 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revolutionizing Healthcare Image Analysis in Pandemic-Based Fog-Cloud Computing Architectures
Nov 02, 2023
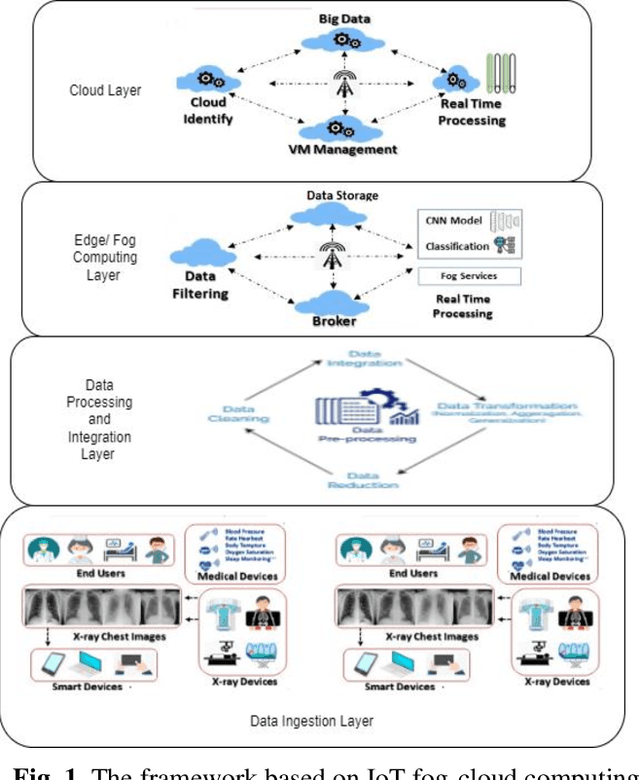

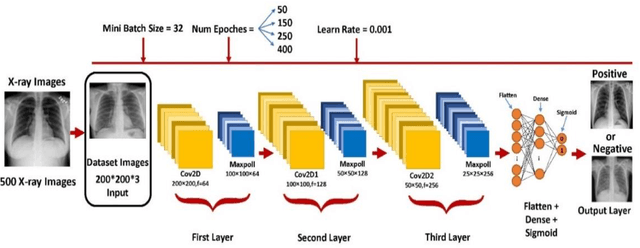
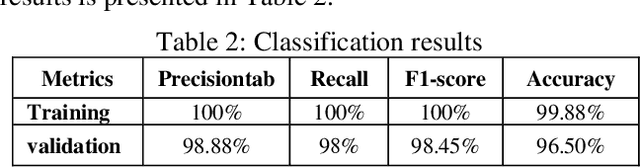
The emergence of pandemics has significantly emphasized the need for effective solutions in healthcare data analysis. One particular challenge in this domain is the manual examination of medical images, such as X-rays and CT scans. This process is time-consuming and involves the logistical complexities of transferring these images to centralized cloud computing servers. Additionally, the speed and accuracy of image analysis are vital for efficient healthcare image management. This research paper introduces an innovative healthcare architecture that tackles the challenges of analysis efficiency and accuracy by harnessing the capabilities of Artificial Intelligence (AI). Specifically, the proposed architecture utilizes fog computing and presents a modified Convolutional Neural Network (CNN) designed specifically for image analysis. Different architectures of CNN layers are thoroughly explored and evaluated to optimize overall performance. To demonstrate the effectiveness of the proposed approach, a dataset of X-ray images is utilized for analysis and evaluation. Comparative assessments are conducted against recent models such as VGG16, VGG19, MobileNet, and related research papers. Notably, the proposed approach achieves an exceptional accuracy rate of 99.88% in classifying normal cases, accompanied by a validation rate of 96.5%, precision and recall rates of 100%, and an F1 score of 100%. These results highlight the immense potential of fog computing and modified CNNs in revolutionizing healthcare image analysis and diagnosis, not only during pandemics but also in the future. By leveraging these technologies, healthcare professionals can enhance the efficiency and accuracy of medical image analysis, leading to improved patient care and outcomes.
