 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons
Jan 08, 2023
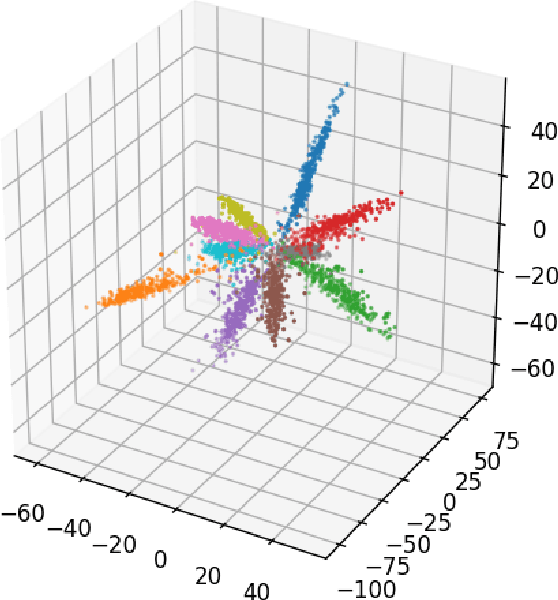
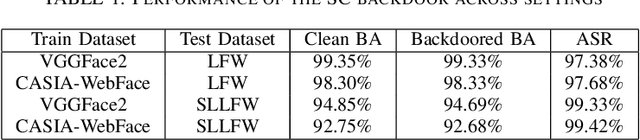
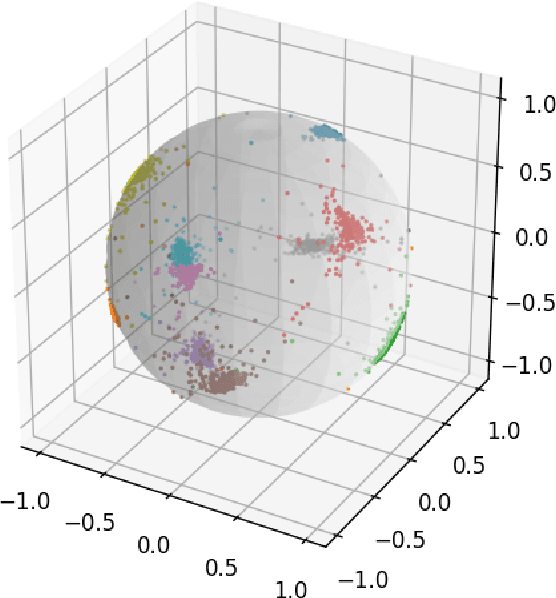
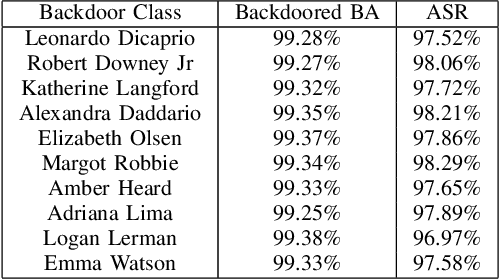
In this paper we describe how to plant novel types of backdoors in any facial recognition model based on the popular architecture of deep Siamese neural networks, by mathematically changing a small fraction of its weights (i.e., without using any additional training or optimization). These backdoors force the system to err only on specific persons which are preselected by the attacker. For example, we show how such a backdoored system can take any two images of a particular person and decide that they represent different persons (an anonymity attack), or take any two images of a particular pair of persons and decide that they represent the same person (a confusion attack), with almost no effect on the correctness of its decisions for other persons. Uniquely, we show that multiple backdoors can be independently installed by multiple attackers who may not be aware of each other's existence with almost no interference. We have experimentally verified the attacks on a FaceNet-based facial recognition system, which achieves SOTA accuracy on the standard LFW dataset of $99.35\%$. When we tried to individually anonymize ten celebrities, the network failed to recognize two of their images as being the same person in $96.97\%$ to $98.29\%$ of the time. When we tried to confuse between the extremely different looking Morgan Freeman and Scarlett Johansson, for example, their images were declared to be the same person in $91.51 \%$ of the time. For each type of backdoor, we sequentially installed multiple backdoors with minimal effect on the performance of each one (for example, anonymizing all ten celebrities on the same model reduced the success rate for each celebrity by no more than $0.91\%$). In all of our experiments, the benign accuracy of the network on other persons was degraded by no more than $0.48\%$ (and in most cases, it remained above $99.30\%$).
