 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Variational Bayesian Training of Tensorized Neural Networks with Automatic Rank Determination
Oct 17, 2020
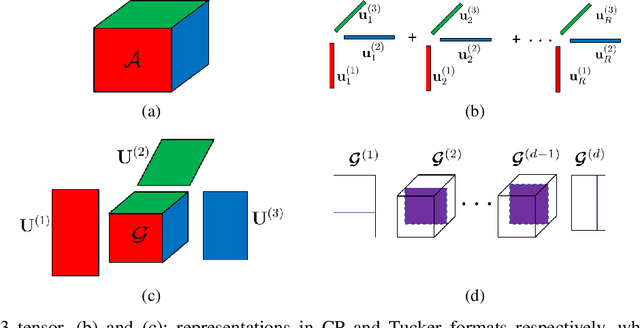
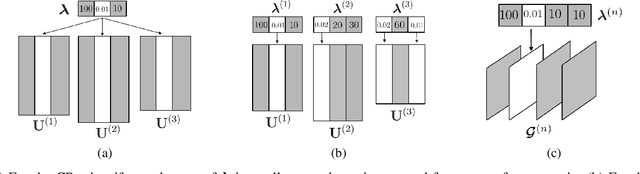
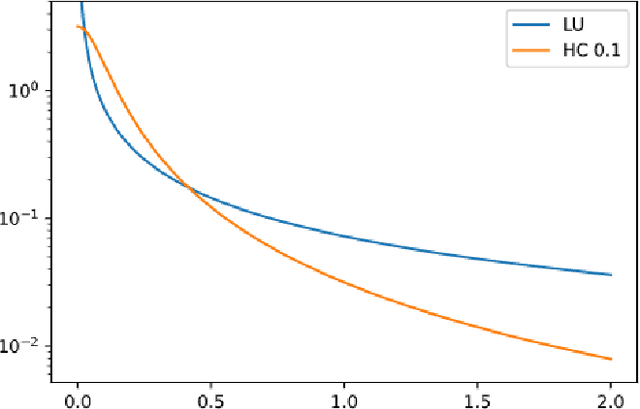
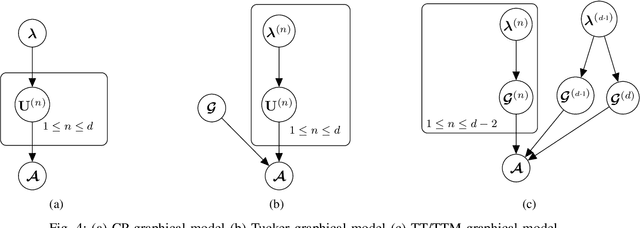
Low-rank tensor decomposition is one of the most effective approaches to reduce the memory and computing requirements of large-size neural networks, enabling their efficient deployment on various hardware platforms. While post-training tensor compression can greatly reduce the cost of inference, uncompressed training still consumes excessive hardware resources, run-time and energy. It is highly desirable to directly train a compact low-rank tensorized model from scratch with a low memory and computational cost. However, this is a very challenging task because it is hard to determine a proper tensor rank a priori, which controls the model complexity and compression ratio in the training process. This paper presents a novel end-to-end framework for low-rank tensorized training of neural networks. We first develop a flexible Bayesian model that can handle various low-rank tensor formats (e.g., CP, Tucker, tensor train and tensor-train matrix) that compress neural network parameters in training. This model can automatically determine the tensor ranks inside a nonlinear forward model, which is beyond the capability of existing Bayesian tensor methods. We further develop a scalable stochastic variational inference solver to estimate the posterior density of large-scale problems in training. Our work provides the first general-purpose rank-adaptive framework for end-to-end tensorized training. Our numerical results on various neural network architectures show orders-of-magnitude parameter reduction and little accuracy loss (or even better accuracy) in the training process.
