 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Function-constrained Program Synthesis
Nov 27, 2023
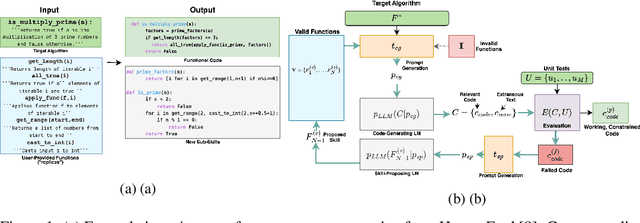



This work introduces (1) a technique that allows large language models (LLMs) to leverage user-provided code when solving programming tasks and (2) a method to iteratively generate modular sub-functions that can aid future code generation attempts when the initial code generated by the LLM is inadequate. Generating computer programs in general-purpose programming languages like Python poses a challenge for LLMs when instructed to use code provided in the prompt. Code-specific LLMs (e.g., GitHub Copilot, CodeLlama2) can generate code completions in real-time by drawing on all code available in a development environment. However, restricting code-specific LLMs to use only in-context code is not straightforward, as the model is not explicitly instructed to use the user-provided code and users cannot highlight precisely which snippets of code the model should incorporate into its context. Moreover, current systems lack effective recovery methods, forcing users to iteratively re-prompt the model with modified prompts until a sufficient solution is reached. Our method differs from traditional LLM-powered code-generation by constraining code-generation to an explicit function set and enabling recovery from failed attempts through automatically generated sub-functions. When the LLM cannot produce working code, we generate modular sub-functions to aid subsequent attempts at generating functional code. A by-product of our method is a library of reusable sub-functions that can solve related tasks, imitating a software team where efficiency scales with experience. We also introduce a new "half-shot" evaluation paradigm that provides tighter estimates of LLMs' coding abilities compared to traditional zero-shot evaluation. Our proposed evaluation method encourages models to output solutions in a structured format, decreasing syntax errors that can be mistaken for poor coding ability.
