 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estudo comparativo de meta-heurísticas para problemas de colorações de grafos
Dec 18, 2019
A classic graph coloring problem is to assign colors to vertices of any graph so that distinct colors are assigned to adjacent vertices. Optimal graph coloring colors a graph with a minimum number of colors, which is its chromatic number. Finding out the chromatic number is a combinatorial optimization problem proven to be computationally intractable, which implies that no algorithm that computes large instances of the problem in a reasonable time is known. For this reason, approximate methods and metaheuristics form a set of techniques that do not guarantee optimality but obtain good solutions in a reasonable time. This paper reports a comparative study of the Hill-Climbing, Simulated Annealing, Tabu Search, and Iterated Local Search metaheuristics for the classic graph coloring problem considering its time efficiency for processing the DSJC125 and DSJC250 instances of the DIMACS benchmark.
Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
Dec 18, 2019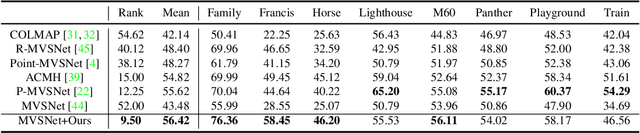
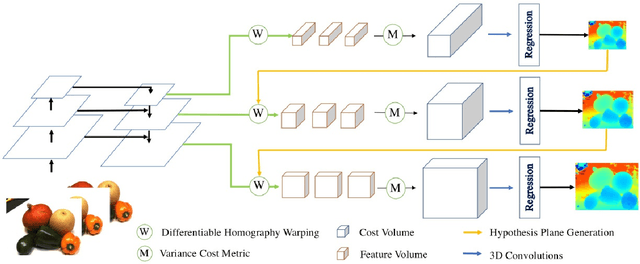
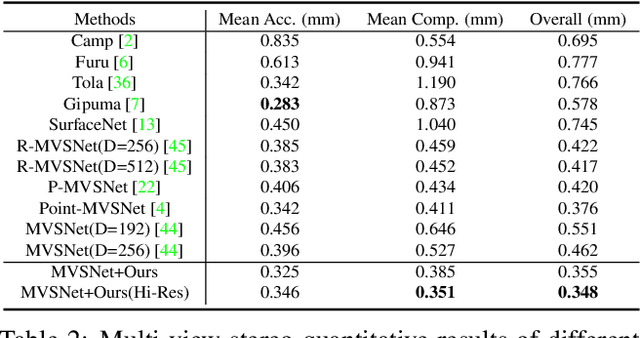
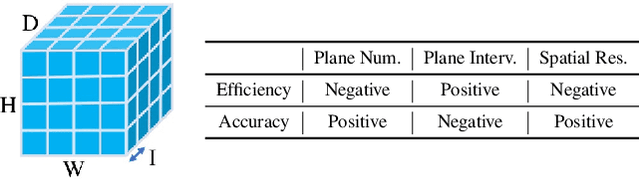
The deep multi-view stereo (MVS) and stereo matching approaches generally construct 3D cost volumes to regularize and regress the output depth or disparity. These methods are limited when high-resolution outputs are needed since the memory and time costs grow cubically as the volume resolution increases. In this paper, we propose a both memory and time efficient cost volume formulation that is complementary to existing multi-view stereo and stereo matching approaches based on 3D cost volumes. First, the proposed cost volume is built upon a standard feature pyramid encoding geometry and context at gradually finer scales. Then, we can narrow the depth (or disparity) range of each stage by the depth (or disparity) map from the previous stage. With gradually higher cost volume resolution and adaptive adjustment of depth (or disparity) intervals, the output is recovered in a coarser to fine manner. We apply the cascade cost volume to the representative MVS-Net, and obtain a 23.1% improvement on DTU benchmark (1st place), with 50.6% and 74.2% reduction in GPU memory and run-time. It is also the state-of-the-art learning-based method on Tanks and Temples benchmark. The statistics of accuracy, run-time and GPU memory on other representative stereo CNNs also validate the effectiveness of our proposed method.
GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems
Sep 02, 2020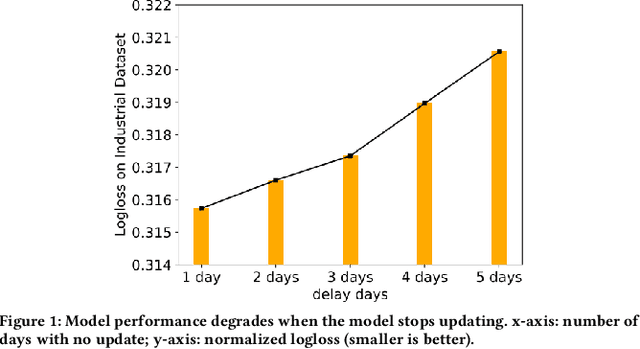

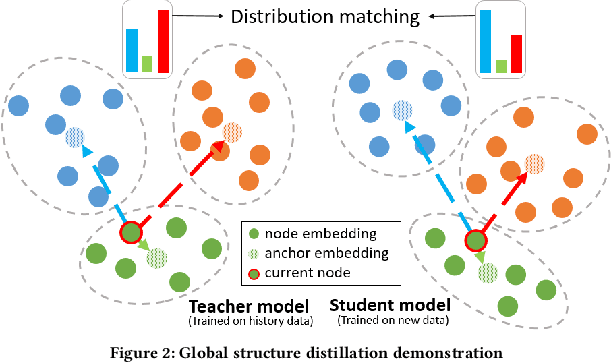
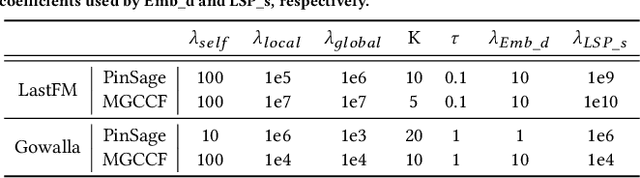
Given the convenience of collecting information through online services, recommender systems now consume large scale data and play a more important role in improving user experience. With the recent emergence of Graph Neural Networks (GNNs), GNN-based recommender models have shown the advantage of modeling the recommender system as a user-item bipartite graph to learn representations of users and items. However, such models are expensive to train and difficult to perform frequent updates to provide the most up-to-date recommendations. In this work, we propose to update GNN-based recommender models incrementally so that the computation time can be greatly reduced and models can be updated more frequently. We develop a Graph Structure Aware Incremental Learning framework, GraphSAIL, to address the commonly experienced catastrophic forgetting problem that occurs when training a model in an incremental fashion. Our approach preserves a user's long-term preference (or an item's long-term property) during incremental model updating. GraphSAIL implements a graph structure preservation strategy which explicitly preserves each node's local structure, global structure, and self-information, respectively. We argue that our incremental training framework is the first attempt tailored for GNN based recommender systems and demonstrate its improvement compared to other incremental learning techniques on two public datasets. We further verify the effectiveness of our framework on a large-scale industrial dataset.
