 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
Feb 26, 2026Generating realistic conversational gestures are essential for achieving natural, socially engaging interactions with digital humans. However, existing methods typically map a single audio stream to a single speaker's motion, without considering social context or modeling the mutual dynamics between two people engaging in conversation. We present DyaDiT, a multi-modal diffusion transformer that generates contextually appropriate human motion from dyadic audio signals. Trained on Seamless Interaction Dataset, DyaDiT takes dyadic audio with optional social-context tokens to produce context-appropriate motion. It fuses information from both speakers to capture interaction dynamics, uses a motion dictionary to encode motion priors, and can optionally utilize the conversational partner's gestures to produce more responsive motion. We evaluate DyaDiT on standard motion generation metrics and conduct quantitative user studies, demonstrating that it not only surpasses existing methods on objective metrics but is also strongly preferred by users, highlighting its robustness and socially favorable motion generation. Code and models will be released upon acceptance.
UniLS: End-to-End Audio-Driven Avatars for Unified Listening and Speaking
Dec 10, 2025Generating lifelike conversational avatars requires modeling not just isolated speakers, but the dynamic, reciprocal interaction of speaking and listening. However, modeling the listener is exceptionally challenging: direct audio-driven training fails, producing stiff, static listening motions. This failure stems from a fundamental imbalance: the speaker's motion is strongly driven by speech audio, while the listener's motion primarily follows an internal motion prior and is only loosely guided by external speech. This challenge has led most methods to focus on speak-only generation. The only prior attempt at joint generation relies on extra speaker's motion to produce the listener. This design is not end-to-end, thereby hindering the real-time applicability. To address this limitation, we present UniLS, the first end-to-end framework for generating unified speak-listen expressions, driven by only dual-track audio. Our method introduces a novel two-stage training paradigm. Stage 1 first learns the internal motion prior by training an audio-free autoregressive generator, capturing the spontaneous dynamics of natural facial motion. Stage 2 then introduces the dual-track audio, fine-tuning the generator to modulate the learned motion prior based on external speech cues. Extensive evaluations show UniLS achieves state-of-the-art speaking accuracy. More importantly, it delivers up to 44.1\% improvement in listening metrics, generating significantly more diverse and natural listening expressions. This effectively mitigates the stiffness problem and provides a practical, high-fidelity audio-driven solution for interactive digital humans.
LineArt: A Knowledge-guided Training-free High-quality Appearance Transfer for Design Drawing with Diffusion Model
Dec 16, 2024



Image rendering from line drawings is vital in design and image generation technologies reduce costs, yet professional line drawings demand preserving complex details. Text prompts struggle with accuracy, and image translation struggles with consistency and fine-grained control. We present LineArt, a framework that transfers complex appearance onto detailed design drawings, facilitating design and artistic creation. It generates high-fidelity appearance while preserving structural accuracy by simulating hierarchical visual cognition and integrating human artistic experience to guide the diffusion process. LineArt overcomes the limitations of current methods in terms of difficulty in fine-grained control and style degradation in design drawings. It requires no precise 3D modeling, physical property specs, or network training, making it more convenient for design tasks. LineArt consists of two stages: a multi-frequency lines fusion module to supplement the input design drawing with detailed structural information and a two-part painting process for Base Layer Shaping and Surface Layer Coloring. We also present a new design drawing dataset ProLines for evaluation. The experiments show that LineArt performs better in accuracy, realism, and material precision compared to SOTAs.
FilterPrompt: Guiding Image Transfer in Diffusion Models
Apr 20, 2024In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Masked Audio Gesture Modeling
Jan 02, 2024



We propose EMAGE, a framework to generate full-body human gestures from audio and masked gestures, encompassing facial, local body, hands, and global movements. To achieve this, we first introduce BEATX (BEAT-SMPLX-FLAME), a new mesh-level holistic co-speech dataset. BEATX combines MoShed SMPLX body with FLAME head parameters and further refines the modeling of head, neck, and finger movements, offering a community-standardized, high-quality 3D motion captured dataset. EMAGE leverages masked body gesture priors during training to boost inference performance. It involves a Masked Audio Gesture Transformer, facilitating joint training on audio-to-gesture generation and masked gesture reconstruction to effectively encode audio and body gesture hints. Encoded body hints from masked gestures are then separately employed to generate facial and body movements. Moreover, EMAGE adaptively merges speech features from the audio's rhythm and content and utilizes four compositional VQ-VAEs to enhance the results' fidelity and diversity. Experiments demonstrate that EMAGE generates holistic gestures with state-of-the-art performance and is flexible in accepting predefined spatial-temporal gesture inputs, generating complete, audio-synchronized results. Our code and dataset are available at https://pantomatrix.github.io/EMAGE/
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023



Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis
Mar 18, 2022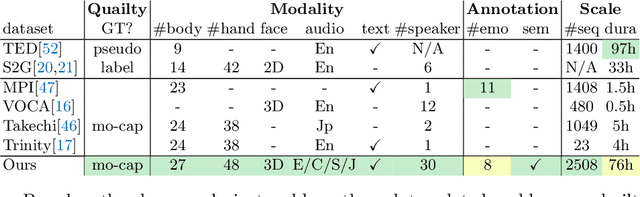
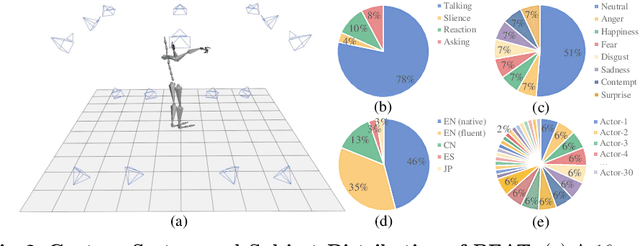