Path Planning in 3D with Motion Primitives for Wind Energy-Harvesting Fixed-Wing Aircraft
Nov 17, 2023In this work, a set of motion primitives is defined for use in an energy-aware motion planning problem. The motion primitives are defined as sequences of control inputs to a simplified four-DOF dynamics model and are used to replace the traditional continuous control space used in many sampling-based motion planners. The primitives are implemented in a Stable Sparse Rapidly Exploring Random Tree (SST) motion planner and compared to an identical planner using a continuous control space. The planner using primitives was found to run 11.0\% faster but yielded solution paths that were on average worse with higher variance. Also, the solution path travel time is improved by about 50\%. Using motion primitives for sampling spaces in SST can effectively reduce the run time of the algorithm, although at the cost of solution quality.
Sample-Driven Federated Learning for Energy-Efficient and Real-Time IoT Sensing
Oct 11, 2023
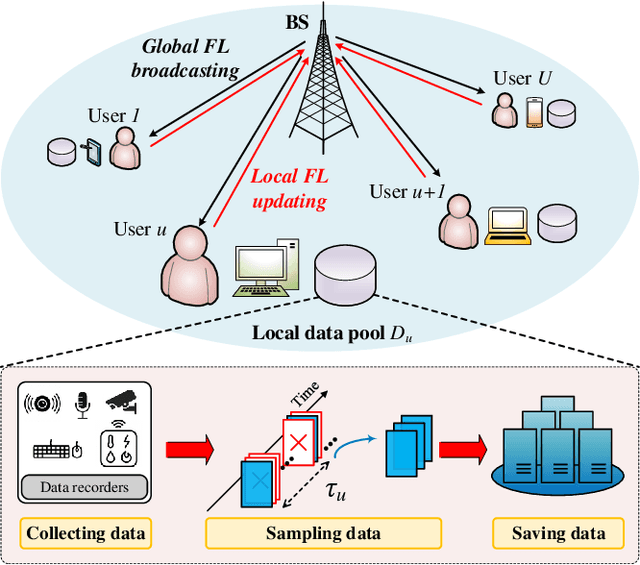
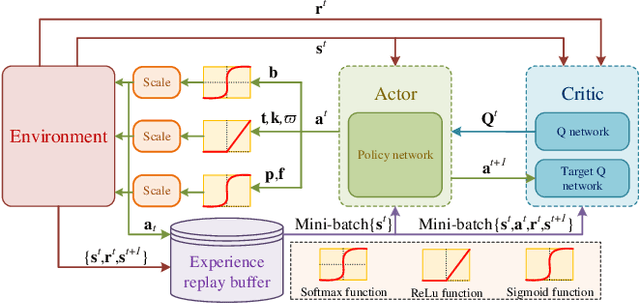
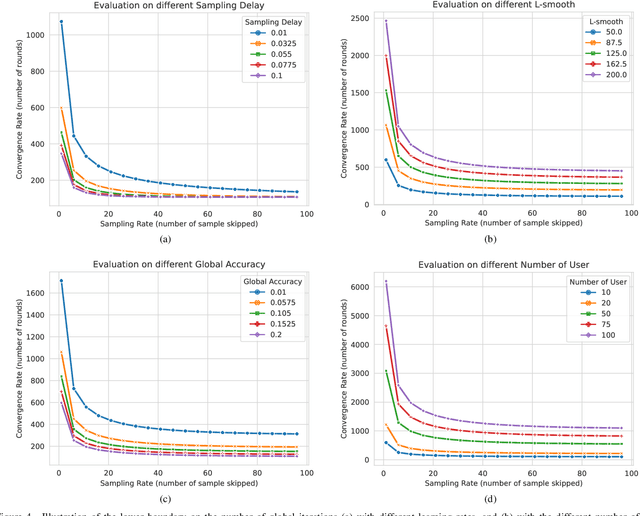
In the domain of Federated Learning (FL) systems, recent cutting-edge methods heavily rely on ideal conditions convergence analysis. Specifically, these approaches assume that the training datasets on IoT devices possess similar attributes to the global data distribution. However, this approach fails to capture the full spectrum of data characteristics in real-time sensing FL systems. In order to overcome this limitation, we suggest a new approach system specifically designed for IoT networks with real-time sensing capabilities. Our approach takes into account the generalization gap due to the user's data sampling process. By effectively controlling this sampling process, we can mitigate the overfitting issue and improve overall accuracy. In particular, We first formulate an optimization problem that harnesses the sampling process to concurrently reduce overfitting while maximizing accuracy. In pursuit of this