 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDIF: Formula-Driven supervised Learning with Implicit Functions for 3D Medical Image Segmentation
Mar 24, 2026Deep learning-based 3D medical image segmentation methods relies on large-scale labeled datasets, yet acquiring such data is difficult due to privacy constraints and the high cost of expert annotation. Formula-Driven Supervised Learning (FDSL) offers an appealing alternative by generating training data and labels directly from mathematical formulas. However, existing voxel-based approaches are limited in geometric expressiveness and cannot synthesize realistic textures. We introduce Formula-Driven supervised learning with Implicit Functions (FDIF), a framework that enables scalable pre-training without using any real data and medical expert annotations. FDIF introduces an implicit-function representation based on signed distance functions (SDFs), enabling compact modeling of complex geometries while exploiting the surface representation of SDFs to support controllable synthesis of both geometric and intensity textures. Across three medical image segmentation benchmarks (AMOS, ACDC, and KiTS) and three architectures (SwinUNETR, nnUNet ResEnc-L, and nnUNet Primus-M), FDIF consistently improves over a formula-driven method, and achieves performance comparable to self-supervised approaches pre-trained on large-scale real datasets. We further show that FDIF pre-training also benefits 3D classification tasks, highlighting implicit-function-based formula supervision as a promising paradigm for data-free representation learning. Code is available at https://github.com/yamanoko/FDIF.
Automatic Dance Video Segmentation for Understanding Choreography
May 30, 2024Segmenting dance video into short movements is a popular way to easily understand dance choreography. However, it is currently done manually and requires a significant amount of effort by experts. That is, even if many dance videos are available on social media (e.g., TikTok and YouTube), it remains difficult for people, especially novices, to casually watch short video segments to practice dance choreography. In this paper, we propose a method to automatically segment a dance video into each movement. Given a dance video as input, we first extract visual and audio features: the former is computed from the keypoints of the dancer in the video, and the latter is computed from the Mel spectrogram of the music in the video. Next, these features are passed to a Temporal Convolutional Network (TCN), and segmentation points are estimated by picking peaks of the network output. To build our training dataset, we annotate segmentation points to dance videos in the AIST Dance Video Database, which is a shared database containing original street dance videos with copyright-cleared dance music. The evaluation study shows that the proposed method (i.e., combining the visual and audio features) can estimate segmentation points with high accuracy. In addition, we developed an application to help dancers practice choreography using the proposed method.
AniFaceDrawing: Anime Portrait Exploration during Your Sketching
Jun 13, 2023In this paper, we focus on how artificial intelligence (AI) can be used to assist users in the creation of anime portraits, that is, converting rough sketches into anime portraits during their sketching process. The input is a sequence of incomplete freehand sketches that are gradually refined stroke by stroke, while the output is a sequence of high-quality anime portraits that correspond to the input sketches as guidance. Although recent GANs can generate high quality images, it is a challenging problem to maintain the high quality of generated images from sketches with a low degree of completion due to ill-posed problems in conditional image generation. Even with the latest sketch-to-image (S2I) technology, it is still difficult to create high-quality images from incomplete rough