 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Feature Representation Learning with Adaptive Displacement Generation and Transformer Fusion for Micro-Expression Recognition
Apr 10, 2023


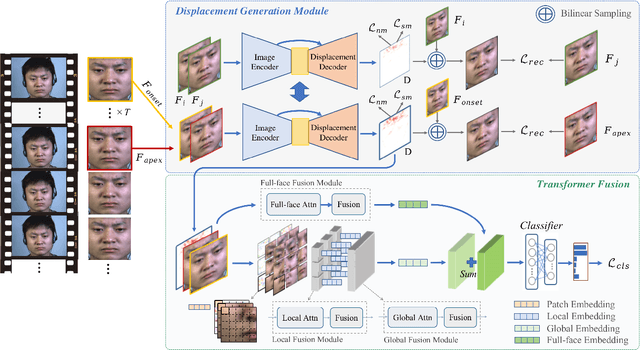
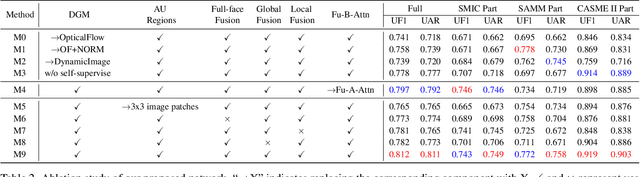
Micro-expressions are spontaneous, rapid and subtle facial movements that can neither be forged nor suppressed. They are very important nonverbal communication clues, but are transient and of low intensity thus difficult to recognize. Recently deep learning based methods have been developed for micro-expression (ME) recognition using feature extraction and fusion techniques, however, targeted feature learning and efficient feature fusion still lack further study according to the ME characteristics. To address these issues, we propose a novel framework Feature Representation Learning with adaptive Displacement Generation and Transformer fusion (FRL-DGT), in which a convolutional Displacement Generation Module (DGM) with self-supervised learning is used to extract dynamic features from onset/apex frames targeted to the subsequent ME recognition task, and a well-designed Transformer Fusion mechanism composed of three Transformer-based fusion modules (local, global fusions based on AU regions and full-face fusion) is applied to extract the multi-level informative features after DGM for the final ME prediction. The extensive experiments with solid leave-one-subject-out (LOSO) evaluation results have demonstrated the superiority of our proposed FRL-DGT to state-of-the-art methods.
DPE: Disentanglement of Pose and Expression for General Video Portrait Editing
Jan 16, 2023
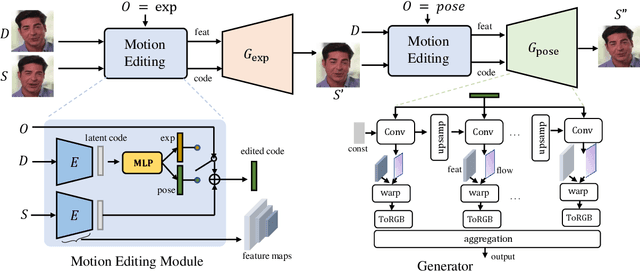
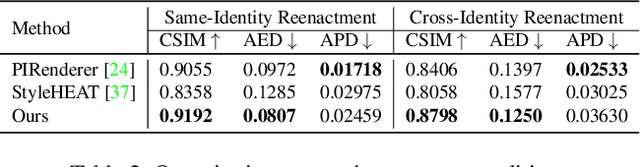
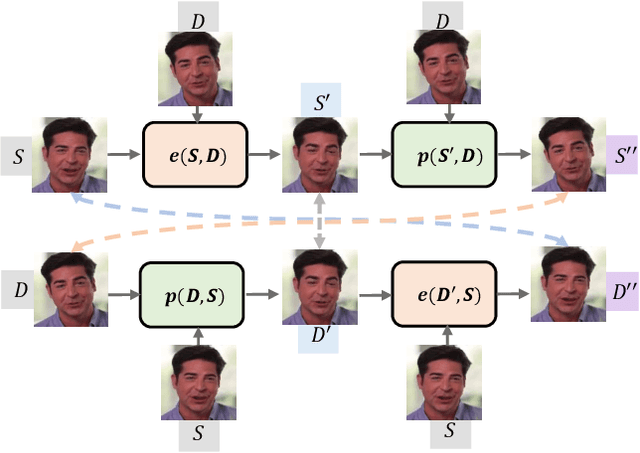
