 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Motion Prior Networks for Facial Expression Recognition
Feb 23, 2019
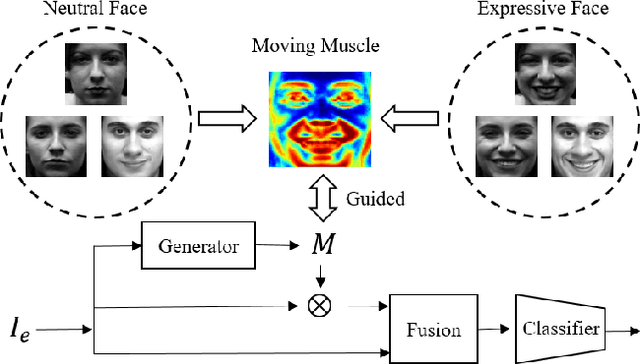
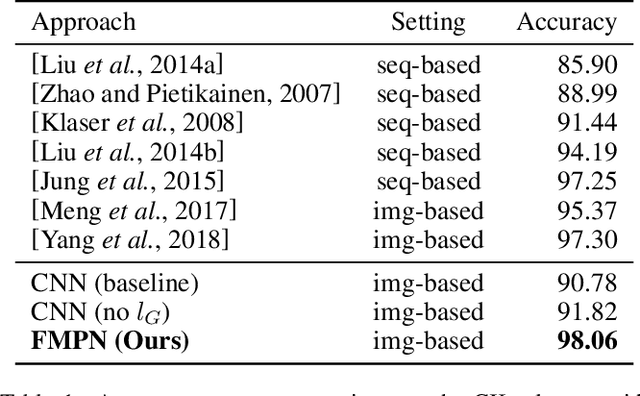
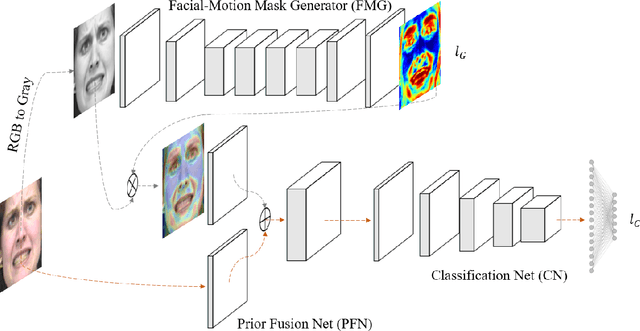
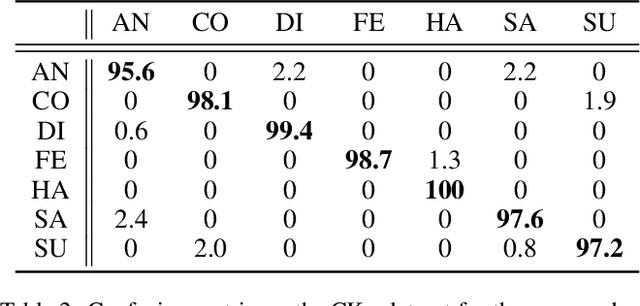
Deep learning based facial expression recognition (FER) has received a lot of attention in the past few years. Most of the existing deep learning based FER methods do not consider domain knowledge well, which thereby fail to extract representative features. In this work, we propose a novel FER framework, named Facial Motion Prior Networks (FMPN). Particularly, we introduce an addition branch to generate a facial mask so as to focus on facial muscle moving regions. To guide the facial mask learning, we propose to incorporate prior domain knowledge by using the average differences between neutral faces and the corresponding expressive faces as the guidance. Extensive experiments on four facial expression benchmark datasets demonstrate the effectiveness of the proposed method, compared with the state-of-the-art approaches.
