 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Triangular Character Animation Sampling with Motion, Emotion, and Relation
Mar 09, 2022

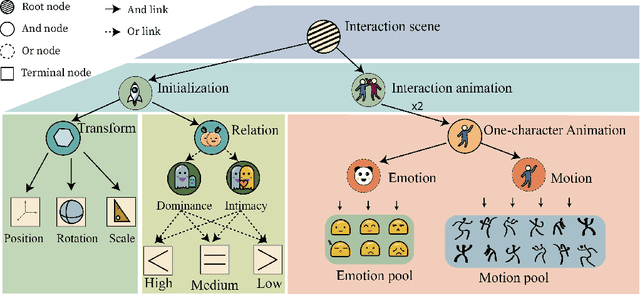

Dramatic progress has been made in animating individual characters. However, we still lack automatic control over activities between characters, especially those involving interactions. In this paper, we present a novel energy-based framework to sample and synthesize animations by associating the characters' body motions, facial expressions, and social relations. We propose a Spatial-Temporal And-Or graph (ST-AOG), a stochastic grammar model, to encode the contextual relationship between motion, emotion, and relation, forming a triangle in a conditional random field. We train our model from a labeled dataset of two-character interactions. Experiments demonstrate that our method can recognize the social relation between two characters and sample new scenes of vivid motion and emotion using Markov Chain Monte Carlo (MCMC) given the social relation. Thus, our method can provide animators with an automatic way to generate 3D character animations, help synthesize interactions between Non-Player Characters (NPCs), and enhance machine emotion intelligence (EQ) in virtual reality (VR).
Fisher Pruning of Deep Nets for Facial Trait Classification
Mar 21, 2018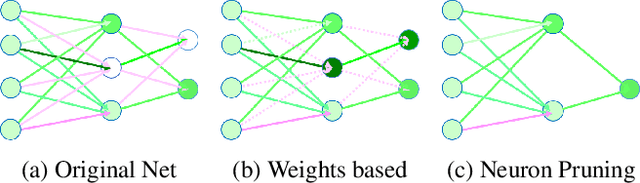
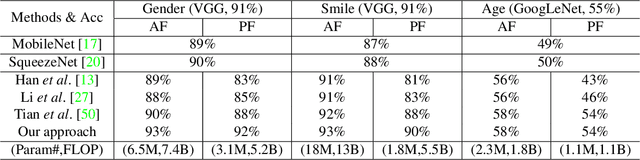
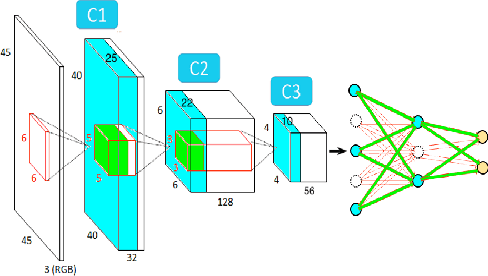
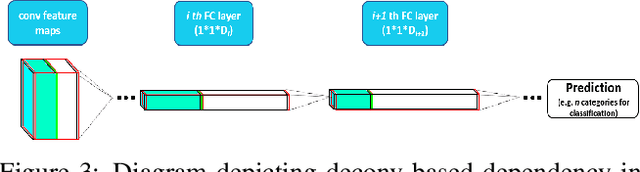
Although deep nets have resulted in high accuracies for various visual tasks, their computational and space requirements are prohibitively high for inclusion on devices without high-end GPUs. In this paper, we introduce a neuron/filter level pruning framework based on Fisher's LDA which leads to high accuracies for a wide array of facial trait classification tasks, while significantly reducing space/computational complexities. The approach is general and can be applied to convolutional, fully-connected, and module-based deep structures, in all cases leveraging the high decorrelation of neuron activations found in the pre-decision layer and cross-layer deconv dependency. Experimental results on binary and multi-category facial traits from the LFWA and Adience datasets illustrate the framework's comparable/better performance to state-of-the-art pruning approaches and compact structures (e.g. SqueezeNet, MobileNet). Ours successfully maintains comparable accuracies even after discarding most parameters (98%-99% for VGG-16, 82% for GoogLeNet) and with significant FLOP reductions (83% for VGG-16, 64% for GoogLeNet).
