 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SleepyWheels: An Ensemble Model for Drowsiness Detection leading to Accident Prevention
Nov 01, 2022
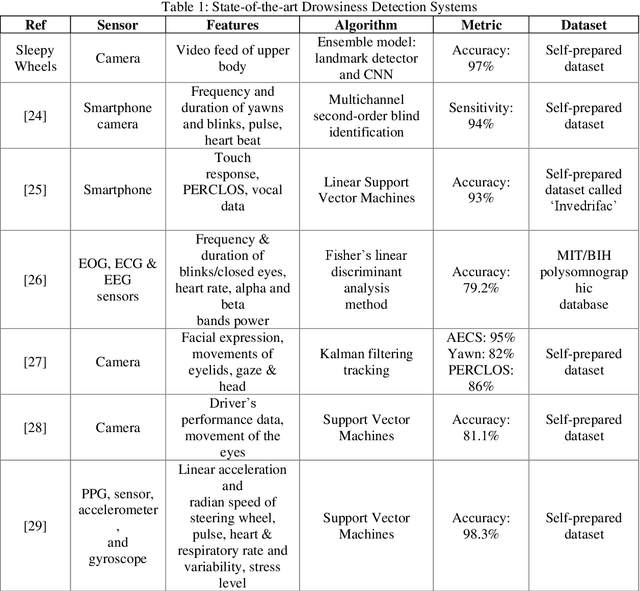

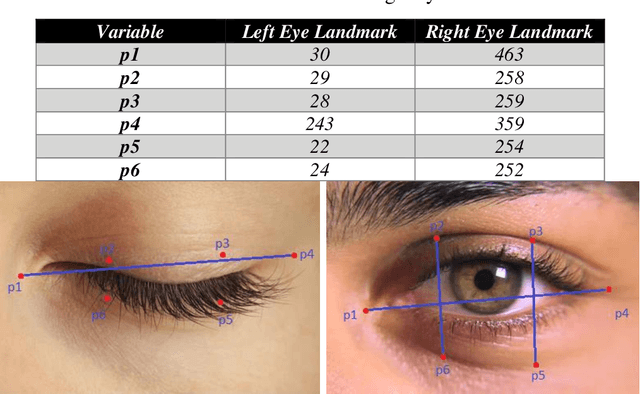
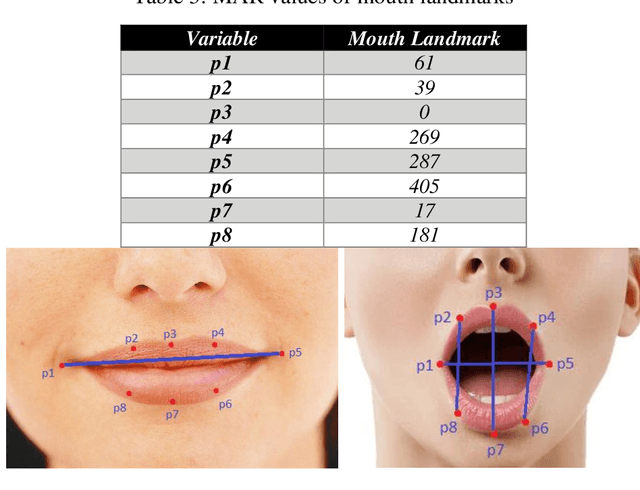
Around 40 percent of accidents related to driving on highways in India occur due to the driver falling asleep behind the steering wheel. Several types of research are ongoing to detect driver drowsiness but they suffer from the complexity and cost of the models. In this paper, SleepyWheels a revolutionary method that uses a lightweight neural network in conjunction with facial landmark identification is proposed to identify driver fatigue in real time. SleepyWheels is successful in a wide range of test scenarios, including the lack of facial characteristics while covering the eye or mouth, the drivers varying skin tones, camera placements, and observational angles. It can work well when emulated to real time systems. SleepyWheels utilized EfficientNetV2 and a facial landmark detector for identifying drowsiness detection. The model is trained on a specially created dataset on driver sleepiness and it achieves an accuracy of 97 percent. The model is lightweight hence it can be further deployed as a mobile application for various platforms.