Metric Learning for Anti-Compression Facial Forgery Detection
Mar 15, 2021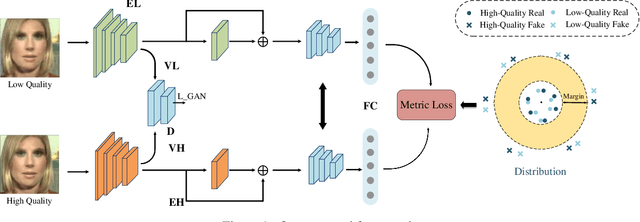
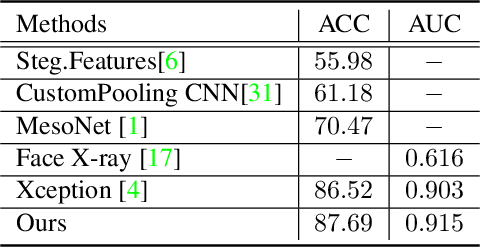
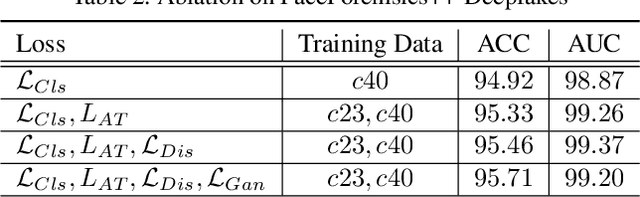
Detecting facial forgery images and videos is an increasingly important topic in multimedia forensics. As forgery images and videos are usually compressed to different formats such as JPEG and H264 when circulating on the Internet, existing forgery-detection methods trained on uncompressed data often have significantly decreased performance in identifying them. To solve this problem, we propose a novel anti-compression facial forgery detection framework, which learns a compression-insensitive embedding feature space utilizing both original and compressed forgeries. Specifically, our approach consists of two novel ideas: (i) extracting compression-insensitive features from both uncompressed and compressed forgeries using an adversarial learning strategy; (ii) learning a robust partition by constructing a metric loss that can reduce the distance of the paired original and compressed images in the embedding space. Experimental results demonstrate that, the proposed method is highly effective in handling both compressed and uncompressed facial forgery images.
Pixel-based Facial Expression Synthesis
Oct 27, 2020
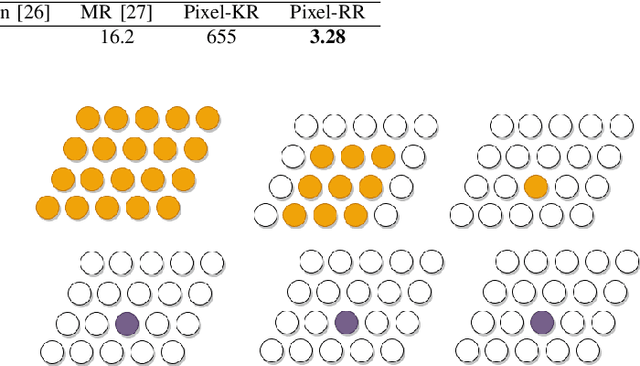


Facial expression synthesis has achieved remarkable advances with the advent of Generative Adversarial Networks (GANs). However, GAN-based approaches mostly generate photo-realistic results as long as the testing data distribution is close to the training data distribution. The quality of GAN results significantly degrades when testing images are from a slightly different distribution. Moreover, recent work has shown that facial expressions can be synthesized by changing localized face regions. In this work, we propose a pixel-based facial expression synthesis method in which each output pixel observes only one input pixel. The proposed method achieves good generalization capability by leveraging only a few hundred training images. Experimental results demonstrate that the proposed method performs comparably well against state-of-the-art GANs on in-dataset images and significantly better on out-of-dataset images. In addition, the proposed model is two orders of magnitude smaller which makes it suitable for deployment on resource-constrained devices.
