 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Photo-realistic Facial Texture Transfer
Jun 14, 2017

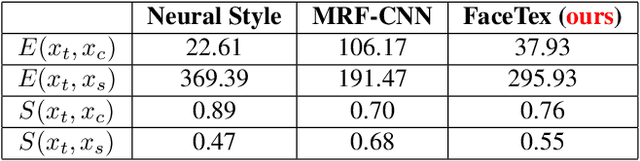

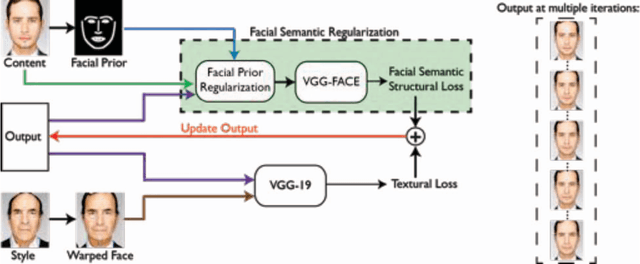
Style transfer methods have achieved significant success in recent years with the use of convolutional neural networks. However, many of these methods concentrate on artistic style transfer with few constraints on the output image appearance. We address the challenging problem of transferring face texture from a style face image to a content face image in a photorealistic manner without changing the identity of the original content image. Our framework for face texture transfer (FaceTex) augments the prior work of MRF-CNN with a novel facial semantic regularization that incorporates a face prior regularization smoothly suppressing the changes around facial meso-structures (e.g eyes, nose and mouth) and a facial structure loss function which implicitly preserves the facial structure so that face texture can be transferred without changing the original identity. We demonstrate results on face images and compare our approach with recent state-of-the-art methods. Our results demonstrate superior texture transfer because of the ability to maintain the identity of the original face image.
Face Anti-Spoofing from the Perspective of Data Sampling
Aug 28, 2022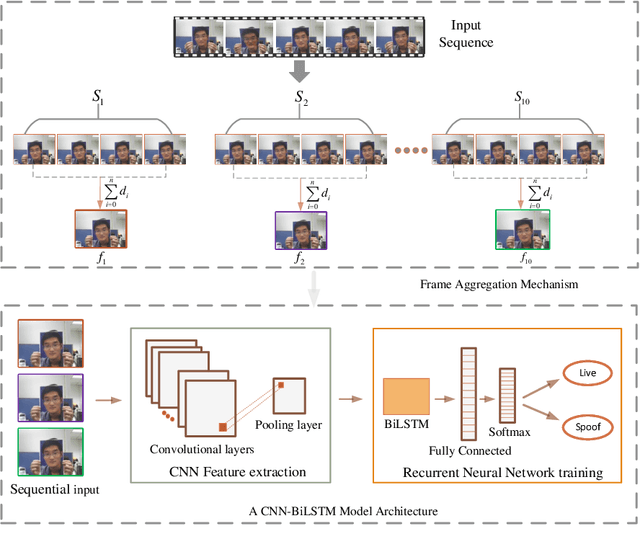

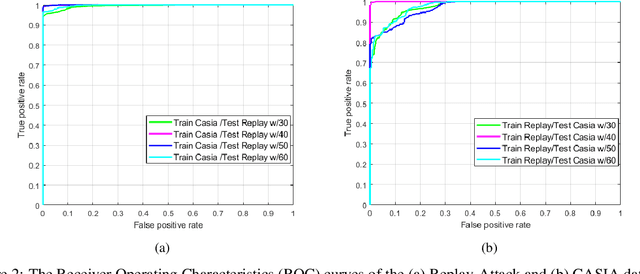
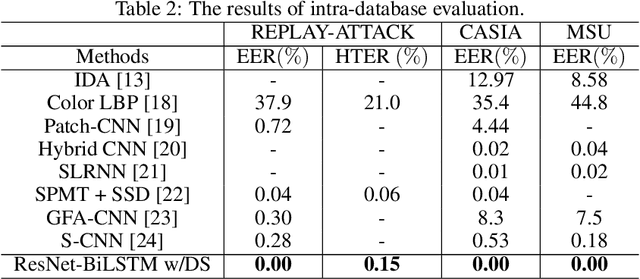
Without deploying face anti-spoofing countermeasures, face recognition systems can be spoofed by presenting a printed photo, a video, or a silicon mask of a genuine user. Thus, face presentation attack detection (PAD) plays a vital role in providing secure facial access to digital devices. Most existing video-based PAD countermeasures lack the ability to cope with long-range temporal variations in videos. Moreover, the key-frame sampling prior to the feature extraction step has not been widely studied in the face anti-spoofing domain. To mitigate these issues, this paper provides a data sampling approach by proposing a video processing scheme that models the long-range temporal variations based on Gaussian Weighting Function. Specifically, the proposed scheme encodes the consecutive t frames of video sequences into a single RGB image based on a Gaussian-weighted summation of the t frames. Using simply the data sampling scheme alone, we demonstrate that state-of-the-art performance can be achieved without any bells and whistles in both intra-database and inter-database testing scenarios for the three public benchmark datasets; namely, Replay-Attack, MSU-MFSD, and CASIA-FASD. In particular, the proposed scheme provides a much lower error (from 15.2% to 6.7% on CASIA-FASD and 5.9% to 4.9% on Replay-Attack) compared to baselines in cross-database scenarios.