One-shot video-driven talking face generation aims at producing a synthetic talking video by transferring the facial motion from a video to an arbitrary portrait image. Head pose and facial expression are always entangled in facial motion and transferred simultaneously. However, the entanglement sets up a barrier for these methods to be used in video portrait editing directly, where it may require to modify the expression only while maintaining the pose unchanged. One challenge of decoupling pose and expression is the lack of paired data, such as the same pose but different expressions. Only a few methods attempt to tackle this challenge with the feat of 3D Morphable Models (3DMMs) for explicit disentanglement. But 3DMMs are not accurate enough to capture facial details due to the limited number of Blenshapes, which has side effects on motion transfer. In this paper, we introduce a novel self-supervised disentanglement framework to decouple pose and expression without 3DMMs and paired data, which consists of a motion editing module, a pose generator, and an expression generator. The editing module projects faces into a latent space where pose motion and expression motion can be disentangled, and the pose or expression transfer can be performed in the latent space conveniently via addition. The two generators render the modified latent codes to images, respectively. Moreover, to guarantee the disentanglement, we propose a bidirectional cyclic training strategy with well-designed constraints. Evaluations demonstrate our method can control pose or expression independently and be used for general video editing.
AFFDEX 2.0: A Real-Time Facial Expression Analysis Toolkit
Feb 24, 2022

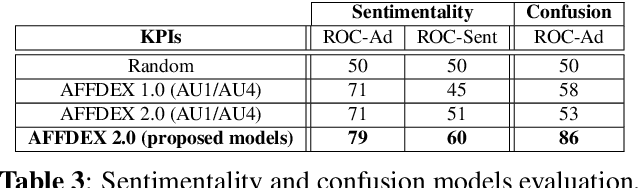

In this paper we introduce AFFDEX 2.0 - a toolkit for analyzing facial expressions in the wild, that is, it is intended for users aiming to; a) estimate the 3D head pose, b) detect facial Action Units (AUs), c) recognize basic emotions and 2 new emotional states (sentimentality and confusion), and d) detect high-level expressive metrics like blink and attention. AFFDEX 2.0 models are mainly based on Deep Learning, and are trained using a large-scale naturalistic dataset