 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023
We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Optimization in Mobile Augmented Reality Systems for the Metaverse over Wireless Communications
Nov 29, 2023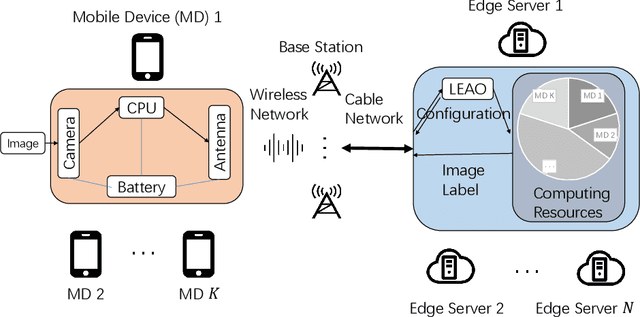
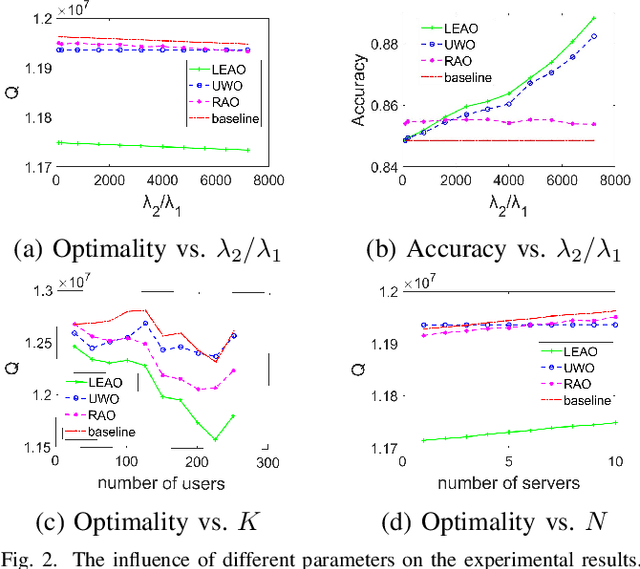
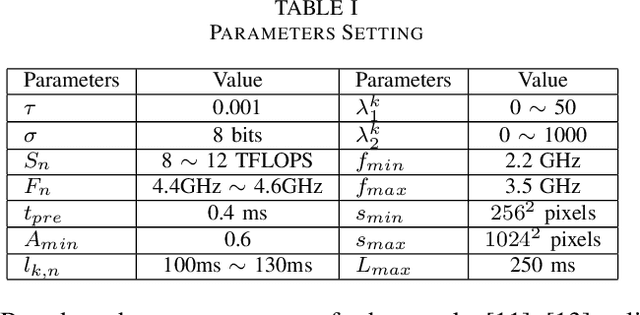
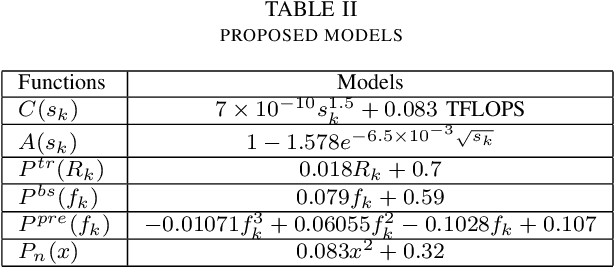
As the essential technical support for Metaverse, Mobile Augmented Reality (MAR) has attracted the attention of many researchers. MAR applications rely on real-time processing of visual and audio data, and thus those heavy workloads can quickly drain the battery of a mobile device. To address such problem, edge-based solutions have appeared for handling some tasks that require more computing power. However, such strategies introduce a new trade-off: reducing the network latency and overall energy consumption requires limiting the size of the data sent to the edge server, which, in turn, results in lower accuracy. In this paper, we design an edge-based MAR system and propose a mathematical model to describe it and analyze the trade-off between latency, accuracy, server resources allocation and energy consumption. Furthermore, an algorithm named LEAO is proposed to solve this problem. We evaluate the performance of the LEAO and other related algorithms across various simulation scenarios. The results demonstrate the superiority of the LEAO algorithm. Finally, our work provides insight into optimization problem in edge-based MAR system for Metaverse.
