 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023
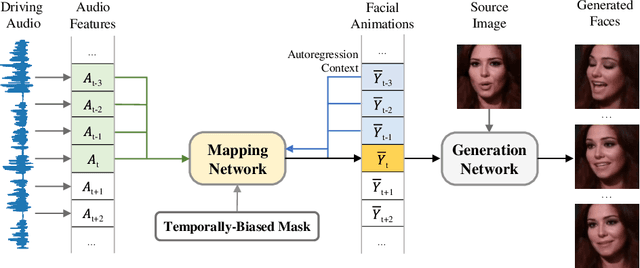
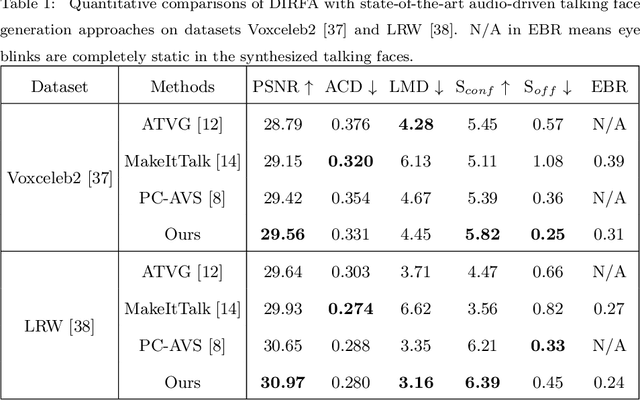

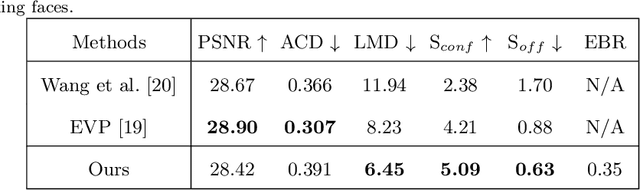
Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.
HyperLips: Hyper Control Lips with High Resolution Decoder for Talking Face Generation
Oct 15, 2023
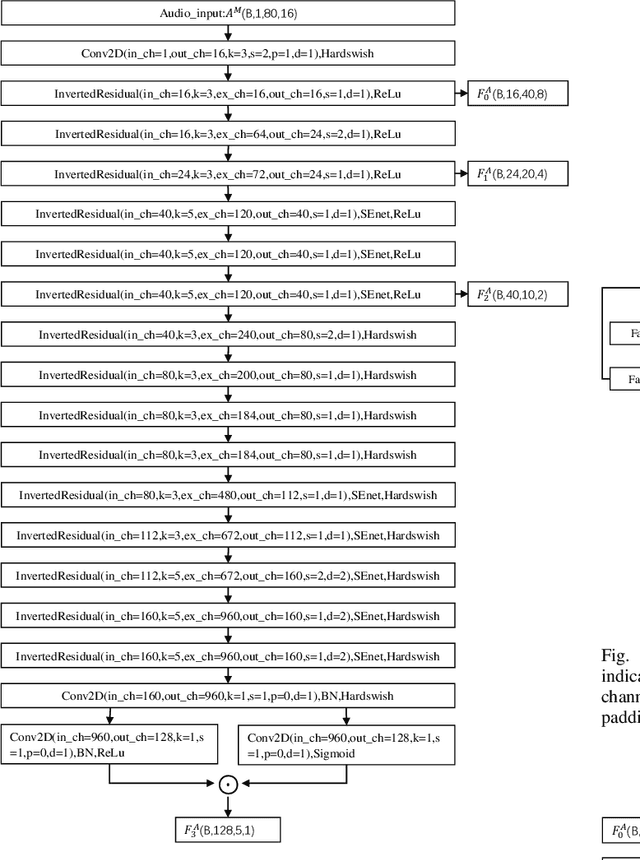
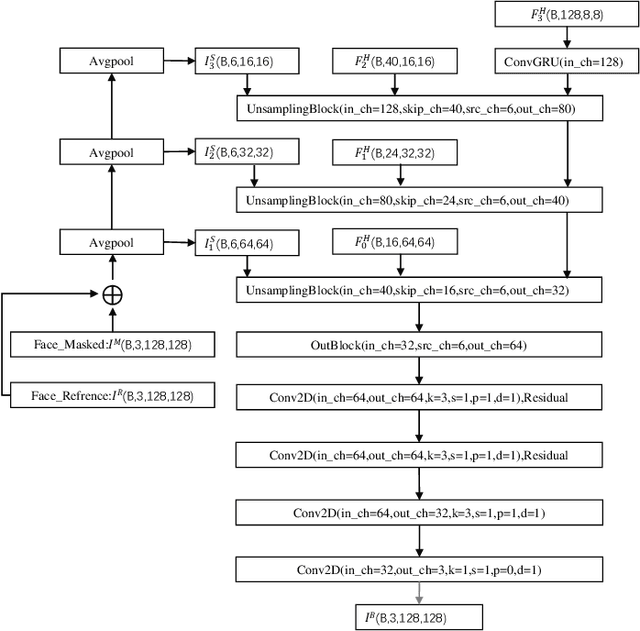
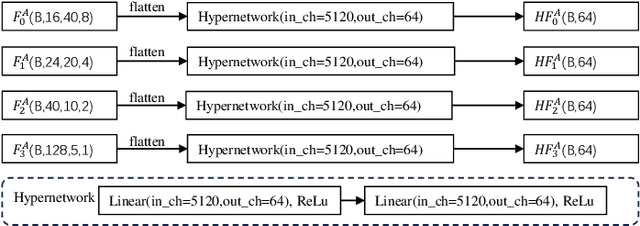
Talking face generation has a wide range of potential applications in the field of virtual digital humans. However, rendering high-fidelity facial video while ensuring lip synchronization is still a challenge for existing audio-driven talking face generation approaches. To address this issue, we propose HyperLips, a two-stage framework consisting of a hypernetwork for controlling lips and a high-resolution decoder for rendering high-fidelity faces. In the first stage, we construct a base face generation network that uses the hypernetwork to control the encoding latent code of the visual face information over audio. First, FaceEncoder is used to obtain latent code by extracting features from the visual face information taken from the video source containing the face frame.Then, HyperConv, which weighting parameters are updated by HyperNet with the audio features as input, will modify the latent code to synchronize the lip movement with the audio. Finally, FaceDecoder will decode the modified and synchronized latent code into