MeciFace: Mechanomyography and Inertial Fusion based Glasses for Edge Real-Time Recognition of Facial and Eating Activities
Jun 19, 2023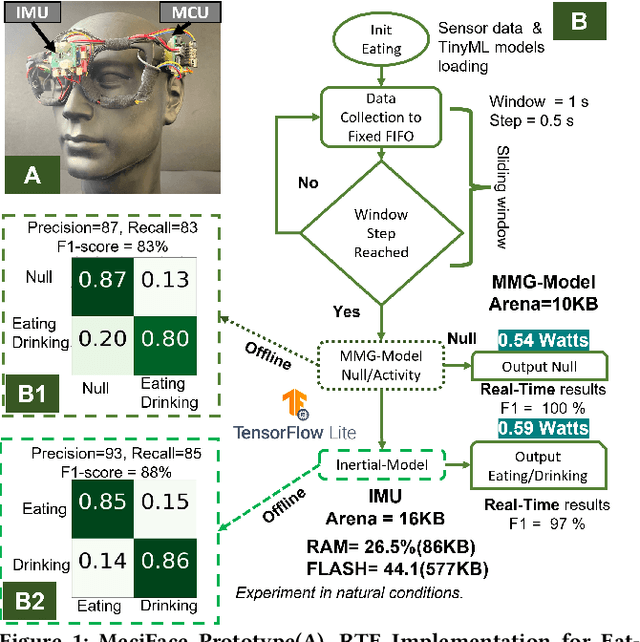

We present MeciFace, a low-power (0.55 Watts), privacy-conscious, real-time on-the-edge (RTE) wearable solution with a tiny memory footprint (11-19 KB), designed to monitor facial expressions and eating activities. We employ lightweight convolutional neural networks as the backbone models for both facial and eating scenarios. The system yielded an F1-score