 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Copula-Based Survival Analysis for Dependent Censoring with Identifiability Guarantees
Dec 27, 2023
Censoring is the central problem in survival analysis where either the time-to-event (for instance, death), or the time-tocensoring (such as loss of follow-up) is observed for each sample. The majority of existing machine learning-based survival analysis methods assume that survival is conditionally independent of censoring given a set of covariates; an assumption that cannot be verified since only marginal distributions is available from the data. The existence of dependent censoring, along with the inherent bias in current estimators has been demonstrated in a variety of applications, accentuating the need for a more nuanced approach. However, existing methods that adjust for dependent censoring require practitioners to specify the ground truth copula. This requirement poses a significant challenge for practical applications, as model misspecification can lead to substantial bias. In this work, we propose a flexible deep learning-based survival analysis method that simultaneously accommodate for dependent censoring and eliminates the requirement for specifying the ground truth copula. We theoretically prove the identifiability of our model under a broad family of copulas and survival distributions. Experiments results from a wide range of datasets demonstrate that our approach successfully discerns the underlying dependency structure and significantly reduces survival estimation bias when compared to existing methods.
Synthetic Data Applications in Finance
Dec 29, 2023Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Interference Management in 5G and Beyond Networks
Jan 03, 2024During the last decade, wireless data services have had an incredible impact on people's lives in ways we could never have imagined. The number of mobile devices has increased exponentially and data traffic has almost doubled every year. Undoubtedly, the rate of growth will continue to be rapid with the explosive increase in demands for data rates, latency, massive connectivity, network reliability, and energy efficiency. In order to manage this level of growth and meet these requirements, the fifth-generation (5G) mobile communications network is envisioned as a revolutionary advancement combining various improvements to previous mobile generation networks and new technologies, including the use of millimeter wavebands (mm-wave), massive multiple-input multipleoutput (mMIMO) multi-beam antennas, network densification, dynamic Time Division Duplex (TDD) transmission, and new waveforms with mixed numerologies. New revolutionary features including terahertz (THz) communications and the integration of Non-Terrestrial Networks (NTN) can further improve the performance and signal quality for future 6G networks. However, despite the inevitable benefits of all these key technologies, the heterogeneous and ultra-flexible structure of the 5G and beyond network brings non-orthogonality into the system and generates significant interference that needs to be handled carefully. Therefore, it is essential to design effective interference management schemes to mitigate severe and sometimes unpredictable interference in mobile networks. In this paper, we provide a comprehensive review of interference management in 5G and Beyond networks and discuss its future evolution. We start with a unified classification and a detailed explanation of the different types of interference and continue by presenting our taxonomy of existing interference management approaches. Then, after explaining interference measurement reports and signaling, we provide for each type of interference identified, an in-depth literature review and technical discussion of appropriate management schemes. We finish by discussing the main interference challenges that will be encountered in future 6G networks and by presenting insights on the suggested new interference management approaches, including useful guidelines for an AI-based solution. This review will provide a first-hand guide to the industry in determining the most relevant technology for interference management, and will also allow for consideration of future challenges and research directions.
FlashVideo: A Framework for Swift Inference in Text-to-Video Generation
Dec 30, 2023In the evolving field of machine learning, video generation has witnessed significant advancements with autoregressive-based transformer models and diffusion models, known for synthesizing dynamic and realistic scenes. However, these models often face challenges with prolonged inference times, even for generating short video clips such as GIFs. This paper introduces FlashVideo, a novel framework tailored for swift Text-to-Video generation. FlashVideo represents the first successful adaptation of the RetNet architecture for video generation, bringing a unique approach to the field. Leveraging the RetNet-based architecture, FlashVideo reduces the time complexity of inference from $\mathcal{O}(L^2)$ to $\mathcal{O}(L)$ for a sequence of length $L$, significantly accelerating inference speed. Additionally, we adopt a redundant-free frame interpolation method, enhancing the efficiency of frame interpolation. Our comprehensive experiments demonstrate that FlashVideo achieves a $\times9.17$ efficiency improvement over a traditional autoregressive-based transformer model, and its inference speed is of the same order of magnitude as that of BERT-based transformer models.