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Dec 24, 2021


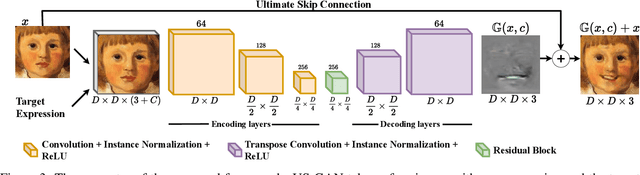
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023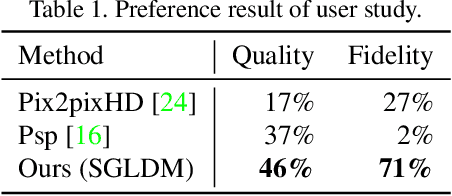

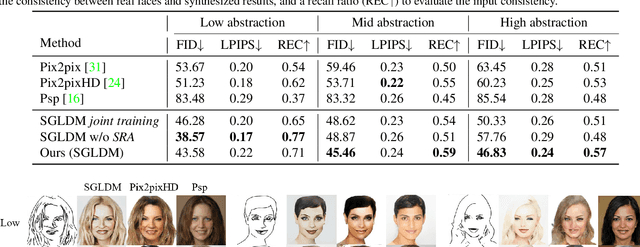
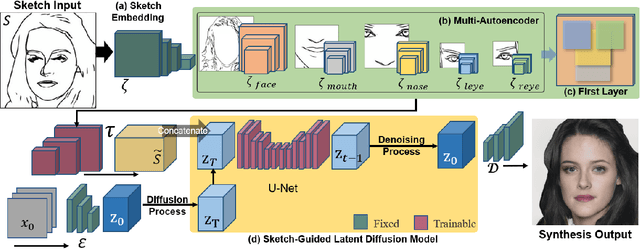
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Facial Thermal and Blood Perfusion Patterns of Human Emotions: Proof-of-Concept
Jan 23, 2023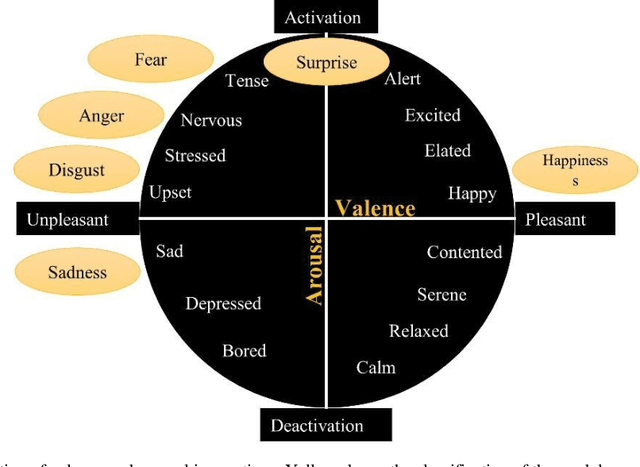
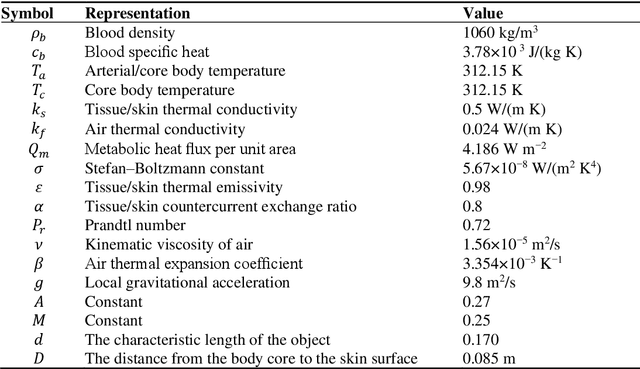
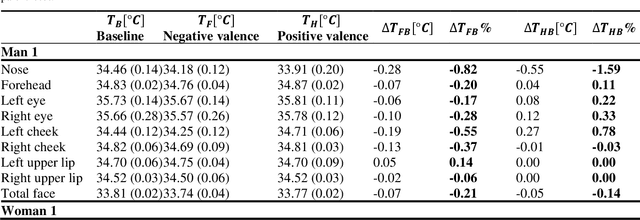
In this work, a preliminary study of proof-of-concept was conducted to evaluate the performance of the thermographic and blood perfusion data when emotions of positive and negative valence are applied, where the blood perfusion data are obtained from the thermographic data. The images were obtained for baseline, positive, and negative valence according to the protocol of the Geneva Affective Picture Database. Absolute and percentage differences of average values of the data between the valences and the baseline were calculated for different regions of interest (forehead, periorbital eyes, cheeks, nose and upper lips). For negative valence, a decrease in temperature and blood perfusion was observed in the regions of interest, and the effect was greater on the left side than on the right side. In positive valence, the temperature and blood perfusion increased in some cases, showing a complex pattern. The temperature and perfusion of the nose was reduced for both valences, which is indicative of the arousal dimension. The blood perfusion images were found to be greater contrast; the percentage differences in the blood perfusion images are greater than those obtained in thermographic images. Moreover, the blood perfusion images, and vasomotor answer are consistent, therefore, they can be a better biomarker than thermographic analysis in identifying emotions.