Background Matting: The World is Your Green Screen
Apr 10, 2020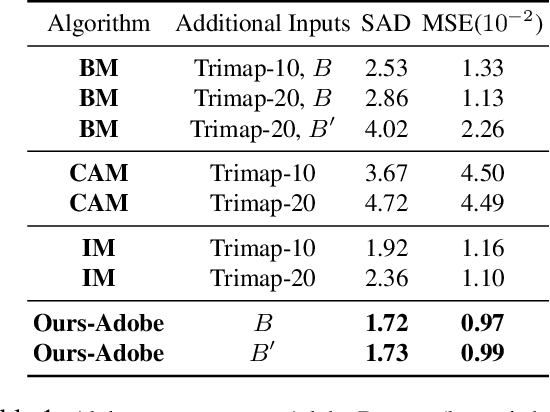
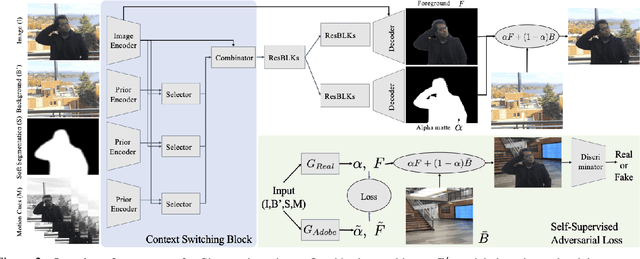
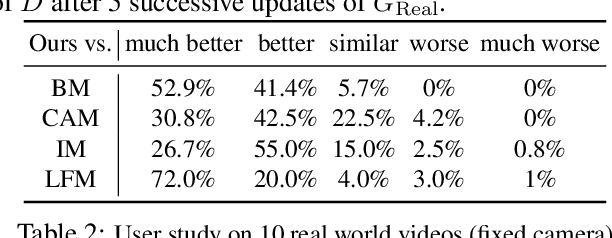

We propose a method for creating a matte -- the per-pixel foreground color and alpha -- of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte. Automatic, trimap-free methods are appearing, but are not of comparable quality. In our trimap free approach, we ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less time-consuming than creating a trimap. We train a deep network with an adversarial loss to predict the matte. We first train a matting network with supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, we train another matting network guided by the first network and by a discriminator that judges the quality of composites. We demonstrate results on a wide variety of photos and videos and show significant improvement over the state of the art.
Robust and Sample Optimal Algorithms for PSD Low-Rank Approximation
Dec 09, 2019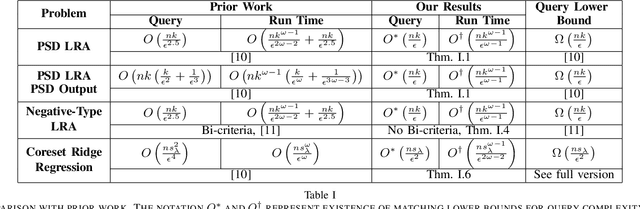
Recently, Musco and Woodruff (FOCS, 2017) showed that given an $n \times n$ positive semidefinite (PSD) matrix $A$, it is possible to compute a relative-error $(1+\epsilon)$-approximate low-rank approximation to $A$ by querying $\widetilde{O}(nk/\epsilon^{2.5})$ entries of $A$ in time $\widetilde{O}(nk/\epsilon^{2.5} +n k^{\omega-1}/\epsilon^{2(\omega-1)})$. They also showed that any relative-error low-rank approximation algorithm must query $\widetilde{\Omega}(nk/\epsilon)$ entries of $A$, and closing this gap is an important open question. Our main result is to resolve this question by showing an algorithm that queries an optimal $\widetilde{O}(nk/\epsilon)$ entries of $A$ and outputs a relative-error low-rank approximation in $\widetilde{O}(n\cdot(k/\epsilon)^{\omega-1})$ time. Note, our running time improves that of Musco and Woodruff, and matches the information-theoretic lower bound if the matrix-multiplication exponent $\omega$ is $2$. Next, we introduce a new robust low-rank approximation model which captures PSD matrices that have been corrupted with noise. We assume that the Frobenius norm of the corruption is bounded. Here, we relax the notion of approximation to additive-error, since it is information-theoretically impossible to obtain a relative-error approximation in this setting. While a sample complexity lower bound precludes sublinear algorithms for arbitrary PSD matices, we provide the first sublinear time and query algorithms when the corruption on the diagonal entries is bounded. As a special case, we show sample-optimal sublinear time algorithms for low-rank approximation of correlation matrices corrupted by noise.
