 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TFDNet: Time-Frequency Enhanced Decomposed Network for Long-term Time Series Forecasting
Aug 25, 2023
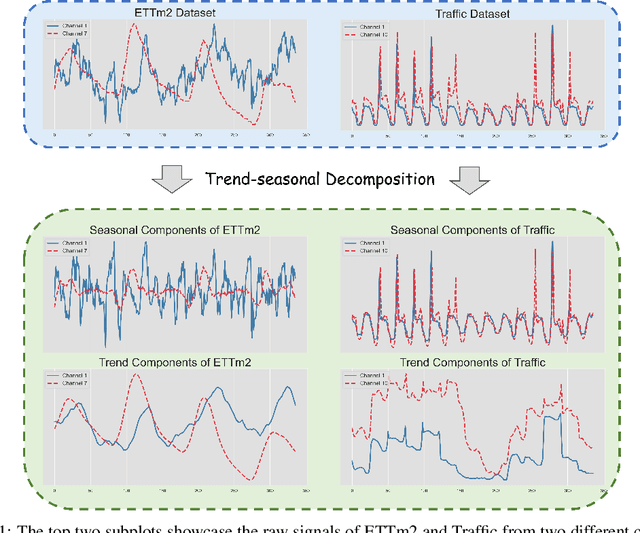
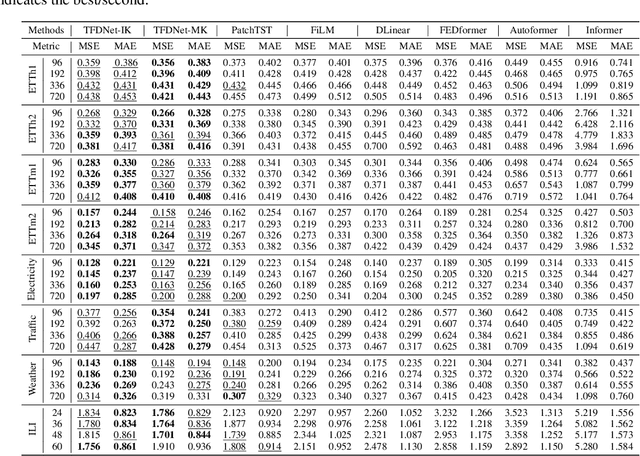
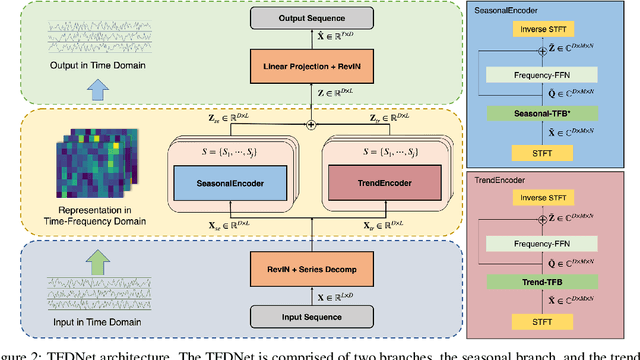
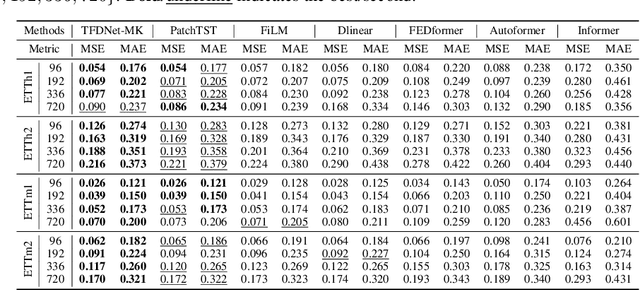
Long-term time series forecasting is a vital task and has a wide range of real applications. Recent methods focus on capturing the underlying patterns from one single domain (e.g. the time domain or the frequency domain), and have not taken a holistic view to process long-term time series from the time-frequency domains. In this paper, we propose a Time-Frequency Enhanced Decomposed Network (TFDNet) to capture both the long-term underlying patterns and temporal periodicity from the time-frequency domain. In TFDNet, we devise a multi-scale time-frequency enhanced encoder backbone and develop two separate trend and seasonal time-frequency blocks to capture the distinct patterns within the decomposed trend and seasonal components in multi-resolutions. Diverse kernel learning strategies of the kernel operations in time-frequency blocks have been explored, by investigating and incorporating the potential different channel-wise correlation patterns of multivariate time series. Experimental evaluation of eight datasets from five benchmark domains demonstrated that TFDNet is superior to state-of-the-art approaches in both effectiveness and efficiency.