* 22 pages, 9 figures
Learning Neural Parametric Head Models
Dec 06, 2022


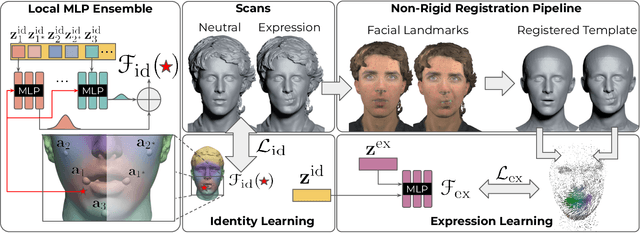
We propose a novel 3D morphable model for complete human heads based on hybrid neural fields. At the core of our model lies a neural parametric representation which disentangles identity and expressions in disjoint latent spaces. To this end, we capture a person's identity in a canonical space as a signed distance field (SDF), and model facial expressions with a neural deformation field. In addition, our representation achieves high-fidelity local detail by introducing an ensemble of local fields centered around facial anchor points. To facilitate generalization, we train our model on a newly-captured dataset of over 2200 head scans from 124 different identities using a custom high-end 3D scanning setup. Our dataset significantly exceeds comparable existing datasets, both with respect to quality and completeness of geometry, averaging around 3.5M mesh faces per scan. Finally, we demonstrate that our approach outperforms state-of-the-art methods by a significant margin in terms of fitting error and reconstruction quality.
Fine-tuning of sign language recognition models: a technical report
Feb 16, 2023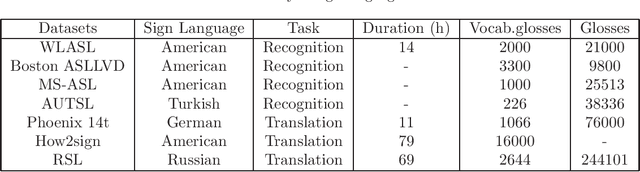
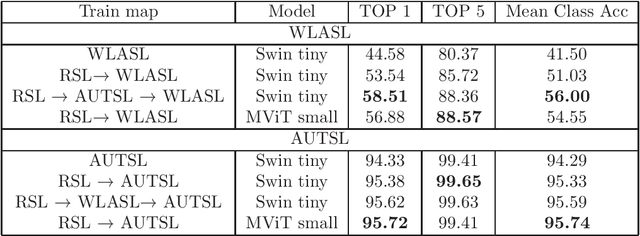
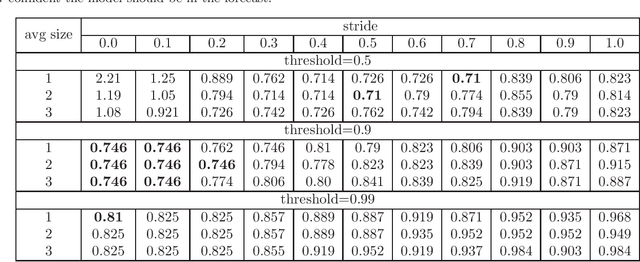
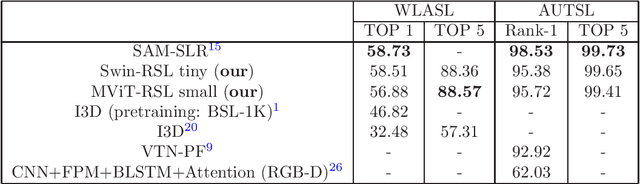
Sign Language Recognition (SLR) is an essential yet challenging task since sign language is performed with the fast and complex movement of hand gestures, body posture, and even facial expressions. %Skeleton Aware Multi-modal Sign Language Recognition In this work, we focused on investigating two questions: how fine-tuning on datasets from other sign languages helps improve sign recognition quality, and whether sign recognition is possible in real-time without using GPU. Three different languages datasets (American sign language WLASL, Turkish - AUTSL, Russian - RSL) have been used to validate the models. The average speed of this system has reached 3 predictions per second, which meets the requirements for the real-time scenario. This model (prototype) will benefit speech or hearing impaired people talk with other trough internet. We also investigated how the additional training of the model in another sign language affects the quality of recognition. The results show that further training of the model on the data of another sign language almost always leads to an improvement in the quality of gesture recognition. We also provide code for reproducing model training experiments, converting models to ONNX format, and inference for real-time gesture recognition.