visual face content. In the second stage, we obtain higher quality face videos through a high-resolution decoder. To further improve the quality of face generation, we trained a high-resolution decoder, HRDecoder, using face images and detected sketches generated from the first stage as input.Extensive quantitative and qualitative experiments show that our method outperforms state-of-the-art work with more realistic, high-fidelity, and lip synchronization. Project page: https://semchan.github.io/HyperLips Project/
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
MIS-AVoiDD: Modality Invariant and Specific Representation for Audio-Visual Deepfake Detection
Oct 13, 2023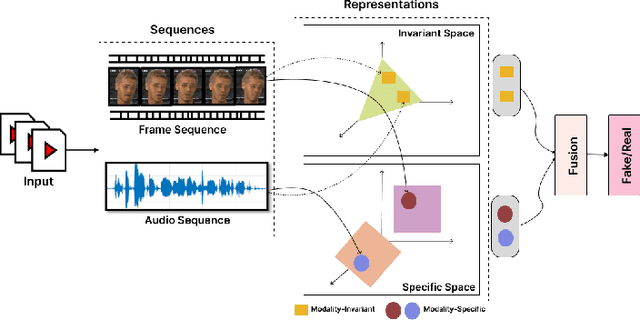
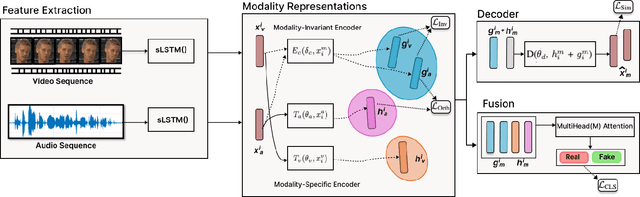

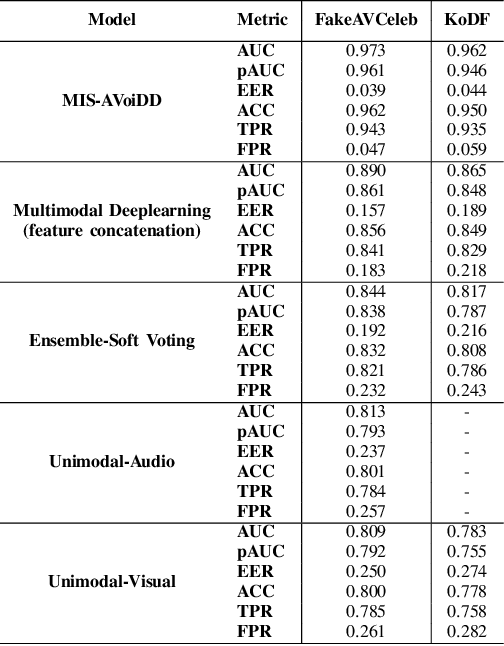
Deepfakes are synthetic media generated using deep generative algorithms and have posed a severe societal and political threat. Apart from facial manipulation and synthetic voice, recently, a novel kind of deepfakes has emerged with either audio or visual modalities manipulated. In this regard, a new generation of multimodal audio-visual deepfake detectors is being investigated to collectively focus on audio and visual data for multimodal manipulation detection. Existing multimodal (audio-visual) deepfake detectors are often based on the fusion of the audio and visual streams from the video. Existing studies suggest that these multimodal detectors often obtain equivalent performances with