Model-Based Offline Planning
Aug 12, 2020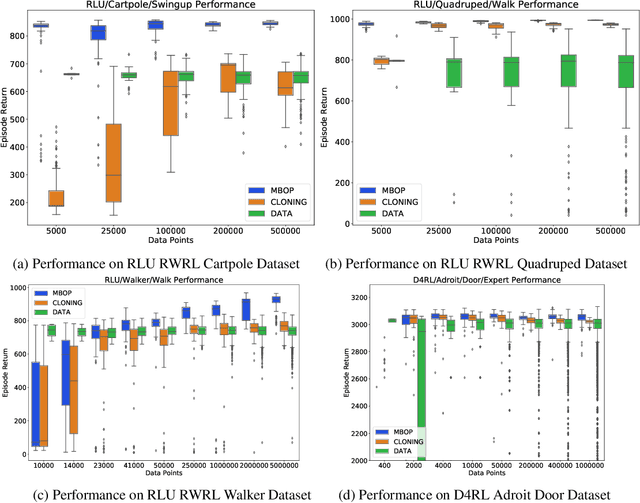
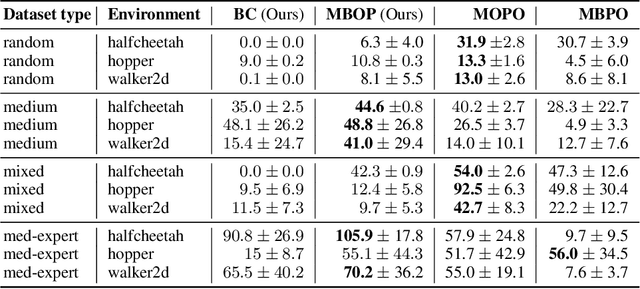
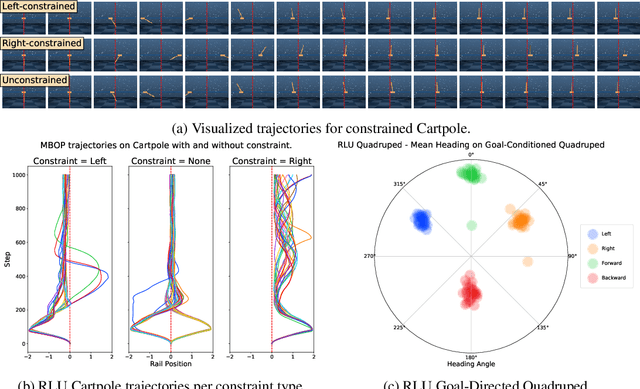
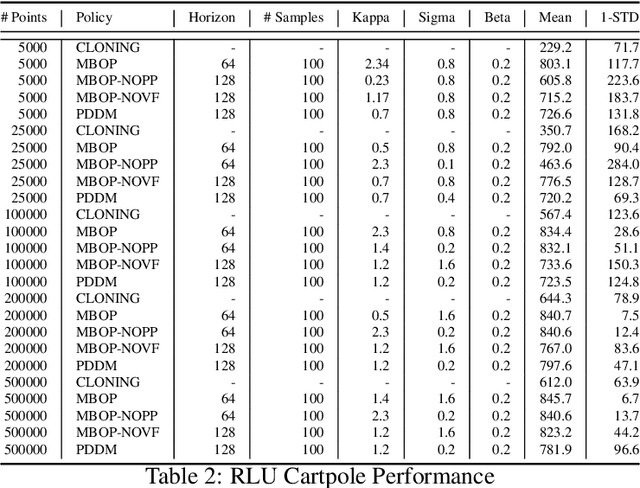
Offline learning is a key part of making reinforcement learning (RL) useable in real systems. Offline RL looks at scenarios where there is data from a system's operation, but no direct access to the system when learning a policy. Recent work on training RL policies from offline data has shown results both with model-free policies learned directly from the data, or with planning on top of learnt models of the data. Model-free policies tend to be more performant, but are more opaque, harder to command externally, and less easy to integrate into larger systems. We propose an offline learner that generates a model that can be used to control the system directly through planning. This allows us to have easily controllable policies directly from data, without ever interacting with the system. We show the performance of our algorithm, Model-Based Offline Planning (MBOP) on a series of robotics-inspired tasks, and demonstrate its ability leverage planning to respect environmental constraints. We are able to find near-optimal polices for certain simulated systems from as little as 50 seconds of real-time system interaction, and create zero-shot goal-conditioned policies on a series of environments.
