 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient Descent over Metagrammars for Syntax-Guided Synthesis
Jul 16, 2020

The performance of a syntax-guided synthesis algorithm is highly dependent on the provision of a good syntactic template, or grammar. Provision of such a template is often left to the user to do manually, though in the absence of such a grammar, state-of-the-art solvers will provide their own default grammar, which is dependent on the signature of the target program to be sythesized. In this work, we speculate this default grammar could be improved upon substantially. We build sets of rules, or metagrammars, for constructing grammars, and perform a gradient descent over these metagrammars aiming to find a metagrammar which solves more benchmarks and on average faster. We show the resulting metagrammar enables CVC4 to solve 26% more benchmarks than the default grammar within a 300s time-out, and that metagrammars learnt from tens of benchmarks generalize to performance on 100s of benchmarks.
An Efficient Machine-Learning Approach for PDF Tabulation in Turbulent Combustion Closure
May 18, 2020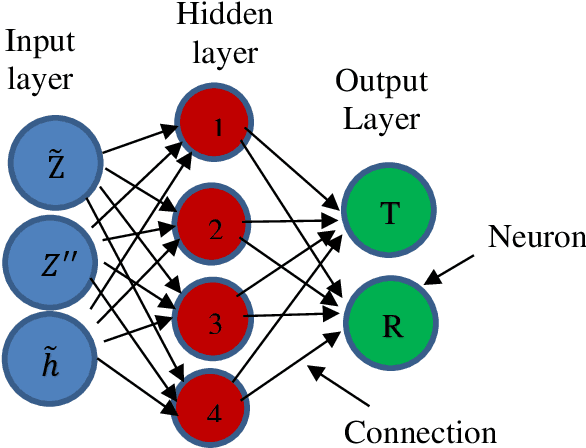
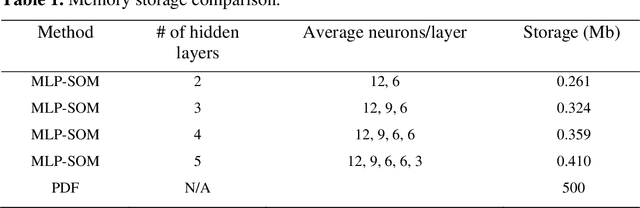
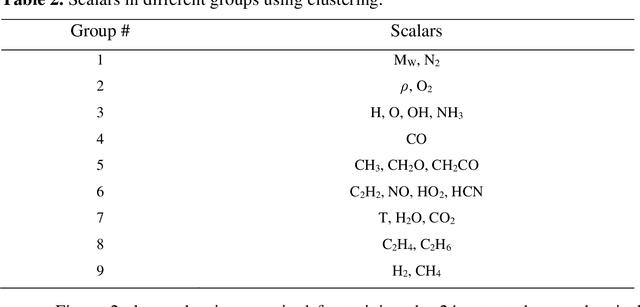
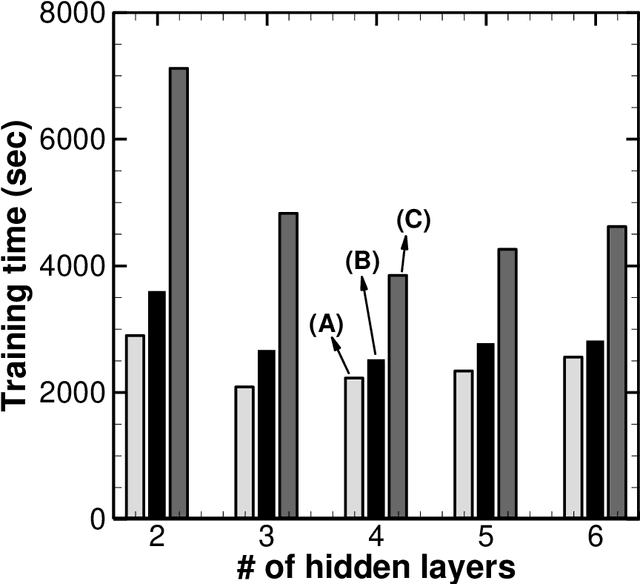
Probability density function (PDF) based turbulent combustion modelling is limited by the need to store multi-dimensional PDF tables that can take up large amounts of memory. A significant saving in storage can be achieved by using various machine-learning techniques that represent the thermo-chemical quantities of a PDF table using mathematical functions. These functions can be computationally more expensive than the existing interpolation