 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modyn: A Platform for Model Training on Dynamic Datasets With Sample-Level Data Selection
Dec 11, 2023
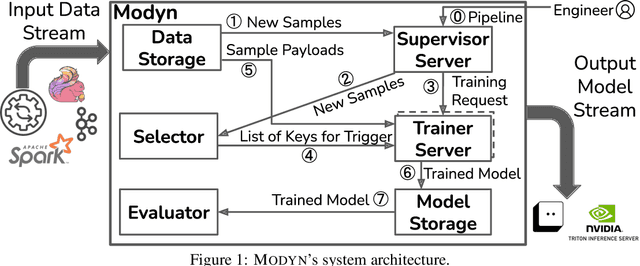

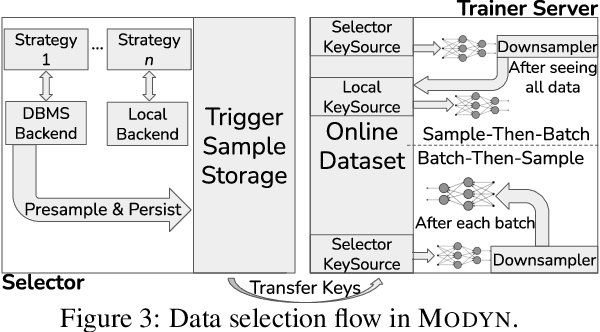
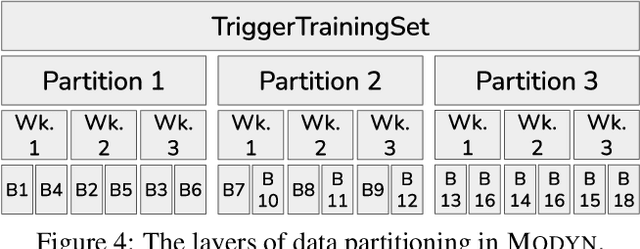
Machine learning training data is often dynamic in real-world use cases, i.e., data is added or removed and may experience distribution shifts over time. Models must incorporate this evolving training data to improve generalization, adapt to potential distribution shifts, and adhere to privacy regulations. However, the cost of model (re)training is proportional to how often the model trains and on how much data it trains on. While ML research explores these topics in isolation, there is no end-to-end open-source platform to facilitate the exploration of model retraining and data selection policies and the deployment these algorithms efficiently at scale. We present Modyn, a platform for model training on dynamic datasets that enables sample-level data selection and triggering policies. Modyn orchestrates continuous training pipelines while optimizing the underlying system infrastructure to support fast access to arbitrary data samples for efficient data selection. Modyn's extensible architecture allows users to run training pipelines without modifying the platform code, and enables researchers to effortlessly extend the system. We evaluate Modyn's training throughput, showing that even in memory-bound recommendation systems workloads, Modyn is able to reach 80 to 100 % of the throughput compared to loading big chunks of data locally without sample-level data selection. Additionally, we showcase Modyn's functionality with three different data selection policies.