objective, our surrogate optimization problem is adept at handling energy efficiency while optimizing the accuracy with high generalization. To solve the optimization problem with high complexity, we introduce an online reinforcement learning algorithm, named Sample-driven Control for Federated Learning (SCFL) built on the Soft Actor-Critic (A2C) framework. This enables the agent to dynamically adapt and find the global optima even in changing environments. By leveraging the capabilities of SCFL, our system offers a promising solution for resource allocation in FL systems with real-time sensing capabilities.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023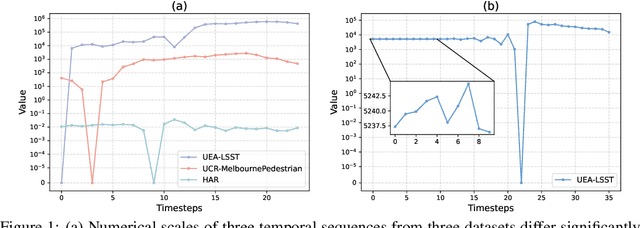
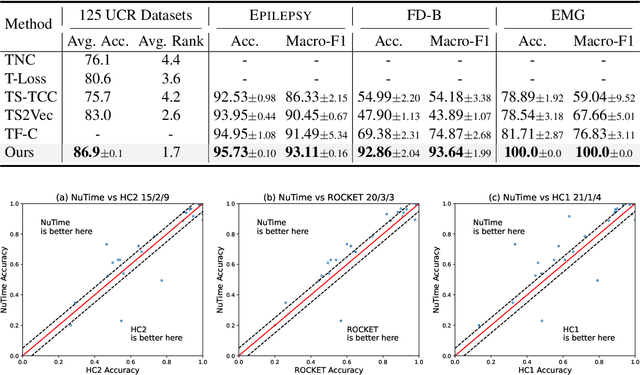
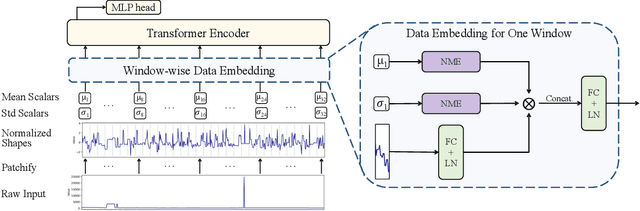
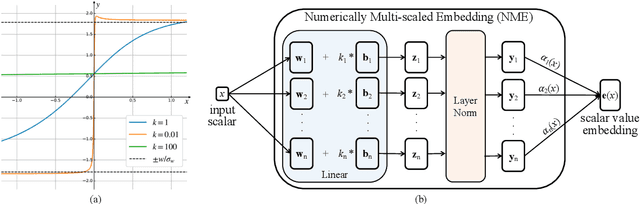
Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Echocardiogram Foundation Model -- Application 1: Estimating Ejection Fraction
Nov 21, 2023Cardiovascular diseases stand as the primary global cause of mortality. Among the various imaging techniques available for visualising the heart and evaluating its function, echocardiograms emerge as the preferred choice due to their safety and low cost. Quantifying cardiac function based on echocardiograms is very laborious, time-consuming and subject to high interoperator variability. In this work, we introduce EchoAI, an echocardiogram foundation model, that is trained using self-supervised learning (SSL) on 1.5 million echocardiograms. We evaluate our approach by fine-tuning EchoAI to estimate the ejection fraction achieving a mean absolute percentage error of 9.40%. This level of accuracy aligns with the performance of expert sonographers.
Clustered Policy Decision Ranking