methods used for thermo-chemical quantities. More importantly, the training time can amount to a considerable portion of the simulation time. In this work, we address these issues by introducing an adaptive training algorithm that relies on multi-layer perception (MLP) neural networks for regression and self-organizing maps (SOMs) for clustering data to tabulate using different networks. The algorithm is designed to address both the multi-dimensionality of the PDF table as well as the computational efficiency of the proposed algorithm. SOM clustering divides the PDF table into several parts based on similarities in data. Each cluster of data is trained using an MLP algorithm on simple network architectures to generate local functions for thermo-chemical quantities. The algorithm is validated for the so-called DLR-A turbulent jet diffusion flame using both RANS and LES simulations and the results of the PDF tabulation are compared to the standard linear interpolation method. The comparison yields a very good agreement between the two tabulation techniques and establishes the MLP-SOM approach as a viable method for PDF tabulation.
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020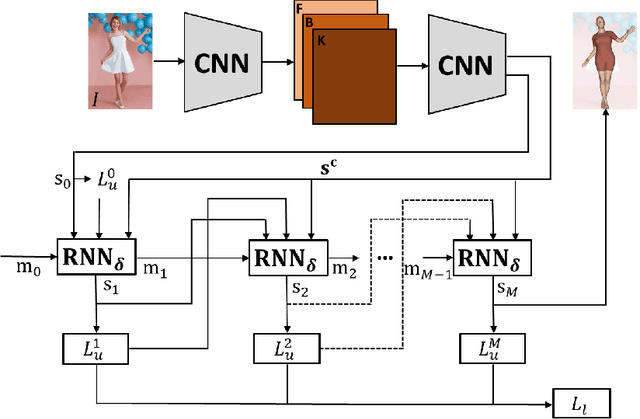
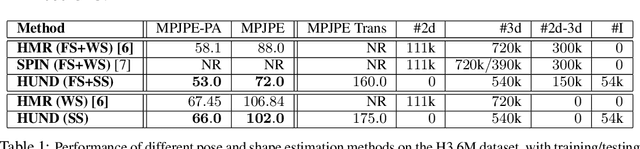

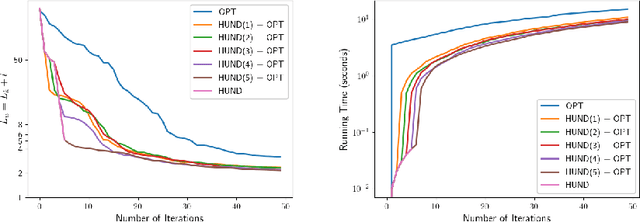
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
Multi-Purchase Behavior: Modeling and Optimization
Jun 14, 2020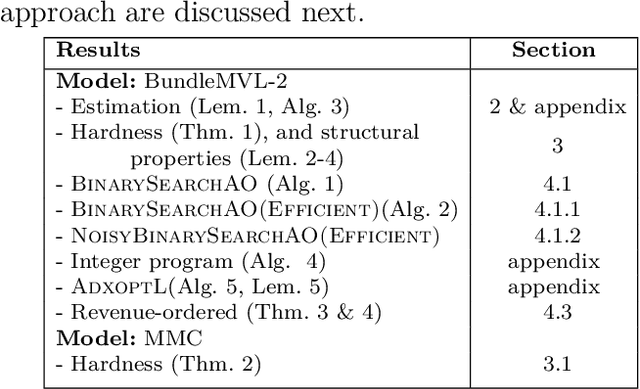
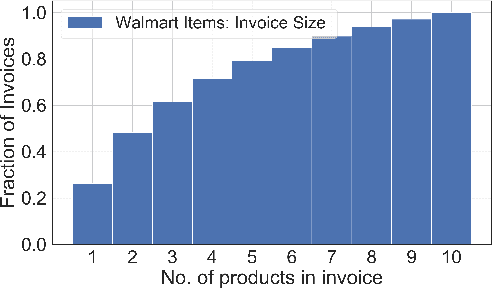

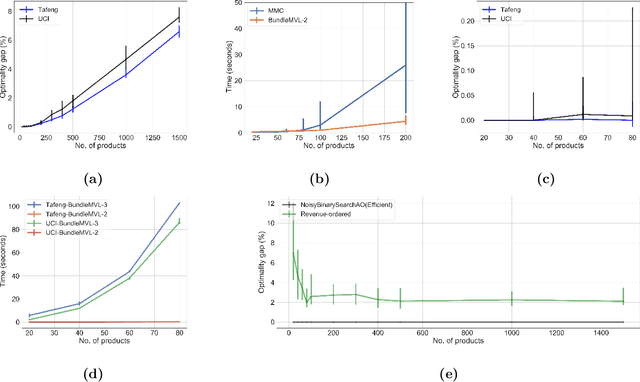