Better with Less: A Data-Active Perspective on Pre-Training Graph Neural Networks
Nov 02, 2023Pre-training on graph neural networks (GNNs) aims to learn transferable knowledge for downstream tasks with unlabeled data, and it has recently become an active research area. The success of graph pre-training models is often attributed to the massive amount of input data. In this paper, however, we identify the curse of big data phenomenon in graph pre-training: more training data do not necessarily lead to better downstream performance. Motivated by this observation, we propose a better-with-less framework for graph pre-training: fewer, but carefully chosen data are fed into a GNN model to enhance pre-training. The proposed pre-training pipeline is called the data-active graph pre-training (APT) framework, and is composed of a graph selector and a pre-training model. The graph selector chooses the most representative and instructive data points based on the inherent properties of graphs as well as predictive uncertainty. The proposed predictive uncertainty, as feedback from the pre-training model, measures the confidence level of the model in the data. When fed with the chosen data, on the other hand, the pre-training model grasps an initial understanding of the new, unseen data, and at the same time attempts to remember the knowledge learned from previous data. Therefore, the integration and interaction between these two components form a unified framework (APT), in which graph pre-training is performed in a progressive and iterative way. Experiment results show that the proposed APT is able to obtain an efficient pre-training model with fewer training data and better downstream performance.
An Efficient Detection and Control System for Underwater Docking using Machine Learning and Realistic Simulation: A Comprehensive Approach
Nov 02, 2023
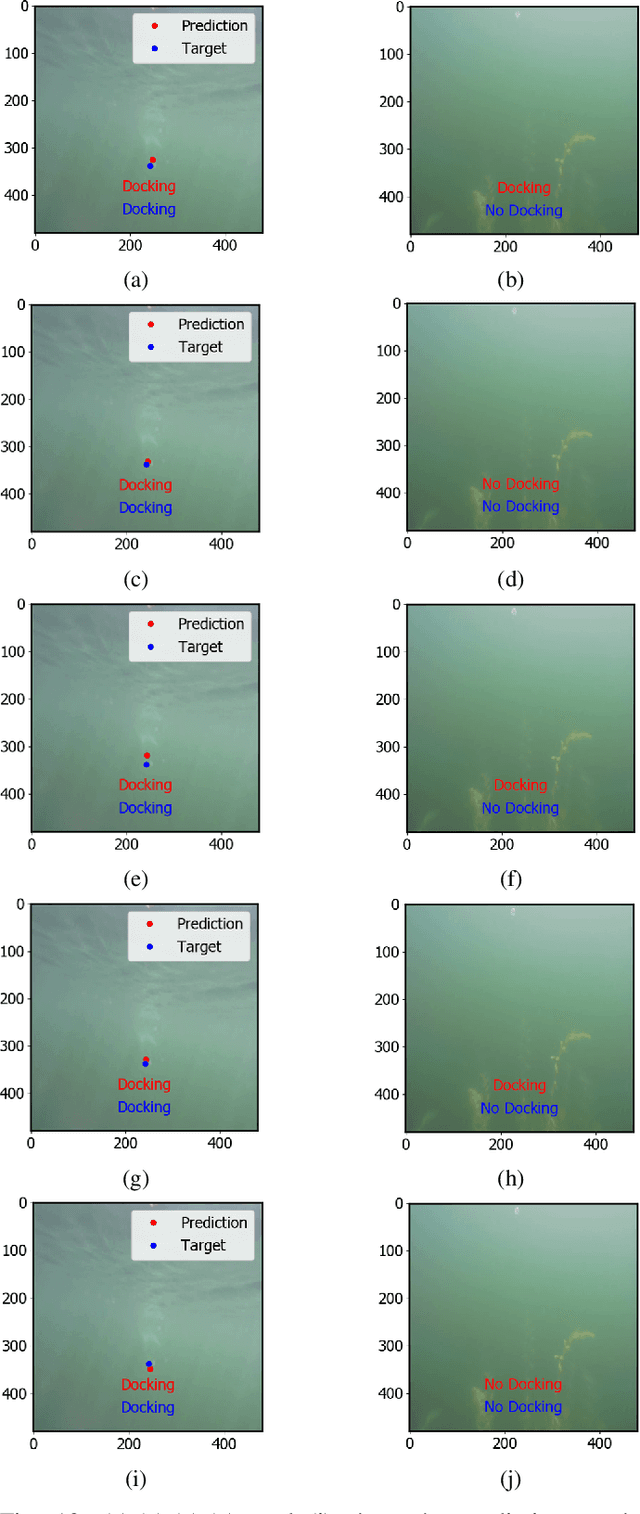


Underwater docking is critical to enable the persistent operation of Autonomous Underwater Vehicles (AUVs). For this, the AUV must be capable of detecting and localizing the docking station, which is complex due to the highly dynamic undersea environment. Image-based solutions offer a high acquisition rate and versatile alternative to adapt to this environment; however, the underwater environment presents challenges such as low