 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analytical Verification of Deep Neural Network Performance for Time-Synchronized Distribution System State Estimation
Nov 12, 2023
Recently, we demonstrated success of a time-synchronized state estimator using deep neural networks (DNNs) for real-time unobservable distribution systems. In this letter, we provide analytical bounds on the performance of that state estimator as a function of perturbations in the input measurements. It has already been shown that evaluating performance based on only the test dataset might not effectively indicate a trained DNN's ability to handle input perturbations. As such, we analytically verify robustness and trustworthiness of DNNs to input perturbations by treating them as mixed-integer linear programming (MILP) problems. The ability of batch normalization in addressing the scalability limitations of the MILP formulation is also highlighted. The framework is validated by performing time-synchronized distribution system state estimation for a modified IEEE 34-node system and a real-world large distribution system, both of which are incompletely observed by micro-phasor measurement units.
Path-aware optimistic optimization for a mobile robot
Dec 18, 2023We consider problems in which a mobile robot samples an unknown function defined over its operating space, so as to find a global optimum of this function. The path traveled by the robot matters, since it influences energy and time requirements. We consider a branch-and-bound algorithm called deterministic optimistic optimization, and extend it to the path-aware setting, obtaining path-aware optimistic optimization (OOPA). In this new algorithm, the robot decides how to move next via an optimal control problem that maximizes the long-term impact of the robot trajectory on lowering the upper bound, weighted by bound and function values to focus the search on the optima. An online version of value iteration is used to solve an approximate version of this optimal control problem. OOPA is evaluated in extensive experiments in two dimensions, where it does better than path-unaware and local-optimization baselines.
Leveraging Hamilton-Jacobi PDEs with time-dependent Hamiltonians for continual scientific machine learning
Nov 13, 2023We address two major challenges in scientific machine learning (SciML): interpretability and computational efficiency. We increase the interpretability of certain learning processes by establishing a new theoretical connection between optimization problems arising from SciML and a generalized Hopf formula, which represents the viscosity solution to a Hamilton-Jacobi partial differential equation (HJ PDE) with time-dependent Hamiltonian. Namely, we show that when we solve certain regularized learning problems with integral-type losses, we actually solve an optimal control problem and its associated HJ PDE with time-dependent Hamiltonian. This connection allows us to reinterpret incremental updates to learned models as the evolution of an associated HJ PDE and optimal control problem in time, where all of the previous information is intrinsically encoded in the solution to the HJ PDE. As a result, existing HJ PDE solvers and optimal control algorithms can be reused to design new efficient training approaches for SciML that naturally coincide with the continual learning framework, while avoiding catastrophic forgetting. As a first exploration of this connection, we consider the special case of linear regression and leverage our connection to develop a new Riccati-based methodology for solving these learning problems that is amenable to continual learning applications. We also provide some corresponding numerical examples that demonstrate the potential computational and memory advantages our Riccati-based approach can provide.
Resilient Control of Networked Microgrids using Vertical Federated Reinforcement Learning: Designs and Real-Time Test-Bed Validations
Nov 21, 2023Improving system-level resiliency of networked microgrids is an important aspect with increased population of inverter-based resources (IBRs). This paper (1) presents resilient control design in presence of adversarial cyber-events, and proposes a novel federated reinforcement learning (Fed-RL) approach to tackle (a) model complexities, unknown dynamical behaviors of IBR devices, (b) privacy issues regarding data sharing in multi-party-owned networked grids, and (2) transfers learned controls from simulation to hardware-in-the-loop test-bed, thereby bridging the gap between simulation and real world. With these multi-prong objectives, first, we formulate a reinforcement learning (RL) training setup generating episodic trajectories with adversaries (attack signal) injected at the primary controllers of the grid forming (GFM) inverters where RL agents (or controllers) are being trained to mitigate the injected attacks. For networked microgrids, the horizontal Fed-RL method involving distinct independent environments is not appropriate, leading us to develop vertical variant Federated Soft Actor-Critic (FedSAC) algorithm to grasp the interconnected dynamics of networked microgrid. Next, utilizing OpenAI Gym interface, we built a custom simulation set-up in GridLAB-D/HELICS co-simulation platform, named Resilient RL Co-simulation (ResRLCoSIM), to train the RL agents with IEEE 123-bus benchmark test systems comprising 3 interconnected microgrids. Finally, the learned policies in simulation world are transferred to the real-time hardware-in-the-loop test-bed set-up developed using high-fidelity Hypersim platform. Experiments show that the simulator-trained RL controllers produce convincing results with the real-time test-bed set-up, validating the minimization of sim-to-real gap.