Self-Paced Deep Regression Forests with Consideration on Ranking Fairness
Dec 23, 2021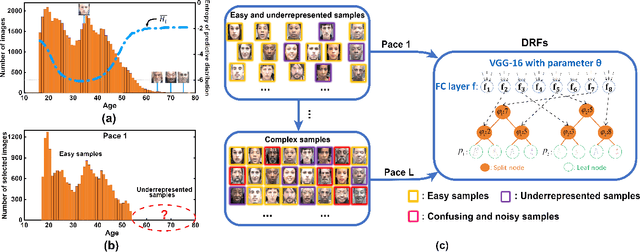
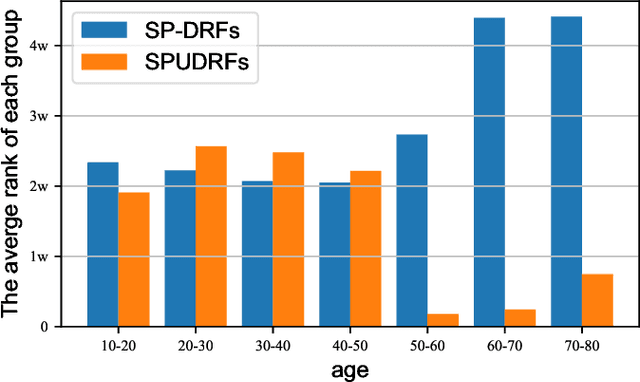
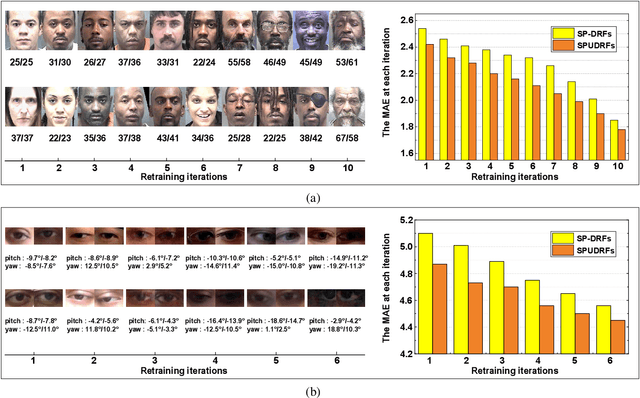
Deep discriminative models (DDMs), such as deep regression forests, deep neural decision forests, have been extensively studied recently to solve problems like facial age estimation, head pose estimation, gaze estimation and so forth. Such problems are challenging in part because a large amount of effective training data without noise and bias is often not available. While some progress has been achieved through learning more discriminative features, or reweighting samples, we argue what is more desirable is to learn gradually to discriminate like human beings. Then, we resort to self-paced learning (SPL). But a natural question arises: can self-paced regime lead DDMs to achieve more robust and less biased solutions? A serious problem with SPL, which is firstly discussed by this work, is it tends to aggravate the bias of solutions, especially for obvious imbalanced data. To this end, this paper proposes a new self-paced paradigm for deep discriminative model, which distinguishes noisy and underrepresented examples according to the output likelihood and entropy associated with each example, and tackle the fundamental ranking problem in SPL from a new perspective: fairness. This paradigm is fundamental, and could be easily combined with a variety of DDMs. Extensive experiments on three computer vision tasks, such as facial age estimation, head pose estimation and gaze estimation, demonstrate the efficacy of our paradigm. To the best of our knowledge, our work is the first paper in the literature of SPL that considers ranking fairness for self-paced regime construction.