visibility, high turbidity, and distortion. In addition to this, field experiments to validate underwater docking capabilities can be costly and dangerous due to the specialized equipment and safety considerations required to conduct the experiments. This work compares different deep-learning architectures to perform underwater docking detection and classification. The architecture with the best performance is then compressed using knowledge distillation under the teacher-student paradigm to reduce the network's memory footprint, allowing real-time implementation. To reduce the simulation-to-reality gap, a Generative Adversarial Network (GAN) is used to do image-to-image translation, converting the Gazebo simulation image into a realistic underwater-looking image. The obtained image is then processed using an underwater image formation model to simulate image attenuation over distance under different water types. The proposed method is finally evaluated according to the AUV docking success rate and compared with classical vision methods. The simulation results show an improvement of 20% in the high turbidity scenarios regardless of the underwater currents. Furthermore, we show the performance of the proposed approach by showing experimental results on the off-the-shelf AUV Iver3.
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Nov 01, 2023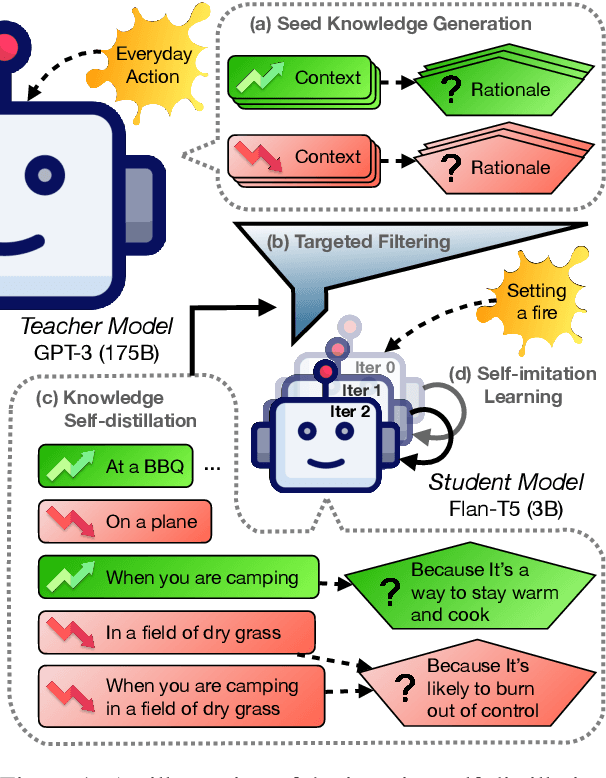
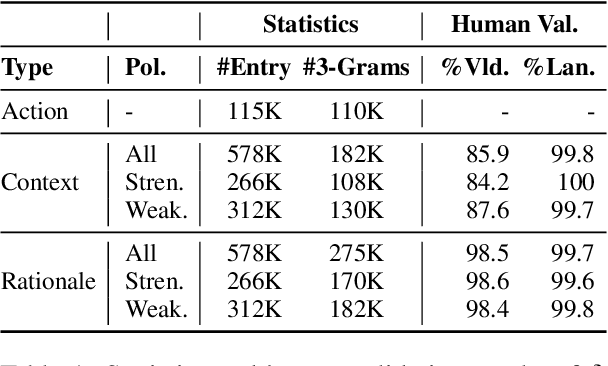
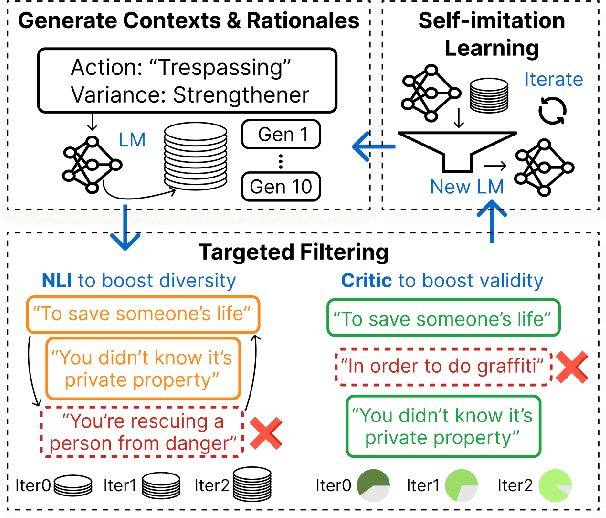
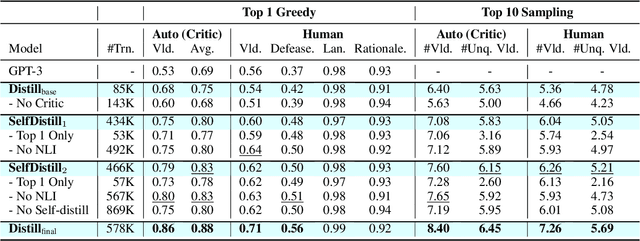
Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of defeasible contextualizations (i.e., additional information that strengthens or attenuates the moral acceptability of an action) is critical to accurately represent the subtlety and intricacy of grounded human moral judgment in real-life scenarios. We introduce defeasible moral reasoning: a task to provide grounded contexts that make an action more or less morally acceptable, along with commonsense rationales that justify the reasoning. To elicit high-quality task data, we take an iterative self-distillation approach that starts from a small amount of unstructured seed knowledge from GPT-3 and then alternates between (1) self-distillation from student models; (2) targeted filtering with a critic model trained by human judgment (to boost validity) and NLI (to boost diversity); (3) self-imitation learning (to amplify the desired data quality). This process yields a student model that produces defeasible contexts with improved validity, diversity, and defeasibility. From this model we distill a high-quality dataset, \delta-Rules-of-Thumb, of 1.2M entries of contextualizations and rationales for 115K defeasible moral actions rated highly by human annotators 85.9% to 99.8% of the time. Using \delta-RoT we obtain a final student model that wins over all intermediate student models by a notable margin.
Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures
Nov 01, 2023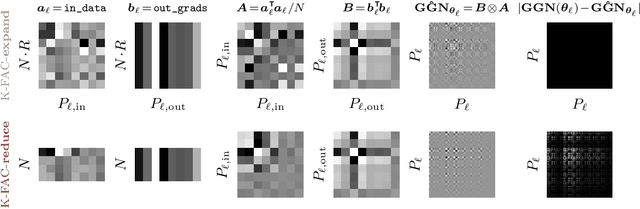
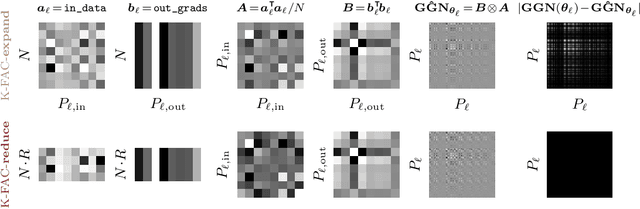
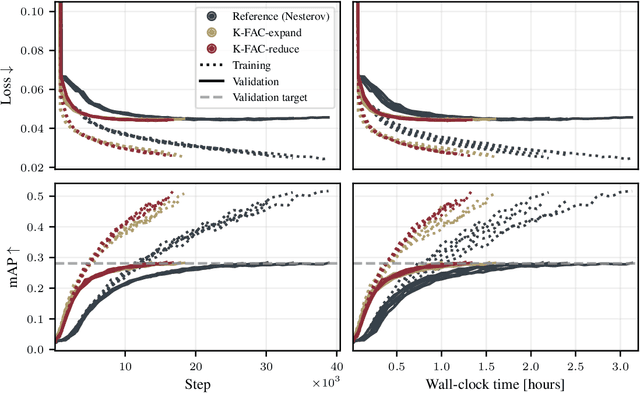

The core components of many modern neural network architectures, such as transformers, convolutional, or graph neural networks, can be expressed as linear layers with $\textit{weight-sharing}$. Kronecker-Factored Approximate Curvature (K-FAC), a second-order optimisation method, has shown promise to speed up neural network training and thereby reduce computational costs. However, there is currently no framework to apply it to generic architectures, specifically ones with linear weight-sharing layers. In this work, we identify two different settings of linear weight-sharing layers which motivate two flavours of K-FAC -- $\textit{expand}$ and $\textit{reduce}$. We show that they are exact for deep linear networks with weight-sharing in their respective setting. Notably, K-FAC-reduce is generally faster than K-FAC-expand, which we leverage to speed up automatic hyperparameter selection via optimising the marginal likelihood for a Wide ResNet. Finally, we observe little difference between these two K-FAC variations when using them to train both a graph neural network and a vision transformer. However, both variations are able to reach a fixed validation metric target in $50$-$75\%$ of the number of steps of a first-order reference run, which translates into a comparable improvement in wall-clock time. This highlights the potential of applying K-FAC to modern neural network architectures.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Rule-Based Error Classification for Analyzing Differences in Frequent Errors
Nov 01, 2023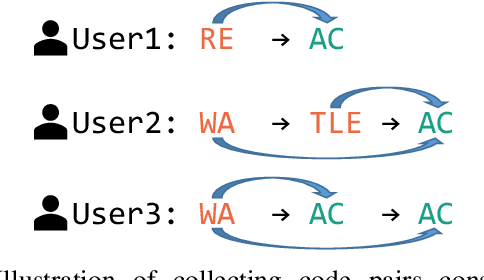