Nov 21, 2023Policies trained via reinforcement learning (RL) are often very complex even for simple tasks. In an episode with n time steps, a policy will make n decisions on actions to take, many of which may appear non-intuitive to the observer. Moreover, it is not clear which of these decisions directly contribute towards achieving the reward and how significant their contribution is. Given a trained policy, we propose a black-box method based on statistical covariance estimation that clusters the states of the environment and ranks each cluster according to the importance of decisions made in its states. We compare our measure against a previous statistical fault localization based ranking procedure.
Deep Attentive Time Warping
Sep 13, 2023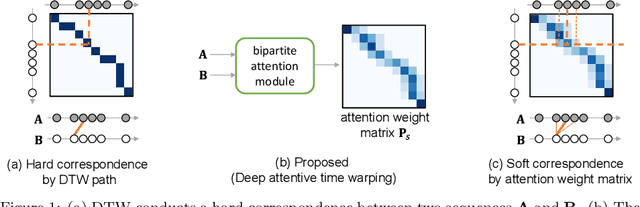
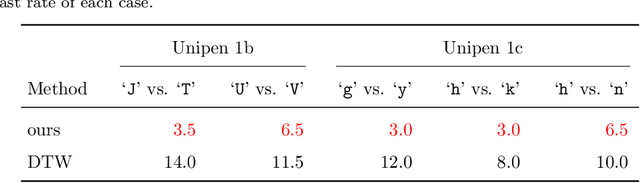
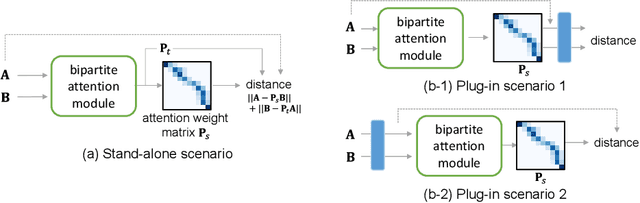
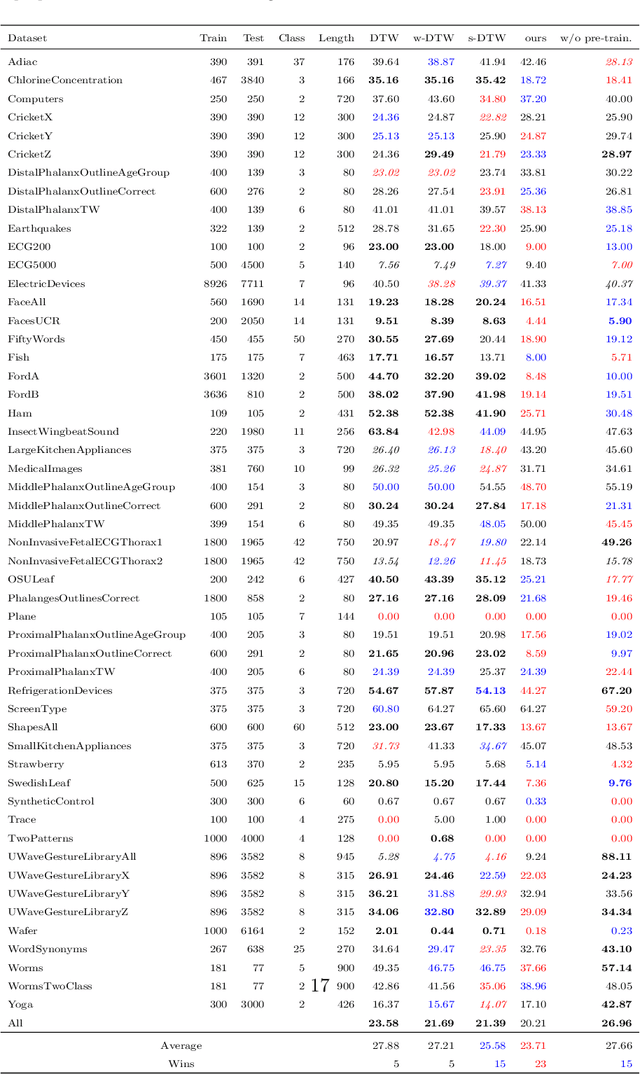
Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.
Message Propagation Through Time: An Algorithm for Sequence Dependency Retention in Time Series Modeling
Sep 28, 2023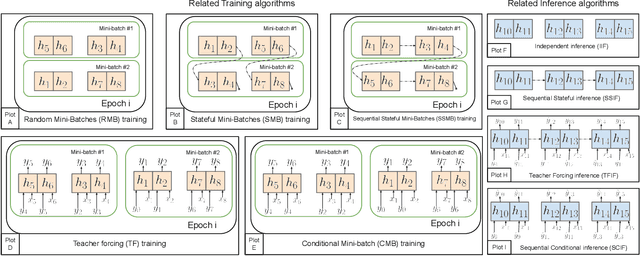
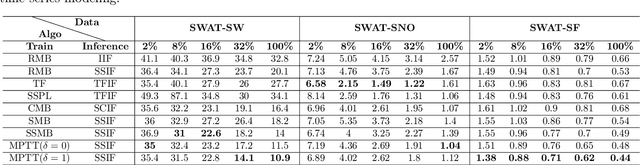
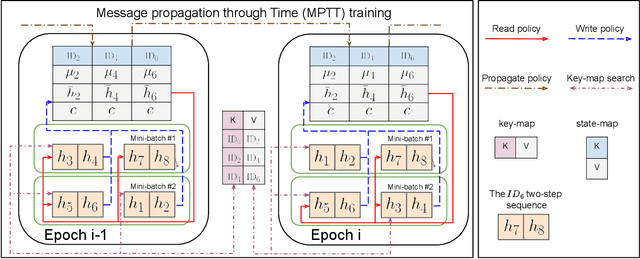

Time series modeling, a crucial area in science, often encounters challenges when training Machine Learning (ML) models like Recurrent Neural Networks (RNNs) using the conventional mini-batch training strategy that assumes independent and identically distributed (IID) samples and initializes RNNs with zero hidden states. The IID assumption ignores temporal dependencies among samples, resulting in poor performance. This paper proposes the Message Propagation Through Time (MPTT) algorithm to effectively incorporate long temporal dependencies while preserving faster training times relative to the stateful solutions. MPTT utilizes two memory modules to asynchronously manage initial hidden states for RNNs, fostering seamless information exchange between samples and allowing diverse mini-batches throughout epochs. MPTT further implements three policies to filter outdated and preserve essential information in the hidden states to generate informative initial hidden states for RNNs, facilitating robust training. Experimental results demonstrate that MPTT outperforms seven strategies on four climate datasets with varying levels of temporal dependencies.