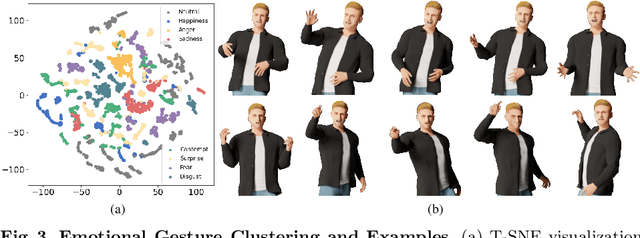
Achieving realistic, vivid, and human-like synthesized conversational gestures conditioned on multi-modal data is still an unsolved problem, due to the lack of available datasets, models and standard evaluation metrics. To address this, we build Body-Expression-Audio-Text dataset, BEAT, which has i) 76 hours, high-quality, multi-modal data captured from 30 speakers talking with eight different emotions and in four different languages, ii) 32 millions frame-level emotion and semantic relevance annotations.Our statistical analysis on BEAT demonstrates the correlation of conversational gestures with facial expressions, emotions, and semantics, in addition to the known correlation with audio, text, and speaker identity. Qualitative and quantitative experiments demonstrate metrics' validness, ground truth data quality, and baseline's state-of-the-art performance. To the best of our knowledge, BEAT is the largest motion capture dataset for investigating the human gestures, which may contribute to a number of different research fields including controllable gesture synthesis, cross-modality analysis, emotional gesture recognition. The data, code and model will be released for research.
dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
Apr 26, 2021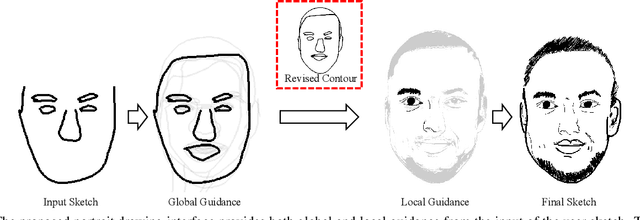
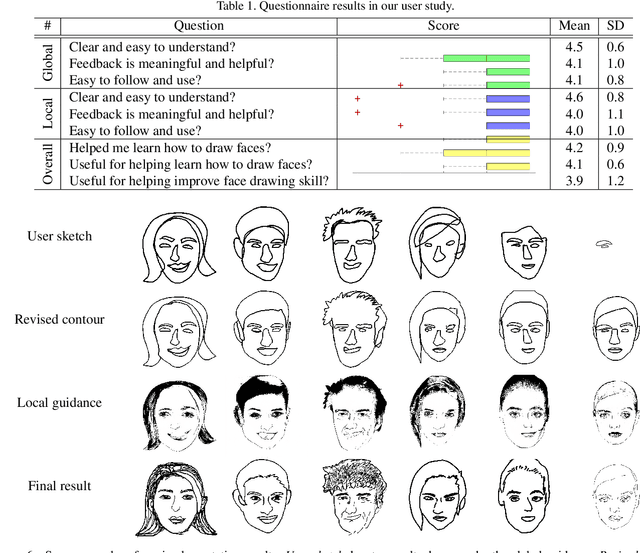
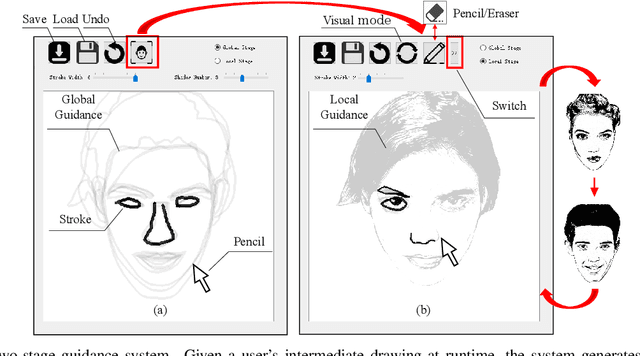
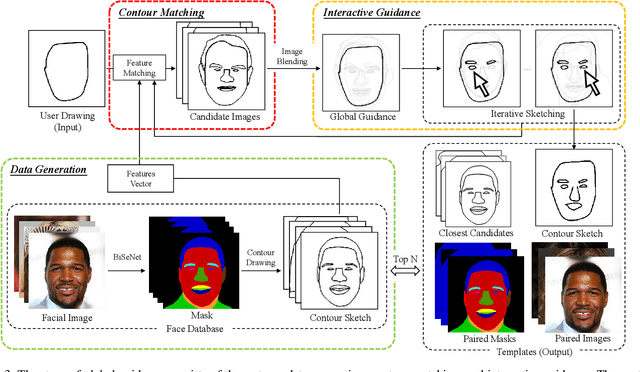
In this paper, we propose dualFace, a portrait drawing interface to assist users with different levels of drawing skills to complete recognizable and authentic face sketches. dualFace consists of two-stage drawing assistance to provide global and local visual guidance: global guidance, which helps users draw contour lines of portraits (i.e., geometric structure), and local guidance, which helps users draws details of facial parts (which conform to user-drawn contour lines), inspired by traditional artist workflows in portrait drawing. In the stage of global guidance, the user draws several contour lines, and dualFace then searches several relevant images from an internal database and displays the suggested face contour lines over the background of the canvas. In the stage of local guidance, we synthesize detailed portrait images with a deep generative model from user-drawn contour lines, but use the synthesized results as detailed drawing guidance. We conducted a user study to verify the effectiveness of dualFace, and we confirmed that dualFace significantly helps achieve a detailed portrait sketch. see http://www.jaist.ac.jp/~xie/dualface.html