Functional differentiations in evolutionary reservoir computing networks
Jun 20, 2020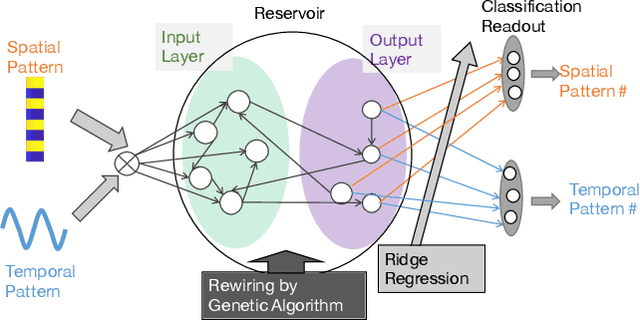
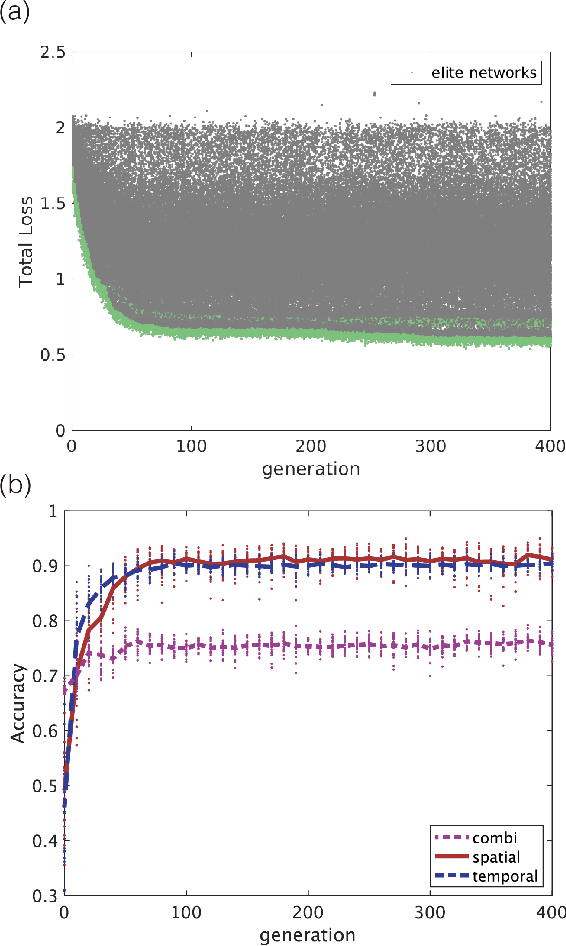
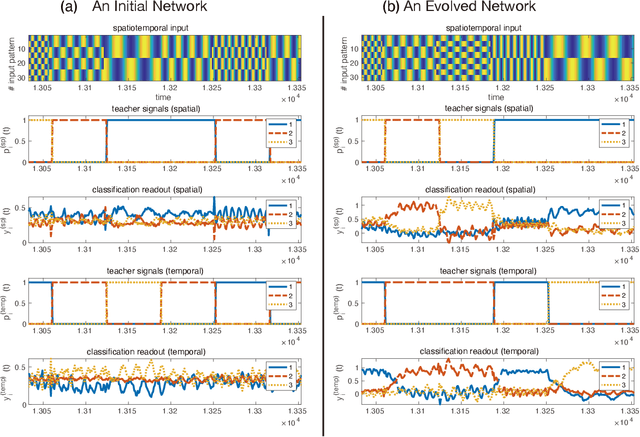
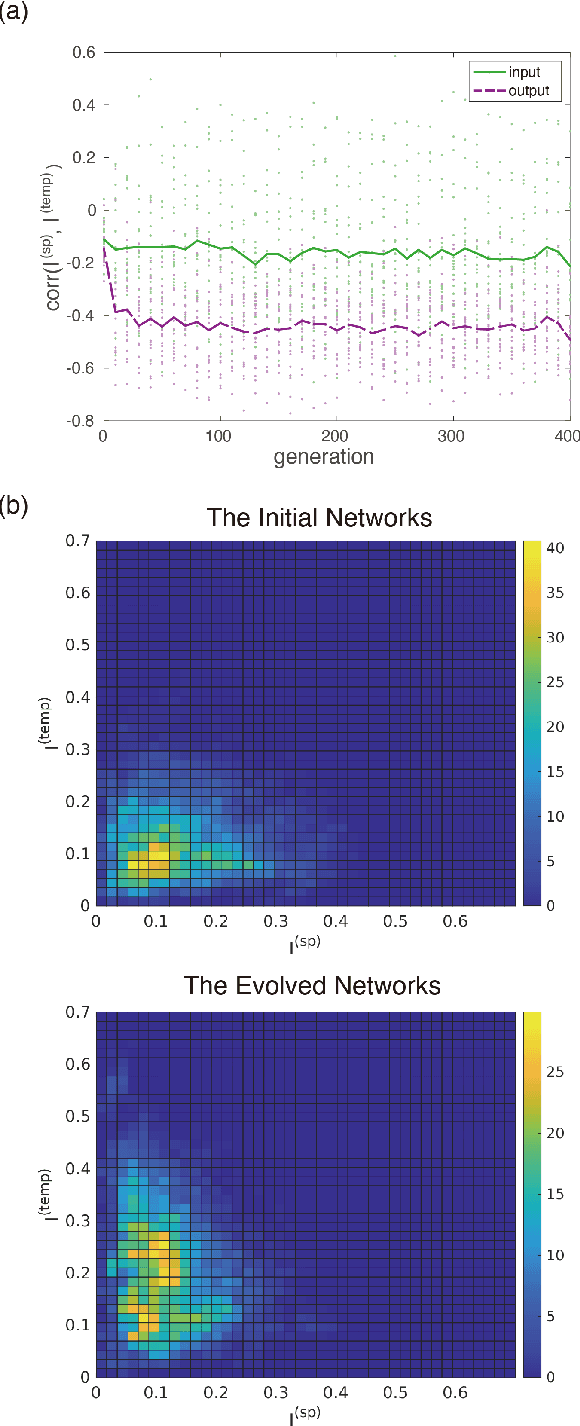
We propose an extended reservoir computer that shows the functional differentiation of neurons. The reservoir computer is developed to enable changing of the internal reservoir using evolutionary dynamics, and we call it an evolutionary reservoir computer. To develop neuronal units to show specificity, depending on the input information, the internal dynamics should be controlled to produce contracting dynamics after expanding dynamics. Expanding dynamics magnifies the difference of input information, while contracting dynamics contributes to forming clusters of input information, thereby producing multiple attractors. The simultaneous appearance of both dynamics indicates the existence of chaos. In contrast, sequential appearance of these dynamics during finite time intervals may induce functional differentiations. In this paper, we show how specific neuronal units are yielded in the evolutionary reservoir computer.
Robustly Learning any Clusterable Mixture of Gaussians
May 13, 2020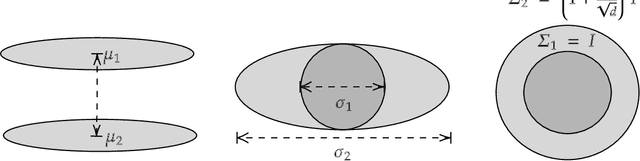