Efficient Interpretable Nonlinear Modeling for Multiple Time Series
Sep 29, 2023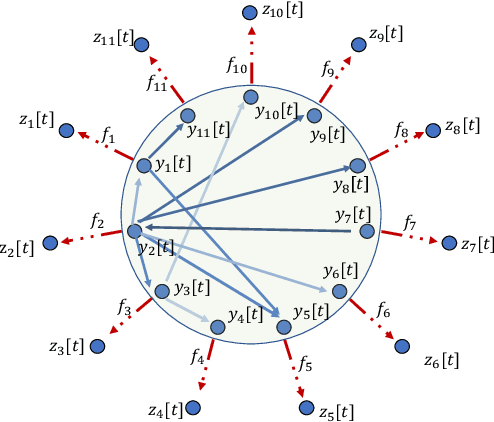
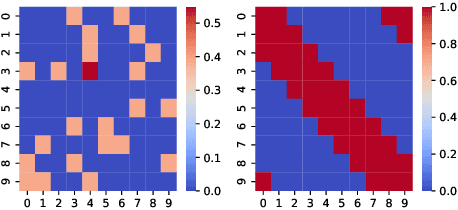
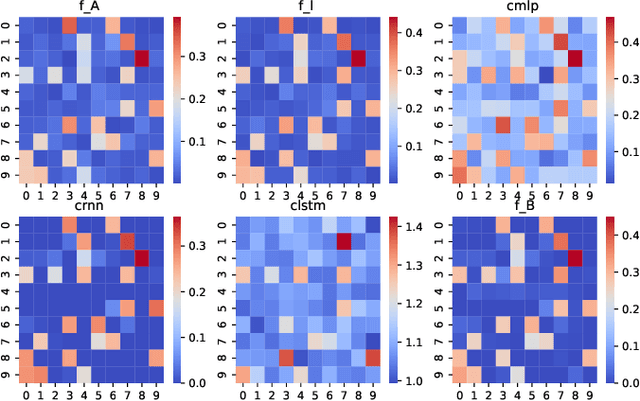
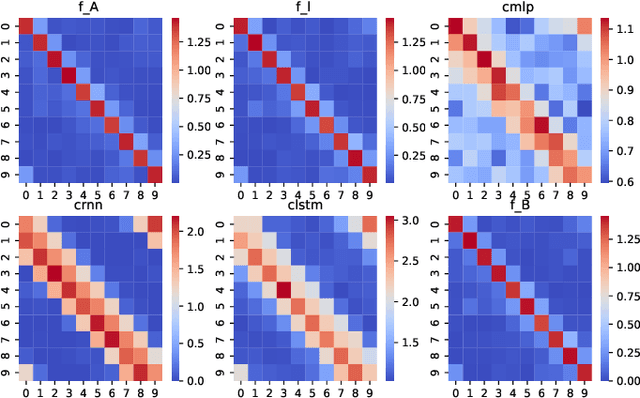
Predictive linear and nonlinear models based on kernel machines or deep neural networks have been used to discover dependencies among time series. This paper proposes an efficient nonlinear modeling approach for multiple time series, with a complexity comparable to linear vector autoregressive (VAR) models while still incorporating nonlinear interactions among different time-series variables. The modeling assumption is that the set of time series is generated in two steps: first, a linear VAR process in a latent space, and second, a set of invertible and Lipschitz continuous nonlinear mappings that are applied per sensor, that is, a component-wise mapping from each latent variable to a variable in the measurement space. The VAR coefficient identification provides a topology representation of the dependencies among the aforementioned variables. The proposed approach models each component-wise nonlinearity using an invertible neural network and imposes sparsity on the VAR coefficients to reflect the parsimonious dependencies usually found in real applications. To efficiently solve the formulated optimization problems, a custom algorithm is devised combining proximal gradient descent, stochastic primal-dual updates, and projection to enforce the corresponding constraints. Experimental results on both synthetic and real data sets show that the proposed algorithm improves the identification of the support of the VAR coefficients in a parsimonious manner while also improving the time-series prediction, as compared to the current state-of-the-art methods.