SFF-DA: Sptialtemporal Feature Fusion for Detecting Anxiety Nonintrusively
Aug 12, 2022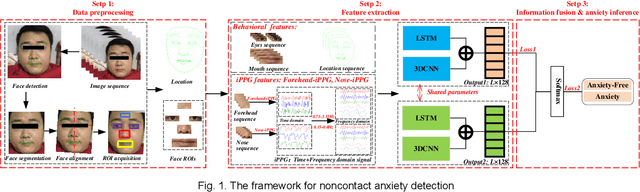
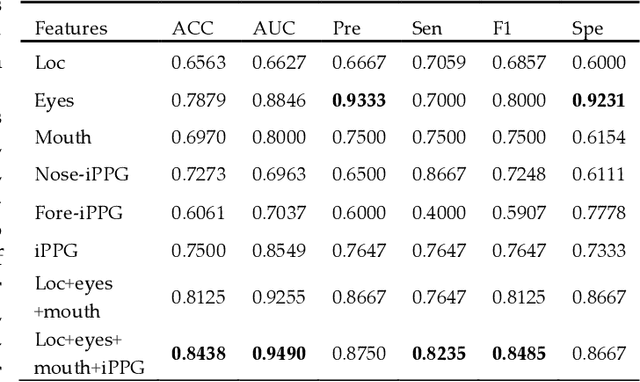
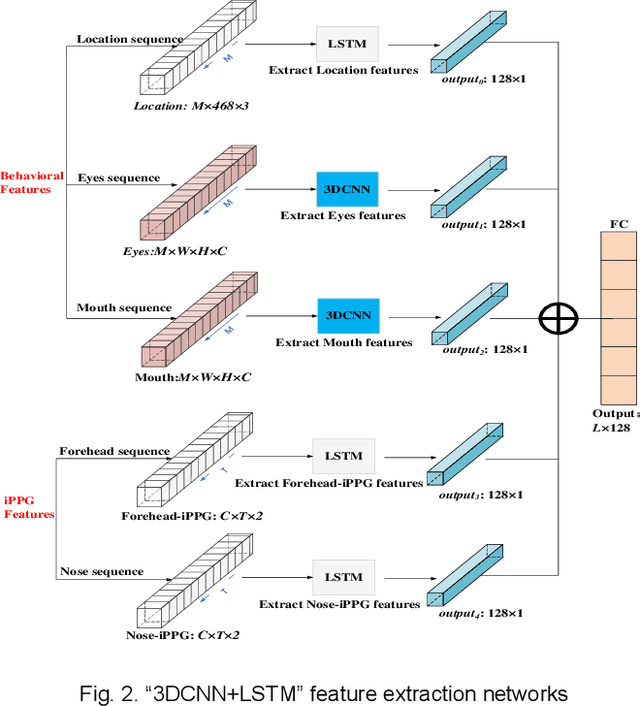
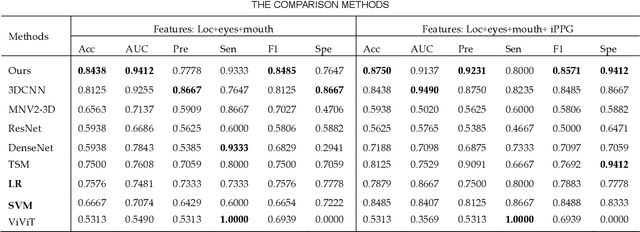
Early detection of anxiety disorders is essential to reduce the suffering of people with mental disorders and to improve treatment outcomes. Anxiety screening based on the mHealth platform is of particular practical value in improving screening efficiency and reducing screening costs. In practice, differences in mobile devices in subjects' physical and mental evaluations and the problems faced with uneven data quality and small sample sizes of data in the real world have made existing methods ineffective. Therefore, we propose a framework based on spatiotemporal feature fusion for detecting anxiety nonintrusively. To reduce the impact of uneven data quality, we constructed a feature extraction network based on "3DCNN+LSTM" and fused spatiotemporal features of facial behavior and noncontact physiology. Moreover, we designed a similarity assessment strategy to solve the problem that the small sample size of data leads to a decline in model accuracy. Our framework was validated with our crew dataset from the real world and two public datasets, UBFC-PHYS and SWELL-KW. The experimental results show that the overall performance of our framework was better than that of the state-of-the-art comparison methods.