Spreeze: High-Throughput Parallel Reinforcement Learning Framework
Dec 11, 2023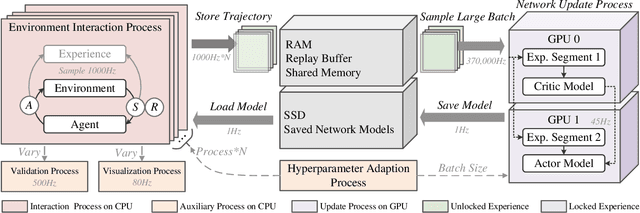

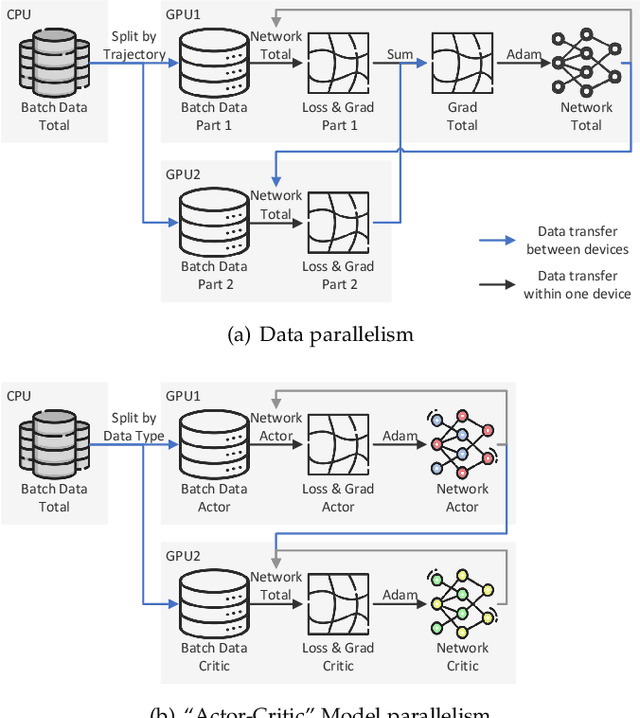
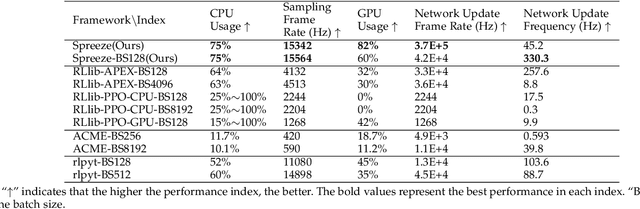
The promotion of large-scale applications of reinforcement learning (RL) requires efficient training computation. While existing parallel RL frameworks encompass a variety of RL algorithms and parallelization techniques, the excessively burdensome communication frameworks hinder the attainment of the hardware's limit for final throughput and training effects on a single desktop. In this paper, we propose Spreeze, a lightweight parallel framework for RL that efficiently utilizes a single desktop hardware resource to approach the throughput limit. We asynchronously parallelize the experience sampling, network update, performance evaluation, and visualization operations, and employ multiple efficient data transmission techniques to transfer various types of data between processes. The framework can automatically adjust the parallelization hyperparameters based on the computing ability of the hardware device in order to perform efficient large-batch updates. Based on the characteristics of the "Actor-Critic" RL algorithm, our framework uses dual GPUs to independently update the network of actors and critics in order to further improve throughput. Simulation results show that our framework can achieve up to 15,000Hz experience sampling and 370,000Hz network update frame rate using only a personal desktop computer, which is an order of magnitude higher than other mainstream parallel RL frameworks, resulting in a 73% reduction of training time. Our work on fully utilizing the hardware resources of a single desktop computer is fundamental to enabling efficient large-scale distributed RL training.
Efficient and Effective Similarity Search over Bipartite Graphs