sketches for anime portraits since anime style tend to be more abstract than in realistic style. To address this issue, we adopt a latent space exploration of StyleGAN with a two-stage training strategy. We consider the input strokes of a freehand sketch to correspond to edge information-related attributes in the latent structural code of StyleGAN, and term the matching between strokes and these attributes stroke-level disentanglement. In the first stage, we trained an image encoder with the pre-trained StyleGAN model as a teacher encoder. In the second stage, we simulated the drawing process of the generated images without any additional data (labels) and trained the sketch encoder for incomplete progressive sketches to generate high-quality portrait images with feature alignment to the disentangled representations in the teacher encoder. We verified the proposed progressive S2I system with both qualitative and quantitative evaluations and achieved high-quality anime portraits from incomplete progressive sketches. Our user study proved its effectiveness in art creation assistance for the anime style.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023



Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Interactive 3D Character Modeling from 2D Orthogonal Drawings with Annotations
Jan 27, 2022
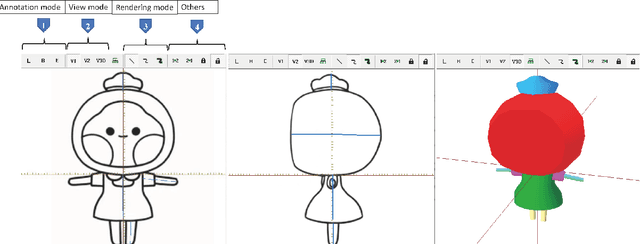
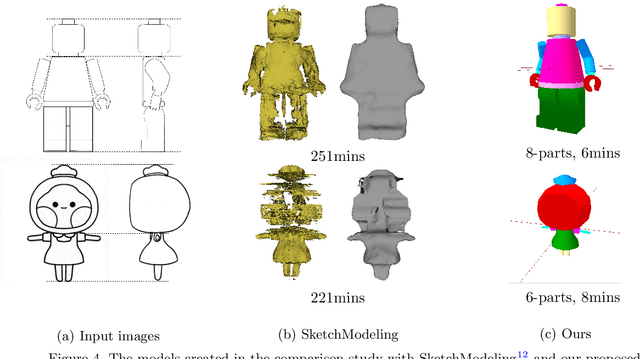
We propose an interactive 3D character modeling approach from orthographic drawings (e.g., front and side views) based on 2D-space annotations. First, the system builds partial correspondences between the input drawings and generates a base mesh with sweeping splines according to edge information in 2D images. Next, users annotates the desired parts on the input drawings (e.g., the eyes and mouth) by using two type of strokes, called addition and erosion, and the system re-optimizes the shape of the base mesh. By repeating the 2D-space operations (i.e., revising and modifying the annotations), users can design a desired character model. To validate the efficiency and quality of our system, we verified the generated results with state-of-the-art methods.
AugLimb: Compact Robotic Limb for Human Augmentation
Sep 01, 2021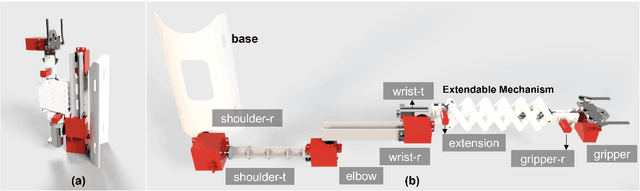

This work proposes a compact robotic limb, AugLimb, that can augment our body functions and support the daily activities. AugLimb adopts the double-layer scissor unit for the extendable mechanism which can achieve 2.5 times longer than the forearm length. The proposed device can be mounted on the user's upper arm, and transform into compact state without obstruction to wearers. The proposed device is lightweight with low burden exerted on the wearer. We developed the prototype of AugLimb to demonstrate the proposed mechanisms. We believe that the design methodology of AugLimb can facilitate human augmentation research for practical use. see http://www.jaist.ac.jp/~xie/auglimb.html
Stroke Correspondence by Labeling Closed Areas
Aug 10, 2021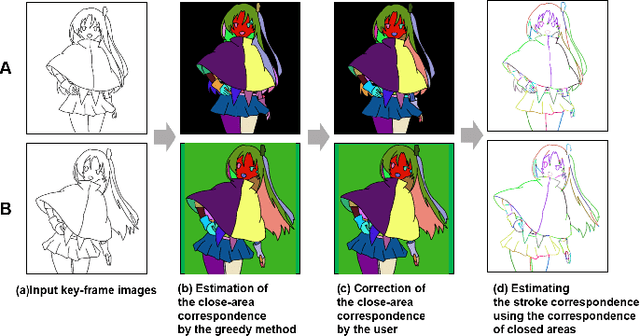

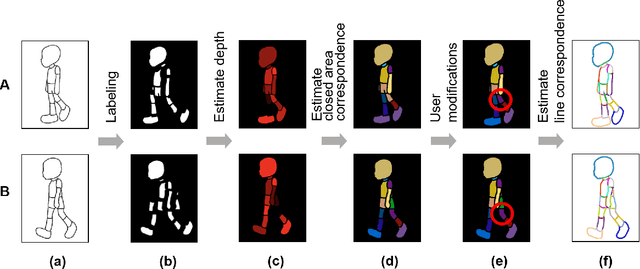
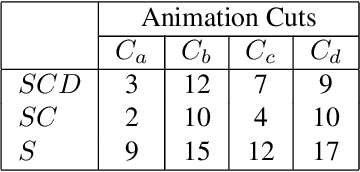
Constructing stroke correspondences between keyframes is one of the most important processes in the production pipeline of hand-drawn inbetweening frames. This process requires time-consuming manual work imposing a tremendous burden on the animators. We propose a method to estimate stroke correspondences between raster character images (keyframes) without vectorization processes. First, the proposed system separates the closed areas in each keyframe and estimates the correspondences between closed areas by using the characteristics of shape, depth, and closed area connection. Second, the proposed system estimates stroke correspondences from the estimated closed area correspondences. We demonstrate the effectiveness of our method by performing a user study and comparing the proposed system with conventional approaches.
dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
Apr 26, 2021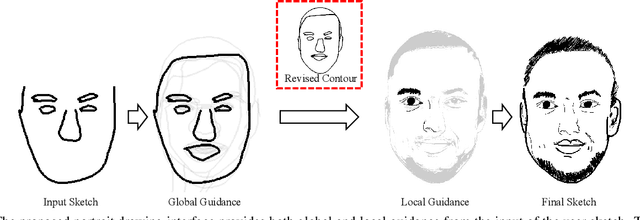
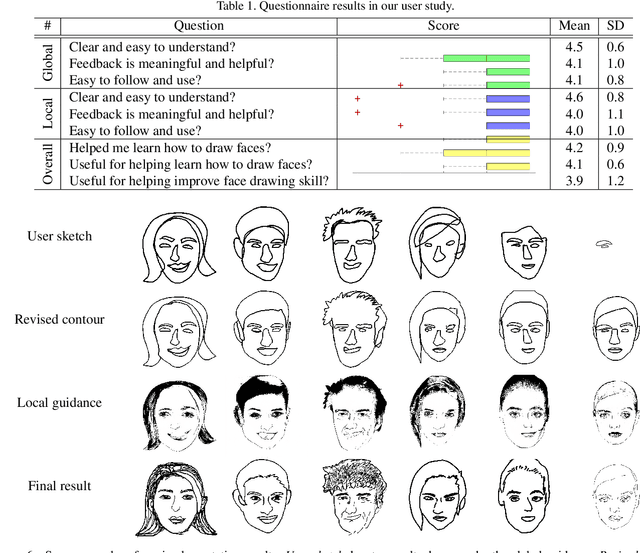
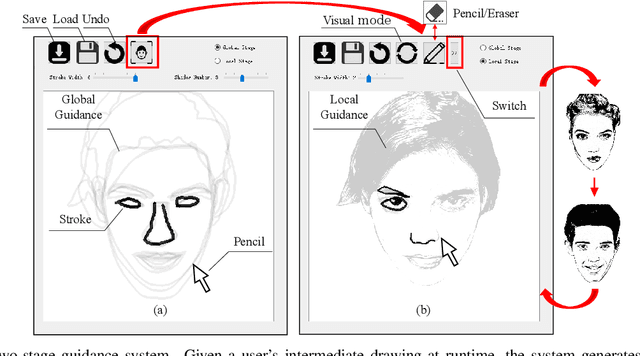
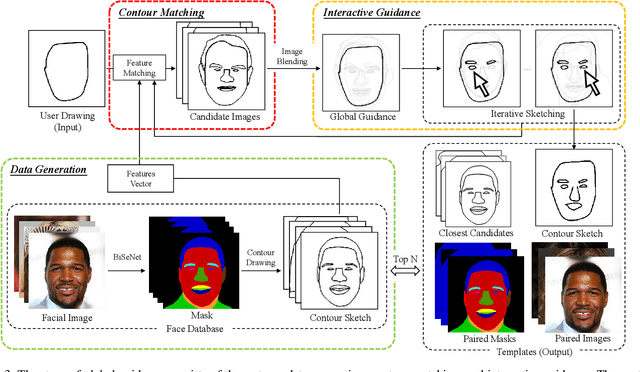
In this paper, we propose dualFace, a portrait drawing interface to assist users with different levels of drawing skills to complete recognizable and authentic face sketches. dualFace consists of two-stage drawing assistance to provide global and local visual guidance: global guidance, which helps users draw contour lines of portraits (i.e., geometric structure), and local guidance, which helps users draws details of facial parts (which conform to user-drawn contour lines), inspired by traditional artist workflows in portrait drawing. In the stage of global guidance, the user draws several contour lines, and dualFace then searches several relevant images from an internal database and displays the suggested face contour lines over the background of the canvas. In the stage of local guidance, we synthesize detailed portrait images with a deep generative model from user-drawn contour lines, but use the synthesized results as detailed drawing guidance. We conducted a user study to verify the effectiveness of dualFace, and we confirmed that dualFace significantly helps achieve a detailed portrait sketch. see http://www.jaist.ac.jp/~xie/dualface.html