Automatic Recognition of Facial Displays of Unfelt Emotions
Jan 09, 2018
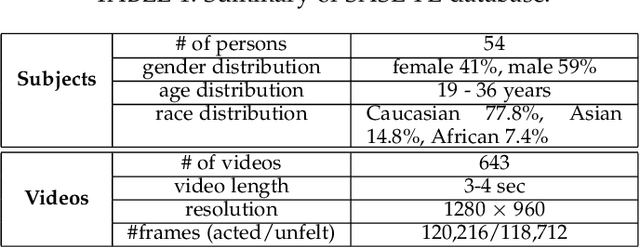

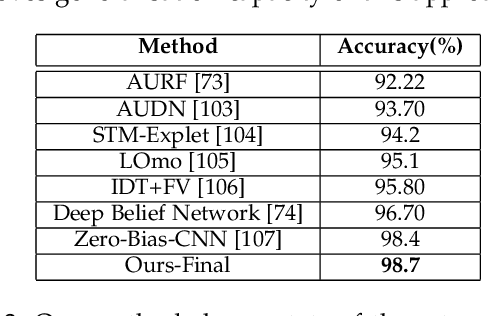
Humans modify their facial expressions in order to communicate their internal states and sometimes to mislead observers regarding their true emotional states. Evidence in experimental psychology shows that discriminative facial responses are short and subtle. This suggests that such behavior would be easier to distinguish when captured in high resolution at an increased frame rate. We are proposing SASE-FE, the first dataset of facial expressions that are either congruent or incongruent with underlying emotion states. We show that overall the problem of recognizing whether facial movements are expressions of authentic emotions or not can be successfully addressed by learning spatio-temporal representations of the data. For this purpose, we propose a method that aggregates features along fiducial trajectories in a deeply learnt space. Performance of the proposed model shows that on average it is easier to distinguish among genuine facial expressions of emotion than among unfelt facial expressions of emotion and that certain emotion pairs such as contempt and disgust are more difficult to distinguish than the rest. Furthermore, the proposed methodology improves state of the art results on CK+ and OULU-CASIA datasets for video emotion recognition, and achieves competitive results when classifying facial action units on BP4D datase.