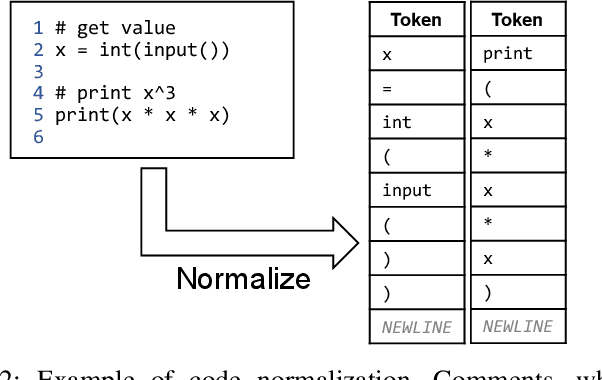
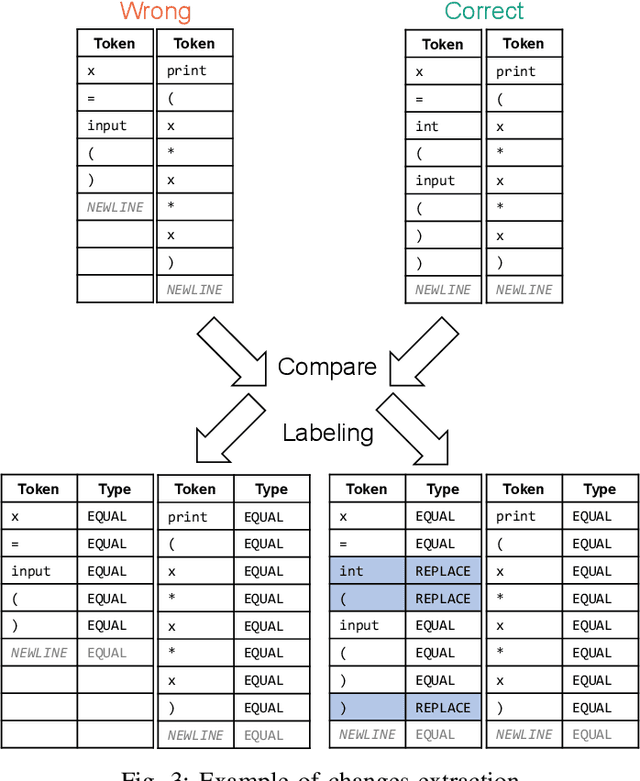

Finding and fixing errors is a time-consuming task not only for novice programmers but also for expert programmers. Prior work has identified frequent error patterns among various levels of programmers. However, the differences in the tendencies between novices and experts have yet to be revealed. From the knowledge of the frequent errors in each level of programmers, instructors will be able to provide helpful advice for each level of learners. In this paper, we propose a rule-based error classification tool to classify errors in code pairs consisting of wrong and correct programs. We classify errors for 95,631 code pairs and identify 3.47 errors on average, which are submitted by various levels of programmers on an online judge system. The classified errors are used to analyze the differences in frequent errors between novice and expert programmers. The analyzed results show that, as for the same introductory problems, errors made by novices are due to the lack of knowledge in programming, and the mistakes are considered an essential part of the learning process. On the other hand, errors made by experts are due to misunderstandings caused by the carelessness of reading problems or the challenges of solving problems differently than usual. The proposed tool can be used to create error-labeled datasets and for further code-related educational research.
From Image to Language: A Critical Analysis of Visual Question Answering (VQA) Approaches, Challenges, and Opportunities
Nov 01, 2023The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.
An Innovative Tool for Uploading/Scraping Large Image Datasets on Social Networks
Nov 01, 2023Nowadays, people can retrieve and share digital information in an increasingly easy and fast fashion through the well-known digital platforms, including sensitive data, inappropriate or illegal content, and, in general, information that might serve as probative evidence in court. Consequently, to assess forensics issues, we need to figure out how to trace back to the posting chain of a digital evidence (e.g., a picture, an audio) throughout the involved platforms -- this is what Digital (also Forensics) Ballistics basically deals with. With the entry of Machine Learning as a tool of the trade in many research