of 86% for the RTE evaluation in the facial expression case. In addition, we obtained an F1-score of 90% for eating/drinking monitoring for the RTE of an unseen user.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023
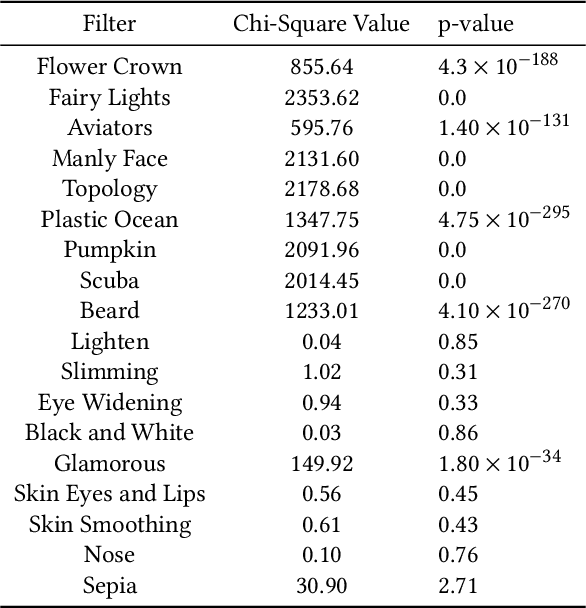

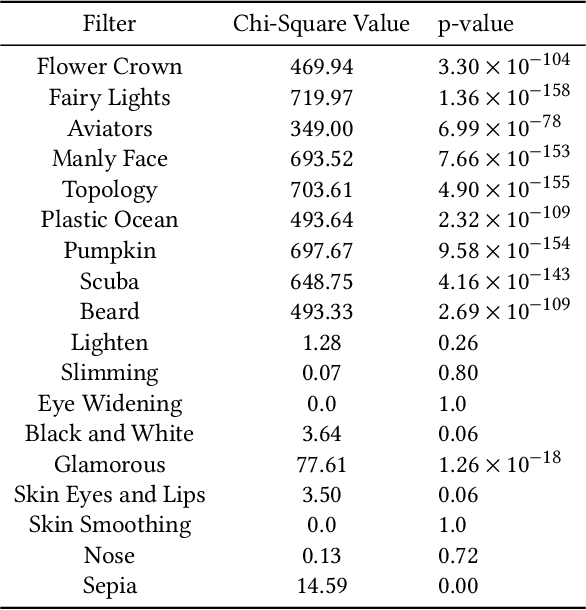
Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022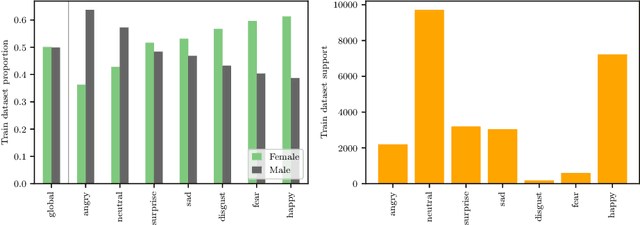
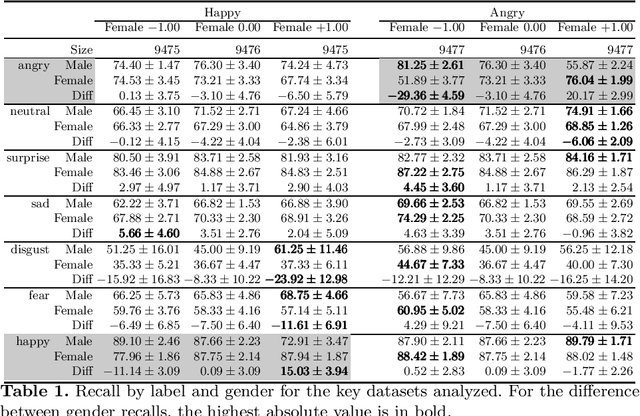
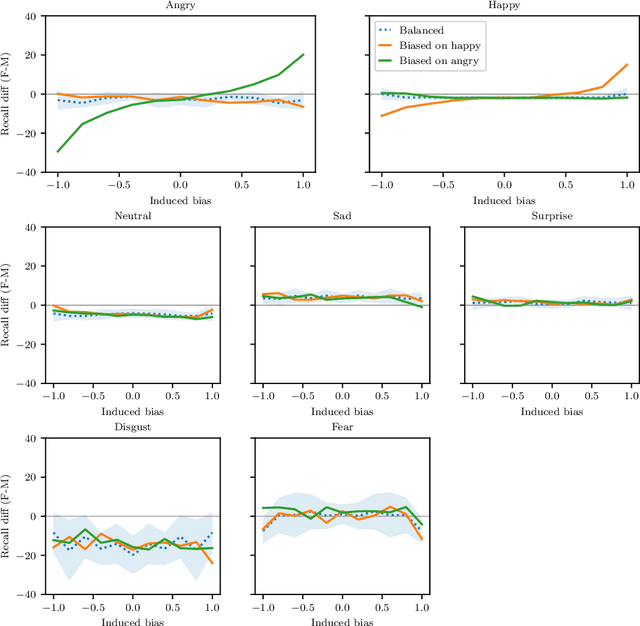
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.