OPT: One-shot Pose-Controllable Talking Head Generation
Feb 16, 2023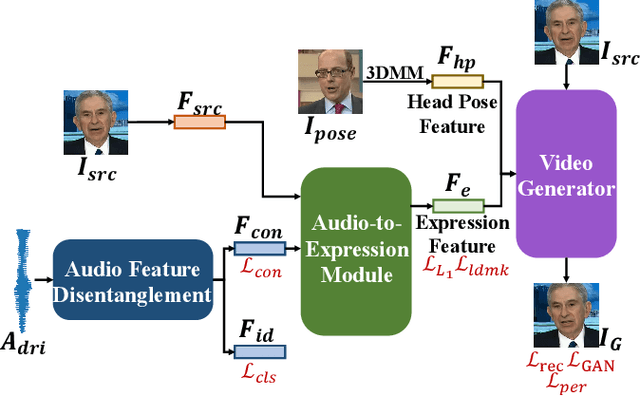
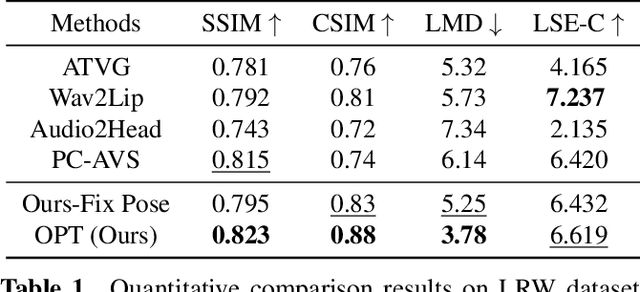

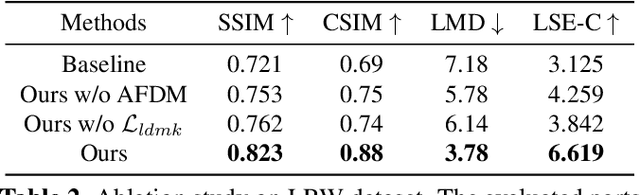
One-shot talking head generation produces lip-sync talking heads based on arbitrary audio and one source face. To guarantee the naturalness and realness, recent methods propose to achieve free pose control instead of simply editing mouth areas. However, existing methods do not preserve accurate identity of source face when generating head motions. To solve the identity mismatch problem and achieve high-quality free pose control, we present One-shot Pose-controllable Talking head generation network (OPT). Specifically, the Audio Feature Disentanglement Module separates content features from audios, eliminating the influence of speaker-specific information contained in arbitrary driving audios. Later, the mouth expression feature is extracted from the content feature and source face, during which the landmark loss is designed to enhance the accuracy of facial structure and identity preserving quality. Finally, to achieve free pose control, controllable head pose features from reference videos are fed into the Video Generator along with the expression feature and source face to generate new talking heads. Extensive quantitative and qualitative experimental results verify that OPT generates high-quality pose-controllable talking heads with no identity mismatch problem, outperforming previous SOTA methods.
