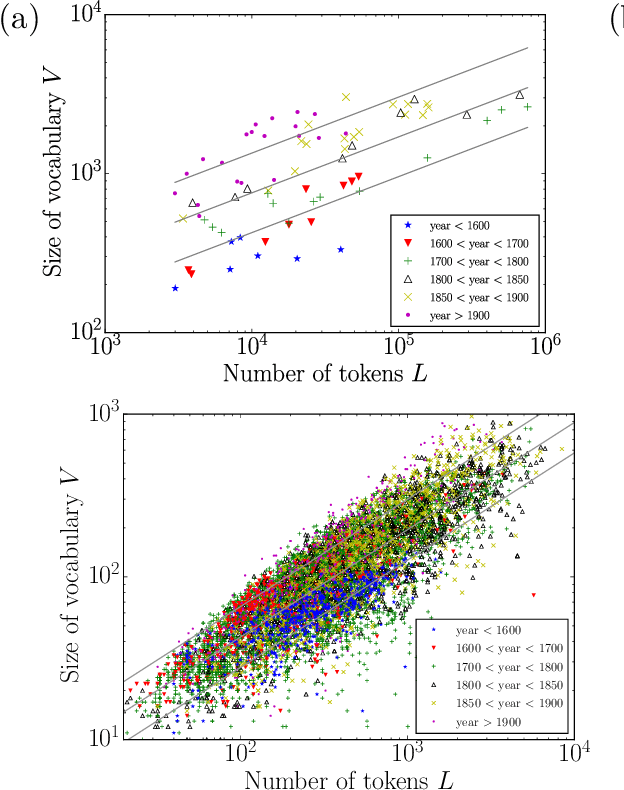
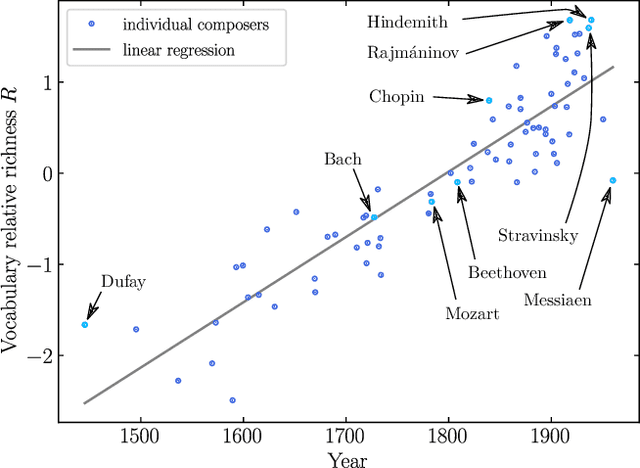
Music is a fundamental human construct, and harmony provides the building blocks of musical language. Using the Kunstderfuge corpus of classical music, we analyze the historical evolution of the richness of harmonic vocabulary of 76 classical composers, covering almost 6 centuries. Such corpus comprises about 9500 pieces, resulting in more than 5 million tokens of music codewords. The fulfilment of Heaps' law for the relation between the size of the harmonic vocabulary of a composer (in codeword types) and the total length of his works (in codeword tokens), with an exponent around 0.35, allows us to define a relative measure of vocabulary richness that has a transparent interpretation. When coupled with the considered corpus, this measure allows us to quantify harmony richness across centuries, unveiling a clear increasing linear trend. In this way, we are able to rank the composers in terms of richness of vocabulary, in the same way as for other related metrics, such as entropy. We find that the latter is particularly highly correlated with our measure of richness. Our approach is not specific for music and can be applied to other systems built by tokens of different types, as for instance natural language.
Ranking and significance of variable-length similarity-based time series motifs
Mar 06, 2015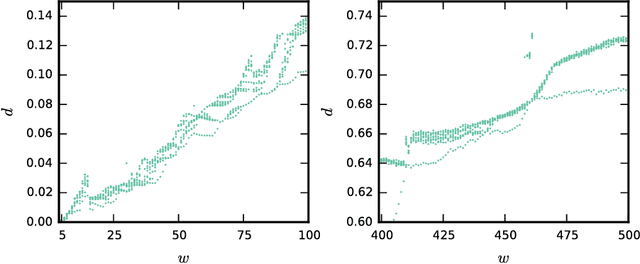
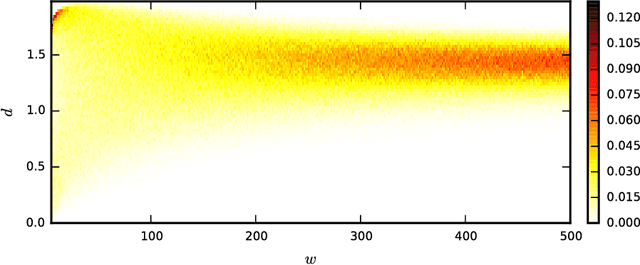
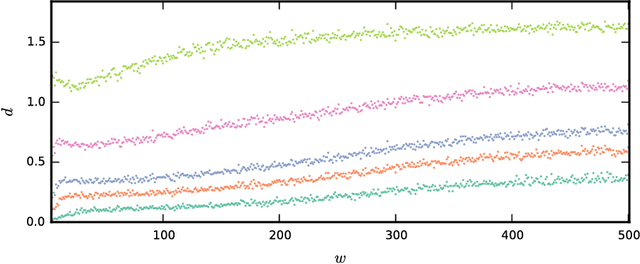
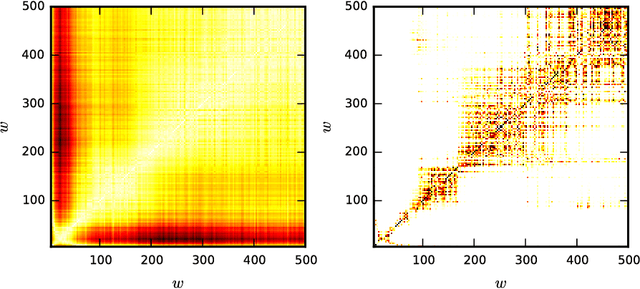
The detection of very similar patterns in a time series, commonly called motifs, has received continuous and increasing attention from diverse scientific communities. In particular, recent approaches for discovering similar motifs of different lengths have been proposed. In this work, we show that such variable-length similarity-based motifs cannot be directly compared, and hence ranked, by their normalized dissimilarities. Specifically, we find that length-normalized motif dissimilarities still have intrinsic dependencies on the motif length, and that lowest dissimilarities are particularly affected by this dependency. Moreover, we find that such dependencies are generally non-linear and change with the considered data set and dissimilarity measure. Based on these findings, we propose a solution to rank those motifs and measure their significance. This solution relies on a compact but accurate model of the dissimilarity space, using a beta distribution with three parameters that depend on the motif length in a non-linear way. We believe the incomparability of variable-length dissimilarities could go beyond the field of time series, and that similar modeling strategies as the one used here could be of help in a more broad context.
* 20 pages, 10 figures