L3Cube-MahaSocialNER: A Social Media based Marathi NER Dataset and BERT models
Dec 30, 2023This work introduces the L3Cube-MahaSocialNER dataset, the first and largest social media dataset specifically designed for Named Entity Recognition (NER) in the Marathi language. The dataset comprises 18,000 manually labeled sentences covering eight entity classes, addressing challenges posed by social media data, including non-standard language and informal idioms. Deep learning models, including CNN, LSTM, BiLSTM, and Transformer models, are evaluated on the individual dataset with IOB and non-IOB notations. The results demonstrate the effectiveness of these models in accurately recognizing named entities in Marathi informal text. The L3Cube-MahaSocialNER dataset offers user-centric information extraction and supports real-time applications, providing a valuable resource for public opinion analysis, news, and marketing on social media platforms. We also show that the zero-shot results of the regular NER model are poor on the social NER test set thus highlighting the need for more social NER datasets. The datasets and models are publicly available at https://github.com/l3cube-pune/MarathiNLP
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Dec 26, 2023
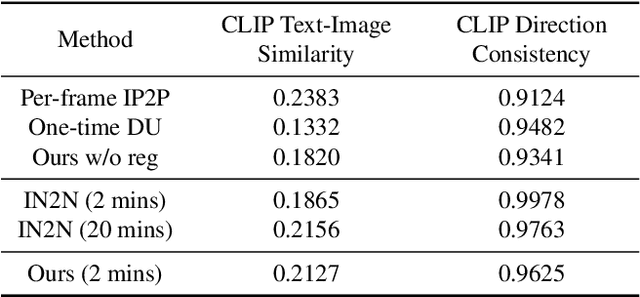
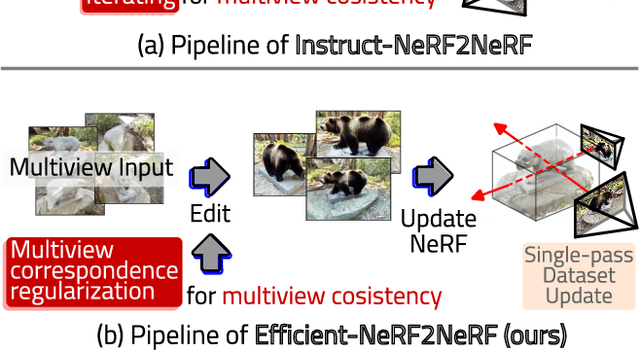
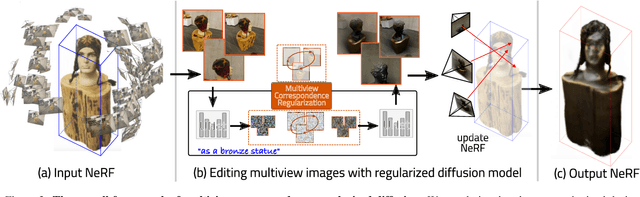
The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
Association rule mining with earthquake data collected from Turkiye region
Dec 26, 2023Earthquakes are evaluated among the most destructive disasters for human beings, as also experienced for Turkiye region. Data science has the property of discovering hidden patterns in case a sufficient volume of data is supplied. Time dependency of events, specifically being defined by co-occurrence in a specific time window, may be handled as an associate rule mining task such as a market-basket analysis application. In this regard, we assumed each day's seismic activity as a single basket of events, leading to discovering the association patterns between these events. Consequently, this study presents the most prominent association rules for the earthquakes recorded in Turkiye region in the last 5 years, each year presented separately. Results indicate statistical inference with events recorded from regions of various distances, which could be further verified with geologic evidence from the field. As a result, we believe that the current study may form a statistical basis for the future works with the aid of machine learning algorithm performed for associate rule mining.