From Categories to Classifier: Name-Only Continual Learning by Exploring the Web
Nov 19, 2023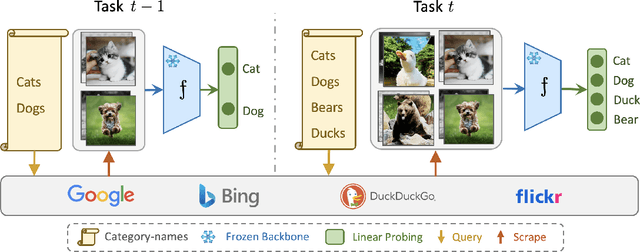
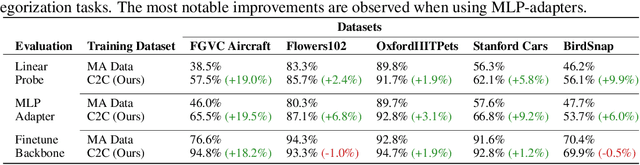

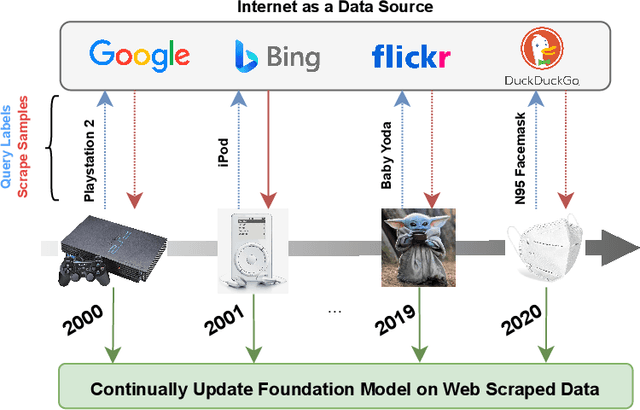
Continual Learning (CL) often relies on the availability of extensive annotated datasets, an assumption that is unrealistically time-consuming and costly in practice. We explore a novel paradigm termed name-only continual learning where time and cost constraints prohibit manual annotation. In this scenario, learners adapt to new category shifts using only category names without the luxury of annotated training data. Our proposed solution leverages the expansive and ever-evolving internet to query and download uncurated webly-supervised data for image classification. We investigate the reliability of our web data and find them comparable, and in some cases superior, to manually annotated datasets. Additionally, we show that by harnessing the web, we can create support sets that surpass state-of-the-art name-only classification that create support sets using generative models or image retrieval from LAION-5B, achieving up to 25% boost in accuracy. When applied across varied continual learning contexts, our method consistently exhibits a small performance gap in comparison to models trained on manually annotated datasets. We present EvoTrends, a class-incremental dataset made from the web to capture real-world trends, created in just minutes. Overall, this paper underscores the potential of using uncurated webly-supervised data to mitigate the challenges associated with manual data labeling in continual learning.