 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024
In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
Deformable One-shot Face Stylization via DINO Semantic Guidance
Mar 04, 2024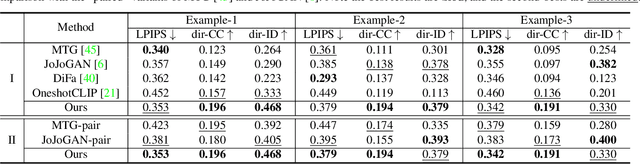


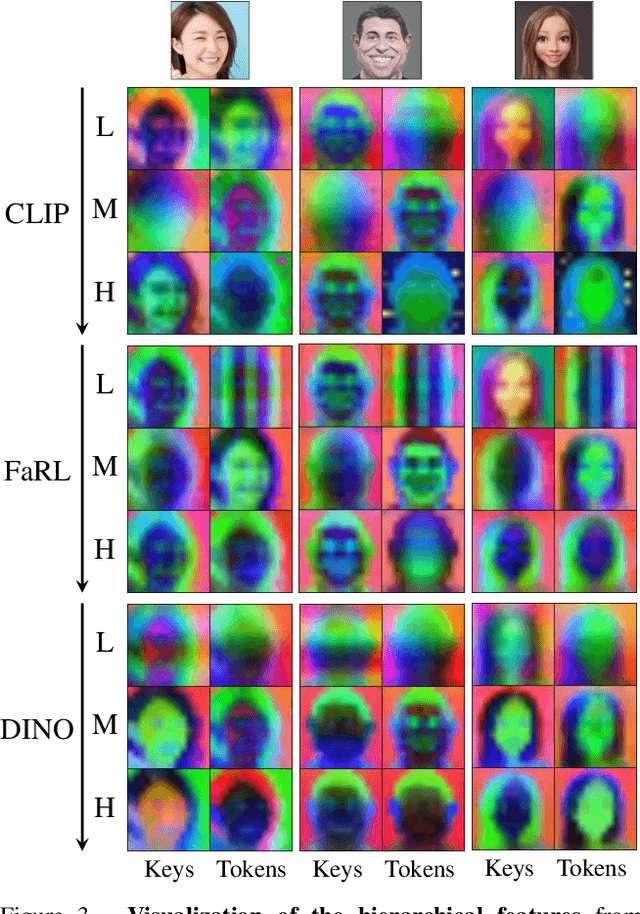
This paper addresses the complex issue of one-shot face stylization, focusing on the simultaneous consideration of appearance and structure, where previous methods have fallen short. We explore deformation-aware face stylization that diverges from traditional single-image style reference, opting for a real-style image pair instead. The cornerstone of our method is the utilization of a self-supervised vision transformer, specifically DINO-ViT, to establish a robust and consistent facial structure representation across both real and style domains. Our stylization process begins by adapting the StyleGAN generator to be deformation-aware through the integration of spatial transformers (STN). We then introduce two innovative constraints for generator fine-tuning under the guidance of DINO semantics: i) a directional deformation loss that regulates directional vectors in DINO space, and ii) a relative structural consistency constraint based on DINO token self-similarities, ensuring diverse generation. Additionally, style-mixing is employed to align the color generation with the reference, minimizing inconsistent correspondences. This framework delivers enhanced deformability for general one-shot face stylization, achieving notable efficiency with a fine-tuning duration of approximately 10 minutes. Extensive qualitative and quantitative comparisons demonstrate our superiority over state-of-the-art one-shot face stylization methods. Code is available at https://github.com/zichongc/DoesFS
Diverse and Lifespan Facial Age Transformation Synthesis with Identity Variation Rationality Metric
Jan 25, 2024Face aging has received continuous research attention over the past two decades. Although previous works on this topic have achieved impressive success, two longstanding problems remain unsettled: 1) generating diverse and plausible facial aging patterns at the target age stage; 2) measuring the rationality of identity variation between the original portrait and its syntheses with age progression or regression. In this paper, we introduce DLAT + , the first algorithm that can realize Diverse and Lifespan Age Transformation on human faces, where the diversity jointly manifests in the transformation of facial textures and shapes. Apart from the diversity mechanism embedded in the model, multiple consistency restrictions are leveraged to keep it away from counterfactual aging syntheses. Moreover, we propose a new metric to assess the rationality of Identity Deviation under Age Gaps (IDAG) between the input face and its series of age-transformed generations, which is based on statistical laws summarized from plenty of genuine face-aging data. Extensive experimental results demonstrate the uniqueness and effectiveness of our method in synthesizing diverse and perceptually reasonable faces across the whole lifetime.