Object Location Prediction in Real-time using LSTM Neural Network and Polynomial Regression
Nov 23, 2023This paper details the design and implementation of a system for predicting and interpolating object location coordinates. Our solution is based on processing inertial measurements and global positioning system data through a Long Short-Term Memory (LSTM) neural network and polynomial regression. LSTM is a type of recurrent neural network (RNN) particularly suited for processing data sequences and avoiding the long-term dependency problem. We employed data from real-world vehicles and the global positioning system (GPS) sensors. A critical pre-processing step was developed to address varying sensor frequencies and inconsistent GPS time steps and dropouts. The LSTM-based system's performance was compared with the Kalman Filter. The system was tuned to work in real-time with low latency and high precision. We tested our system on roads under various driving conditions, including acceleration, turns, deceleration, and straight paths. We tested our proposed solution's accuracy and inference time and showed that it could perform in real-time. Our LSTM-based system yielded an average error of 0.11 meters with an inference time of 2 ms. This represents a 76\% reduction in error compared to the traditional Kalman filter method, which has an average error of 0.46 meters with a similar inference time to the LSTM-based system.
GLIMPSE: Generalized Local Imaging with MLPs
Jan 01, 2024Deep learning is the current de facto state of the art in tomographic imaging. A common approach is to feed the result of a simple inversion, for example the backprojection, to a convolutional neural network (CNN) which then computes the reconstruction. Despite strong results on 'in-distribution' test data similar to the training data, backprojection from sparse-view data delocalizes singularities, so these approaches require a large receptive field to perform well. As a consequence, they overfit to certain global structures which leads to poor generalization on out-of-distribution (OOD) samples. Moreover, their memory complexity and training time scale unfavorably with image resolution, making them impractical for application at realistic clinical resolutions, especially in 3D: a standard U-Net requires a substantial 140GB of memory and 2600 seconds per epoch on a research-grade GPU when training on 1024x1024 images. In this paper, we introduce GLIMPSE, a local processing neural network for computed tomography which reconstructs a pixel value by feeding only the measurements associated with the neighborhood of the pixel to a simple MLP. While achieving comparable or better performance with successful CNNs like the U-Net on in-distribution test data, GLIMPSE significantly outperforms them on OOD samples while maintaining a memory footprint almost independent of image resolution; 5GB memory suffices to train on 1024x1024 images. Further, we built GLIMPSE to be fully differentiable, which enables feats such as recovery of accurate projection angles if they are out of calibration.
Predicting Infant Brain Connectivity with Federated Multi-Trajectory GNNs using Scarce Data
Jan 01, 2024The understanding of the convoluted evolution of infant brain networks during the first postnatal year is pivotal for identifying the dynamics of early brain connectivity development. Existing deep learning solutions suffer from three major limitations. First, they cannot generalize to multi-trajectory prediction tasks, where each graph trajectory corresponds to a particular imaging modality or connectivity type (e.g., T1-w MRI). Second, existing models require extensive training datasets to achieve satisfactory performance which are often challenging to obtain. Third, they do not efficiently utilize incomplete time series data. To address these limitations, we introduce FedGmTE-Net++, a federated graph-based multi-trajectory evolution network. Using the power of federation, we aggregate local learnings among diverse hospitals with limited datasets. As a result, we enhance the performance of each hospital's local generative model, while preserving data privacy. The three key innovations of FedGmTE-Net++ are: (i) presenting the first federated learning framework specifically designed for brain multi-trajectory evolution prediction in a data-scarce environment, (ii) incorporating an auxiliary regularizer in the local objective function to exploit all the longitudinal brain connectivity within the evolution trajectory and maximize data utilization, (iii) introducing a two-step imputation process, comprising a preliminary KNN-based precompletion followed by an imputation refinement step that employs regressors to improve similarity scores and refine imputations. Our comprehensive experimental results showed the outperformance of FedGmTE-Net++ in brain multi-trajectory prediction from a single baseline graph in comparison with benchmark methods.