 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simulating the Air Quality Impact of Prescribed Fires Using a Graph Neural Network-Based PM$_{2.5}$ Emissions Forecasting System
Dec 07, 2023
The increasing size and severity of wildfires across western North America have generated dangerous levels of PM$_{2.5}$ pollution in recent years. In a warming climate, expanding the use of prescribed fires is widely considered to be the most robust fire mitigation strategy. However, reliably forecasting the potential air quality impact from these prescribed fires, a critical ingredient in determining the fires' location and time, at hourly to daily time scales remains a challenging problem. This paper proposes a novel integration of prescribed fire simulation with a spatio-temporal graph neural network-based PM$_{2.5}$ forecasting model. The experiments in this work focus on determining the optimal time for implementing prescribed fires in California as well as quantifying the potential air quality trade-offs involved in conducting more prescribed fires outside the fire season.
Auralization based on multi-perspective ambisonic room impulse responses
Dec 06, 2023Most often, virtual acoustic rendering employs real-time updated room acoustic simulations to accomplish auralization for a variable listener perspective. As an alternative, we propose and test a technique to interpolate room impulse responses, specifically Ambisonic room impulse responses (ARIRs) available at a grid of spatially distributed receiver perspectives, measured or simulated in a desired acoustic environment. In particular, we extrapolate a triplet of neighboring ARIRs to the variable listener perspective, preceding their linear interpolation. The extrapolation is achieved by decomposing each ARIR into localized sound events and re-assigning their direction, time, and level to what could be observed at the listener perspective, with as much temporal, directional, and perspective context as possible. We propose to undertake this decomposition in two levels: Peaks in the early ARIRs are decomposed into jointly localized sound events, based on time differences of arrival observed in either an ARIR triplet, or all ARIRs observing the direct sound. Sound events that could not be jointly localized are treated as residuals whose less precise localization utilizes direction-of-arrival detection and the estimated time of arrival. For the interpolated rendering, suitable parameter settings are found by evaluating the proposed method in a listening experiment, using both measured and simulated ARIR data sets, under static and time-varying conditions.
* 18 pages, published in Acta Acustica (Open Access), datasets are available via https://paperswithcode.com/dataset/cube-b-format-ambisonic-rir-dataset and https://paperswithcode.com/dataset/variable-perspective-arir-rendering-listening
CaVE: A Cone-Aligned Approach for Fast Predict-then-optimize with Binary Linear Programs
Dec 12, 2023The end-to-end predict-then-optimize framework, also known as decision-focused learning, has gained popularity for its ability to integrate optimization into the training procedure of machine learning models that predict the unknown cost (objective function) coefficients of optimization problems from contextual instance information. Naturally, most of the problems of interest in this space can be cast as integer linear programs. In this work, we focus on binary linear programs (BLPs) and propose a new end-to-end training method for predict-then-optimize. Our method, Cone-aligned Vector Estimation (CaVE), aligns the predicted cost vectors with the cone corresponding to the true optimal solution of a training instance. When the predicted cost vector lies inside the cone, the optimal solution to the linear relaxation of the binary problem is optimal w.r.t. to the true cost vector. Not only does this alignment produce decision-aware learning models, but it also dramatically reduces training time as it circumvents the need to solve BLPs to compute a loss function with its gradients. Experiments across multiple datasets show that our method exhibits a favorable trade-off between training time and solution quality, particularly with large-scale optimization problems such as vehicle routing, a hard BLP that has yet to benefit from predict-then-optimize methods in the literature due to its difficulty.
Unleashing the Power of CNN and Transformer for Balanced RGB-Event Video Recognition
Dec 18, 2023Pattern recognition based on RGB-Event data is a newly arising research topic and previous works usually learn their features using CNN or Transformer. As we know, CNN captures the local features well and the cascaded self-attention mechanisms are good at extracting the long-range global relations. It is intuitive to combine them for high-performance RGB-Event based video recognition, however, existing works fail to achieve a good balance between the accuracy and model parameters, as shown in Fig.~\ref{firstimage}. In this work, we propose a novel RGB-Event based recognition framework termed TSCFormer, which is a relatively lightweight CNN-Transformer model. Specifically, we mainly adopt the CNN as the backbone network to first encode both RGB and Event data. Meanwhile, we initialize global tokens as the input and fuse them with RGB and Event features using the BridgeFormer module. It captures the global long-range relations well between both modalities and maintains the simplicity of the whole model architecture at the same time. The enhanced features will be projected and fused into the RGB and Event CNN blocks, respectively, in an interactive manner using F2E and F2V modules. Similar operations are conducted for other CNN blocks to achieve adaptive fusion and local-global feature enhancement under different resolutions. Finally, we concatenate these three features and feed them into the classification head for pattern recognition. Extensive experiments on two large-scale RGB-Event benchmark datasets (PokerEvent and HARDVS) fully validated the effectiveness of our proposed TSCFormer. The source code and pre-trained models will be released at https://github.com/Event-AHU/TSCFormer.
MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training
Dec 18, 2023In the acceleration of deep neural network training, the GPU has become the mainstream platform. GPUs face substantial challenges on GNNs, such as workload imbalance and memory access irregularities, leading to underutilized hardware. Existing solutions such as PyG, DGL with cuSPARSE, and GNNAdvisor frameworks partially address these challenges but memory traffic is still significant. We argue that drastic performance improvements can only be achieved by the vertical optimization of algorithm and system innovations, rather than treating the speedup optimization as an "after-thought" (i.e., (i) given a GNN algorithm, designing an accelerator, or (ii) given hardware, mainly optimizing the GNN algorithm). In this paper, we present MaxK-GNN, an advanced high-performance GPU training system integrating algorithm and system innovation. (i) We introduce the MaxK nonlinearity and provide a theoretical analysis of MaxK nonlinearity as a universal approximator, and present the Compressed Balanced Sparse Row (CBSR) format, designed to store the data and index of the feature matrix after nonlinearity; (ii) We design a coalescing enhanced forward computation with row-wise product-based SpGEMM Kernel using CBSR for input feature matrix fetching and strategic placement of a sparse output accumulation buffer in shared memory; (iii) We develop an optimized backward computation with outer product-based and SSpMM Kernel. We conduct extensive evaluations of MaxK-GNN and report the end-to-end system run-time. Experiments show that MaxK-GNN system could approach the theoretical speedup limit according to Amdahl's law. We achieve comparable accuracy to SOTA GNNs, but at a significantly increased speed: 3.22/4.24 times speedup (vs. theoretical limits, 5.52/7.27 times) on Reddit compared to DGL and GNNAdvisor implementations.
Quantitative perfusion maps using a novelty spatiotemporal convolutional neural network
Dec 08, 2023Dynamic susceptibility contrast magnetic resonance imaging (DSC-MRI) is widely used to evaluate acute ischemic stroke to distinguish salvageable tissue and infarct core. For this purpose, traditional methods employ deconvolution techniques, like singular value decomposition, which are known to be vulnerable to noise, potentially distorting the derived perfusion parameters. However, deep learning technology could leverage it, which can accurately estimate clinical perfusion parameters compared to traditional clinical approaches. Therefore, this study presents a perfusion parameters estimation network that considers spatial and temporal information, the Spatiotemporal Network (ST-Net), for the first time. The proposed network comprises a designed physical loss function to enhance model performance further. The results indicate that the network can accurately estimate perfusion parameters, including cerebral blood volume (CBV), cerebral blood flow (CBF), and time to maximum of the residual function (Tmax). The structural similarity index (SSIM) mean values for CBV, CBF, and Tmax parameters were 0.952, 0.943, and 0.863, respectively. The DICE score for the hypo-perfused region reached 0.859, demonstrating high consistency. The proposed model also maintains time efficiency, closely approaching the performance of commercial gold-standard software.
Closing the Gap: Achieving Better Accuracy-Robustness Tradeoffs Against Query-Based Attacks
Dec 15, 2023Although promising, existing defenses against query-based attacks share a common limitation: they offer increased robustness against attacks at the price of a considerable accuracy drop on clean samples. In this work, we show how to efficiently establish, at test-time, a solid tradeoff between robustness and accuracy when mitigating query-based attacks. Given that these attacks necessarily explore low-confidence regions, our insight is that activating dedicated defenses, such as RND (Qin et al., NeuRIPS 2021) and Random Image Transformations (Xie et al., ICLR 2018), only for low-confidence inputs is sufficient to prevent them. Our approach is independent of training and supported by theory. We verify the effectiveness of our approach for various existing defenses by conducting extensive experiments on CIFAR-10, CIFAR-100, and ImageNet. Our results confirm that our proposal can indeed enhance these defenses by providing better tradeoffs between robustness and accuracy when compared to state-of-the-art approaches while being completely training-free.
