 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Generation with Temporal Structure Augmentation
Paper and Code
Apr 21, 2020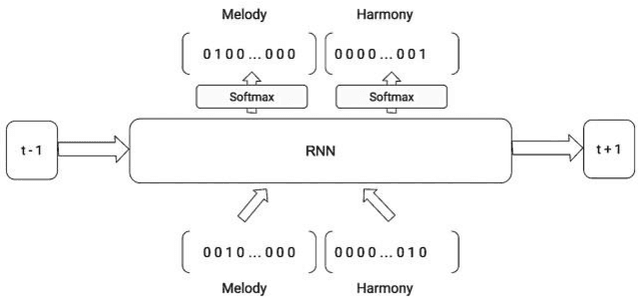
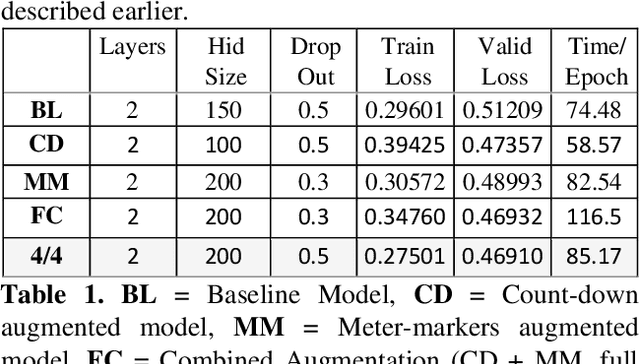
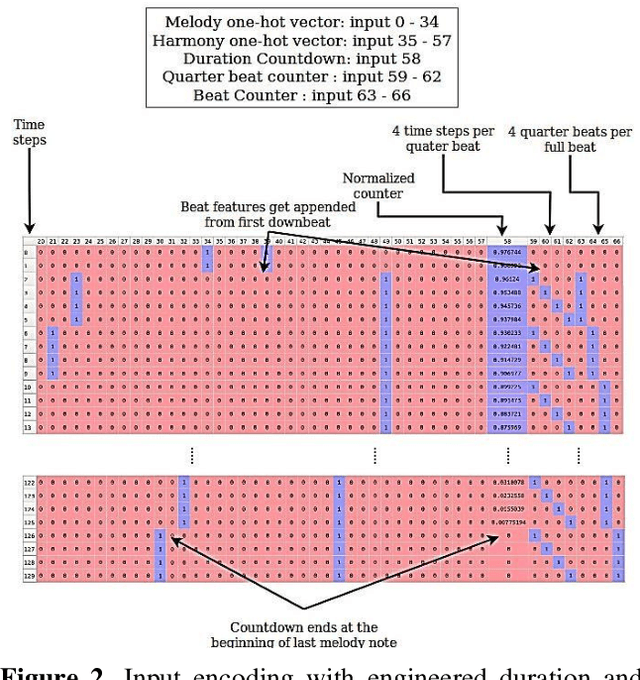
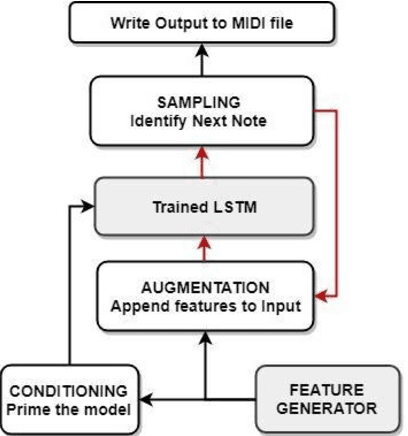
In this paper we introduce a novel feature augmentation approach for generating structured musical compositions comprising melodies and harmonies. The proposed method augments a connectionist generation model with count-down to song conclusion and meter markers as extra input features to study whether neural networks can learn to produce more aesthetically pleasing and structured musical output as a consequence of augmenting the input data with structural features. An RNN architecture with LSTM cells is trained on the Nottingham folk music dataset in a supervised sequence learning setup, following a Music Language Modelling approach, and then applied to generation of harmonies and melodies. Our experiments show an improved prediction performance for both types of annotation. The generated music was also subjectively evaluated using an on-line Turing style listening test which confirms a substantial improvement in the aesthetic quality and in the perceived structure of the music generated using the temporal structure.