We study the efficient learnability of high-dimensional Gaussian mixtures in the outlier-robust setting, where a small constant fraction of the data is adversarially corrupted. We resolve the polynomial learnability of this problem when the components are pairwise separated in total variation distance. Specifically, we provide an algorithm that, for any constant number of components $k$, runs in polynomial time and learns the components of an $\epsilon$-corrupted $k$-mixture within information theoretically near-optimal error of $\tilde{O}(\epsilon)$, under the assumption that the overlap between any pair of components $P_i, P_j$ (i.e., the quantity $1-TV(P_i, P_j)$) is bounded by $\mathrm{poly}(\epsilon)$. Our separation condition is the qualitatively weakest assumption under which accurate clustering of the samples is possible. In particular, it allows for components with arbitrary covariances and for components with identical means, as long as their covariances differ sufficiently. Ours is the first polynomial time algorithm for this problem, even for $k=2$. Our algorithm follows the Sum-of-Squares based proofs to algorithms approach. Our main technical contribution is a new robust identifiability proof of clusters from a Gaussian mixture, which can be captured by the constant-degree Sum of Squares proof system. The key ingredients of this proof are a novel use of SoS-certifiable anti-concentration and a new characterization of pairs of Gaussians with small (dimension-independent) overlap in terms of their parameter distance.