Hearing Loss Detection from Facial Expressions in One-on-one Conversations
Jan 17, 2024Individuals with impaired hearing experience difficulty in conversations, especially in noisy environments. This difficulty often manifests as a change in behavior and may be captured via facial expressions, such as the expression of discomfort or fatigue. In this work, we build on this idea and introduce the problem of detecting hearing loss from an individual's facial expressions during a conversation. Building machine learning models that can represent hearing-related facial expression changes is a challenge. In addition, models need to disentangle spurious age-related correlations from hearing-driven expressions. To this end, we propose a self-supervised pre-training strategy tailored for the modeling of expression variations. We also use adversarial representation learning to mitigate the age bias. We evaluate our approach on a large-scale egocentric dataset with real-world conversational scenarios involving subjects with hearing loss and show that our method for hearing loss detection achieves superior performance over baselines.
Bias in Generative AI
Mar 05, 2024
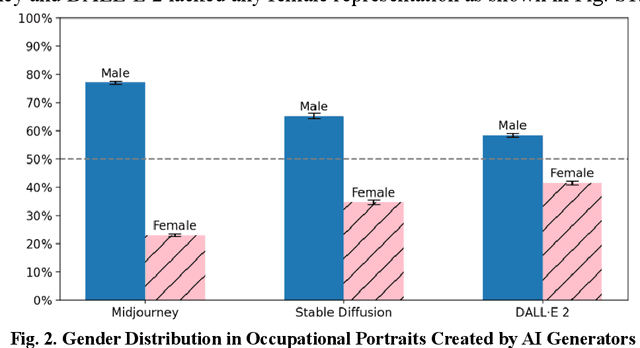
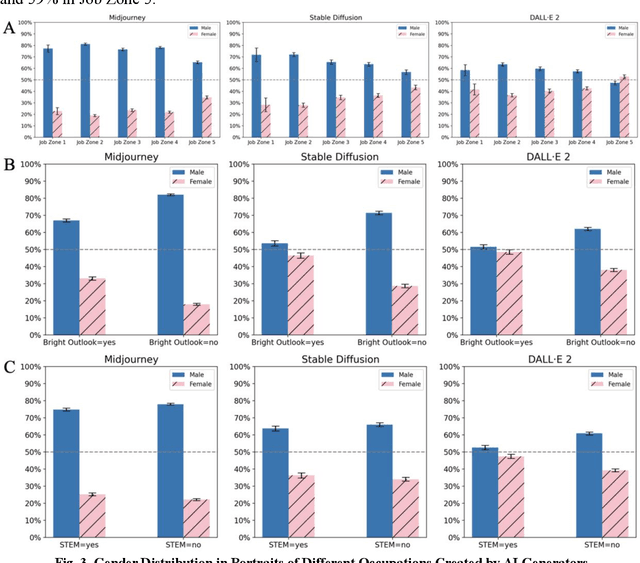
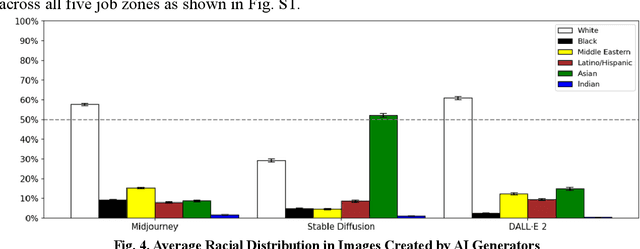
This study analyzed images generated by three popular generative artificial intelligence (AI) tools - Midjourney, Stable Diffusion, and DALLE 2 - representing various occupations to investigate potential bias in AI generators. Our analysis revealed two overarching areas of concern in these AI generators, including (1) systematic gender and racial biases, and (2) subtle biases in facial expressions and appearances. Firstly, we found that all three AI generators exhibited bias against women and African Americans. Moreover, we found that the evident gender and racial biases uncovered in our analysis were even more pronounced than the status quo when compared to labor force statistics or Google images, intensifying the harmful biases we are actively striving to rectify in our society. Secondly, our study uncovered more nuanced prejudices in the portrayal of emotions and appearances. For example, women were depicted as younger with more smiles and happiness, while men were depicted as older with more neutral expressions and anger, posing a risk that generative AI models may unintentionally depict women as more submissive and less competent than men. Such nuanced biases, by their less overt nature, might be more problematic as they can permeate perceptions unconsciously and may be more difficult to rectify. Although the extent of bias varied depending on the model, the direction of bias remained consistent in both commercial and open-source AI generators. As these tools become commonplace, our study highlights the urgency to identify and mitigate various biases in generative AI, reinforcing the commitment to ensuring that AI technologies benefit all of humanity for a more inclusive future.
IdentiFace : A VGG Based Multimodal Facial Biometric System
Jan 10, 2024The development of facial biometric systems has contributed greatly to the development of the computer vision field. Nowadays, there's always a need to develop a multimodal system that combines multiple biometric traits in an efficient, meaningful way. In this paper, we introduce "IdentiFace" which is a multimodal facial biometric system that combines the core of facial recognition with some of the most important soft biometric traits such as gender, face shape, and emotion. We also focused on developing the system using only VGG-16 inspired architecture with minor changes across different subsystems. This unification allows for simpler integration across modalities. It makes it easier to interpret the learned features between the tasks which gives a good indication about the decision-making process across the facial modalities and potential connection. For the recognition problem, we acquired a 99.2% test accuracy for five classes with high intra-class variations using data collected from the FERET database[1]. We achieved 99.4% on our dataset and 95.15% on the public dataset[2] in the gender recognition problem. We were also able to achieve a testing accuracy of 88.03% in the face-shape problem using the celebrity face-shape dataset[3]. Finally, we achieved a decent testing accuracy of 66.13% in the emotion task which is considered a very acceptable accuracy compared to related work on the FER2013 dataset[4].