Combating Uncertainty and Class Imbalance in Facial Expression Recognition
Dec 15, 2022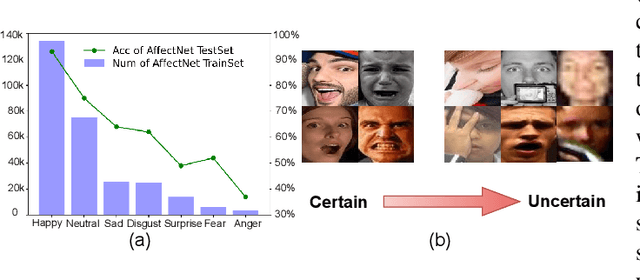
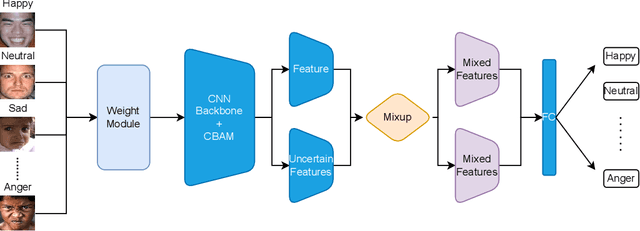
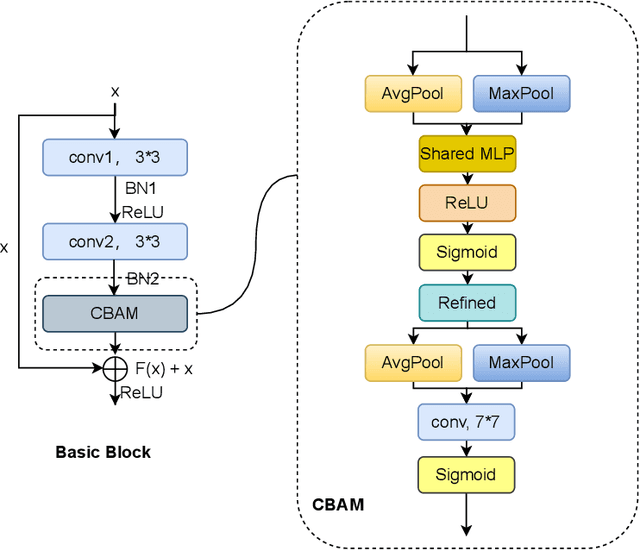
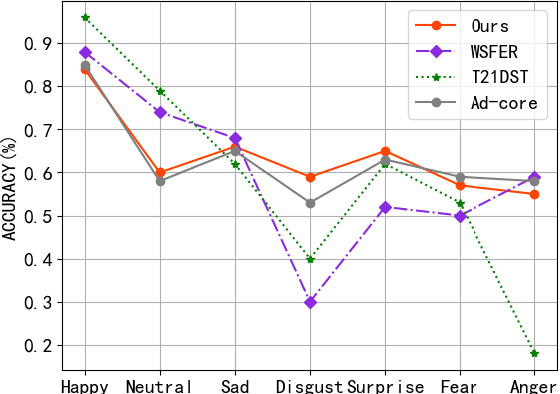
Recognition of facial expression is a challenge when it comes to computer vision. The primary reasons are class imbalance due to data collection and uncertainty due to inherent noise such as fuzzy facial expressions and inconsistent labels. However, current research has focused either on the problem of class imbalance or on the problem of uncertainty, ignoring the intersection of how to address these two problems. Therefore, in this paper, we propose a framework based on Resnet and Attention to solve the above problems. We design weight for each class. Through the penalty mechanism, our model will pay more attention to the learning of small samples during training, and the resulting decrease in model accuracy can be improved by a Convolutional Block Attention Module (CBAM). Meanwhile, our backbone network will also learn an uncertain feature for each sample. By mixing uncertain features between samples, the model can better learn those features that can be used for classification, thus suppressing uncertainty. Experiments show that our method surpasses most basic methods in terms of accuracy on facial expression data sets (e.g., AffectNet, RAF-DB), and it also solves the problem of class imbalance well.
Cluster-level pseudo-labelling for source-free cross-domain facial expression recognition
Oct 11, 2022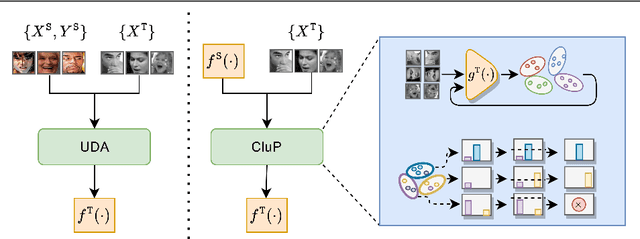
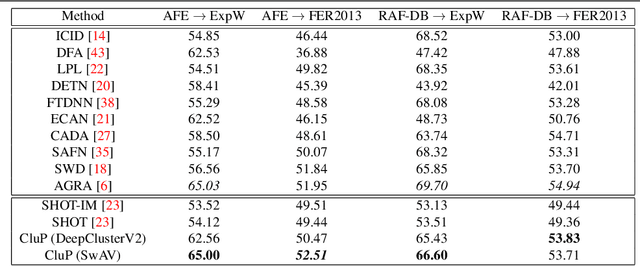
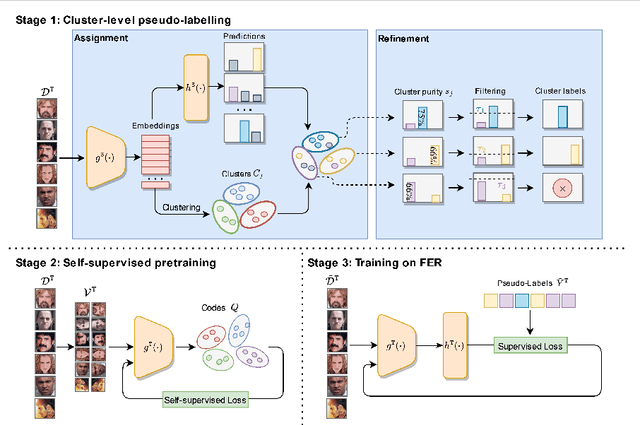

Automatically understanding emotions from visual data is a fundamental task for human behaviour understanding. While models devised for Facial Expression Recognition (FER) have demonstrated excellent performances on many datasets, they often suffer from severe performance degradation when trained and tested on different datasets due to domain shift. In addition, as face images are considered highly sensitive data, the accessibility to large-scale datasets for model training is