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022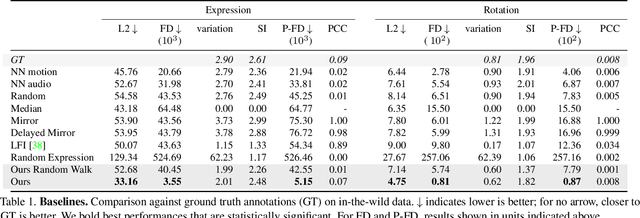
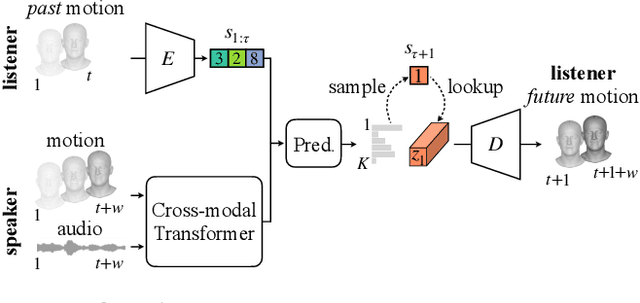
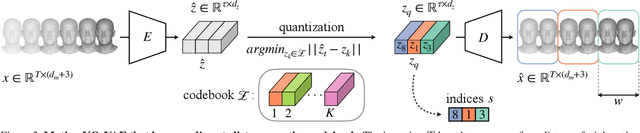
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
Kernel function impact on convolutional neural networks
Feb 20, 2023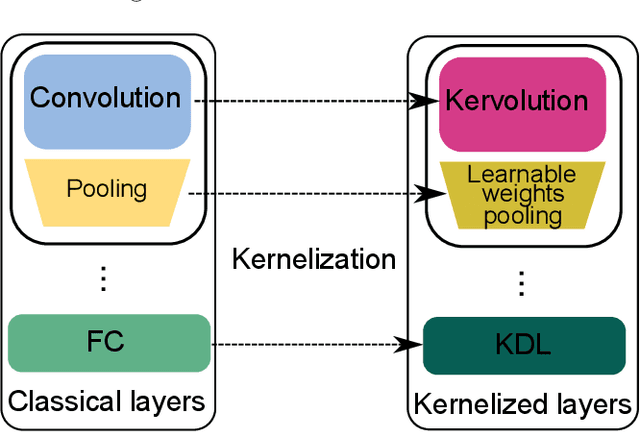
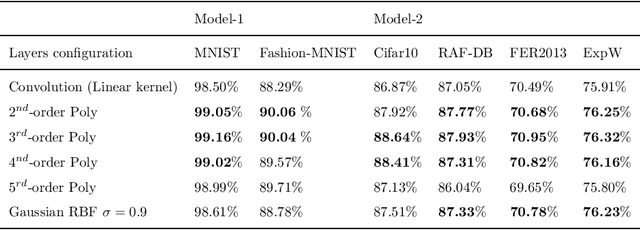
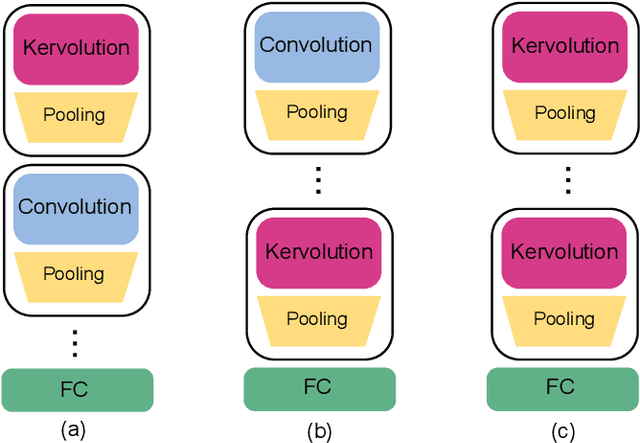
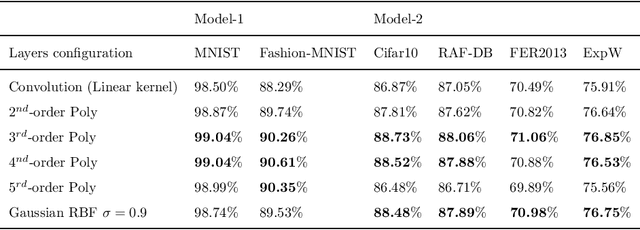
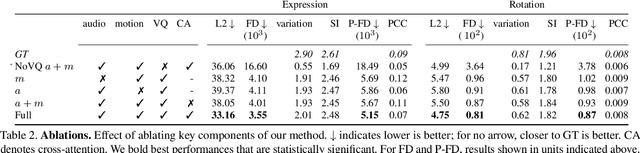
This paper investigates the usage of kernel functions at the different layers in a convolutional neural network. We carry out extensive studies of their impact on convolutional, pooling and fully-connected layers. We notice that the linear kernel may not be sufficiently effective to fit the input data distributions, whereas high order kernels prone to over-fitting. This leads to conclude that a trade-off between complexity and performance should be reached. We show how one can effectively leverage kernel functions, by introducing a more distortion aware pooling layers which reduces over-fitting while keeping track of the majority of the information fed into subsequent layers. We further propose Kernelized Dense Layers (KDL), which replace fully-connected layers, and capture higher order feature interactions. The experiments on conventional classification datasets i.e. MNIST, FASHION-MNIST and CIFAR-10, show that the proposed techniques improve the performance of the network compared to classical convolution, pooling and fully connected layers. Moreover, experiments on fine-grained classification i.e. facial expression databases, namely RAF-DB, FER2013 and ExpW demonstrate that the discriminative power of the network is boosted, since the proposed techniques improve the awareness to slight visual details and allows the network reaching state-of-the-art results.