Democratizing the Creation of Animatable Facial Avatars
Jan 29, 2024In high-end visual effects pipelines, a customized (and expensive) light stage system is (typically) used to scan an actor in order to acquire both geometry and texture for various expressions. Aiming towards democratization, we propose a novel pipeline for obtaining geometry and texture as well as enough expression information to build a customized person-specific animation rig without using a light stage or any other high-end hardware (or manual cleanup). A key novel idea consists of warping real-world images to align with the geometry of a template avatar and subsequently projecting the warped image into the template avatar's texture; importantly, this allows us to leverage baked-in real-world lighting/texture information in order to create surrogate facial features (and bridge the domain gap) for the sake of geometry reconstruction. Not only can our method be used to obtain a neutral expression geometry and de-lit texture, but it can also be used to improve avatars after they have been imported into an animation system (noting that such imports tend to be lossy, while also hallucinating various features). Since a default animation rig will contain template expressions that do not correctly correspond to those of a particular individual, we use a Simon Says approach to capture various expressions and build a person-specific animation rig (that moves like they do). Our aforementioned warping/projection method has high enough efficacy to reconstruct geometry corresponding to each expressions.
Context-aware Talking Face Video Generation
Feb 28, 2024In this paper, we consider a novel and practical case for talking face video generation. Specifically, we focus on the scenarios involving multi-people interactions, where the talking context, such as audience or surroundings, is present. In these situations, the video generation should take the context into consideration in order to generate video content naturally aligned with driving audios and spatially coherent to the context. To achieve this, we provide a two-stage and cross-modal controllable video generation pipeline, taking facial landmarks as an explicit and compact control signal to bridge the driving audio, talking context and generated videos. Inside this pipeline, we devise a 3D video diffusion model, allowing for efficient contort of both spatial conditions (landmarks and context video), as well as audio condition for temporally coherent generation. The experimental results verify the advantage of the proposed method over other baselines in terms of audio-video synchronization, video fidelity and frame consistency.
SVFAP: Self-supervised Video Facial Affect Perceiver
Dec 31, 2023Video-based facial affect analysis has recently attracted increasing attention owing to its critical role in human-computer interaction. Previous studies mainly focus on developing various deep learning architectures and training them in a fully supervised manner. Although significant progress has been achieved by these supervised methods, the longstanding lack of large-scale high-quality labeled data severely hinders their further improvements. Motivated by the recent success of self-supervised learning in computer vision, this paper introduces a self-supervised approach, termed Self-supervised Video Facial Affect Perceiver (SVFAP), to address the dilemma faced by supervised methods. Specifically, SVFAP leverages masked facial video autoencoding to perform self-supervised pre-training on massive unlabeled facial videos. Considering that large spatiotemporal redundancy exists in facial videos, we propose a novel temporal pyramid and spatial bottleneck Transformer as the encoder of SVFAP, which not only enjoys low computational cost but also achieves excellent performance. To verify the effectiveness of our method, we conduct experiments on nine datasets spanning three downstream tasks, including dynamic facial expression recognition, dimensional emotion recognition, and personality recognition. Comprehensive results demonstrate that SVFAP can learn powerful affect-related representations via large-scale self-supervised pre-training and it significantly outperforms previous state-of-the-art methods on all datasets. Codes will be available at https://github.com/sunlicai/SVFAP.
Headset: Human emotion awareness under partial occlusions multimodal dataset
Feb 14, 2024The volumetric representation of human interactions is one of the fundamental domains in the development of immersive media productions and telecommunication applications. Particularly in the context of the rapid advancement of Extended Reality (XR) applications, this volumetric data has proven to be an essential technology for future XR elaboration. In this work, we present a new multimodal database to help advance the development of immersive technologies. Our proposed database provides ethically compliant and diverse volumetric data, in particular 27 participants displaying posed facial expressions and subtle body movements while speaking, plus 11 participants wearing head-mounted displays (HMDs). The recording system consists of a volumetric capture (VoCap) studio, including 31 synchronized modules with 62 RGB cameras and 31 depth cameras. In addition to textured meshes, point clouds, and multi-view RGB-D data, we use one Lytro Illum camera for providing light field (LF) data simultaneously. Finally, we also provide an evaluation of our dataset employment with regard to the tasks of facial expression classification, HMDs removal, and point cloud reconstruction. The dataset can be helpful in the evaluation and performance testing of various XR algorithms, including but not limited to facial expression recognition and reconstruction, facial reenactment, and volumetric video. HEADSET and its all associated raw data and license agreement will be publicly available for research purposes.