Malignancy-Aware Follow-Up Volume Prediction for Lung Nodules
Jun 24, 2020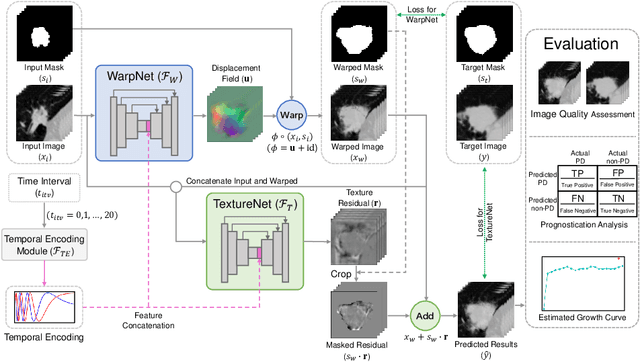
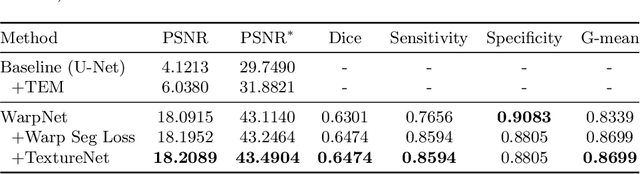

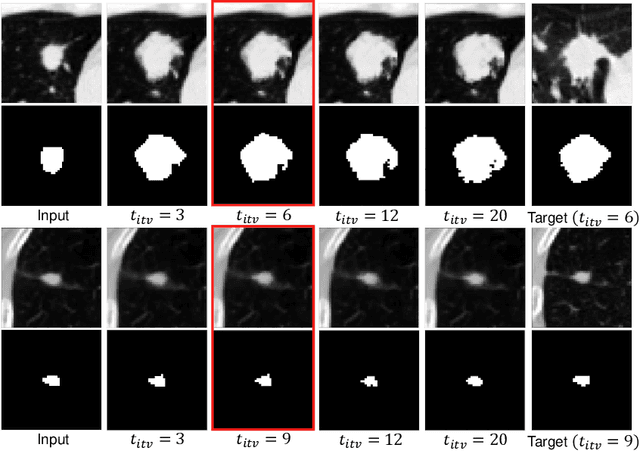
Follow-up serves an important role in the management of pulmonary nodules for lung cancer. Imaging diagnostic guidelines with expert consensus have been made to help radiologists make clinical decision for each patient. However, tumor growth is such a complicated process that it is difficult to stratify high-risk nodules from low-risk ones based on morphologic characteristics. On the other hand, recent deep learning studies using convolutional neural networks (CNNs) to predict the malignancy score of nodules, only provides clinicians with black-box predictions. To this end, we propose a unified framework, named Nodule Follow-Up Prediction Network (NoFoNet), which predicts the growth of pulmonary nodules with high-quality visual appearances and accurate quantitative malignancy scores, given any time interval from baseline observations. It is achieved by predicting future displacement field of each voxel with a WarpNet. A TextureNet is further developed to refine textural details of WarpNet outputs. We also introduce techniques including Temporal Encoding Module and Warp Segmentation Loss to encourage time-aware and malignancy-aware representation learning. We build an in-house follow-up dataset from two medical centers to validate the effectiveness of the proposed method. NoFoNet~significantly outperforms direct prediction by a U-Net in terms of visual quality; more importantly, it demonstrates accurate differentiating performance between high- and low-risk nodules. Our promising results suggest the potentials in computer aided intervention for lung nodule management.
Online Guest Detection in a Smart Home using Pervasive Sensors and Probabilistic Reasoning