unimodal audio and visual deepfake detectors. We conjecture that the heterogeneous nature of the audio and visual signals creates distributional modality gaps and poses a significant challenge to effective fusion and efficient performance. In this paper, we tackle the problem at the representation level to aid the fusion of audio and visual streams for multimodal deepfake detection. Specifically, we propose the joint use of modality (audio and visual) invariant and specific representations. This ensures that the common patterns and patterns specific to each modality representing pristine or fake content are preserved and fused for multimodal deepfake manipulation detection. Our experimental results on FakeAVCeleb and KoDF audio-visual deepfake datasets suggest the enhanced accuracy of our proposed method over SOTA unimodal and multimodal audio-visual deepfake detectors by $17.8$% and $18.4$%, respectively. Thus, obtaining state-of-the-art performance.
Emotion Recognition for Challenged People Facial Appearance in Social using Neural Network
May 11, 2023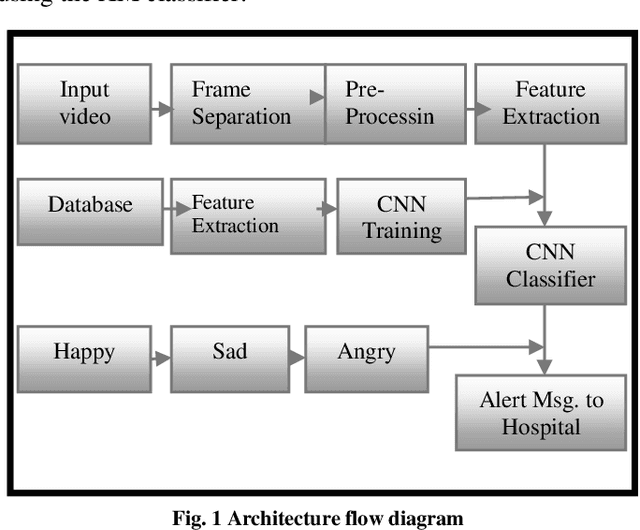
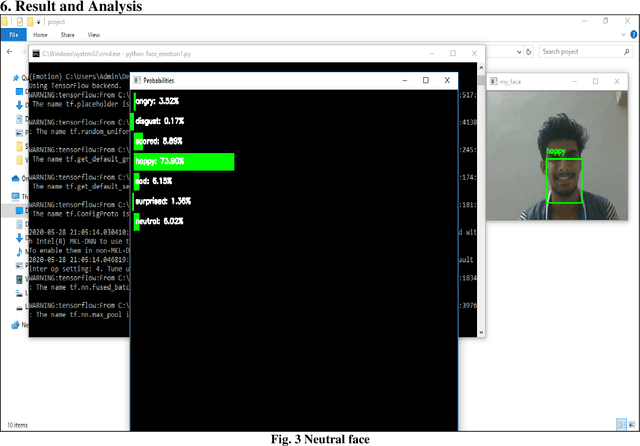
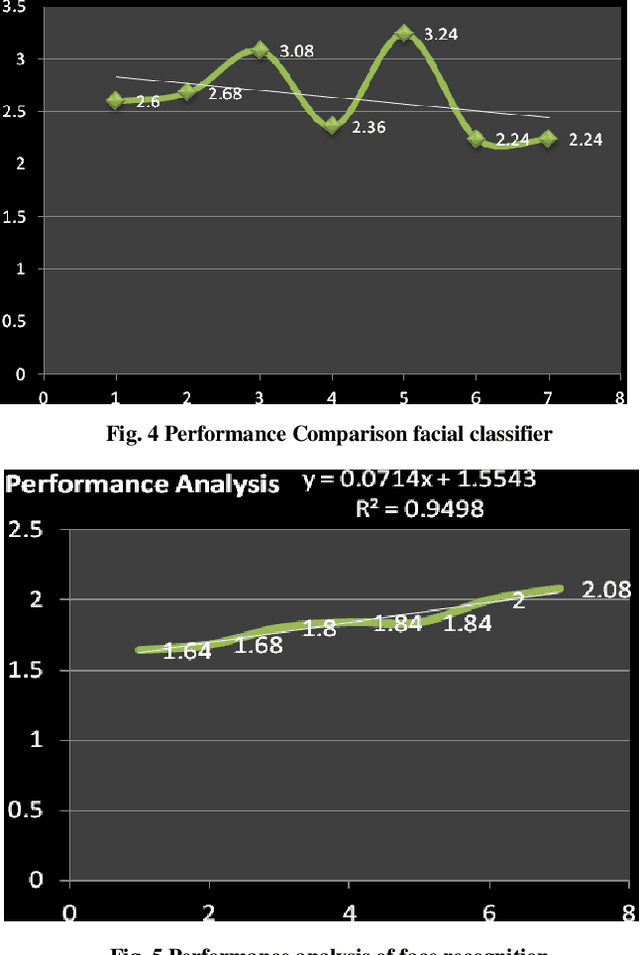
Human communication is the vocal and non verbal signal to communicate with others. Human expression is a significant biometric object in picture and record databases of surveillance systems. Face appreciation has a serious role in biometric methods and is good-looking for plentiful applications, including visual scrutiny and security. Facial expressions are a form of nonverbal communication; recognizing them helps improve the human machine interaction. This paper proposes an idea for face and enlightenment invariant credit of facial expressions by the images. In order on, the person's face can be computed. Face expression is used in CNN classifier to categorize the acquired picture into different emotion categories. It is a deep, feed-forward artificial neural network. Outcome surpasses human presentation and shows poses alternate performance. Varying lighting conditions can influence the fitting process and reduce recognition precision. Results illustrate that dependable facial appearance credited with changing lighting conditions for separating reasonable facial terminology display emotions is an efficient representation of clean and assorted moving expressions. This process can also manage the proportions of dissimilar basic affecting expressions of those mixed jointly to produce sensible emotional facial expressions. Our system contains a pre-defined data set, which was residential by a statistics scientist and includes all pure and varied expressions. On average, a data set has achieved 92.4% exact validation of the expressions synthesized by our technique. These facial expressions are compared through the pre-defined data-position inside our system. If it recognizes the person in an abnormal condition, an alert will be passed to the nearby hospital/doctor seeing that a message.