We study the problem of modeling purchase of multiple items and utilizing it to display optimized recommendations, which is a central problem for online e-commerce platforms. Rich personalized modeling of users and fast computation of optimal products to display given these models can lead to significantly higher revenues and simultaneously enhance the end user experience. We present a parsimonious multi-purchase family of choice models called the BundleMVL-K family, and develop a binary search based iterative strategy that efficiently computes optimized recommendations for this model. This is one of the first attempts at operationalizing multi-purchase class of choice models. We characterize structural properties of the optimal solution, which allow one to decide if a product is part of the optimal assortment in constant time, reducing the size of the instance that needs to be solved computationally. We also establish the hardness of computing optimal recommendation sets. We show one of the first quantitative links between modeling multiple purchase behavior and revenue gains. The efficacy of our modeling and optimization techniques compared to competing solutions is shown using several real world datasets on multiple metrics such as model fitness, expected revenue gains and run-time reductions. The benefit of taking multiple purchases into account is observed to be $6-8\%$ in relative terms for the Ta Feng and UCI shopping datasets when compared to the MNL model for instances with $\sim 1500$ products. Additionally, across $8$ real world datasets, the test log-likelihood fits of our models are on average $17\%$ better in relative terms. The simplicity of our models and the iterative nature of our optimization technique allows practitioners meet stringent computational constraints while increasing their revenues in practical recommendation applications at scale.