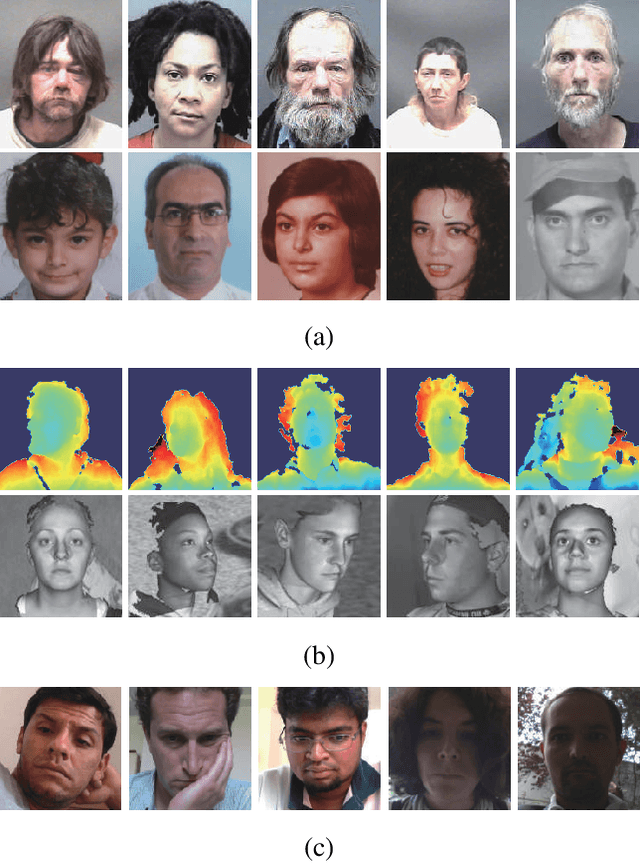
SD-GAN: Structural and Denoising GAN reveals facial parts under occlusion
Feb 19, 2020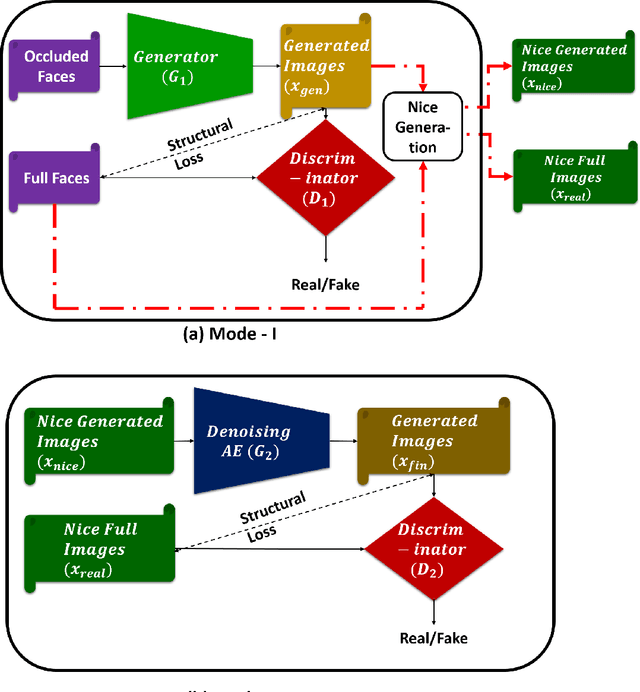
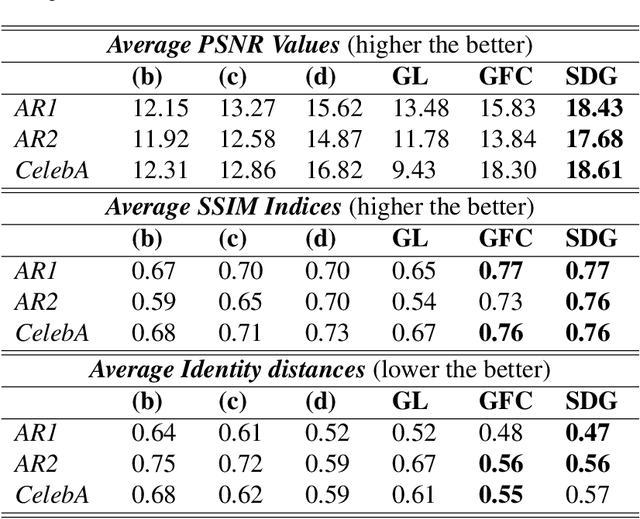
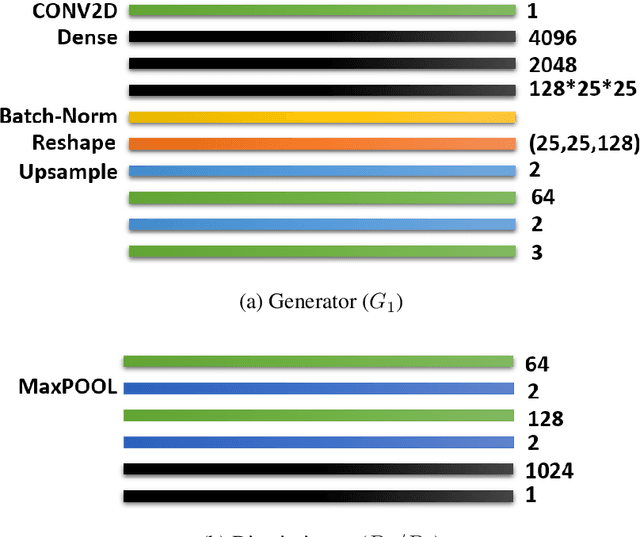
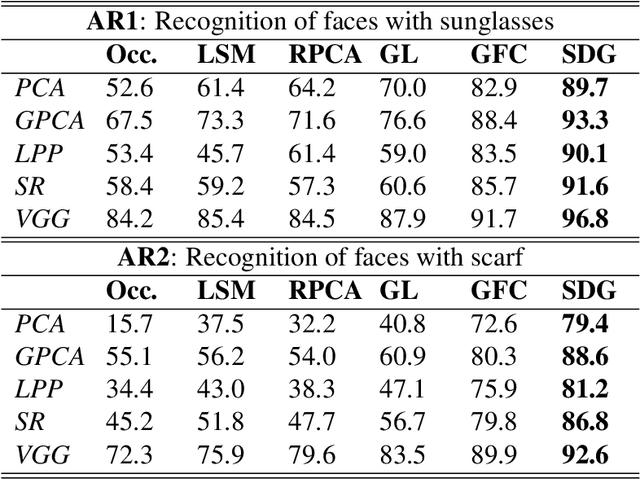
Certain facial parts are salient (unique) in appearance, which substantially contribute to the holistic recognition of a subject. Occlusion of these salient parts deteriorates the performance of face recognition algorithms. In this paper, we propose a generative model to reconstruct the missing parts of the face which are under occlusion. The proposed generative model (SD-GAN) reconstructs a face preserving the illumination variation and identity of the face. A novel adversarial training algorithm has been designed for a bimodal mutually exclusive Generative Adversarial Network (GAN) model, for faster convergence. A novel adversarial "structural" loss function is also proposed, comprising of two components: a holistic and a local loss, characterized by SSIM and patch-wise MSE. Ablation studies on real and synthetically occluded face datasets reveal that our proposed technique outperforms the competing methods by a considerable margin, even for boosting the performance of Face Recognition.