consisting of thousands of participants from different demographic groups. AFFDEX 2.0 is an enhanced version of our previous toolkit [1], that is capable of tracking efficiently faces at more challenging conditions, detecting more accurately facial expressions, and recognizing new emotional states (sentimentality and confusion). AFFDEX 2.0 can process multiple faces in real time, and is working across the Windows and Linux platforms.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023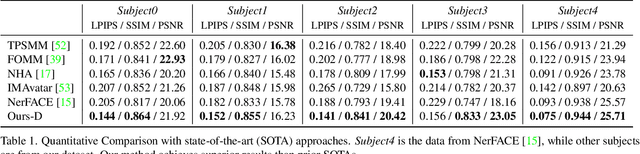
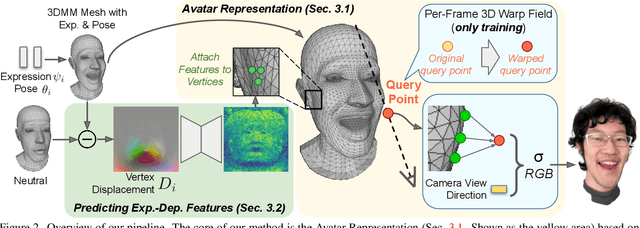
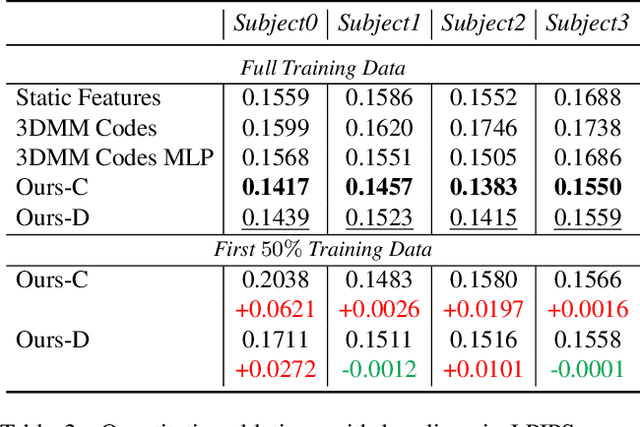
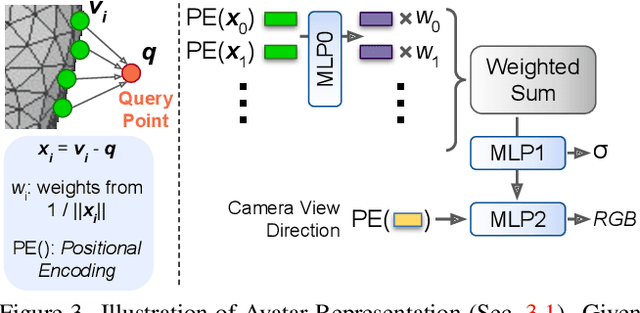
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
Automatic Quantification of Facial Asymmetry using Facial Landmarks
Mar 20, 2021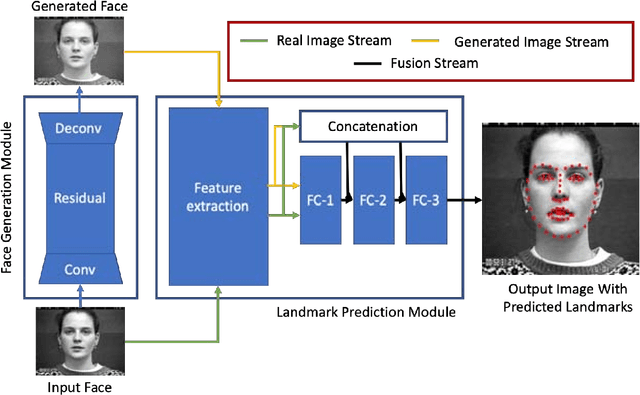
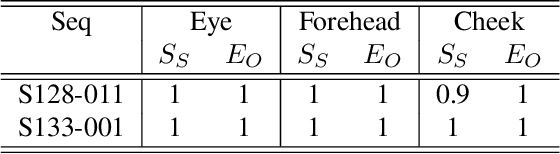

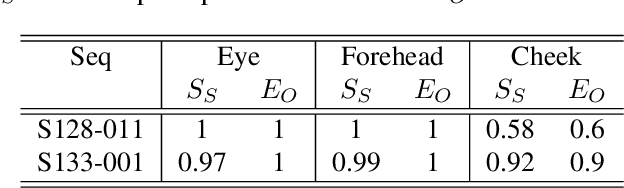
One-sided facial paralysis causes uneven movements of facial muscles on the sides of the face. Physicians currently assess facial asymmetry in a subjective manner based on their clinical experience. This paper proposes a novel method to provide an objective and quantitative asymmetry score for frontal faces. Our metric has the potential to help physicians for diagnosis as well as monitoring the rehabilitation of patients with one-sided facial paralysis. A deep learning based landmark detection technique is used to estimate style invariant facial landmark points and dense optical flow is used to generate motion maps from a short sequence of frames. Six face regions are considered corresponding to the left and right parts of the forehead, eyes, and mouth. Motion is computed and compared between the left and the right parts of each region of interest to estimate the symmetry score. For testing, asymmetric sequences are synthetically generated from a facial expression dataset. A score equation is developed to quantify symmetry in both symmetric and asymmetric face sequences.