often denied. In this work, we tackle the above-mentioned problems by proposing the first Source-Free Unsupervised Domain Adaptation (SFUDA) method for FER. Our method exploits self-supervised pretraining to learn good feature representations from the target data and proposes a novel and robust cluster-level pseudo-labelling strategy that accounts for in-cluster statistics. We validate the effectiveness of our method in four adaptation setups, proving that it consistently outperforms existing SFUDA methods when applied to FER, and is on par with methods addressing FER in the UDA setting.
A Robust Framework for Deep Learning Approaches to Facial Emotion Recognition and Evaluation
Jan 30, 2022

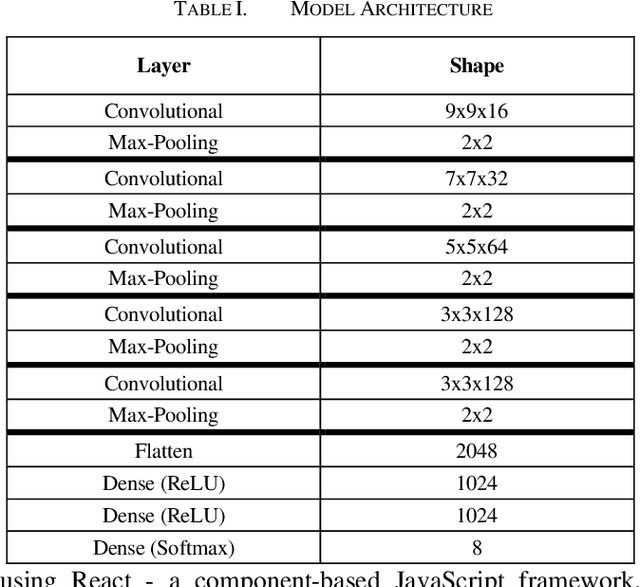
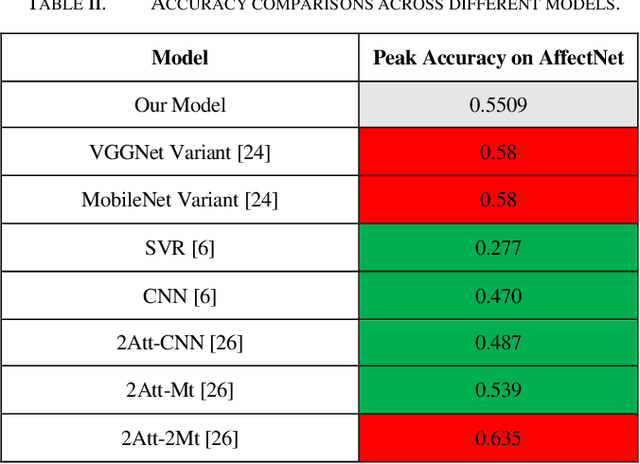
Facial emotion recognition is a vast and complex problem space within the domain of computer vision and thus requires a universally accepted baseline method with which to evaluate proposed models. While test datasets have served this purpose in the academic sphere real world application and testing of such models lacks any real comparison. Therefore we propose a framework in which models developed for FER can be compared and contrasted against one another in a constant standardized fashion. A lightweight convolutional neural network is trained on the AffectNet dataset a large variable dataset for facial emotion recognition and a web application is developed and deployed with our proposed framework as a proof of concept. The CNN is embedded into our application and is capable of instant real time facial emotion recognition. When tested on the AffectNet test set this model achieves high accuracy for emotion classification of eight different emotions. Using our framework the validity of this model and others can be properly tested by evaluating a model efficacy not only based on its accuracy on a sample test dataset, but also on in the wild experiments. Additionally, our application is built with the ability to save and store any image captured or uploaded to it for emotion recognition, allowing for the curation of more quality and diverse facial emotion recognition datasets.