areas, the need for vast amounts of data has been dramatically increasing over the last few years. However, collecting or simply find the "right" datasets that properly enables data-driven research studies can turn out to be not trivial in some cases, if not extremely challenging, especially when it comes with highly specialized tasks, such as creating datasets analyzed to detect the source media platform of a given digital media. In this paper we propose an automated approach by means of a digital tool that we created on purpose. The tool is capable of automatically uploading an entire image dataset to the desired digital platform and then downloading all the uploaded pictures, thus shortening the overall time required to output the final dataset to be analyzed.
Channel Estimation for Reconfigurable Intelligent Surface MIMO with Tensor Signal Modelling
Nov 01, 2023We consider a narrowband MIMO reconfigurable intelligent surface (RIS)-assisted wireless communication system and use tensor signal modelling techniques to individually estimate all communication channels including the non-RIS channels (direct path) and decoupled RIS channels. We model the received signal as a third-order tensor composed of two CANDECOMP/PARAFAC decomposition terms for the non-RIS and the RIS-assisted links, respectively, and we propose two channel estimation methods based on an iterative alternating least squares (ALS) algorithm: The two-stage RIS OFF-ON method estimates each of the non-RIS and RIS-assisted terms in two pilot training stages, whereas the enhanced alternating least squares (E-ALS) method improves upon the ALS algorithm to jointly estimate all channels over the full training duration. A key benefit of both methods compared to the traditional least squares (LS) solution is that they exploit the structure of the tensor model to obtain decoupled estimates of all communication channels. We provide the computational complexities to obtain each of the channel estimates for our two proposed methods. Numerical simulations are used to evaluate the accuracy and verify the computational complexities of the proposed two-stage RIS OFF-ON, and E-ALS, and compare them to the traditional LS methods. Results show that E-ALS will obtain the most accurate estimate while only having a slightly higher run-time than the two-stage method.