Guided Facial Skin Color Correction
May 19, 2021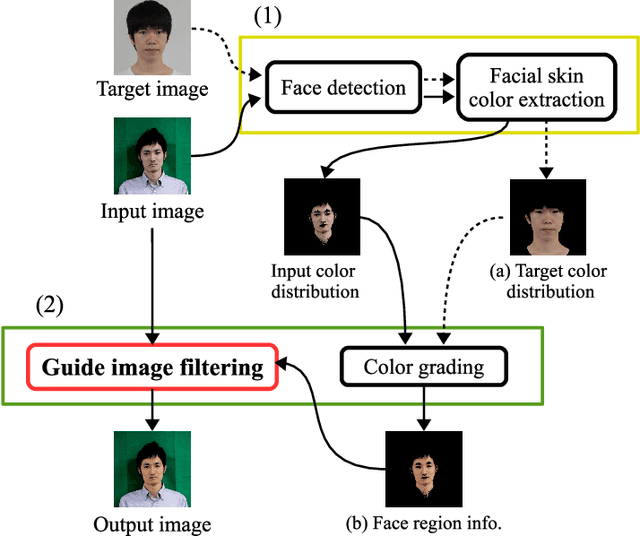

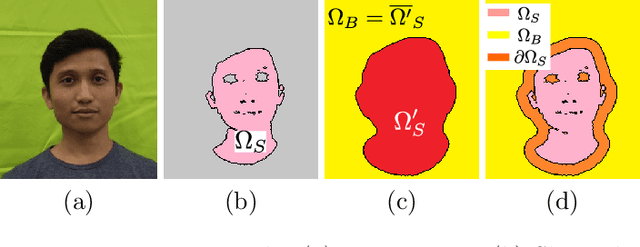

This paper proposes an automatic image correction method for portrait photographs, which promotes consistency of facial skin color by suppressing skin color changes due to background colors. In portrait photographs, skin color is often distorted due to the lighting environment (e.g., light reflected from a colored background wall and over-exposure by a camera strobe), and if the photo is artificially combined with another background color, this color change is emphasized, resulting in an unnatural synthesized result. In our framework, after roughly extracting the face region and rectifying the skin color distribution in a color space, we perform color and brightness correction around the face in the original image to achieve a proper color balance of the facial image, which is not affected by luminance and background colors. Unlike conventional algorithms for color correction, our final result is attained by a color correction process with a guide image. In particular, our guided image filtering for the color correction does not require a perfectly-aligned guide image required in the original guide image filtering method proposed by He et al. Experimental results show that our method generates more natural results than conventional methods on not only headshot photographs but also natural scene photographs. We also show automatic yearbook style photo generation as an another application.
Facial Landmark Correlation Analysis
Nov 24, 2019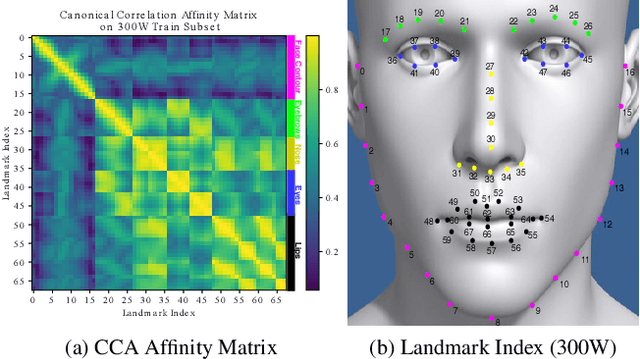


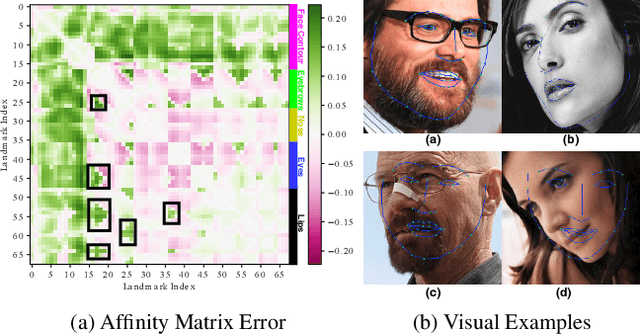
We present a facial landmark position correlation analysis as well as its applications. Although numerous facial landmark detection methods have been presented in the literature, few of them concern the intrinsic relationship among the landmarks. In order to reveal and interpret this relationship, we propose to analyze the facial landmark correlation by using Canonical Correlation Analysis (CCA). We experimentally show that dense facial landmark annotations in current benchmarks are strongly correlated, and we propose several applications based on this analysis. First, we give insights into the predictions from different facial landmark detection models (including cascaded random forests, cascaded Convolutional Neural Networks (CNNs), heatmap regression models) and interpret how CNNs progressively learn to predict facial landmarks. Second, we propose a few-shot learning method that allows to considerably reduce manual effort for dense landmark annotation. To this end, we select a portion of landmarks from the dense annotation format to form a sparse format, which is mostly correlated to the rest of them. Thanks to the strong correlation among the landmarks, the entire set of dense facial landmarks can then be inferred from the annotation in the sparse format by transfer learning. Unlike the previous methods, we mainly focus on how to find the most efficient sparse format to annotate. Overall, our correlation analysis provides new perspectives for the research on facial landmark detection.
Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms
Jan 30, 2022
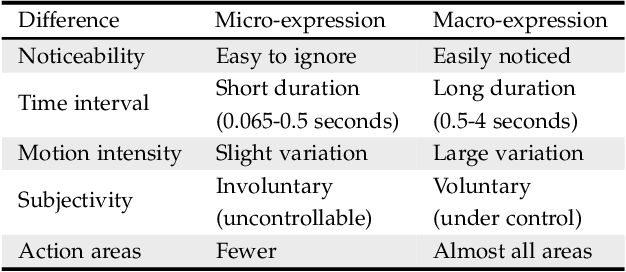
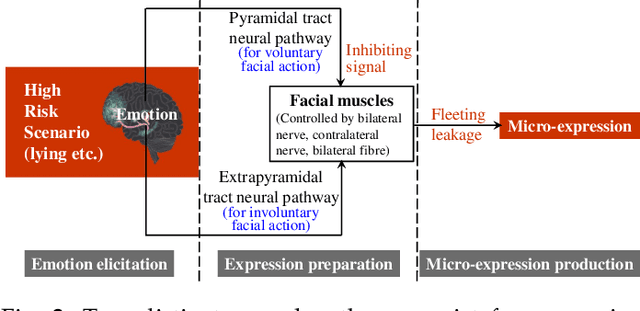
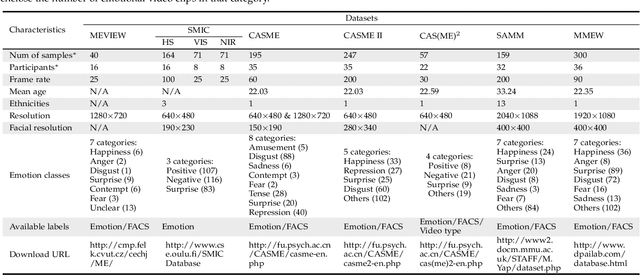
Unlike the conventional facial expressions, micro-expressions are involuntary and transient facial expressions capable of revealing the genuine emotions that people attempt to hide. Therefore, they can provide important information in a broad range of applications such as lie detection, criminal detection, etc. Since micro-expressions are transient and of low intensity, however, their detection and recognition is difficult and relies heavily on expert experiences. Due to its intrinsic particularity and complexity, video-based micro-expression analysis is attractive but challenging, and has recently become an active area of research. Although there have been numerous developments in this area, thus far there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences between macro- and micro-expressions, then use these differences to guide our research survey of video-based micro-expression analysis in a cascaded structure, encompassing the neuropsychological basis, datasets, features, spotting algorithms, recognition algorithms, applications and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are addressed and discussed. Furthermore, after considering the limitations of existing micro-expression datasets, we present and release a new dataset - called micro-and-macro expression warehouse (MMEW) - containing more video samples and more labeled emotion types. We then perform a unified comparison of representative methods on CAS(ME)2 for spotting, and on MMEW and SAMM for recognition, respectively. Finally, some potential future research directions are explored and outlined.
Personality Detection of Applicants And Employees Using K-mode Algorithm And Ocean Model
Dec 27, 2022The combination of conduct, emotion, motivation, and thinking is referred to as personality. To shortlist candidates more effectively, many organizations rely on personality predictions. The firm can hire or pick the best candidate for the desired job description by grouping applicants based on the necessary personality preferences. A model is created to identify applicants' personality types so that employers may find qualified candidates by examining a person's facial expression, speech intonation, and resume. Additionally, the paper emphasises detecting the changes in employee behaviour. Employee attitudes and behaviour towards each set of questions are being examined and analysed. Here, the K-Modes clustering method is used to predict employee well-being, including job pressure, the working environment, and relationships with peers, utilizing the OCEAN Model and the CNN algorithm in the AVI-AI administrative system. Findings imply that AVIs can be used for efficient candidate screening with an AI decision agent. The study of the specific field is beyond the current explorations and needed to be expanded with deeper models and new configurations that can patch extremely complex operations.