* 5 pages, 4 figures
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023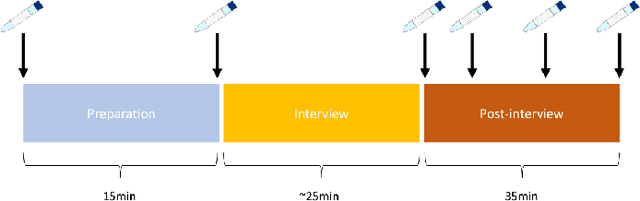
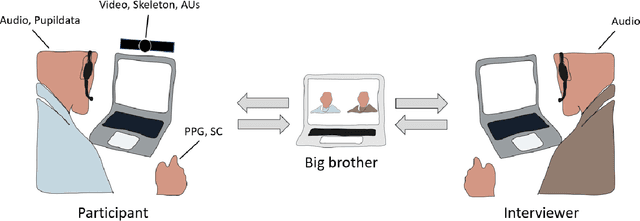
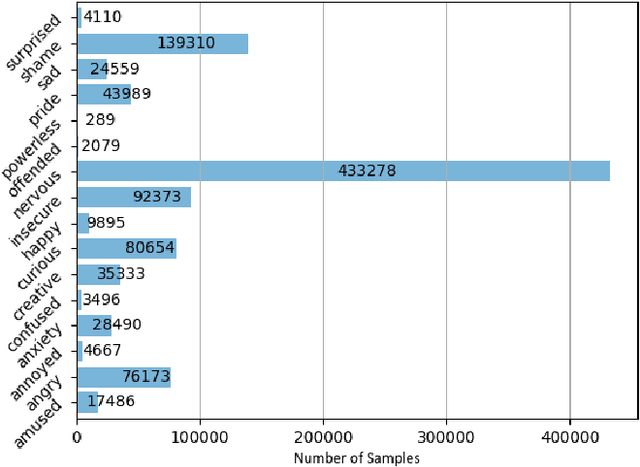
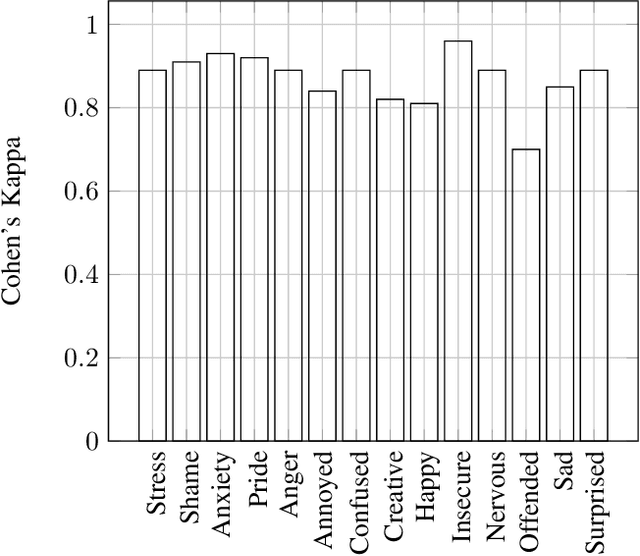
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.
GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models
Apr 19, 2023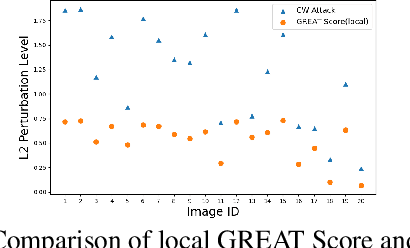
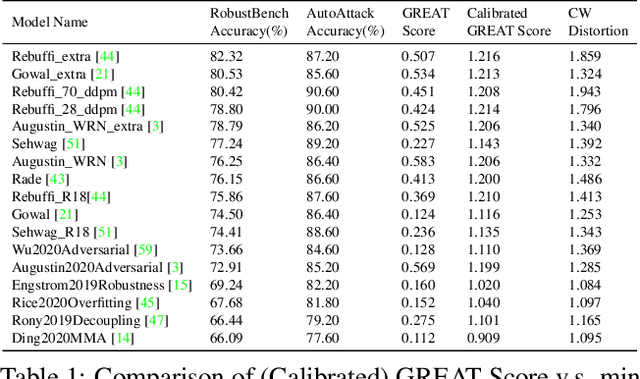
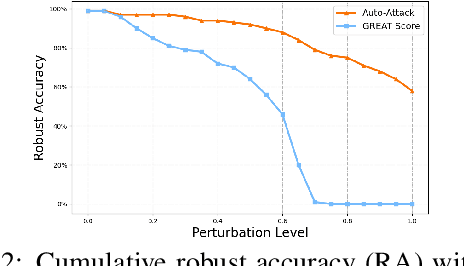
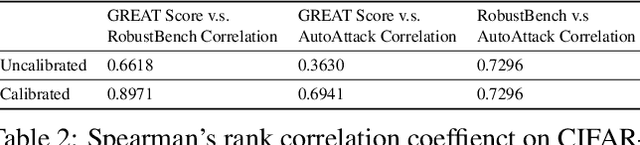
Current studies on adversarial robustness mainly focus on aggregating local robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true global robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called GREAT Score , for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench (Croce,et. al. 2021). (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.
Head3D: Complete 3D Head Generation via Tri-plane Feature Distillation
Mar 28, 2023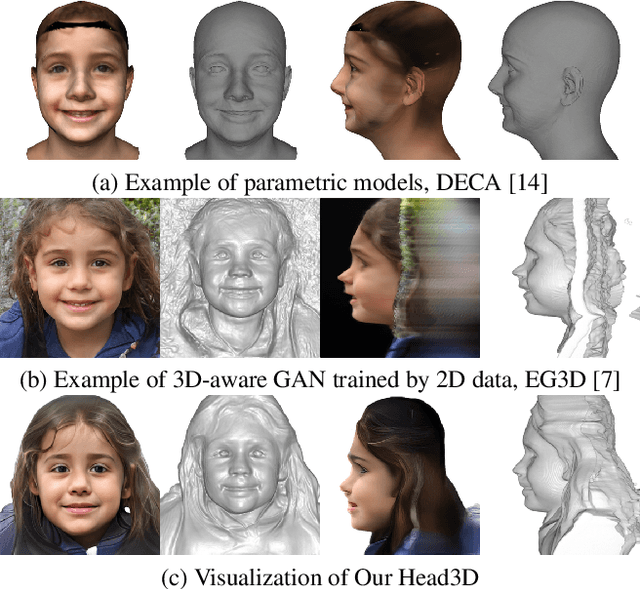

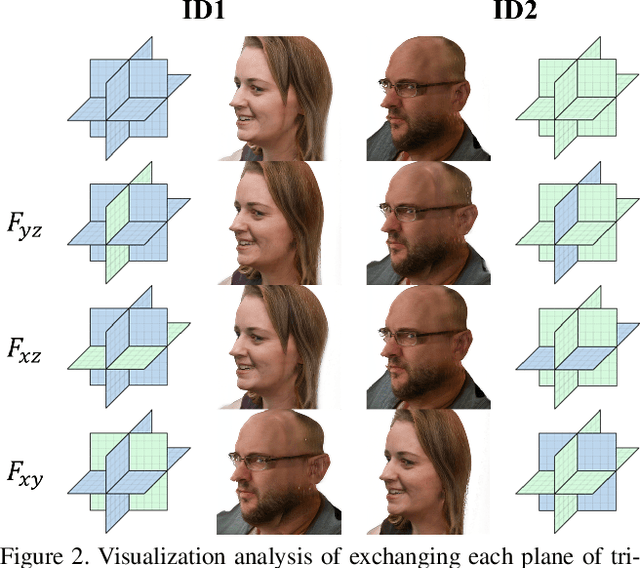

Head generation with diverse identities is an important task in computer vision and computer graphics, widely used in multimedia applications. However, current full head generation methods require a large number of 3D scans or multi-view images to train the model, resulting in expensive data acquisition cost. To address this issue, we propose Head3D, a method to generate full 3D heads with limited multi-view images. Specifically, our approach first extracts facial priors represented by tri-planes learned in EG3D, a 3D-aware generative model, and then proposes feature distillation to deliver the 3D frontal faces into complete heads without compromising head integrity. To mitigate the domain gap between the face and head models, we present dual-discriminators to guide the frontal and back head generation, respectively. Our model achieves cost-efficient and diverse complete head generation with photo-realistic renderings and high-quality geometry representations. Extensive experiments demonstrate the effectiveness of our proposed Head3D, both qualitatively and quantitatively.