A Relearning Approach to Reinforcement Learning for Control of Smart Buildings
Aug 04, 2020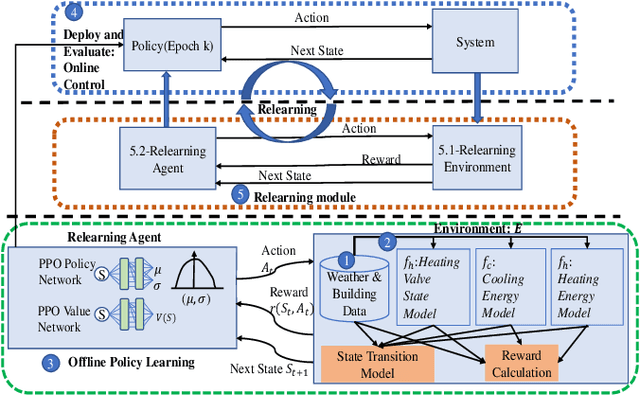
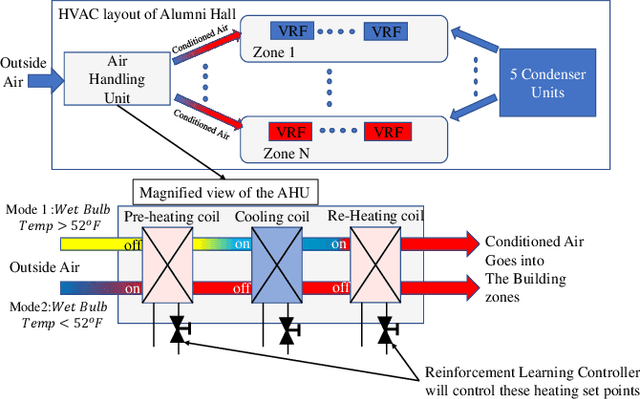
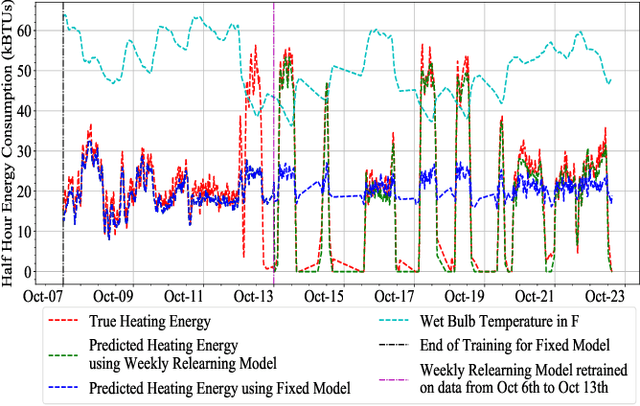
This paper demonstrates that continual relearning of control policies using incremental deep reinforcement learning (RL) can improve policy learning for non-stationary processes. We demonstrate this approach for a data-driven 'smart building environment' that we use as a test-bed for developing HVAC controllers for reducing energy consumption of large buildings on our university campus. The non-stationarity in building operations and weather patterns makes it imperative to develop control strategies that are adaptive to changing conditions. On-policy RL algorithms, such as Proximal Policy Optimization (PPO) represent an approach for addressing this non-stationarity, but exploration on the actual system is not an option for safety-critical systems. As an alternative, we develop an incremental RL technique that simultaneously reduces building energy consumption without sacrificing overall comfort. We compare the performance of our incremental RL controller to that of a static RL controller that does not implement the relearning function. The performance of the static controller diminishes significantly over time, but the relearning controller adjusts to changing conditions while ensuring comfort and optimal energy performance.