Cross-subject Action Unit Detection with Meta Learning and Transformer-based Relation Modeling
May 18, 2022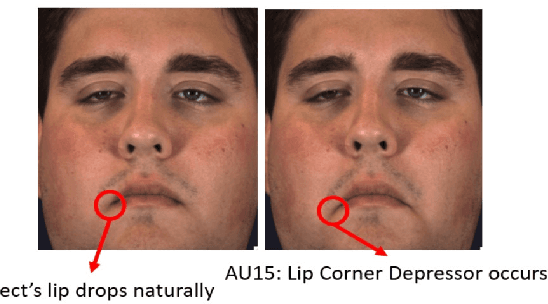
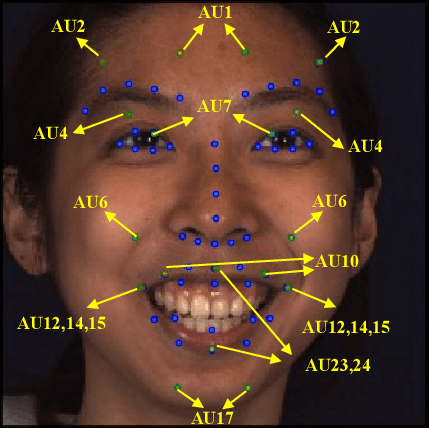
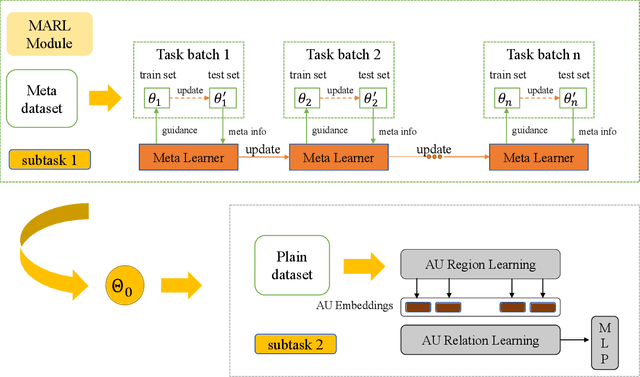
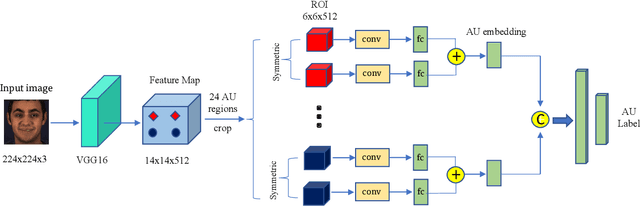
Facial Action Unit (AU) detection is a crucial task for emotion analysis from facial movements. The apparent differences of different subjects sometimes mislead changes brought by AUs, resulting in inaccurate results. However, most of the existing AU detection methods based on deep learning didn't consider the identity information of different subjects. The paper proposes a meta-learning-based cross-subject AU detection model to eliminate the identity-caused differences. Besides, a transformer-based relation learning module is introduced to learn the latent relations of multiple AUs. To be specific, our proposed work is composed of two sub-tasks. The first sub-task is meta-learning-based AU local region representation learning, called MARL, which learns discriminative representation of local AU regions that incorporates the shared information of multiple subjects and eliminates identity-caused differences. The second sub-task uses the local region representation of AU of the first sub-task as input, then adds relationship learning based on the transformer encoder architecture to capture AU relationships. The entire training process is cascaded. Ablation study and visualization show that our MARL can eliminate identity-caused differences, thus obtaining a robust and generalized AU discriminative embedding representation. Our results prove that on the two public datasets BP4D and DISFA, our method is superior to the state-of-the-art technology, and the F1 score is improved by 1.3% and 1.4%, respectively.
Hey Human, If your Facial Emotions are Uncertain, You Should Use Bayesian Neural Networks!
Aug 17, 2020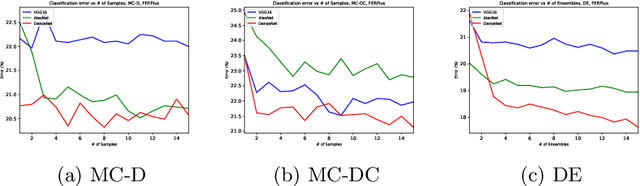
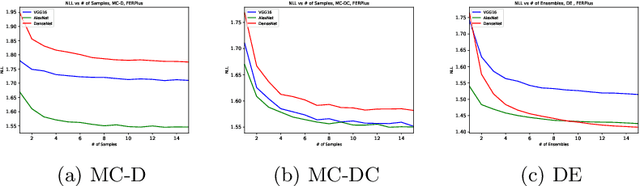
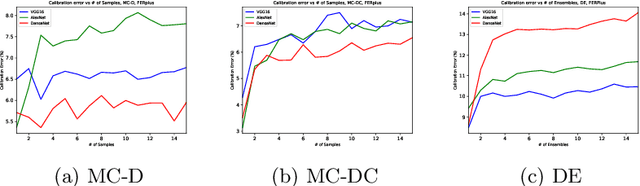
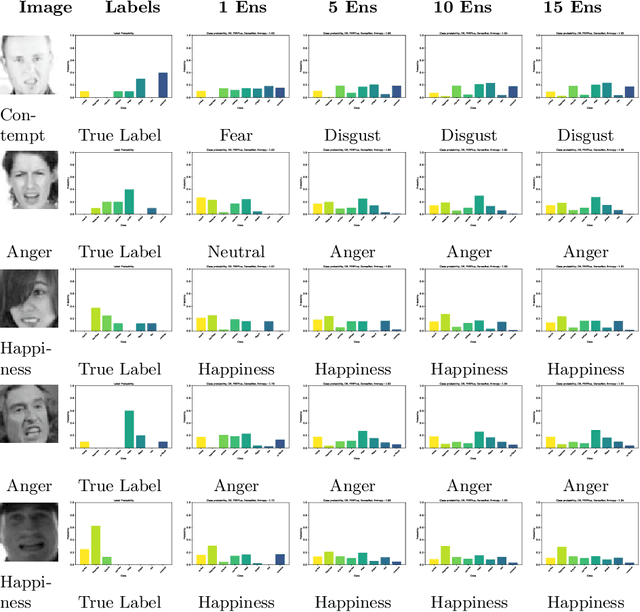