Dec 11, 2023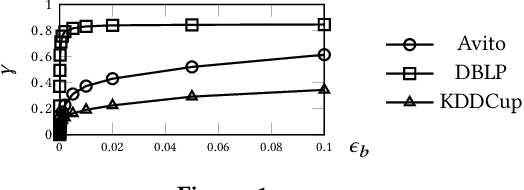
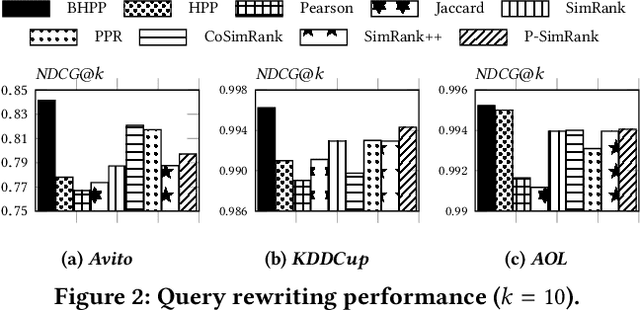
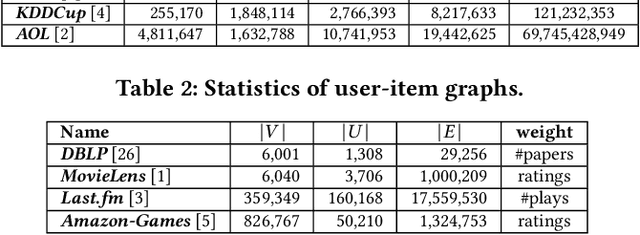
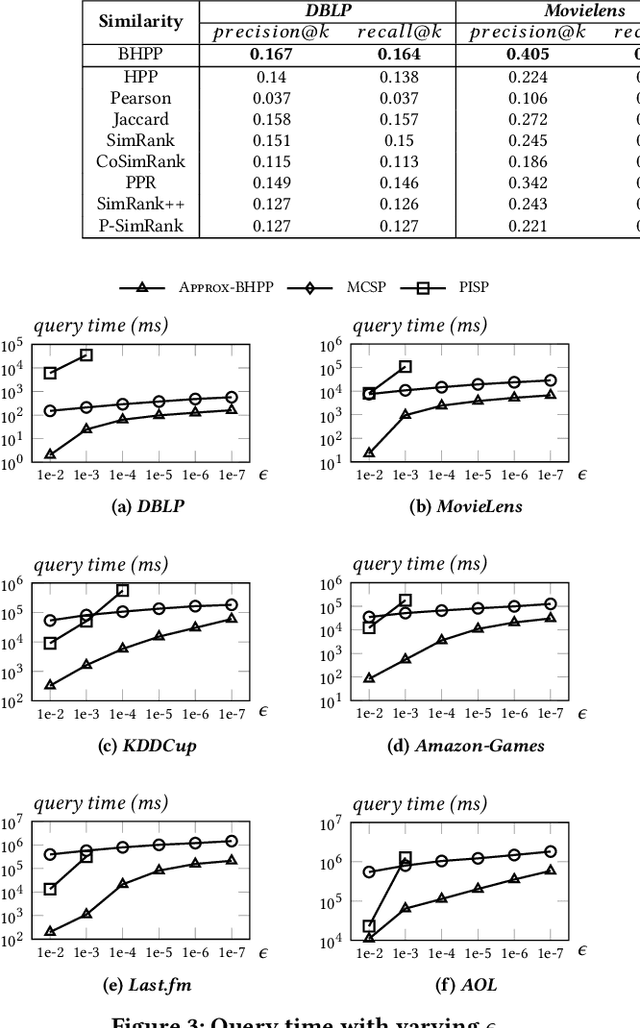
Similarity search over a bipartite graph aims to retrieve from the graph the nodes that are similar to each other, which finds applications in various fields such as online advertising, recommender systems etc. Existing similarity measures either (i) overlook the unique properties of bipartite graphs, or (ii) fail to capture high-order information between nodes accurately, leading to suboptimal result quality. Recently, Hidden Personalized PageRank (HPP) is applied to this problem and found to be more effective compared with prior similarity measures. However, existing solutions for HPP computation incur significant computational costs, rendering it inefficient especially on large graphs. In this paper, we first identify an inherent drawback of HPP and overcome it by proposing bidirectional HPP (BHPP). Then, we formulate similarity search over bipartite graphs as the problem of approximate BHPP computation, and present an efficient solution Approx-BHPP. Specifically, Approx-BHPP offers rigorous theoretical accuracy guarantees with optimal computational complexity by combining deterministic graph traversal with matrix operations in an optimized and non-trivial way. Moreover, our solution achieves significant gain in practical efficiency due to several carefully-designed optimizations. Extensive experiments, comparing BHPP against 8 existing similarity measures over 7 real bipartite graphs, demonstrate the effectiveness of BHPP on query rewriting and item recommendation. Moreover, Approx-BHPP outperforms baseline solutions often by up to orders of magnitude in terms of computational time on both small and large datasets.