Two Birds with One Stone: Transforming and Generating Facial Images with Iterative GAN
Mar 07, 2018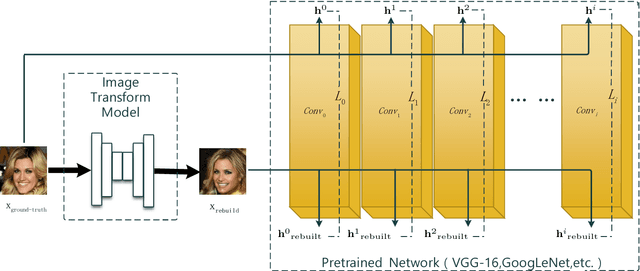

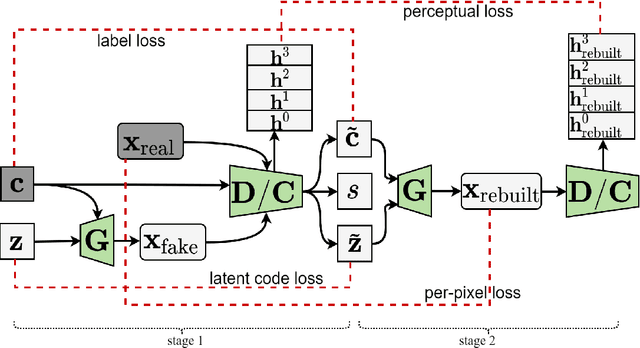

Generating high fidelity identity-preserving faces with different facial attributes has a wide range of applications. Although a number of generative models have been developed to tackle this problem, there is still much room for further improvement.In paticular, the current solutions usually ignore the perceptual information of images, which we argue that it benefits the output of a high-quality image while preserving the identity information, especially in facial attributes learning area.To this end, we propose to train GAN iteratively via regularizing the min-max process with an integrated loss, which includes not only the per-pixel loss but also the perceptual loss. In contrast to the existing methods only deal with either image generation or transformation, our proposed iterative architecture can achieve both of them. Experiments on the multi-label facial dataset CelebA demonstrate that the proposed model has excellent performance on recognizing multiple attributes, generating a high-quality image, and transforming image with controllable attributes.