Fast Cell Library Characterization for Design Technology Co-Optimization Based on Graph Neural Networks
Dec 20, 2023Design technology co-optimization (DTCO) plays a critical role in achieving optimal power, performance, and area (PPA) for advanced semiconductor process development. Cell library characterization is essential in DTCO flow, but traditional methods are time-consuming and costly. To overcome these challenges, we propose a graph neural network (GNN)-based machine learning model for rapid and accurate cell library characterization. Our model incorporates cell structures and demonstrates high prediction accuracy across various process-voltage-temperature (PVT) corners and technology parameters. Validation with 512 unseen technology corners and over one million test data points shows accurate predictions of delay, power, and input pin capacitance for 33 types of cells, with a mean absolute percentage error (MAPE) $\le$ 0.95% and a speed-up of 100X compared with SPICE simulations. Additionally, we investigate system-level metrics such as worst negative slack (WNS), leakage power, and dynamic power using predictions obtained from the GNN-based model on unseen corners. Our model achieves precise predictions, with absolute error $\le$3.0 ps for WNS, percentage errors $\le$0.60% for leakage power, and $\le$0.99% for dynamic power, when compared to golden reference. With the developed model, we further proposed a fine-grained drive strength interpolation methodology to enhance PPA for small-to-medium-scale designs, resulting in an approximate 1-3% improvement.
Generate E-commerce Product Background by Integrating Category Commonality and Personalized Style
Dec 20, 2023The state-of-the-art methods for e-commerce product background generation suffer from the inefficiency of designing product-wise prompts when scaling up the production, as well as the ineffectiveness of describing fine-grained styles when customizing personalized backgrounds for some specific brands. To address these obstacles, we integrate the category commonality and personalized style into diffusion models. Concretely, we propose a Category-Wise Generator to enable large-scale background generation for the first time. A unique identifier in the prompt is assigned to each category, whose attention is located on the background by a mask-guided cross attention layer to learn the category-wise style. Furthermore, for products with specific and fine-grained requirements in layout, elements, etc, a Personality-Wise Generator is devised to learn such personalized style directly from a reference image to resolve textual ambiguities, and is trained in a self-supervised manner for more efficient training data usage. To advance research in this field, the first large-scale e-commerce product background generation dataset BG60k is constructed, which covers more than 60k product images from over 2k categories. Experiments demonstrate that our method could generate high-quality backgrounds for different categories, and maintain the personalized background style of reference images. The link to BG60k and codes will be available soon.
Bayesian Metaplasticity from Synaptic Uncertainty
Dec 15, 2023Catastrophic forgetting remains a challenge for neural networks, especially in lifelong learning scenarios. In this study, we introduce MEtaplasticity from Synaptic Uncertainty (MESU), inspired by metaplasticity and Bayesian inference principles. MESU harnesses synaptic uncertainty to retain information over time, with its update rule closely approximating the diagonal Newton's method for synaptic updates. Through continual learning experiments on permuted MNIST tasks, we demonstrate MESU's remarkable capability to maintain learning performance across 100 tasks without the need of explicit task boundaries.