Contrast-Phys+: Unsupervised and Weakly-supervised Video-based Remote Physiological Measurement via Spatiotemporal Contrast
Sep 13, 2023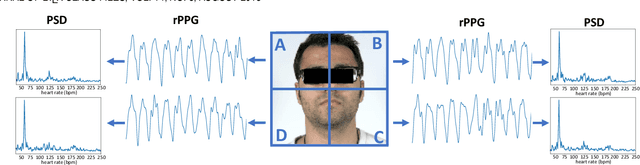
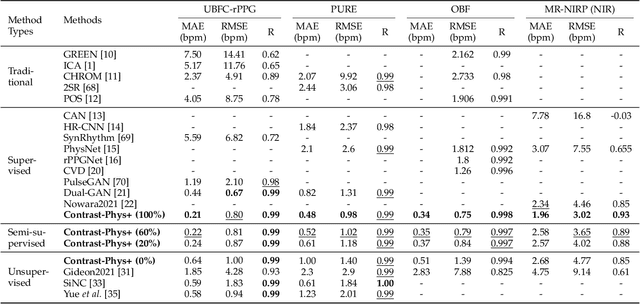
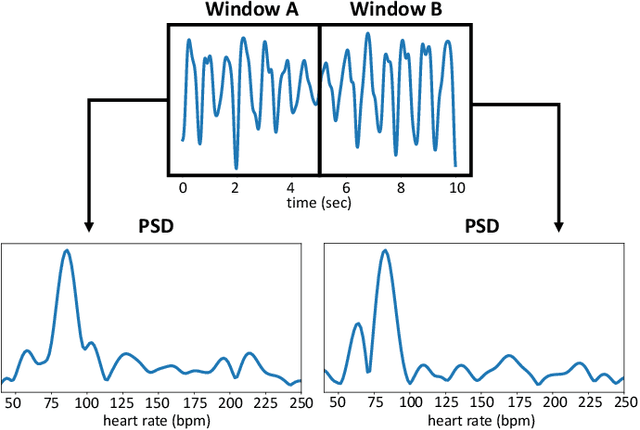
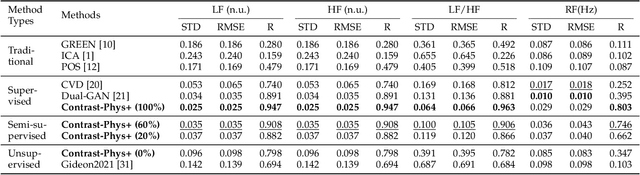
Video-based remote physiological measurement utilizes facial videos to measure the blood volume change signal, which is also called remote photoplethysmography (rPPG). Supervised methods for rPPG measurements have been shown to achieve good performance. However, the drawback of these methods is that they require facial videos with ground truth (GT) physiological signals, which are often costly and difficult to obtain. In this paper, we propose Contrast-Phys+, a method that can be trained in both unsupervised and weakly-supervised settings. We employ a 3DCNN model to generate multiple spatiotemporal rPPG signals and incorporate prior knowledge of rPPG into a contrastive loss function. We further incorporate the GT signals into contrastive learning to adapt to partial or misaligned labels. The contrastive loss encourages rPPG/GT signals from the same video to be grouped together, while pushing those from different videos apart. We evaluate our methods on five publicly available datasets that include both RGB and Near-infrared videos. Contrast-Phys+ outperforms the state-of-the-art supervised methods, even when using partially available or misaligned GT signals, or no labels at all. Additionally, we highlight the advantages of our methods in terms of computational efficiency, noise robustness, and generalization.