Adaptive Graph-Based Feature Normalization for Facial Expression Recognition
Jul 22, 2022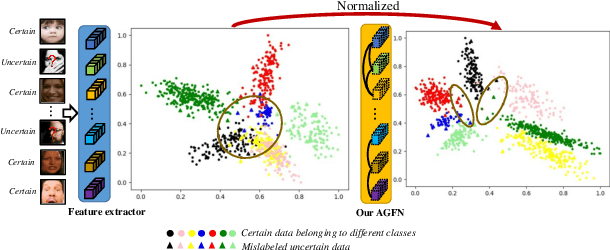
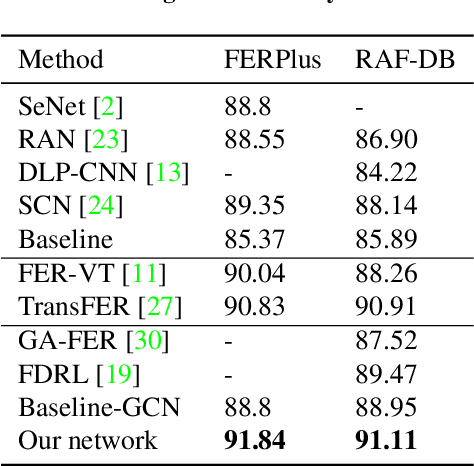
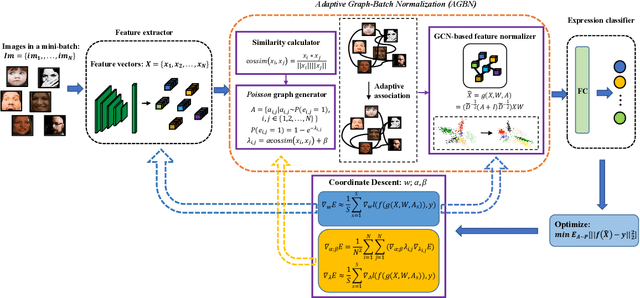
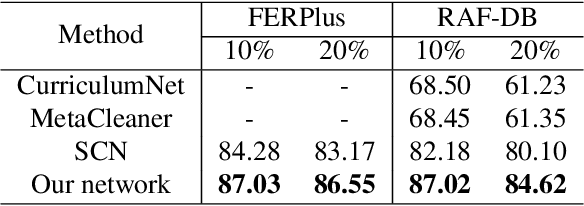
Facial Expression Recognition (FER) suffers from data uncertainties caused by ambiguous facial images and annotators' subjectiveness, resulting in excursive semantic and feature covariate shifting problem. Existing works usually correct mislabeled data by estimating noise distribution, or guide network training with knowledge learned from clean data, neglecting the associative relations of expressions. In this work, we propose an Adaptive Graph-based Feature Normalization (AGFN) method to protect FER models from data uncertainties by normalizing feature distributions with the association of expressions. Specifically, we propose a Poisson graph generator to adaptively construct topological graphs for samples in each mini-batches via a sampling process, and correspondingly design a coordinate descent strategy to optimize proposed network. Our method outperforms state-of-the-art works with accuracies of 91.84% and 91.11% on the benchmark datasets FERPlus and RAF-DB, respectively, and when the percentage of mislabeled data increases (e.g., to 20%), our network surpasses existing works significantly by 3.38% and 4.52%.