Out-of-Core GPU Gradient Boosting
May 19, 2020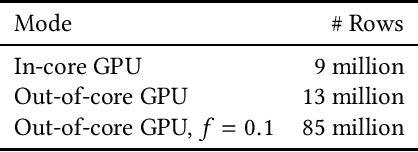
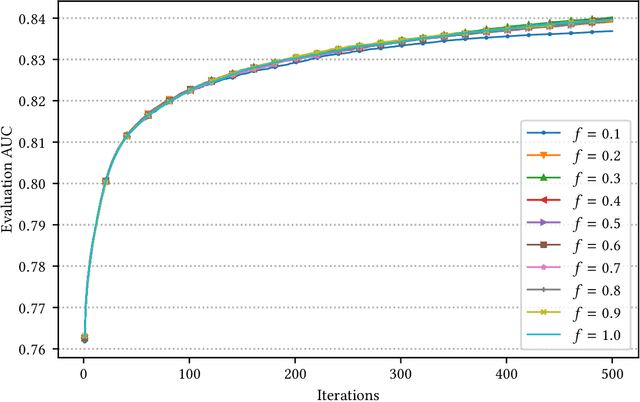
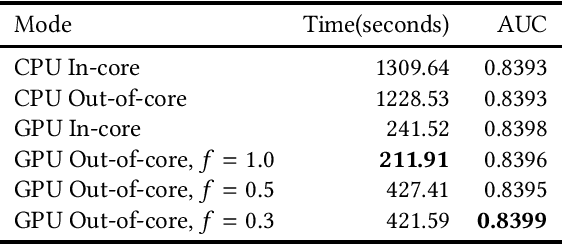
GPU-based algorithms have greatly accelerated many machine learning methods; however, GPU memory is typically smaller than main memory, limiting the size of training data. In this paper, we describe an out-of-core GPU gradient boosting algorithm implemented in the XGBoost library. We show that much larger datasets can fit on a given GPU, without degrading model accuracy or training time. To the best of our knowledge, this is the first out-of-core GPU implementation of gradient boosting. Similar approaches can be applied to other machine learning algorithms
An Empirical Evaluation of Similarity Measures for Time Series Classification
Jan 16, 2014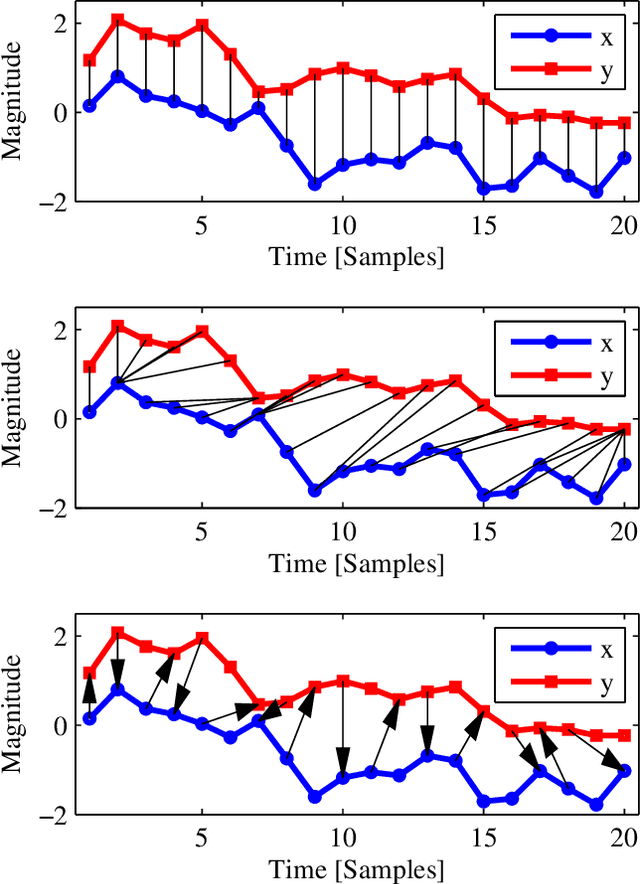
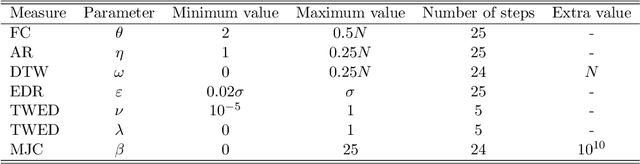
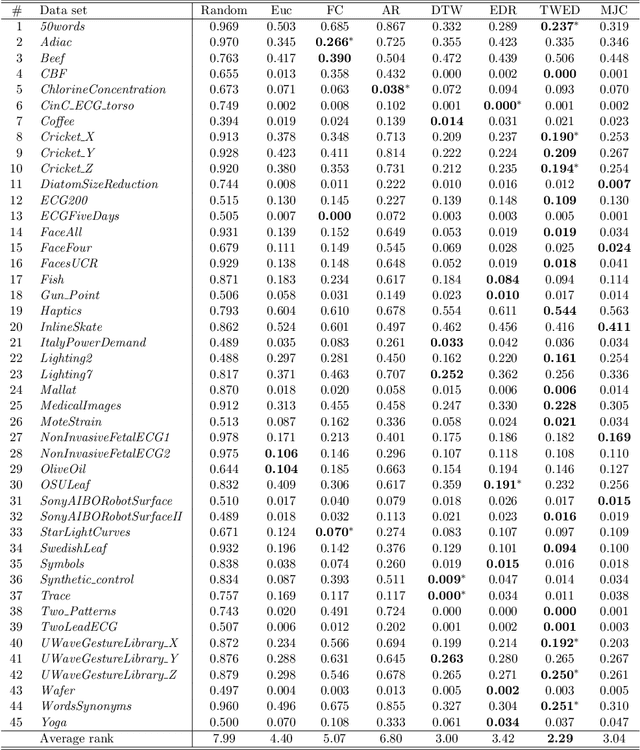
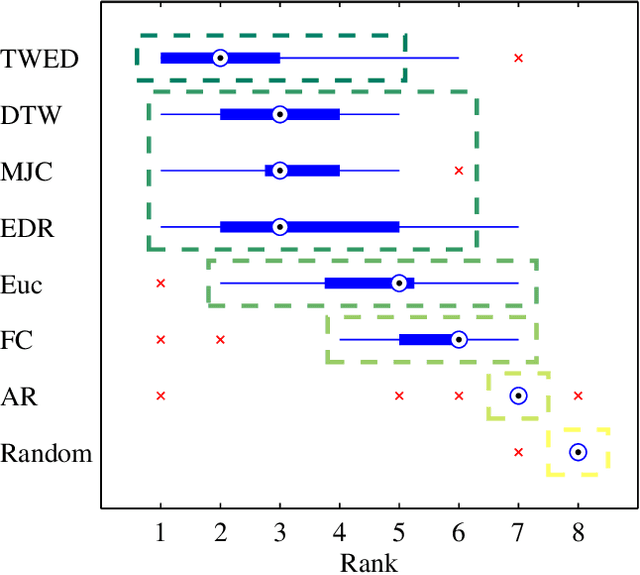
Time series are ubiquitous, and a measure to assess their similarity is a core part of many computational systems. In particular, the similarity measure is the most essential ingredient of time series clustering and classification systems. Because of this importance, countless approaches to estimate time series similarity have been proposed. However, there is a lack of comparative studies using empirical, rigorous, quantitative, and large-scale assessment strategies. In this article, we provide an extensive evaluation of similarity measures for time series classification following the aforementioned principles. We consider 7 different measures coming from alternative measure `families', and 45 publicly-available time series data sets coming from a wide variety of scientific domains. We focus on out-of-sample classification accuracy, but in-sample accuracies and parameter choices are also discussed. Our work is based on rigorous evaluation methodologies and includes the use of powerful statistical significance tests to derive meaningful conclusions. The obtained results show the equivalence, in terms of accuracy, of a number of measures, but with one single candidate outperforming the rest. Such findings, together with the followed methodology, invite researchers on the field to adopt a more consistent evaluation criteria and a more informed decision regarding the baseline measures to which new developments should be compared.