VEGAC: Visual Saliency-based Age, Gender, and Facial Expression Classification Using Convolutional Neural Networks
Mar 13, 2018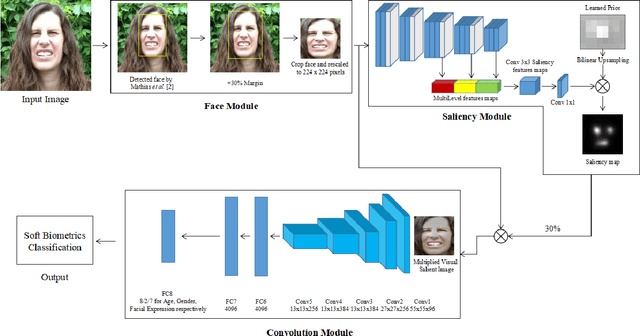
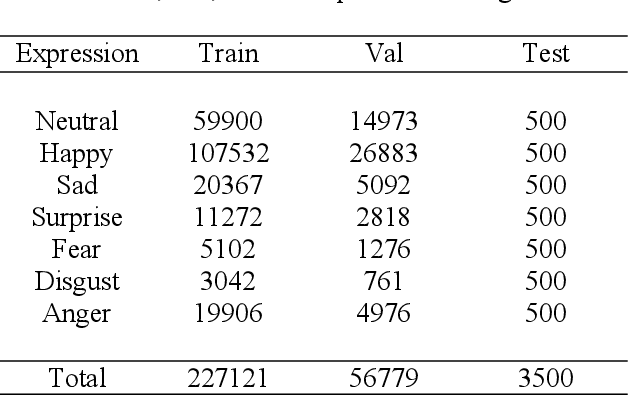
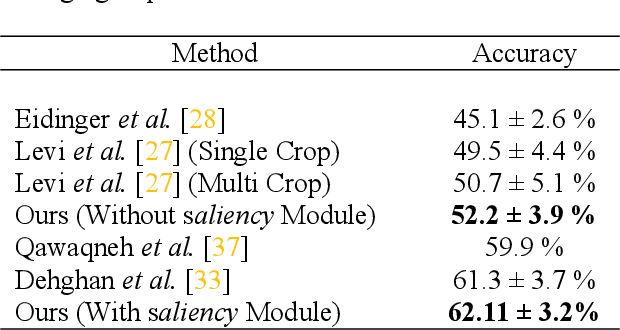

This paper explores the use of Visual Saliency to Classify Age, Gender and Facial Expression for Facial Images. For multi-task classification, we propose our method VEGAC, which is based on Visual Saliency. Using the Deep Multi-level Network [1] and off-the-shelf face detector [2], our proposed method first detects the face in the test image and extracts the CNN predictions on the cropped face. The CNN of VEGAC were fine-tuned on the collected dataset from different benchmarks. Our convolutional neural network (CNN) uses the VGG-16 architecture [3] and is pre-trained on ImageNet for image classification. We demonstrate the usefulness of our method for Age Estimation, Gender Classification, and Facial Expression Classification. We show that we obtain the competitive result with our method on selected benchmarks. All our models and code will be publically available.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021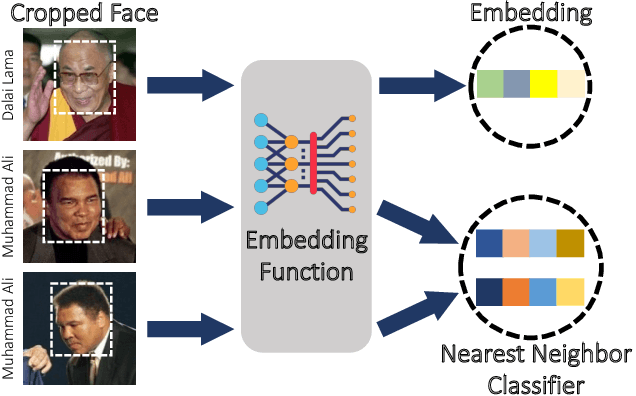
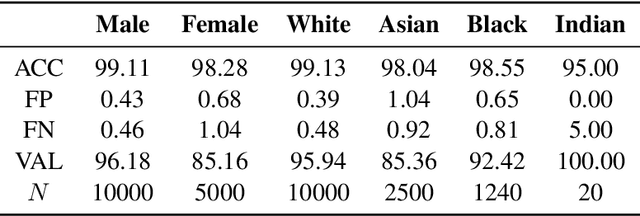
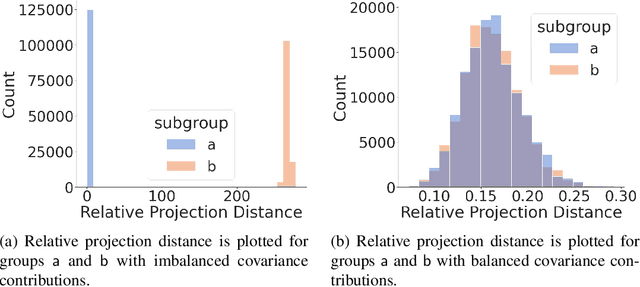