MAAIG: Motion Analysis And Instruction Generation
Nov 02, 2023Many people engage in self-directed sports training at home but lack the real-time guidance of professional coaches, making them susceptible to injuries or the development of incorrect habits. In this paper, we propose a novel application framework called MAAIG(Motion Analysis And Instruction Generation). It can generate embedding vectors for each frame based on user-provided sports action videos. These embedding vectors are associated with the 3D skeleton of each frame and are further input into a pretrained T5 model. Ultimately, our model utilizes this information to generate specific sports instructions. It has the capability to identify potential issues and provide real-time guidance in a manner akin to professional coaches, helping users improve their sports skills and avoid injuries.
HPC-based Solvers of Minimisation Problems for Signal Processing
Nov 03, 2023Several physics and engineering applications involve the solution of a minimisation problem to compute an approximation of the input signal. Modern computing hardware and software apply high-performance computing to solve and considerably reduce the execution time. We compare and analyse different minimisation methods in terms of functional computation, convergence, execution time, and scalability properties, for the solution of two minimisation problems (i.e., approximation and denoising) with different constraints that involve computationally expensive operations. These problems are attractive due to their numerical and analytical properties, and our general analysis can be extended to most signal-processing problems. We perform our tests on the Cineca Marconi100 cluster, at the 26th position in the top500 list. Our experimental results show that PRAXIS is the best optimiser in terms of minima computation: the efficiency of the approximation is 38% with 256 processes, while the denoising has 46% with 32 processes.
FENCE: Fairplay Ensuring Network Chain Entity for Real-Time Multiple ID Detection at Scale In Fantasy Sports
Oct 09, 2023Dream11 takes pride in being a unique platform that enables over 190 million fantasy sports users to demonstrate their skills and connect deeper with their favorite sports. While managing such a scale, one issue we are faced with is duplicate/multiple account creation in the system. This is done by some users with the intent of abusing the platform, typically for bonus offers. The challenge is to detect these multiple accounts before it is too late. We propose a graph-based solution to solve this problem in which we first predict edges/associations between users. Using the edge information we highlight clusters of colluding multiple accounts. In this paper, we talk about our distributed ML system which is deployed to serve and support the inferences from our detection models. The challenge is to do this in real-time in order to take corrective actions. A core part of this setup also involves human-in-the-loop components for validation, feedback, and ground-truth labeling.
3DiffTection: 3D Object Detection with Geometry-Aware Diffusion Features
Nov 07, 2023We present 3DiffTection, a state-of-the-art method for 3D object detection from single images, leveraging features from a 3D-aware diffusion model. Annotating large-scale image data for 3D detection is resource-intensive and time-consuming. Recently, pretrained large image diffusion models have become prominent as effective feature extractors for 2D perception tasks. However, these features are initially trained on paired text and image data, which are not optimized for 3D tasks, and often exhibit a domain gap when applied to the target data. Our approach bridges these gaps through two specialized tuning strategies: geometric and semantic. For geometric tuning, we fine-tune a diffusion model to perform novel view synthesis conditioned on a single image, by introducing a novel epipolar warp operator. This task meets two essential criteria: the necessity for 3D awareness and reliance solely on posed image data, which are readily available (e.g., from videos) and does not require manual annotation. For semantic refinement, we further train the model on target data with detection supervision. Both tuning phases employ ControlNet to preserve the integrity of the original feature capabilities. In the final step, we harness these enhanced capabilities to conduct a test-time prediction ensemble across multiple virtual viewpoints. Through our methodology, we obtain 3D-aware features that are tailored for 3D detection and excel in identifying cross-view point correspondences. Consequently, our model emerges as a powerful 3D detector, substantially surpassing previous benchmarks, e.g., Cube-RCNN, a precedent in single-view 3D detection by 9.43\% in AP3D on the Omni3D-ARkitscene dataset. Furthermore, 3DiffTection showcases robust data efficiency and generalization to cross-domain data.