* 28 pages, 5 figures, 3 tables
Relative Feature Importance
Jul 16, 2020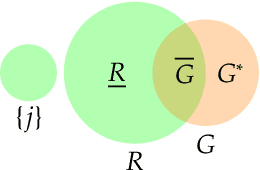
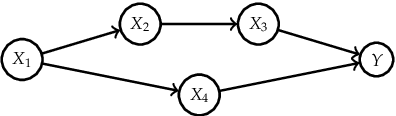
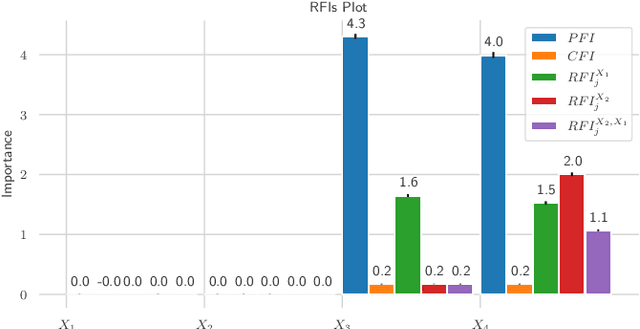
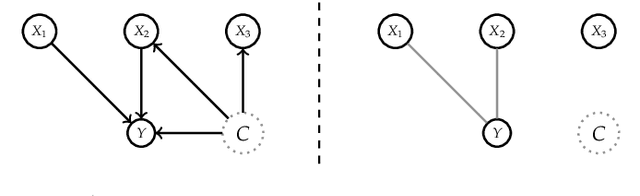
Interpretable Machine Learning (IML) methods are used to gain insight into the relevance of a feature of interest for the performance of a model. Commonly used IML methods differ in whether they consider features of interest in isolation, e.g., Permutation Feature Importance (PFI), or in relation to all remaining feature variables, e.g., Conditional Feature Importance (CFI). As such, the perturbation mechanisms inherent to PFI and CFI represent extreme reference points. We introduce Relative Feature Importance (RFI), a generalization of PFI and CFI that allows for a more nuanced feature importance computation beyond the PFI versus CFI dichotomy. With RFI, the importance of a feature relative to any other subset of features can be assessed, including variables that were not available at training time. We derive general interpretation rules for RFI based on a detailed theoretical analysis of the implications of relative feature relevance, and demonstrate the method's usefulness on simulated examples.
An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department
Aug 04, 2020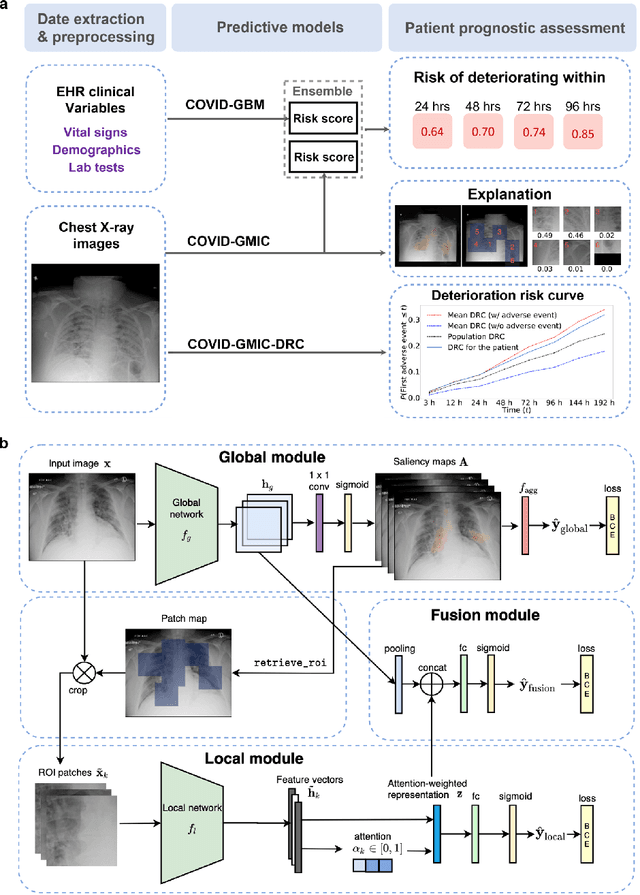
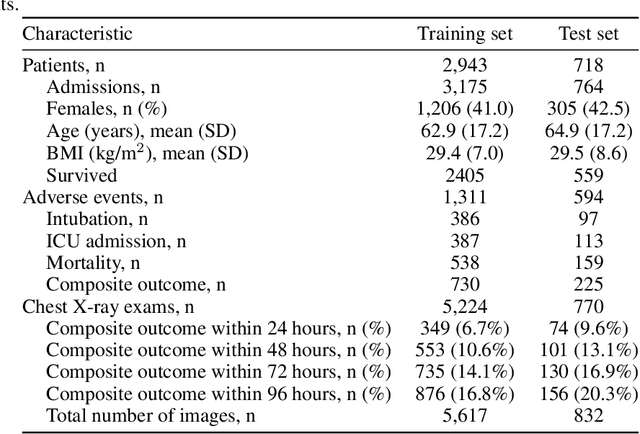
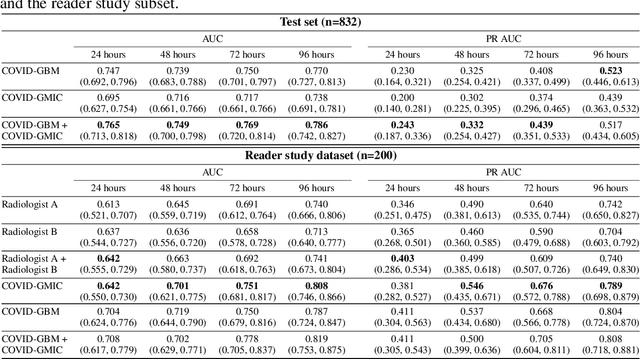