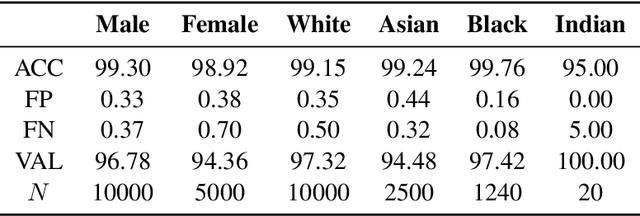
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
Fusing Body Posture with Facial Expressions for Joint Recognition of Affect in Child-Robot Interaction
Jan 07, 2019
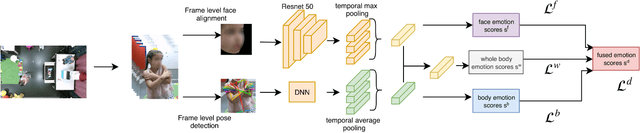

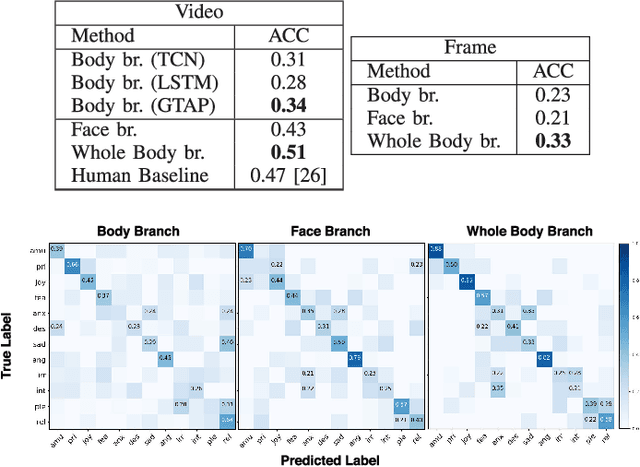
In this paper we address the problem of multi-cue affect recognition in challenging environments such as child-robot interaction. Towards this goal we propose a method for automatic recognition of affect that leverages body expressions alongside facial expressions, as opposed to traditional methods that usually focus only on the latter. We evaluate our methods on a challenging child-robot interaction database of emotional expressions, as well as on a database of emotional expressions by actors, and show that the proposed method achieves significantly better results when compared with the facial expression baselines, can be trained both jointly and separately, and offers us computational models for both the individual modalities, as well as for the whole body emotion.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022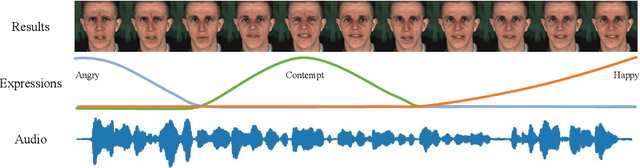
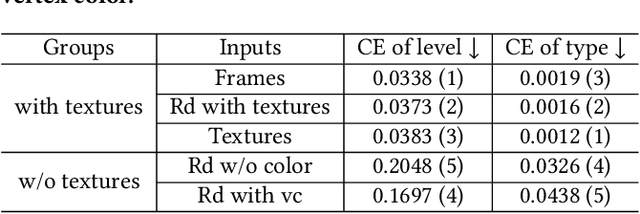
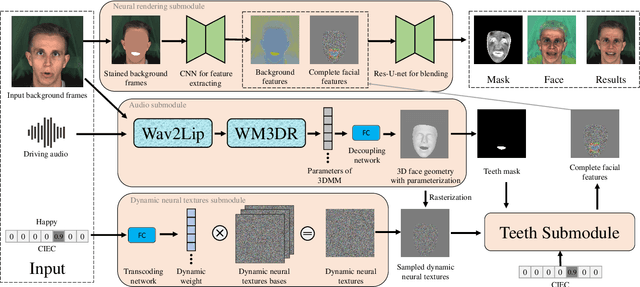
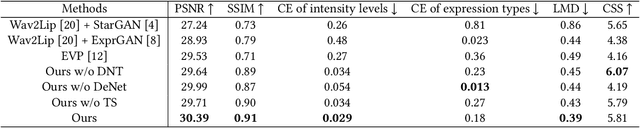
Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.