An Adaptive Framework for Generalizing Network Traffic Prediction towards Uncertain Environments
Nov 30, 2023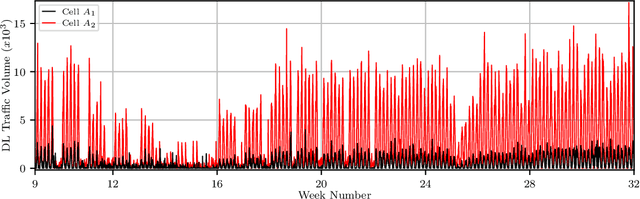
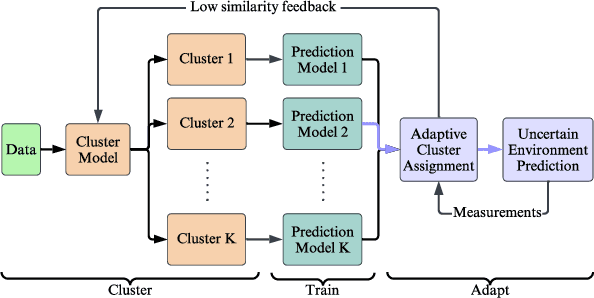
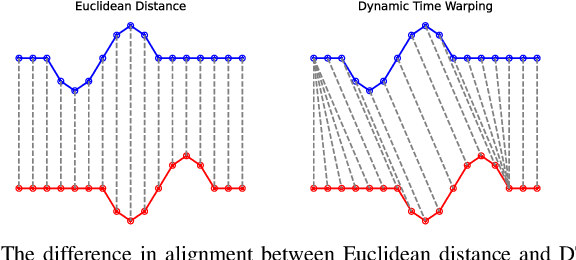
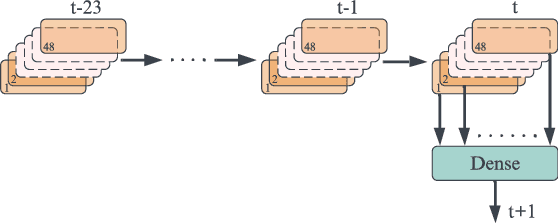
We have developed a new framework using time-series analysis for dynamically assigning mobile network traffic prediction models in previously unseen wireless environments. Our framework selectively employs learned behaviors, outperforming any single model with over a 50% improvement relative to current studies. More importantly, it surpasses traditional approaches without needing prior knowledge of a cell. While this paper focuses on network traffic prediction using our adaptive forecasting framework, this framework can also be applied to other machine learning applications in uncertain environments. The framework begins with unsupervised clustering of time-series data to identify unique trends and seasonal patterns. Subsequently, we apply supervised learning for traffic volume prediction within each cluster. This specialization towards specific traffic behaviors occurs without penalties from spatial and temporal variations. Finally, the framework adaptively assigns trained models to new, previously unseen cells. By analyzing real-time measurements of a cell, our framework intelligently selects the most suitable cluster for that cell at any given time, with cluster assignment dynamically adjusting to spatio-temporal fluctuations.
CoGS: Controllable Gaussian Splatting
Dec 09, 2023Capturing and re-animating the 3D structure of articulated objects present significant barriers. On one hand, methods requiring extensively calibrated multi-view setups are prohibitively complex and resource-intensive, limiting their practical applicability. On the other hand, while single-camera Neural Radiance Fields (NeRFs) offer a more streamlined approach, they have excessive training and rendering costs. 3D Gaussian Splatting would be a suitable alternative but for two reasons. Firstly, existing methods for 3D dynamic Gaussians require synchronized multi-view cameras, and secondly, the lack of controllability in dynamic scenarios. We present CoGS, a method for Controllable Gaussian Splatting, that enables the direct manipulation of scene elements, offering real-time control of dynamic scenes without the prerequisite of pre-computing control signals. We evaluated CoGS using both synthetic and real-world datasets that include dynamic objects that differ in degree of difficulty. In our evaluations, CoGS consistently outperformed existing dynamic and controllable neural representations in terms of visual fidelity.