Medical Face Masks and Emotion Recognition from the Body: Insights from a Deep Learning Perspective
Feb 20, 2023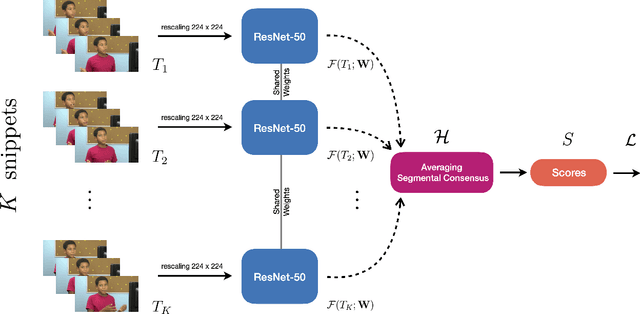
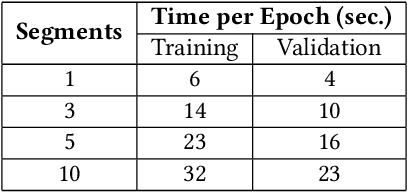
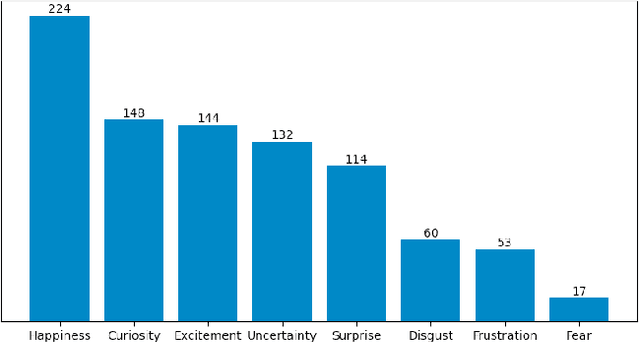

The COVID-19 pandemic has undoubtedly changed the standards and affected all aspects of our lives, especially social life. It has forced people to extensively wear medical face masks, in order to prevent transmission. This face occlusion can strongly irritate emotional reading from the face and urges us to incorporate the whole body for emotion recognition, as it needs to play a more major role, despite its complementary nature. In this paper, we want to conduct insightful studies about the effect of face occlusion on emotion recognition performance, and showcase the superiority of full body input over plain masked face. We utilize a deep learning model based on the Temporal Segment Network framework and aspire to fully overcome the consequences of the face mask. Although single RGB stream models can adapt and learn both facial and bodily features, this may lead to irrelevant information confusion. By processing those features separately and fusing their preliminary prediction scores with a late fusion scheme, we are more effectively taking advantage of both modalities. This architecture can also naturally support temporal modeling, by mingling information among neighboring segment frames. Experimental results suggest that spatial structure plays a more important role for an emotional expression, while temporal structure is complementary.