Facial emotion recognition is the task to classify human emotions in face images. It is a difficult task due to high aleatoric uncertainty and visual ambiguity. A large part of the literature aims to show progress by increasing accuracy on this task, but this ignores the inherent uncertainty and ambiguity in the task. In this paper we show that Bayesian Neural Networks, as approximated using MC-Dropout, MC-DropConnect, or an Ensemble, are able to model the aleatoric uncertainty in facial emotion recognition, and produce output probabilities that are closer to what a human expects. We also show that calibration metrics show strange behaviors for this task, due to the multiple classes that can be considered correct, which motivates future work. We believe our work will motivate other researchers to move away from Classical and into Bayesian Neural Networks.
Modeling Human Response to Robot Errors for Timely Error Detection
Aug 01, 2022

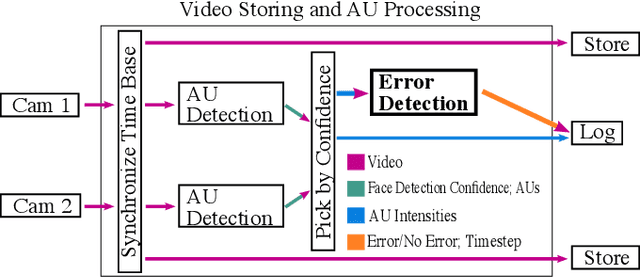
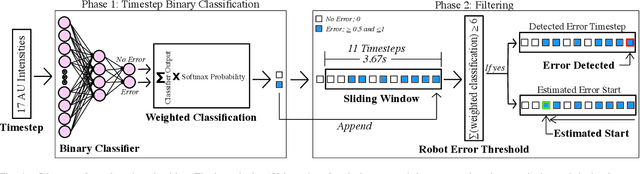
In human-robot collaboration, robot errors are inevitable -- damaging user trust, willingness to work together, and task performance. Prior work has shown that people naturally respond to robot errors socially and that in social interactions it is possible to use human responses to detect errors. However, there is little exploration in the domain of non-social, physical human-robot collaboration such as assembly and tool retrieval. In this work, we investigate how people's organic, social responses to robot errors may be used to enable timely automatic detection of errors in physical human-robot interactions. We conducted a data collection study to obtain facial responses to train a real-time detection algorithm and a case study to explore the generalizability of our method with different task settings and errors. Our results show that natural social responses are effective signals for timely detection and localization of robot errors even in non-social contexts and that our method is robust across a variety of task contexts, robot errors, and user responses. This work contributes to robust error detection without detailed task specifications.