From "What" to "When" -- a Spiking Neural Network Predicting Rare Events and Time to their Occurrence
Nov 09, 2023In the reinforcement learning (RL) tasks, the ability to predict receiving reward in the near or more distant future means the ability to evaluate the current state as more or less close to the target state (labelled by the reward signal). In the present work, we utilize a spiking neural network (SNN) to predict time to the next target event (reward - in case of RL). In the context of SNNs, events are represented as spikes emitted by network neurons or input nodes. It is assumed that target events are indicated by spikes emitted by a special network input node. Using description of the current state encoded in the form of spikes from the other input nodes, the network should predict approximate time of the next target event. This research paper presents a novel approach to learning the corresponding predictive model by an SNN consisting of leaky integrate-and-fire (LIF) neurons. The proposed method leverages specially designed local synaptic plasticity rules and a novel columnar-layered SNN architecture. Similar to our previous works, this study places a strong emphasis on the hardware-friendliness of the proposed models, ensuring their efficient implementation on modern and future neuroprocessors. The approach proposed was tested on a simple reward prediction task in the context of one of the RL benchmark ATARI games, ping-pong. It was demonstrated that the SNN described in this paper gives superior prediction accuracy in comparison with precise machine learning techniques, such as decision tree algorithms and convolutional neural networks.
Real-time Addressee Estimation: Deployment of a Deep-Learning Model on the iCub Robot
Nov 09, 2023Addressee Estimation is the ability to understand to whom a person is talking, a skill essential for social robots to interact smoothly with humans. In this sense, it is one of the problems that must be tackled to develop effective conversational agents in multi-party and unstructured scenarios. As humans, one of the channels that mainly lead us to such estimation is the non-verbal behavior of speakers: first of all, their gaze and body pose. Inspired by human perceptual skills, in the present work, a deep-learning model for Addressee Estimation relying on these two non-verbal features is designed, trained, and deployed on an iCub robot. The study presents the procedure of such implementation and the performance of the model deployed in real-time human-robot interaction compared to previous tests on the dataset used for the training.
PAC-Bayes Generalization Certificates for Learned Inductive Conformal Prediction
Dec 07, 2023Inductive Conformal Prediction (ICP) provides a practical and effective approach for equipping deep learning models with uncertainty estimates in the form of set-valued predictions which are guaranteed to contain the ground truth with high probability. Despite the appeal of this coverage guarantee, these sets may not be efficient: the size and contents of the prediction sets are not directly controlled, and instead depend on the underlying model and choice of score function. To remedy this, recent work has proposed learning model and score function parameters using data to directly optimize the efficiency of the ICP prediction sets. While appealing, the generalization theory for such an approach is lacking: direct optimization of empirical efficiency may yield prediction sets that are either no longer efficient on test data, or no longer obtain the required coverage on test data. In this work, we use PAC-Bayes theory to obtain generalization bounds on both the coverage and the efficiency of set-valued predictors which can be directly optimized to maximize efficiency while satisfying a desired test coverage. In contrast to prior work, our framework allows us to utilize the entire calibration dataset to learn the parameters of the model and score function, instead of requiring a separate hold-out set for obtaining test-time coverage guarantees. We leverage these theoretical results to provide a practical algorithm for using calibration data to simultaneously fine-tune the parameters of a model and score function while guaranteeing test-time coverage and efficiency of the resulting prediction sets. We evaluate the approach on regression and classification tasks, and outperform baselines calibrated using a Hoeffding bound-based PAC guarantee on ICP, especially in the low-data regime.
Diffence: Fencing Membership Privacy With Diffusion Models
Dec 07, 2023Deep learning models, while achieving remarkable performance across various tasks, are vulnerable to member inference attacks, wherein adversaries identify if a specific data point was part of a model's training set. This susceptibility raises substantial privacy concerns, especially when models are trained on sensitive datasets. Current defense methods often struggle to provide robust protection without hurting model utility, and they often require retraining the model or using extra data. In this work, we introduce a novel defense framework against membership attacks by leveraging generative models. The key intuition of our defense is to remove the differences between member and non-member inputs which can be used to perform membership attacks, by re-generating input samples before feeding them to the target model. Therefore, our defense works \emph{pre-inference}, which is unlike prior defenses that are either training-time (modify the model) or post-inference time (modify the model's output). A unique feature of our defense is that it works on input samples only, without modifying the training or inference phase of the target model. Therefore, it can be cascaded with other defense mechanisms as we demonstrate through experiments. Through extensive experimentation, we show that our approach can serve as a robust plug-n-play defense mechanism, enhancing membership privacy without compromising model utility in both baseline and defended settings. For example, our method enhanced the effectiveness of recent state-of-the-art defenses, reducing attack accuracy by an average of 5.7\% to 12.4\% across three datasets, without any impact on the model's accuracy. By integrating our method with prior defenses, we achieve new state-of-the-art performance in the privacy-utility trade-off.