Mar 13, 2020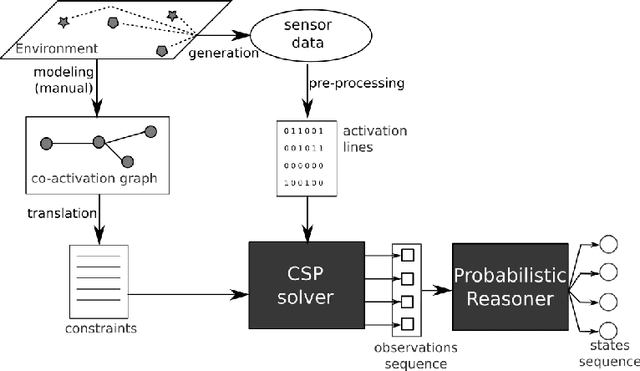
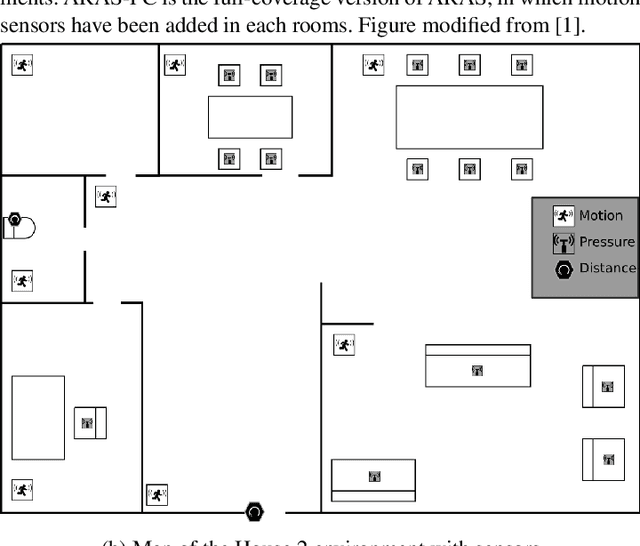
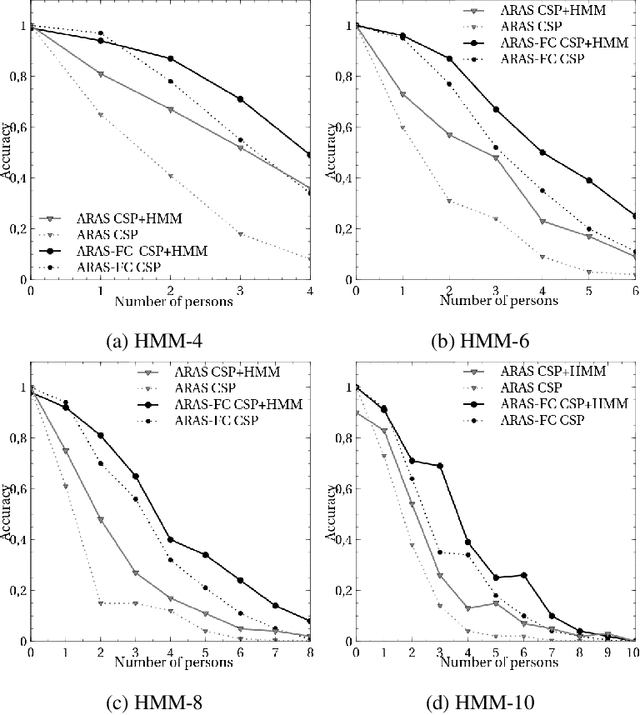
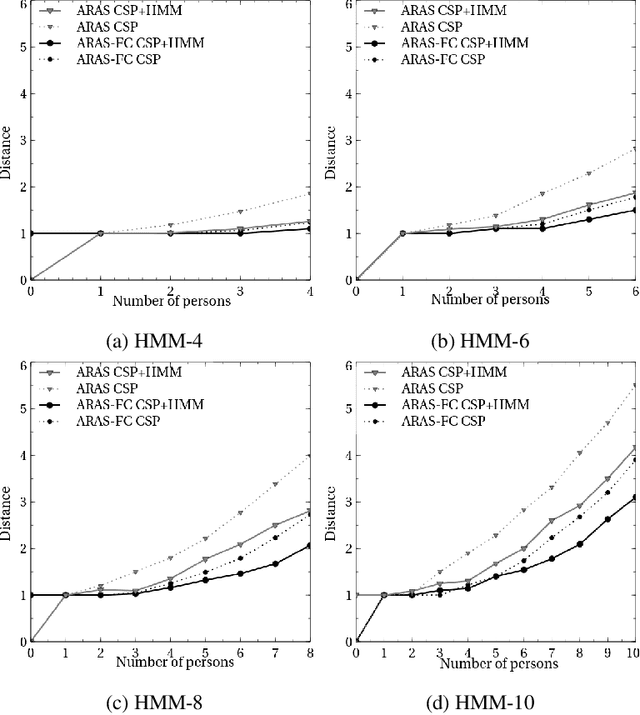
Smart home environments equipped with distributed sensor networks are capable of helping people by providing services related to health, emergency detection or daily routine management. A backbone to these systems relies often on the system's ability to track and detect activities performed by the users in their home. Despite the continuous progress in the area of activity recognition in smart homes, many systems make a strong underlying assumption that the number of occupants in the home at any given moment of time is always known. Estimating the number of persons in a Smart Home at each time step remains a challenge nowadays. Indeed, unlike most (crowd) counting solution which are based on computer vision techniques, the sensors considered in a Smart Home are often very simple and do not offer individually a good overview of the situation. The data gathered needs therefore to be fused in order to infer useful information. This paper aims at addressing this challenge and presents a probabilistic approach able to estimate the number of persons in the environment at each time step. This approach works in two steps: first, an estimate of the number of persons present in the environment is done using a Constraint Satisfaction Problem solver, based on the topology of the sensor network and the sensor activation pattern at this time point. Then, a Hidden Markov Model refines this estimate by considering the uncertainty related to the sensors. Using both simulated and real data, our method has been tested and validated on two smart homes of different sizes and configuration and demonstrates the ability to accurately estimate the number of inhabitants.