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams
Oct 16, 2023Test-time adaptation (TTA) aims to address distributional shifts between training and testing data using only unlabeled test data streams for continual model adaptation. However, most TTA methods assume benign test streams, while test samples could be unexpectedly diverse in the wild. For instance, an unseen object or noise could appear in autonomous driving. This leads to a new threat to existing TTA algorithms; we found that prior TTA algorithms suffer from those noisy test samples as they blindly adapt to incoming samples. To address this problem, we present Screening-out Test-Time Adaptation (SoTTA), a novel TTA algorithm that is robust to noisy samples. The key enabler of SoTTA is two-fold: (i) input-wise robustness via high-confidence uniform-class sampling that effectively filters out the impact of noisy samples and (ii) parameter-wise robustness via entropy-sharpness minimization that improves the robustness of model parameters against large gradients from noisy samples. Our evaluation with standard TTA benchmarks with various noisy scenarios shows that our method outperforms state-of-the-art TTA methods under the presence of noisy samples and achieves comparable accuracy to those methods without noisy samples. The source code is available at https://github.com/taeckyung/SoTTA .
URLLC-Awared Resource Allocation for Heterogeneous Vehicular Edge Computing
Nov 30, 2023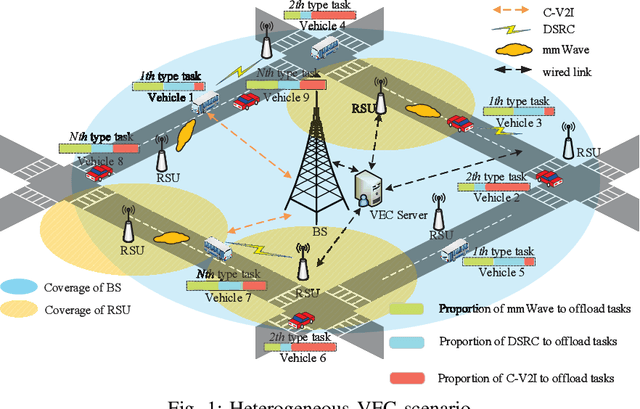
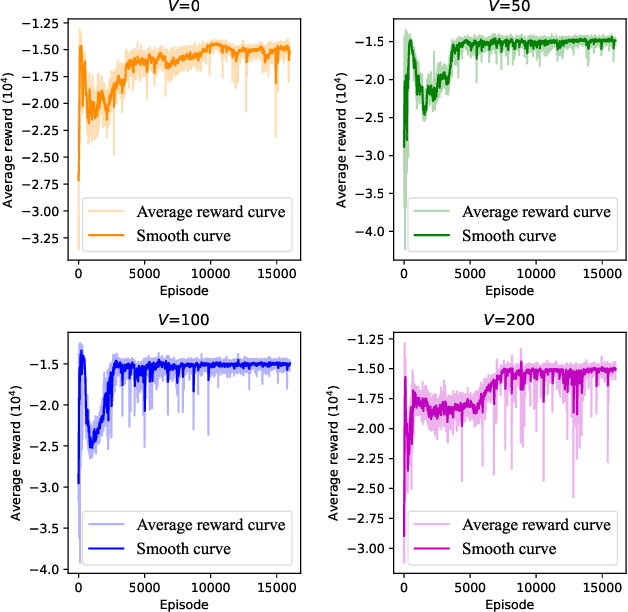
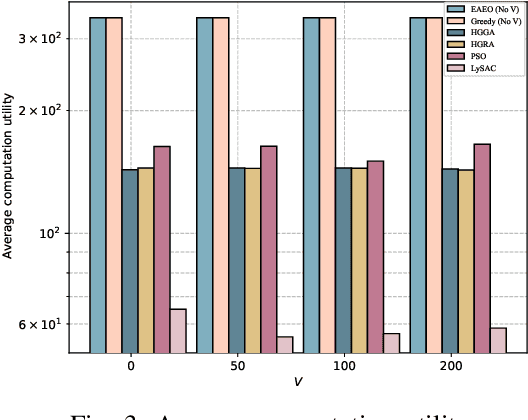
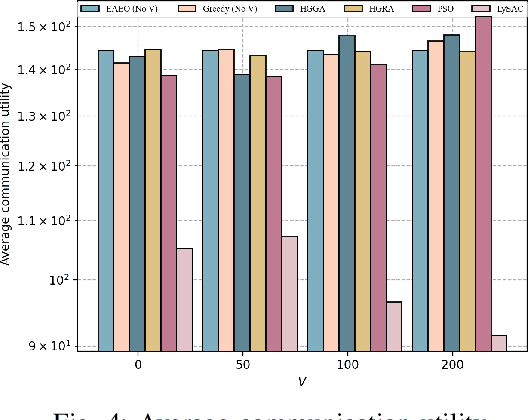
Vehicular edge computing (VEC) is a promising technology to support real-time vehicular applications, where vehicles offload intensive computation tasks to the nearby VEC server for processing. However, the traditional VEC that relies on single communication technology cannot well meet the communication requirement for task offloading, thus the heterogeneous VEC integrating the advantages of dedicated short-range communications (DSRC), millimeter-wave (mmWave) and cellular-based vehicle to infrastructure (C-V2I) is introduced to enhance the communication capacity. The communication resource allocation and computation resource allocation may significantly impact on the ultra-reliable low-latency communication (URLLC) performance and the VEC system utility, in this case, how to do the resource allocations is becoming necessary. In this paper, we consider a heterogeneous VEC with multiple communication technologies and various types of tasks, and propose an effective resource allocation policy to minimize the system utility while satisfying the URLLC requirement. We first formulate an optimization problem to minimize the system utility under the URLLC constraint which modeled by the moment generating function (MGF)-based stochastic network calculus (SNC), then we present a Lyapunov-guided deep reinforcement learning (DRL) method to convert and solve the optimization problem. Extensive simulation experiments illustrate that the proposed resource allocation approach is effective.