Performative Time-Series Forecasting
Oct 09, 2023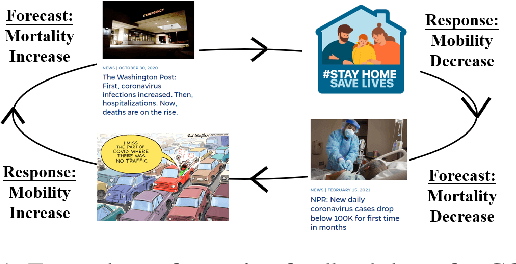
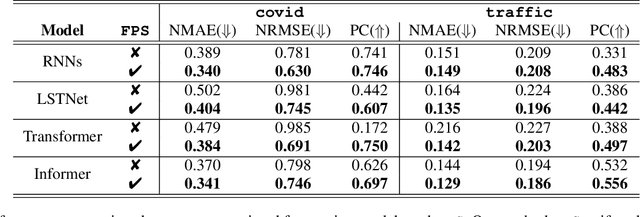
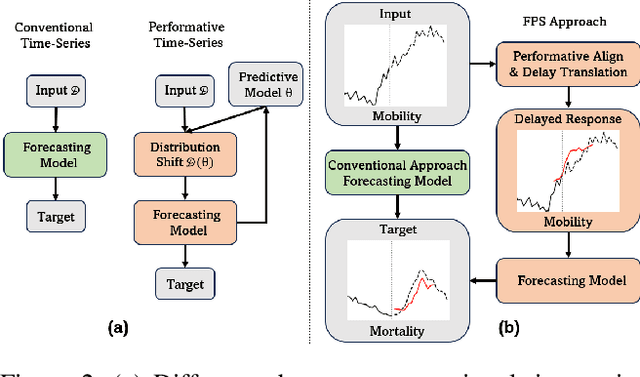
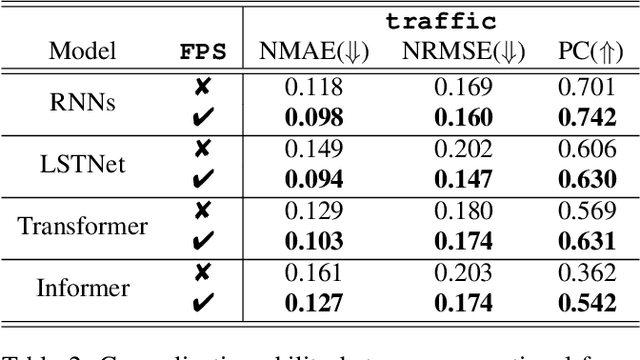
Time-series forecasting is a critical challenge in various domains and has witnessed substantial progress in recent years. Many real-life scenarios, such as public health, economics, and social applications, involve feedback loops where predictions can influence the predicted outcome, subsequently altering the target variable's distribution. This phenomenon, known as performativity, introduces the potential for 'self-negating' or 'self-fulfilling' predictions. Despite extensive studies in classification problems across domains, performativity remains largely unexplored in the context of time-series forecasting from a machine-learning perspective. In this paper, we formalize performative time-series forecasting (PeTS), addressing the challenge of accurate predictions when performativity-induced distribution shifts are possible. We propose a novel approach, Feature Performative-Shifting (FPS), which leverages the concept of delayed response to anticipate distribution shifts and subsequently predicts targets accordingly. We provide theoretical insights suggesting that FPS can potentially lead to reduced generalization error. We conduct comprehensive experiments using multiple time-series models on COVID-19 and traffic forecasting tasks. The results demonstrate that FPS consistently outperforms conventional time-series forecasting methods, highlighting its efficacy in handling performativity-induced challenges.