Portrait Eyeglasses and Shadow Removal by Leveraging 3D Synthetic Data
Mar 20, 2022
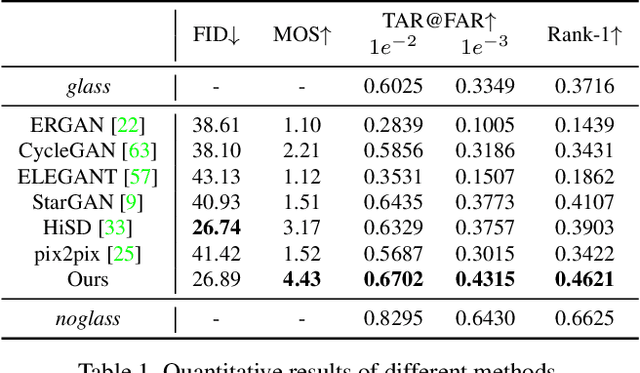
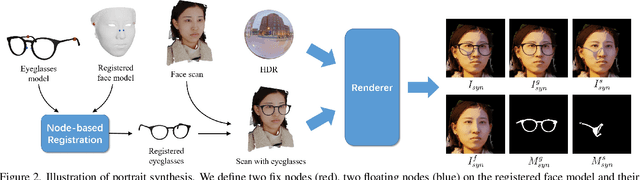
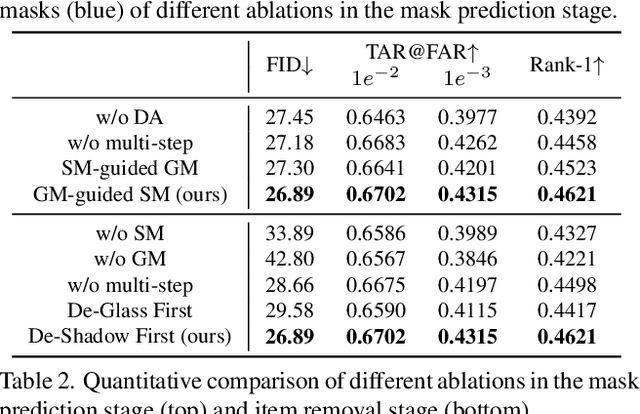
In portraits, eyeglasses may occlude facial regions and generate cast shadows on faces, which degrades the performance of many techniques like face verification and expression recognition. Portrait eyeglasses removal is critical in handling these problems. However, completely removing the eyeglasses is challenging because the lighting effects (e.g., cast shadows) caused by them are often complex. In this paper, we propose a novel framework to remove eyeglasses as well as their cast shadows from face images. The method works in a detect-then-remove manner, in which eyeglasses and cast shadows are both detected and then removed from images. Due to the lack of paired data for supervised training, we present a new synthetic portrait dataset with both intermediate and final supervisions for both the detection and removal tasks. Furthermore, we apply a cross-domain technique to fill the gap between the synthetic and real data. To the best of our knowledge, the proposed technique is the first to remove eyeglasses and their cast shadows simultaneously. The code and synthetic dataset are available at https://github.com/StoryMY/take-off-eyeglasses.