SPiC-E : Structural Priors in 3D Diffusion Models using Cross-Entity Attention
Nov 30, 2023We are witnessing rapid progress in automatically generating and manipulating 3D assets due to the availability of pretrained text-image diffusion models. However, time-consuming optimization procedures are required for synthesizing each sample, hindering their potential for democratizing 3D content creation. Conversely, 3D diffusion models now train on million-scale 3D datasets, yielding high-quality text-conditional 3D samples within seconds. In this work, we present SPiC-E - a neural network that adds structural guidance to 3D diffusion models, extending their usage beyond text-conditional generation. At its core, our framework introduces a cross-entity attention mechanism that allows for multiple entities (in particular, paired input and guidance 3D shapes) to interact via their internal representations within the denoising network. We utilize this mechanism for learning task-specific structural priors in 3D diffusion models from auxiliary guidance shapes. We show that our approach supports a variety of applications, including 3D stylization, semantic shape editing and text-conditional abstraction-to-3D, which transforms primitive-based abstractions into highly-expressive shapes. Extensive experiments demonstrate that SPiC-E achieves SOTA performance over these tasks while often being considerably faster than alternative methods. Importantly, this is accomplished without tailoring our approach for any specific task.
AV-RIR: Audio-Visual Room Impulse Response Estimation
Nov 30, 2023Accurate estimation of Room Impulse Response (RIR), which captures an environment's acoustic properties, is important for speech processing and AR/VR applications. We propose AV-RIR, a novel multi-modal multi-task learning approach to accurately estimate the RIR from a given reverberant speech signal and the visual cues of its corresponding environment. AV-RIR builds on a novel neural codec-based architecture that effectively captures environment geometry and materials properties and solves speech dereverberation as an auxiliary task by using multi-task learning. We also propose Geo-Mat features that augment material information into visual cues and CRIP that improves late reverberation components in the estimated RIR via image-to-RIR retrieval by 86%. Empirical results show that AV-RIR quantitatively outperforms previous audio-only and visual-only approaches by achieving 36% - 63% improvement across various acoustic metrics in RIR estimation. Additionally, it also achieves higher preference scores in human evaluation. As an auxiliary benefit, dereverbed speech from AV-RIR shows competitive performance with the state-of-the-art in various spoken language processing tasks and outperforms reverberation time error score in the real-world AVSpeech dataset. Qualitative examples of both synthesized reverberant speech and enhanced speech can be found at https://www.youtube.com/watch?v=tTsKhviukAE.
IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions
Nov 30, 2023Retrieval-Augmented Generation (RAG), by incorporating external knowledge with parametric memory of language models, has become the state-of-the-art architecture for open-domain QA tasks. However, common knowledge bases are inherently constrained by limited coverage and noisy information, making retrieval-based approaches inadequate to answer implicit reasoning questions. In this paper, we propose an Induction-Augmented Generation (IAG) framework that utilizes inductive knowledge along with the retrieved documents for implicit reasoning. We leverage large language models (LLMs) for deriving such knowledge via a novel prompting method based on inductive reasoning patterns. On top of this, we implement two versions of IAG named IAG-GPT and IAG-Student, respectively. IAG-GPT directly utilizes the knowledge generated by GPT-3 for answer prediction, while IAG-Student gets rid of dependencies on GPT service at inference time by incorporating a student inductor model. The inductor is firstly trained via knowledge distillation and further optimized by back-propagating the generator feedback via differentiable beam scores. Experimental results show that IAG outperforms RAG baselines as well as ChatGPT on two Open-Domain QA tasks. Notably, our best models have won the first place in the official leaderboards of CSQA2.0 (since Nov 1, 2022) and StrategyQA (since Jan 8, 2023).
MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition
Nov 30, 2023Large-scale pre-trained models have demonstrated impressive performance in vision and language tasks within open-world scenarios. Due to the lack of comparable pre-trained models for 3D shapes, recent methods utilize language-image pre-training to realize zero-shot 3D shape recognition. However, due to the modality gap, pretrained language-image models are not confident enough in the generalization to 3D shape recognition. Consequently, this paper aims to improve the confidence with view selection and hierarchical prompts. Leveraging the CLIP model as an example, we employ view selection on the vision side by identifying views with high prediction confidence from multiple rendered views of a 3D shape. On the textual side, the strategy of hierarchical prompts is proposed for the first time. The first layer prompts several classification candidates with traditional class-level descriptions, while the second layer refines the prediction based on function-level descriptions or further distinctions between the candidates. Remarkably, without the need for additional training, our proposed method achieves impressive zero-shot 3D classification accuracies of 84.44\%, 91.51\%, and 66.17\% on ModelNet40, ModelNet10, and ShapeNet Core55, respectively. Furthermore, we will make the code publicly available to facilitate reproducibility and further research in this area.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
A GPU-based Hydrodynamic Simulator with Boid Interactions
Nov 25, 2023We present a hydrodynamic simulation system using the GPU compute shaders of DirectX for simulating virtual agent behaviors and navigation inside a smoothed particle hydrodynamical (SPH) fluid environment with real-time water mesh surface reconstruction. The current SPH literature includes interactions between SPH and heterogeneous meshes but seldom involves interactions between SPH and virtual boid agents. The contribution of the system lies in the combination of the parallel smoothed particle hydrodynamics model with the distributed boid model of virtual agents to enable agents to interact with fluids. The agents based on the boid algorithm influence the motion of SPH fluid particles, and the forces from the SPH algorithm affect the movement of the boids. To enable realistic fluid rendering and simulation in a particle-based system, it is essential to construct a mesh from the particle attributes. Our system also contributes to the surface reconstruction aspect of the pipeline, in which we performed a set of experiments with the parallel marching cubes algorithm per frame for constructing the mesh from the fluid particles in a real-time compute and memory-intensive application, producing a wide range of triangle configurations. We also demonstrate that our system is versatile enough for reinforced robotic agents instead of boid agents to interact with the fluid environment for underwater navigation and remote control engineering purposes.