Constant-time Motion Planning with Anytime Refinement for Manipulation
Nov 01, 2023Robotic manipulators are essential for future autonomous systems, yet limited trust in their autonomy has confined them to rigid, task-specific systems. The intricate configuration space of manipulators, coupled with the challenges of obstacle avoidance and constraint satisfaction, often makes motion planning the bottleneck for achieving reliable and adaptable autonomy. Recently, a class of constant-time motion planners (CTMP) was introduced. These planners employ a preprocessing phase to compute data structures that enable online planning provably guarantee the ability to generate motion plans, potentially sub-optimal, within a user defined time bound. This framework has been demonstrated to be effective in a number of time-critical tasks. However, robotic systems often have more time allotted for planning than the online portion of CTMP requires, time that can be used to improve the solution. To this end, we propose an anytime refinement approach that works in combination with CTMP algorithms. Our proposed framework, as it operates as a constant time algorithm, rapidly generates an initial solution within a user-defined time threshold. Furthermore, functioning as an anytime algorithm, it iteratively refines the solution's quality within the allocated time budget. This enables our approach to strike a balance between guaranteed fast plan generation and the pursuit of optimization over time. We support our approach by elucidating its analytical properties, showing the convergence of the anytime component towards optimal solutions. Additionally, we provide empirical validation through simulation and real-world demonstrations on a 6 degree-of-freedom robot manipulator, applied to an assembly domain.
Using deep neural networks to improve the precision of fast-sampled particle timing detectors
Dec 10, 2023Measurements from particle timing detectors are often affected by the time walk effect caused by statistical fluctuations in the charge deposited by passing particles. The constant fraction discriminator (CFD) algorithm is frequently used to mitigate this effect both in test setups and in running experiments, such as the CMS-PPS system at the CERN's LHC. The CFD is simple and effective but does not leverage all voltage samples in a time series. Its performance could be enhanced with deep neural networks, which are commonly used for time series analysis, including computing the particle arrival time. We evaluated various neural network architectures using data acquired at the test beam facility in the DESY-II synchrotron, where a precise MCP (MicroChannel Plate) detector was installed in addition to PPS diamond timing detectors. MCP measurements were used as a reference to train the networks and compare the results with the standard CFD method. Ultimately, we improved the timing precision by 8% to 23%, depending on the detector's readout channel. The best results were obtained using a UNet-based model, which outperformed classical convolutional networks and the multilayer perceptron.
LoRA-Enhanced Distillation on Guided Diffusion Models
Dec 12, 2023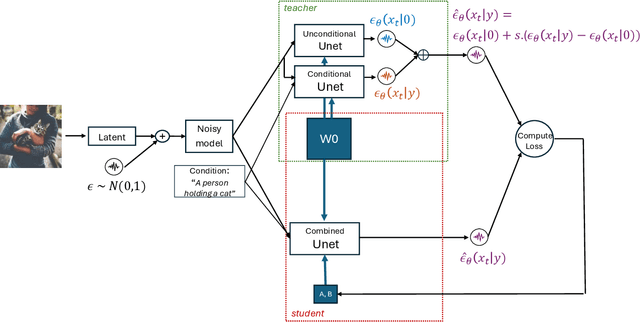


Diffusion models, such as Stable Diffusion (SD), offer the ability to generate high-resolution images with diverse features, but they come at a significant computational and memory cost. In classifier-free guided diffusion models, prolonged inference times are attributed to the necessity of computing two separate diffusion models at each denoising step. Recent work has shown promise in improving inference time through distillation techniques, teaching the model to perform similar denoising steps with reduced computations. However, the application of distillation introduces additional memory overhead to these already resource-intensive diffusion models, making it less practical. To address these challenges, our research explores a novel approach that combines Low-Rank Adaptation (LoRA) with model distillation to efficiently compress diffusion models. This approach not only reduces inference time but also mitigates memory overhead, and notably decreases memory consumption even before applying distillation. The results are remarkable, featuring a significant reduction in inference time due to the distillation process and a substantial 50% reduction in memory consumption. Our examination of the generated images underscores that the incorporation of LoRA-enhanced distillation maintains image quality and alignment with the provided prompts. In summary, while conventional distillation tends to increase memory consumption, LoRA-enhanced distillation offers optimization without any trade-offs or compromises in quality.