During the COVID-19 pandemic, rapid and accurate triage of patients at the emergency department is critical to inform decision-making. We propose a data-driven approach for automatic prediction of deterioration risk using a deep neural network that learns from chest X-ray images, and a gradient boosting model that learns from routine clinical variables. Our AI prognosis system, trained using data from 3,661 patients, achieves an AUC of 0.786 (95% CI: 0.742-0.827) when predicting deterioration within 96 hours. The deep neural network extracts informative areas of chest X-ray images to assist clinicians in interpreting the predictions, and performs comparably to two radiologists in a reader study. In order to verify performance in a real clinical setting, we silently deployed a preliminary version of the deep neural network at NYU Langone Health during the first wave of the pandemic, which produced accurate predictions in real-time. In summary, our findings demonstrate the potential of the proposed system for assisting front-line physicians in the triage of COVID-19 patients.
Using a memory of motion to efficiently achieve visual predictive control tasks
Jan 31, 2020

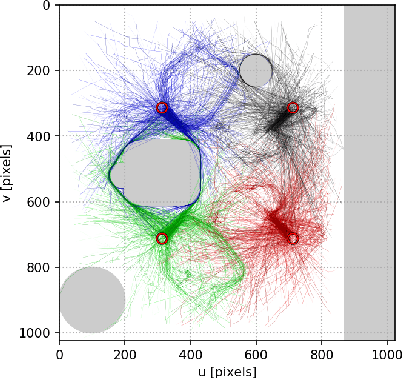
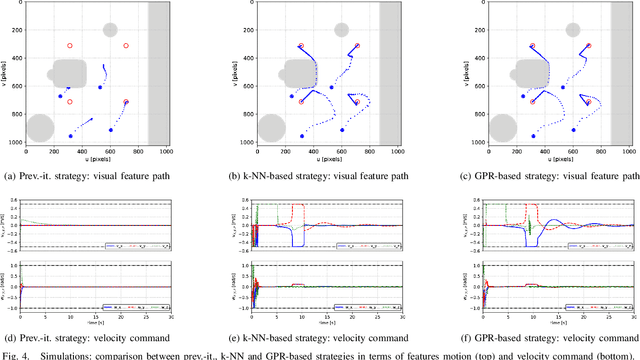
This paper addresses the problem of efficiently achieving visual predictive control tasks. To this end, a memory of motion, containing a set of trajectories built off-line, is used for leveraging precomputation and dealing with difficult visual tasks. Regression techniques, such as k-nearest neighbors and Gaussian process regression, are used to query the memory and provide on-line the control optimization process with a warm-start and way points. The proposed technique allows the robot to achieve difficult tasks and, at the same time, keep the execution time limited. Simulation and experimental results, carried out with a 7-axis manipulator, show the effectiveness of the approach.