InterMulti:Multi-view Multimodal Interactions with Text-dominated Hierarchical High-order Fusion for Emotion Analysis
Dec 20, 2022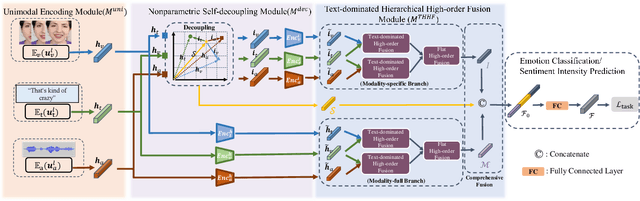
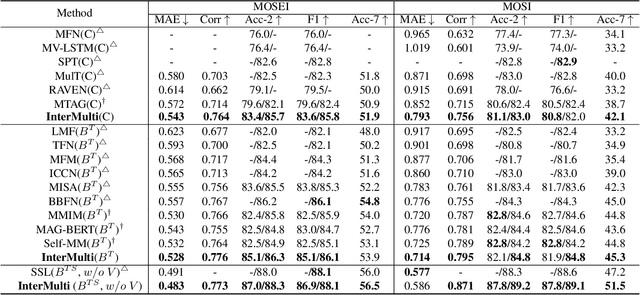
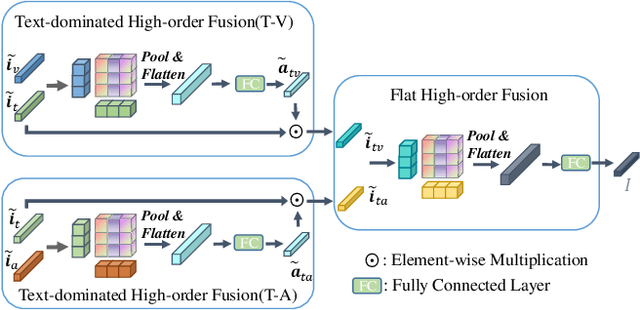
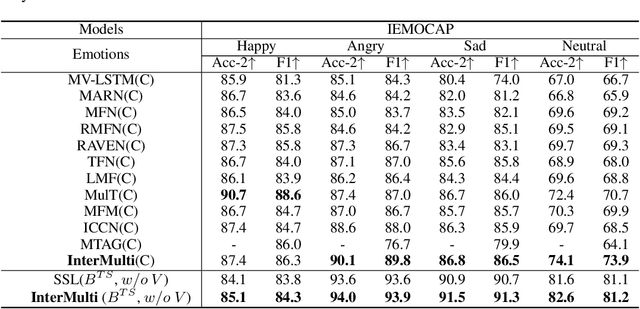
Humans are sophisticated at reading interlocutors' emotions from multimodal signals, such as speech contents, voice tones and facial expressions. However, machines might struggle to understand various emotions due to the difficulty of effectively decoding emotions from the complex interactions between multimodal signals. In this paper, we propose a multimodal emotion analysis framework, InterMulti, to capture complex multimodal interactions from different views and identify emotions from multimodal signals. Our proposed framework decomposes signals of different modalities into three kinds of multimodal interaction representations, including a modality-full interaction representation, a modality-shared interaction representation, and three modality-specific interaction representations. Additionally, to balance the contribution of different modalities and learn a more informative latent interaction representation, we developed a novel Text-dominated Hierarchical High-order Fusion(THHF) module. THHF module reasonably integrates the above three kinds of representations into a comprehensive multimodal interaction representation. Extensive experimental results on widely used datasets, (i.e.) MOSEI, MOSI and IEMOCAP, demonstrate that our method outperforms the state-of-the-art.
Controllable Face Manipulation and UV Map Generation by Self-supervised Learning
Sep 24, 2022

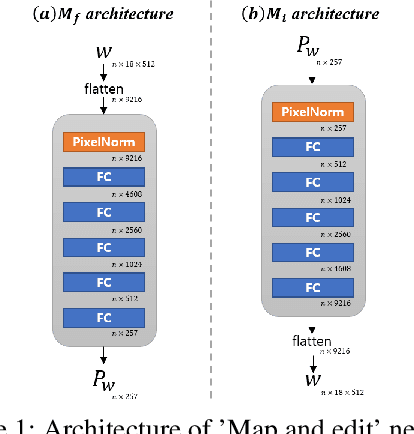
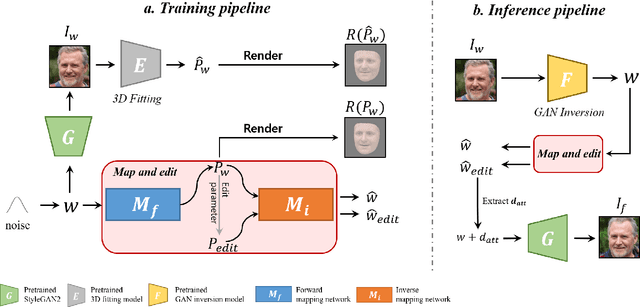
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.