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022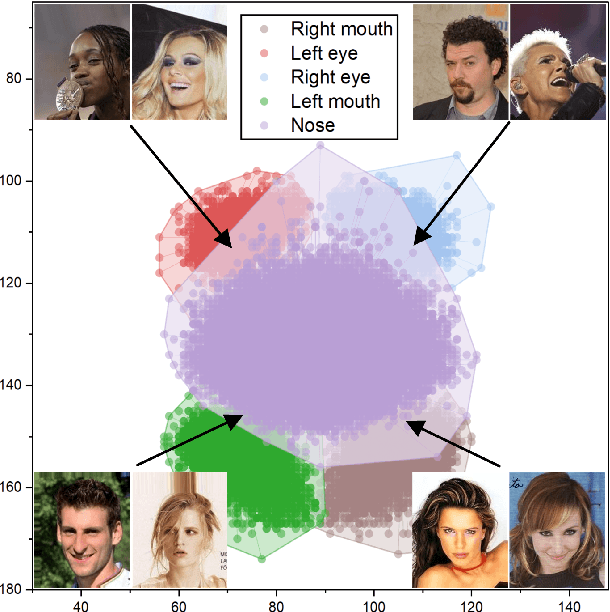
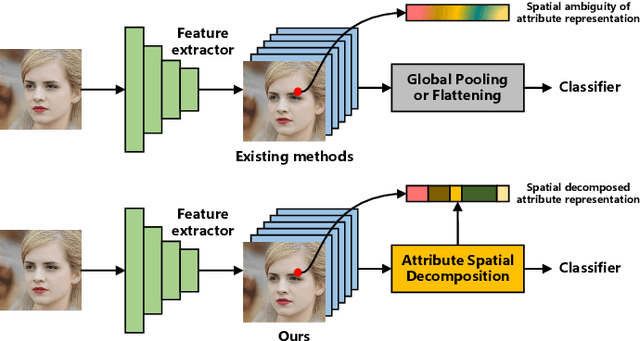
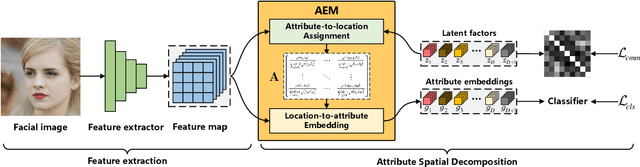
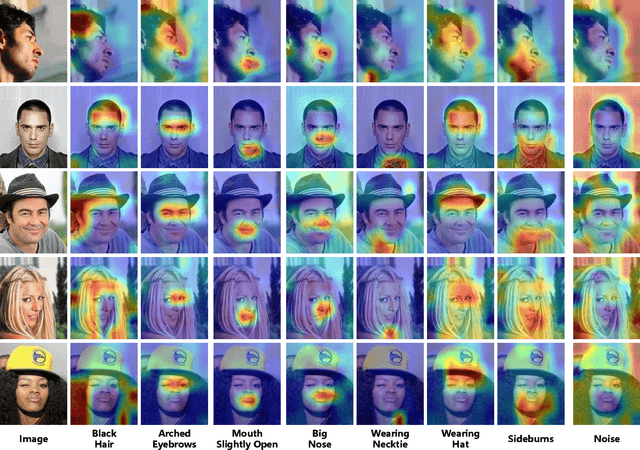
Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
Robustness of Facial Recognition to GAN-based Face-morphing Attacks
Dec 18, 2020
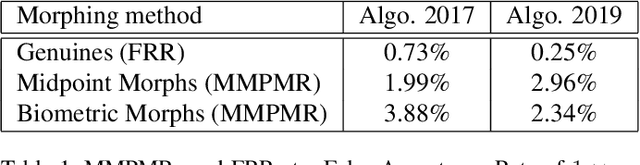

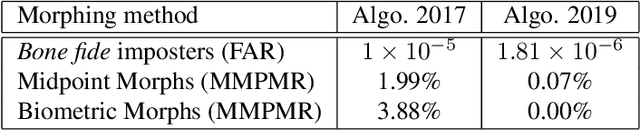
Face-morphing attacks have been a cause for concern for a number of years. Striving to remain one step ahead of attackers, researchers have proposed many methods of both creating and detecting morphed images. These detection methods, however, have generally proven to be inadequate. In this work we identify two new, GAN-based methods that an attacker may already have in his arsenal. Each method is evaluated against state-of-the-art facial recognition (FR) algorithms and we demonstrate that improvements to the fidelity of FR algorithms do lead to a reduction in the success rate of attacks provided morphed images are considered when setting operational acceptance thresholds.