Revisiting Modified Greedy Algorithm for Monotone Submodular Maximization with a Knapsack Constraint
Aug 12, 2020

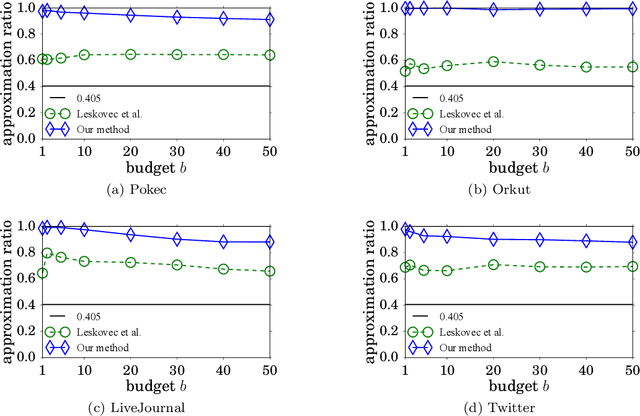
Monotone submodular maximization with a knapsack constraint is NP-hard. Various approximation algorithms have been devised to address this optimization problem. In this paper, we revisit the widely known modified greedy algorithm. First, we show that this algorithm can achieve an approximation factor of $0.405$, which significantly improves the known factor of $0.357$ given by Wolsey or $(1-1/\mathrm{e})/2\approx 0.316$ given by Khuller et al. More importantly, our analysis uncovers a gap in Khuller et al.'s proof for the extensively mentioned approximation factor of $(1-1/\sqrt{\mathrm{e}})\approx 0.393$ in the literature to clarify a long time of misunderstanding on this issue. Second, we enhance the modified greedy algorithm to derive a data-dependent upper bound on the optimum. We empirically demonstrate the tightness of our upper bound with a real-world application. The bound enables us to obtain a data-dependent ratio typically much higher than $0.405$ between the solution value of the modified greedy algorithm and the optimum. It can also be used to significantly improve the efficiency of algorithms such as branch and bound.
COVID CT-Net: Predicting Covid-19 From Chest CT Images Using Attentional Convolutional Network
Sep 10, 2020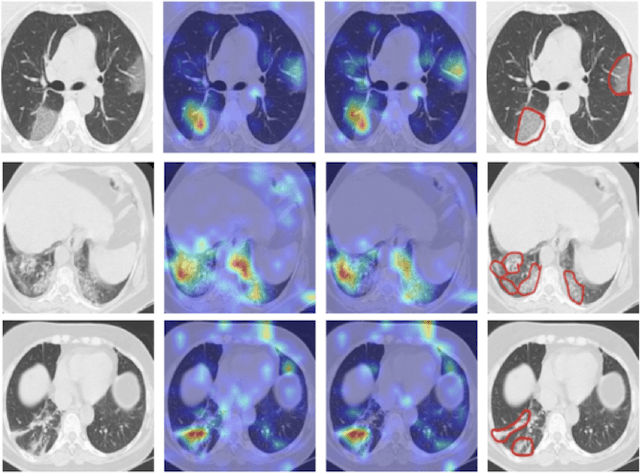
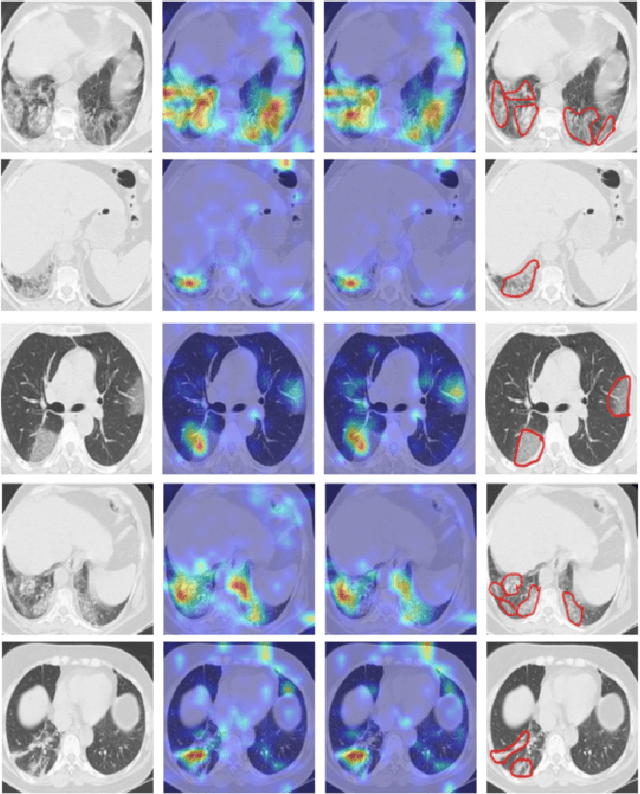