Meta Auxiliary Learning for Facial Action Unit Detection
May 14, 2021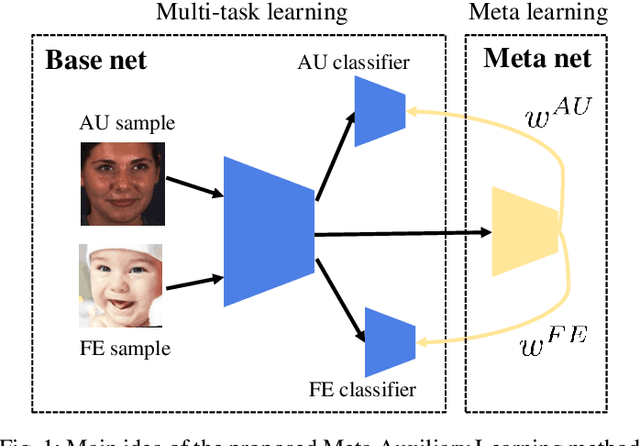
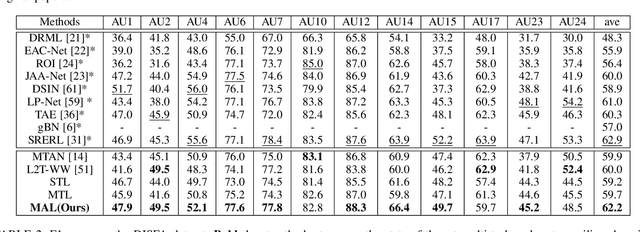
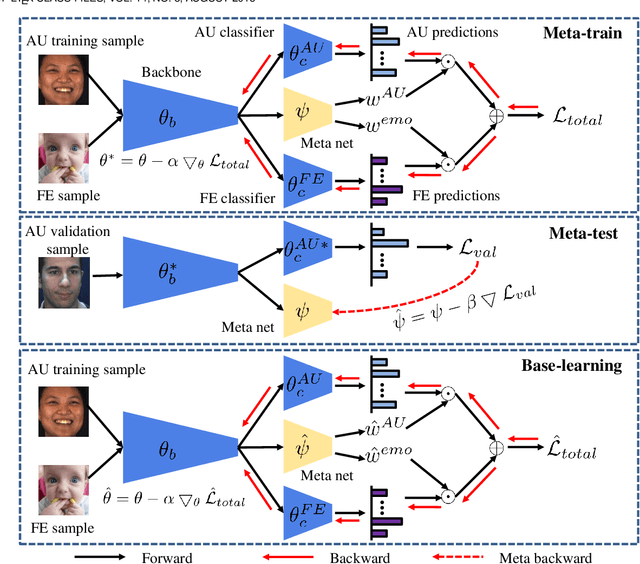
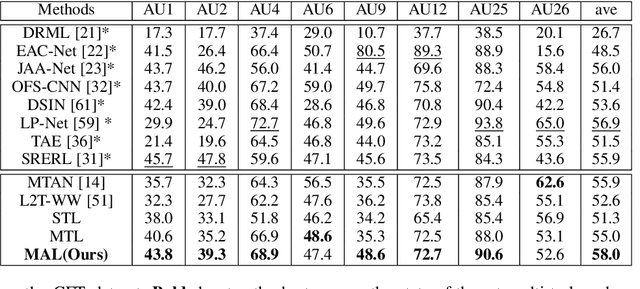
Despite the success of deep neural networks on facial action unit (AU) detection, better performance depends on a large number of training images with accurate AU annotations. However, labeling AU is time-consuming, expensive, and error-prone. Considering AU detection and facial expression recognition (FER) are two highly correlated tasks, and facial expression (FE) is relatively easy to annotate, we consider learning AU detection and FER in a multi-task manner. However, the performance of the AU detection task cannot be always enhanced due to the negative transfer in the multi-task scenario. To alleviate this issue, we propose a Meta Auxiliary Learning method (MAL) that automatically selects highly related FE samples by learning adaptative weights for the training FE samples in a meta learning manner. The learned sample weights alleviate the negative transfer from two aspects: 1) balance the loss of each task automatically, and 2) suppress the weights of FE samples that have large uncertainties. Experimental results on several popular AU datasets demonstrate MAL consistently improves the AU detection performance compared with the state-of-the-art multi-task and auxiliary learning methods. MAL automatically estimates adaptive weights for the auxiliary FE samples according to their semantic relevance with the primary AU detection task.