Neural Face Rigging for Animating and Retargeting Facial Meshes in the Wild
May 15, 2023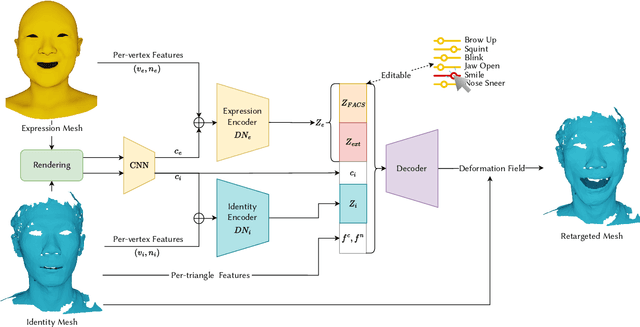
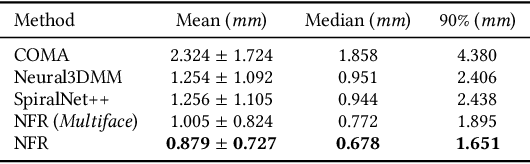

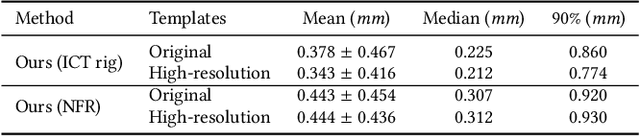
We propose an end-to-end deep-learning approach for automatic rigging and retargeting of 3D models of human faces in the wild. Our approach, called Neural Face Rigging (NFR), holds three key properties: (i) NFR's expression space maintains human-interpretable editing parameters for artistic controls; (ii) NFR is readily applicable to arbitrary facial meshes with different connectivity and expressions; (iii) NFR can encode and produce fine-grained details of complex expressions performed by arbitrary subjects. To the best of our knowledge, NFR is the first approach to provide realistic and controllable deformations of in-the-wild facial meshes, without the manual creation of blendshapes or correspondence. We design a deformation autoencoder and train it through a multi-dataset training scheme, which benefits from the unique advantages of two data sources: a linear 3DMM with interpretable control parameters as in FACS, and 4D captures of real faces with fine-grained details. Through various experiments, we show NFR's ability to automatically produce realistic and accurate facial deformations across a wide range of existing datasets as well as noisy facial scans in-the-wild, while providing artist-controlled, editable parameters.
4D Facial Expression Diffusion Model
Mar 29, 2023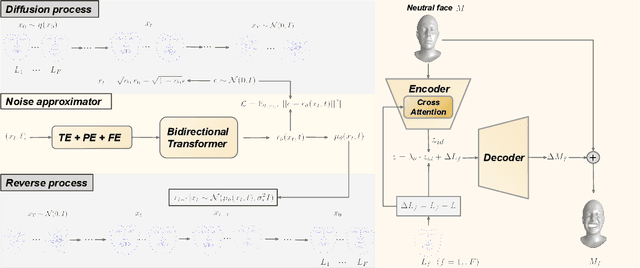
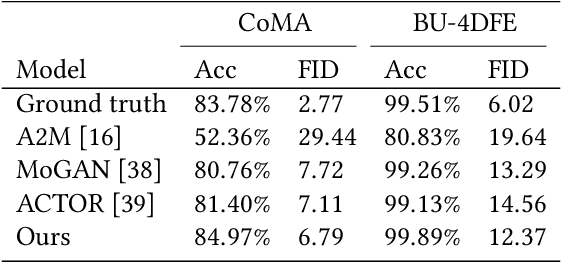

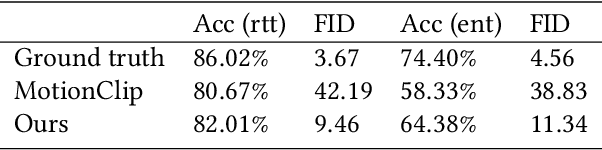
Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at https://github.com/ZOUKaifeng/4DFM. Code and models will be made available upon acceptance.
HDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
Sep 14, 2023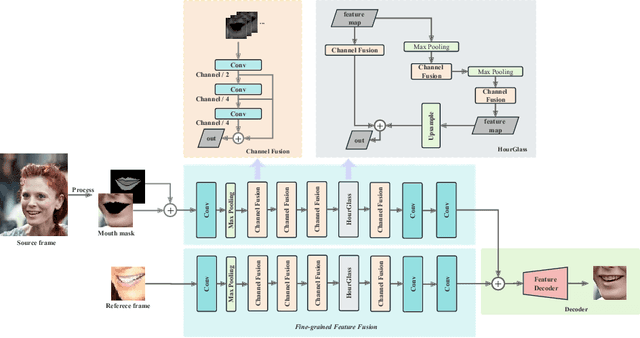
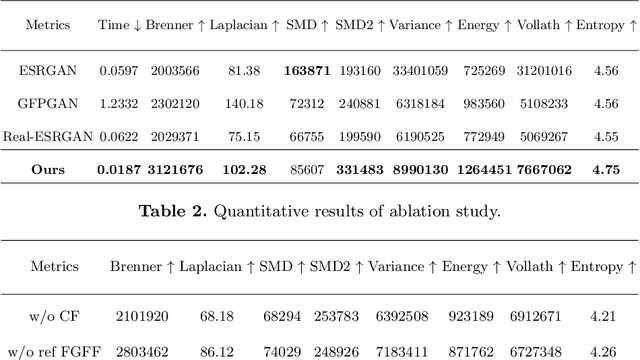
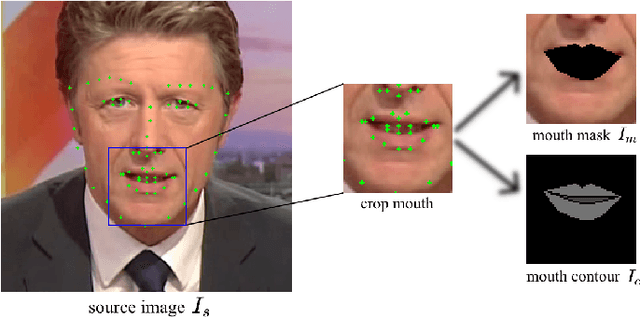
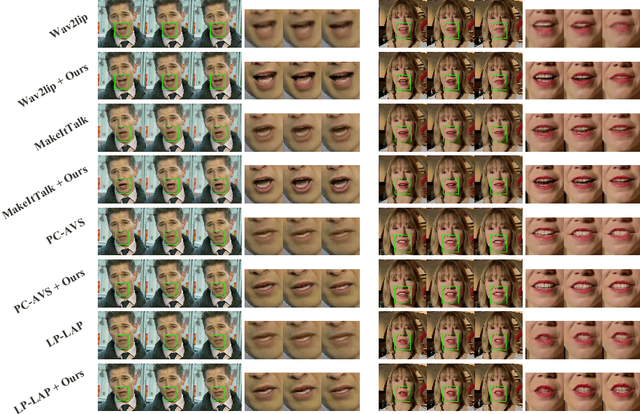
Talking Face Generation (TFG) aims to reconstruct facial movements to achieve high natural lip movements from audio and facial features that are under potential connections. Existing TFG methods have made significant advancements to produce natural and realistic images. However, most work rarely takes visual quality into consideration. It is challenging to ensure lip synchronization while avoiding visual quality degradation in cross-modal generation methods. To address this issue, we propose a universal High-Definition Teeth Restoration Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth regions at an extremely fast speed while maintaining synchronization, and temporal consistency. In particular, we propose a Fine-Grained Feature Fusion (FGFF) module to effectively capture fine texture feature information around teeth and surrounding regions, and use these features to fine-grain the feature map to enhance the clarity of teeth. Extensive experiments show that our method can be adapted to arbitrary TFG methods without suffering from lip synchronization and frame coherence. Another advantage of HDTR-Net is its real-time generation ability. Also under the condition of high-definition restoration of talking face video synthesis, its inference speed is $300\%$ faster than the current state-of-the-art face restoration based on super-resolution.