Multi-view Deep Features for Robust Facial Kinship Verification
Jun 01, 2020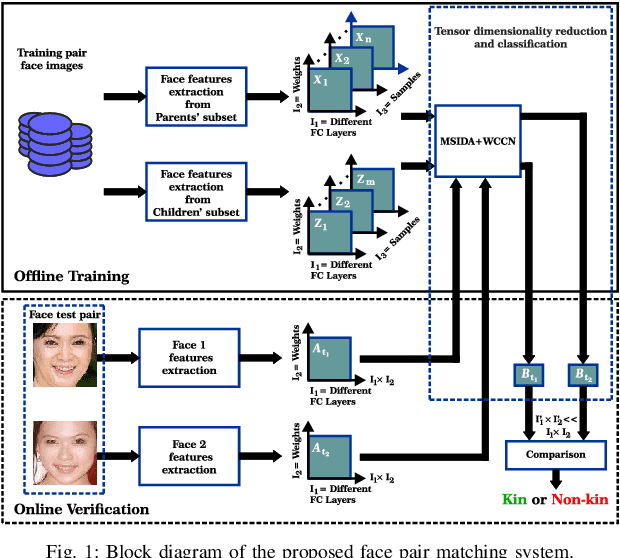
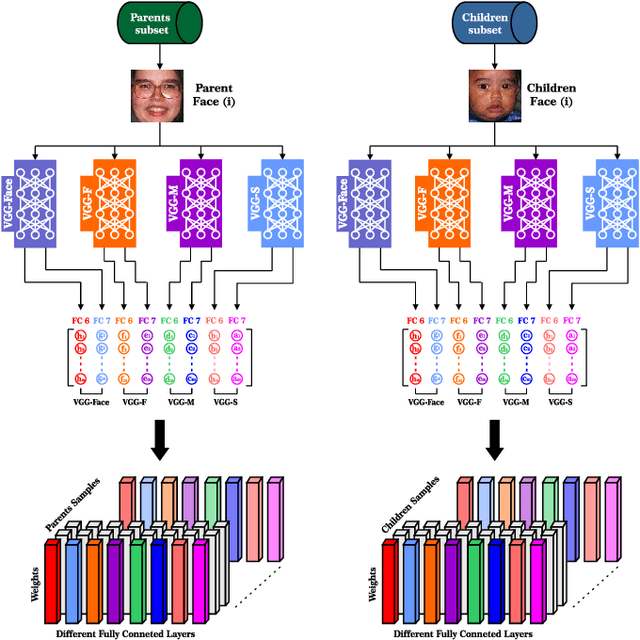
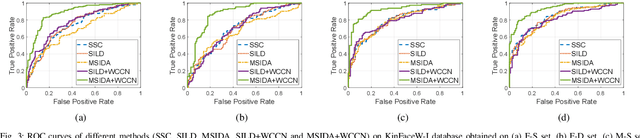
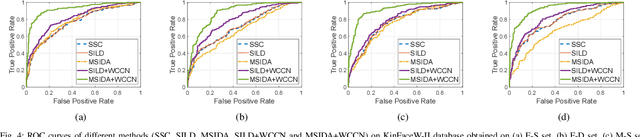
Automatic kinship verification from facial images is an emerging research topic in machine learning community. In this paper, we proposed an effective facial features extraction model based on multi-view deep features. Thus, we used four pre-trained deep learning models using eight features layers (FC6 and FC7 layers of each VGG-F, VGG-M, VGG-S and VGG-Face models) to train the proposed Multilinear Side-Information based Discriminant Analysis integrating Within Class Covariance Normalization (MSIDA+WCCN) method. Furthermore, we show that how can metric learning methods based on WCCN method integration improves the Simple Scoring Cosine similarity (SSC) method. We refer that we used the SSC method in RFIW'20 competition using the eight deep features concatenation. Thus, the integration of WCCN in the metric learning methods decreases the intra-class variations effect introduced by the deep features weights. We evaluate our proposed method on two kinship benchmarks namely KinFaceW-I and KinFaceW-II databases using four Parent-Child relations (Father-Son, Father-Daughter, Mother-Son and Mother-Daughter). Thus, the proposed MSIDA+WCCN method improves the SSC method with 12.80% and 14.65% on KinFaceW-I and KinFaceW-II databases, respectively. The results obtained are positively compared with some modern methods, including those that rely on deep learning.