Verification-Friendly Deep Neural Networks
Dec 15, 2023Machine learning techniques often lack formal correctness guarantees. This is evidenced by the widespread adversarial examples that plague most deep-learning applications. This resulted in several research efforts that aim at verifying deep neural networks, with a particular focus on safety-critical applications. However, formal verification techniques still face major scalability and precision challenges when dealing with the complexity of such networks. The over-approximation introduced during the formal verification process to tackle the scalability challenge often results in inconclusive analysis. To address this challenge, we propose a novel framework to generate Verification-friendly Neural Networks (VNNs). We present a post-training optimization framework to achieve a balance between preserving prediction performance and robustness in the resulting networks. Our proposed framework proves to result in networks that are comparable to the original ones in terms of prediction performance, while amenable to verification. This essentially enables us to establish robustness for more VNNs than their deep neural network counterparts, in a more time-efficient manner.
Multi-stage Learning for Radar Pulse Activity Segmentation
Dec 15, 2023Radio signal recognition is a crucial function in electronic warfare. Precise identification and localisation of radar pulse activities are required by electronic warfare systems to produce effective countermeasures. Despite the importance of these tasks, deep learning-based radar pulse activity recognition methods have remained largely underexplored. While deep learning for radar modulation recognition has been explored previously, classification tasks are generally limited to short and non-interleaved IQ signals, limiting their applicability to military applications. To address this gap, we introduce an end-to-end multi-stage learning approach to detect and localise pulse activities of interleaved radar signals across an extended time horizon. We propose a simple, yet highly effective multi-stage architecture for incrementally predicting fine-grained segmentation masks that localise radar pulse activities across multiple channels. We demonstrate the performance of our approach against several reference models on a novel radar dataset, while also providing a first-of-its-kind benchmark for radar pulse activity segmentation.
Emotion-Aware Music Recommendation System: Enhancing User Experience Through Real-Time Emotional Context
Nov 17, 2023
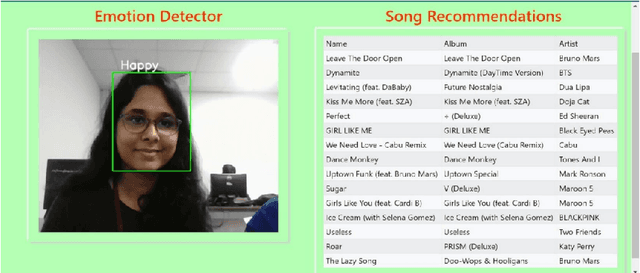

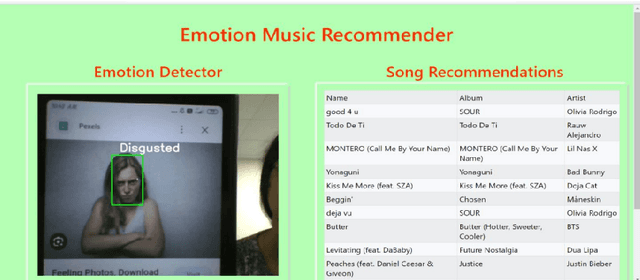
This study addresses the deficiency in conventional music recommendation systems by focusing on the vital role of emotions in shaping users music choices. These systems often disregard the emotional context, relying predominantly on past listening behavior and failing to consider the dynamic and evolving nature of users emotional preferences. This gap leads to several limitations. Users may receive recommendations that do not match their current mood, which diminishes the quality of their music experience. Furthermore, without accounting for emotions, the systems might overlook undiscovered or lesser-known songs that have a profound emotional impact on users. To combat these limitations, this research introduces an AI model that incorporates emotional context into the song recommendation process. By accurately detecting users real-time emotions, the model can generate personalized song recommendations that align with the users emotional state. This approach aims to enhance the user experience by offering music that resonates with their current mood, elicits the desired emotions, and creates a more immersive and meaningful listening experience. By considering emotional context in the song recommendation process, the proposed model offers an opportunity for a more personalized and emotionally resonant musical journey.