Machine learning for uncertainty estimation in fusing precipitation observations from satellites and ground-based gauges
Nov 13, 2023To form precipitation datasets that are accurate and, at the same time, have high spatial densities, data from satellites and gauges are often merged in the literature. However, uncertainty estimates for the data acquired in this manner are scarcely provided, although the importance of uncertainty quantification in predictive modelling is widely recognized. Furthermore, the benefits that machine learning can bring to the task of providing such estimates have not been broadly realized and properly explored through benchmark experiments. The present study aims at filling in this specific gap by conducting the first benchmark tests on the topic. On a large dataset that comprises 15-year-long monthly data spanning across the contiguous United States, we extensively compared six learners that are, by their construction, appropriate for predictive uncertainty quantification. These are the quantile regression (QR), quantile regression forests (QRF), generalized random forests (GRF), gradient boosting machines (GBM), light gradient boosting machines (LightGBM) and quantile regression neural networks (QRNN). The comparison referred to the competence of the learners in issuing predictive quantiles at nine levels that facilitate a good approximation of the entire predictive probability distribution, and was primarily based on the quantile and continuous ranked probability skill scores. Three types of predictor variables (i.e., satellite precipitation variables, distances between a point of interest and satellite grid points, and elevation at a point of interest) were used in the comparison and were additionally compared with each other. This additional comparison was based on the explainable machine learning concept of feature importance. The results suggest that the order from the best to the worst of the learners for the task investigated is the following: LightGBM, QRF, GRF, GBM, QRNN and QR...
MetaSymNet: A Dynamic Symbolic Regression Network Capable of Evolving into Arbitrary Formulations
Nov 13, 2023Mathematical formulas serve as the means of communication between humans and nature, encapsulating the operational laws governing natural phenomena. The concise formulation of these laws is a crucial objective in scientific research and an important challenge for artificial intelligence (AI). While traditional artificial neural networks (MLP) excel at data fitting, they often yield uninterpretable black box results that hinder our understanding of the relationship between variables x and predicted values y. Moreover, the fixed network architecture in MLP often gives rise to redundancy in both network structure and parameters. To address these issues, we propose MetaSymNet, a novel neural network that dynamically adjusts its structure in real-time, allowing for both expansion and contraction. This adaptive network employs the PANGU meta function as its activation function, which is a unique type capable of evolving into various basic functions during training to compose mathematical formulas tailored to specific needs. We then evolve the neural network into a concise, interpretable mathematical expression. To evaluate MetaSymNet's performance, we compare it with four state-of-the-art symbolic regression algorithms across more than 10 public datasets comprising 222 formulas. Our experimental results demonstrate that our algorithm outperforms others consistently regardless of noise presence or absence. Furthermore, we assess MetaSymNet against MLP and SVM regarding their fitting ability and extrapolation capability, these are two essential aspects of machine learning algorithms. The findings reveal that our algorithm excels in both areas. Finally, we compared MetaSymNet with MLP using iterative pruning in network structure complexity. The results show that MetaSymNet's network structure complexity is obviously less than MLP under the same goodness of fit.
Quantized Distillation: Optimizing Driver Activity Recognition Models for Resource-Constrained Environments
Nov 10, 2023Deep learning-based models are at the forefront of most driver observation benchmarks due to their remarkable accuracies but are also associated with high computational costs. This is challenging, as resources are often limited in real-world driving scenarios. This paper introduces a lightweight framework for resource-efficient driver activity recognition. The framework enhances 3D MobileNet, a neural architecture optimized for speed in video classification, by incorporating knowledge distillation and model quantization to balance model accuracy and computational efficiency. Knowledge distillation helps maintain accuracy while reducing the model size by leveraging soft labels from a larger teacher model (I3D), instead of relying solely on original ground truth data. Model quantization significantly lowers memory and computation demands by using lower precision integers for model weights and activations. Extensive testing on a public dataset for in-vehicle monitoring during autonomous driving demonstrates that this new framework achieves a threefold reduction in model size and a 1.4-fold improvement in inference time, compared to an already optimized architecture. The code for this study is available at https://github.com/calvintanama/qd-driver-activity-reco.