MFEViT: A Robust Lightweight Transformer-based Network for Multimodal 2D+3D Facial Expression Recognition
Sep 20, 2021
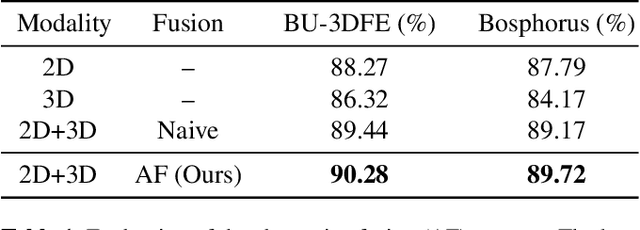
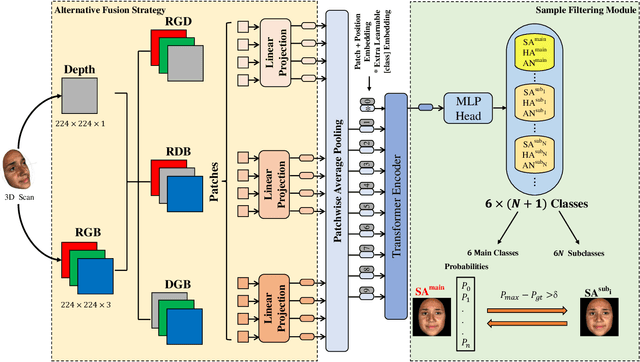
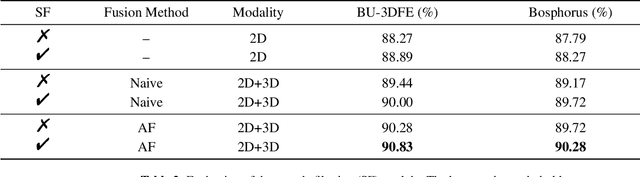
Vision transformer (ViT) has been widely applied in many areas due to its self-attention mechanism that help obtain the global receptive field since the first layer. It even achieves surprising performance exceeding CNN in some vision tasks. However, there exists an issue when leveraging vision transformer into 2D+3D facial expression recognition (FER), i.e., ViT training needs mass data. Nonetheless, the number of samples in public 2D+3D FER datasets is far from sufficient for evaluation. How to utilize the ViT pre-trained on RGB images to handle 2D+3D data becomes a challenge. To solve this problem, we propose a robust lightweight pure transformer-based network for multimodal 2D+3D FER, namely MFEViT. For narrowing the gap between RGB and multimodal data, we devise an alternative fusion strategy, which replaces each of the three channels of an RGB image with the depth-map channel and fuses them before feeding them into the transformer encoder. Moreover, the designed sample filtering module adds several subclasses for each expression and move the noisy samples to their corresponding subclasses, thus eliminating their disturbance on the network during the training stage. Extensive experiments demonstrate that our MFEViT outperforms state-of-the-art approaches with an accuracy of 90.83% on BU-3DFE and 90.28% on Bosphorus. Specifically, the proposed MFEViT is a lightweight model, requiring much fewer parameters than multi-branch CNNs. To the best of our knowledge, this is the first work to introduce vision transformer into multimodal 2D+3D FER. The source code of our MFEViT will be publicly available online.
Signal-level Fusion for Indexing and Retrieval of Facial Biometric Data
Mar 05, 2021
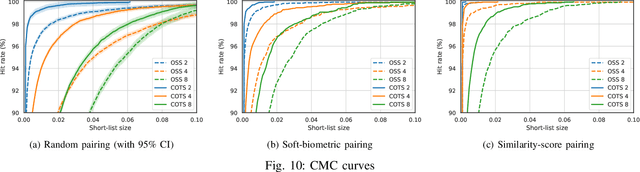

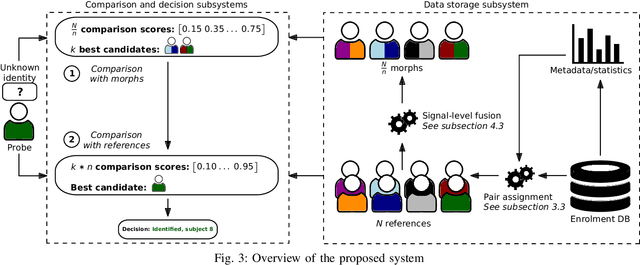
The growing scope, scale, and number of biometric deployments around the world emphasise the need for research into technologies facilitating efficient and reliable biometric identification queries. This work presents a method of indexing biometric databases, which relies on signal-level fusion of facial images (morphing) to create a multi-stage data-structure and retrieval protocol. By successively pre-filtering the list of potential candidate identities, the proposed method makes it possible to reduce the necessary number of biometric template comparisons to complete a biometric identification transaction. The proposed method is extensively evaluated on publicly available databases using open-source and commercial off-the-shelf recognition systems. The results show that using the proposed method, the computational workload can be reduced down to around 30%, while the biometric performance of a baseline exhaustive search-based retrieval is fully maintained, both in closed-set and open-set identification scenarios.