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023
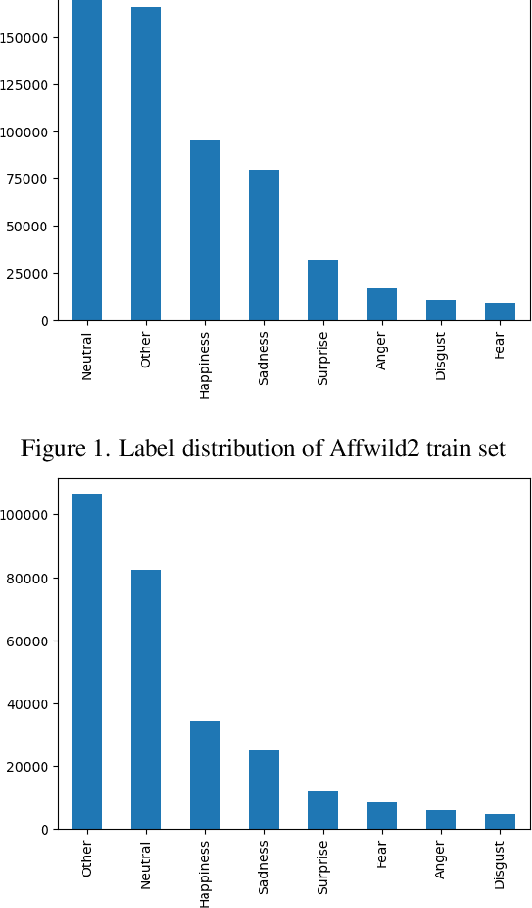

In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
Towards a General Deep Feature Extractor for Facial Expression Recognition
Jan 19, 2022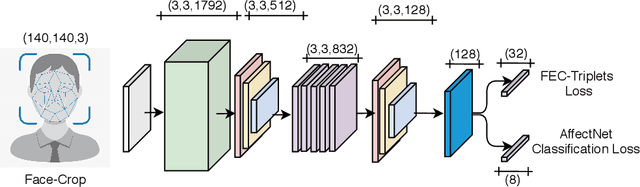



The human face conveys a significant amount of information. Through facial expressions, the face is able to communicate numerous sentiments without the need for verbalisation. Visual emotion recognition has been extensively studied. Recently several end-to-end trained deep neural networks have been proposed for this task. However, such models often lack generalisation ability across datasets. In this paper, we propose the Deep Facial Expression Vector ExtractoR (DeepFEVER), a new deep learning-based approach that learns a visual feature extractor general enough to be applied to any other facial emotion recognition task or dataset. DeepFEVER outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets. DeepFEVER's extracted features also generalise extremely well to other datasets -- even those unseen during training -- namely, the Real-World Affective Faces (RAF) dataset.
* Published in: 2021 IEEE International Conference on Image Processing (ICIP). arXiv admin note: text overlap with arXiv:2103.09154