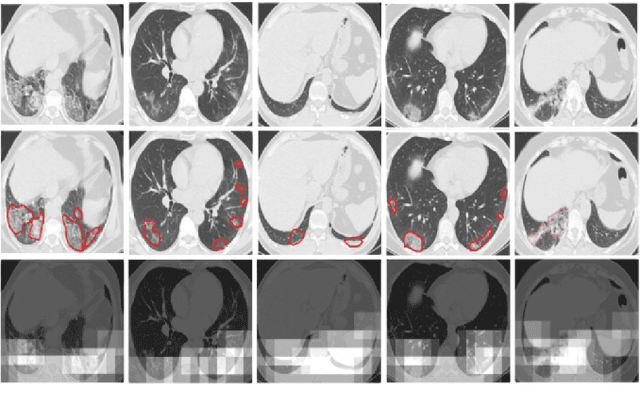
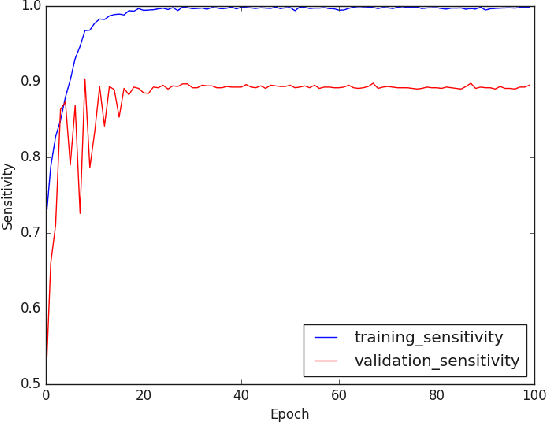
The novel corona-virus disease (COVID-19) pandemic has caused a major outbreak in more than 200 countries around the world, leading to a severe impact on the health and life of many people globally. As of Aug 25th of 2020, more than 20 million people are infected, and more than 800,000 death are reported. Computed Tomography (CT) images can be used as a as an alternative to the time-consuming "reverse transcription polymerase chain reaction (RT-PCR)" test, to detect COVID-19. In this work we developed a deep learning framework to predict COVID-19 from CT images. We propose to use an attentional convolution network, which can focus on the infected areas of chest, enabling it to perform a more accurate prediction. We trained our model on a dataset of more than 2000 CT images, and report its performance in terms of various popular metrics, such as sensitivity, specificity, area under the curve, and also precision-recall curve, and achieve very promising results. We also provide a visualization of the attention maps of the model for several test images, and show that our model is attending to the infected regions as intended. In addition to developing a machine learning modeling framework, we also provide the manual annotation of the potentionally infected regions of chest, with the help of a board-certified radiologist, and make that publicly available for other researchers.