Does Differential Privacy Prevent Backdoor Attacks in Practice?
Nov 10, 2023
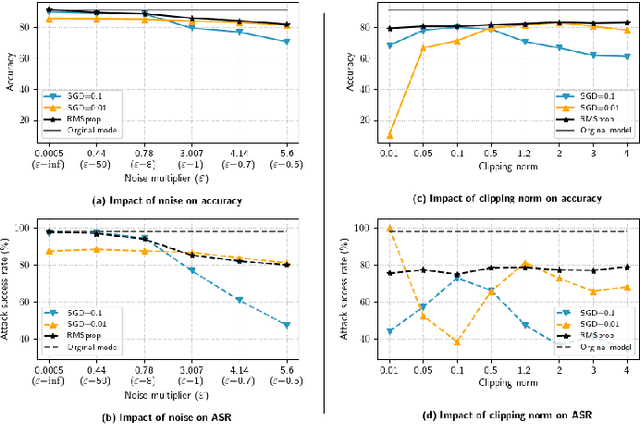
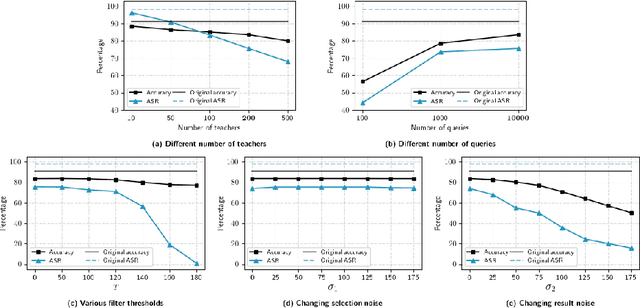

Differential Privacy (DP) was originally developed to protect privacy. However, it has recently been utilized to secure machine learning (ML) models from poisoning attacks, with DP-SGD receiving substantial attention. Nevertheless, a thorough investigation is required to assess the effectiveness of different DP techniques in preventing backdoor attacks in practice. In this paper, we investigate the effectiveness of DP-SGD and, for the first time in literature, examine PATE in the context of backdoor attacks. We also explore the role of different components of DP algorithms in defending against backdoor attacks and will show that PATE is effective against these attacks due to the bagging structure of the teacher models it employs. Our experiments reveal that hyperparameters and the number of backdoors in the training dataset impact the success of DP algorithms. Additionally, we propose Label-DP as a faster and more accurate alternative to DP-SGD and PATE. We conclude that while Label-DP algorithms generally offer weaker privacy protection, accurate hyper-parameter tuning can make them more effective than DP methods in defending against backdoor attacks while maintaining model accuracy.
Lidar-based Norwegian tree species detection using deep learning
Nov 10, 2023Background: The mapping of tree species within Norwegian forests is a time-consuming process, involving forest associations relying on manual labeling by experts. The process can involve both aerial imagery, personal familiarity, or on-scene references, and remote sensing data. The state-of-the-art methods usually use high resolution aerial imagery with semantic segmentation methods. Methods: We present a deep learning based tree species classification model utilizing only lidar (Light Detection And Ranging) data. The lidar images are segmented into four classes (Norway Spruce, Scots Pine, Birch, background) with a U-Net based network. The model is trained with focal loss over partial weak labels. A major benefit of the approach is that both the lidar imagery and the base map for the labels have free and open access. Results: Our tree species classification model achieves a macro-averaged F1 score of 0.70 on an independent validation with National Forest Inventory (NFI) in-situ sample plots. That is close to, but below the performance of aerial, or aerial and lidar combined models.