On $\ell_p$-norm Robustness of Ensemble Stumps and Trees
Sep 29, 2020
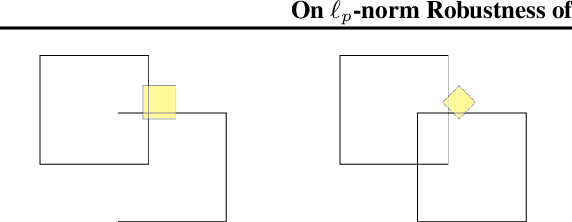

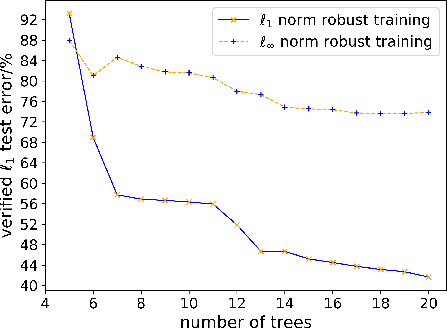
Recent papers have demonstrated that ensemble stumps and trees could be vulnerable to small input perturbations, so robustness verification and defense for those models have become an important research problem. However, due to the structure of decision trees, where each node makes decision purely based on one feature value, all the previous works only consider the $\ell_\infty$ norm perturbation. To study robustness with respect to a general $\ell_p$ norm perturbation, one has to consider the correlation between perturbations on different features, which has not been handled by previous algorithms. In this paper, we study the problem of robustness verification and certified defense with respect to general $\ell_p$ norm perturbations for ensemble decision stumps and trees. For robustness verification of ensemble stumps, we prove that complete verification is NP-complete for $p\in(0, \infty)$ while polynomial time algorithms exist for $p=0$ or $\infty$. For $p\in(0, \infty)$ we develop an efficient dynamic programming based algorithm for sound verification of ensemble stumps. For ensemble trees, we generalize the previous multi-level robustness verification algorithm to $\ell_p$ norm. We demonstrate the first certified defense method for training ensemble stumps and trees with respect to $\ell_p$ norm perturbations, and verify its effectiveness empirically on real datasets.
Efficient Derivative Computation for Cumulative B-Splines on Lie Groups
Nov 20, 2019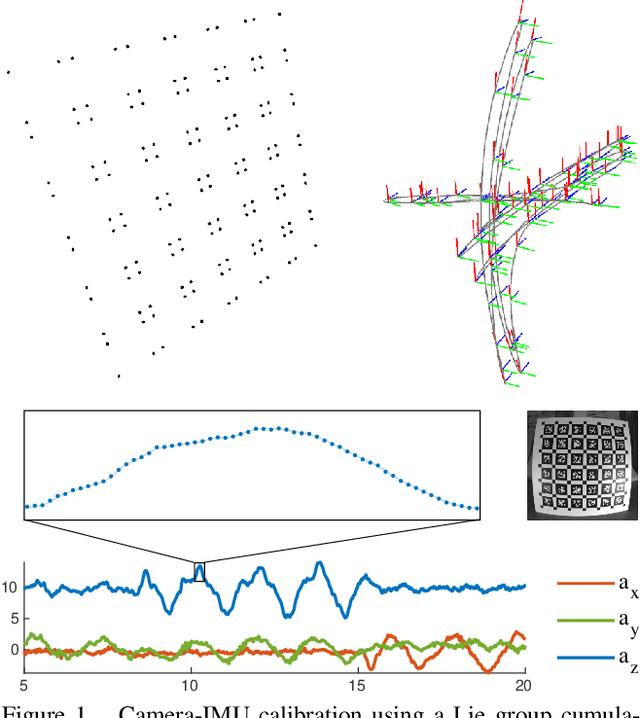
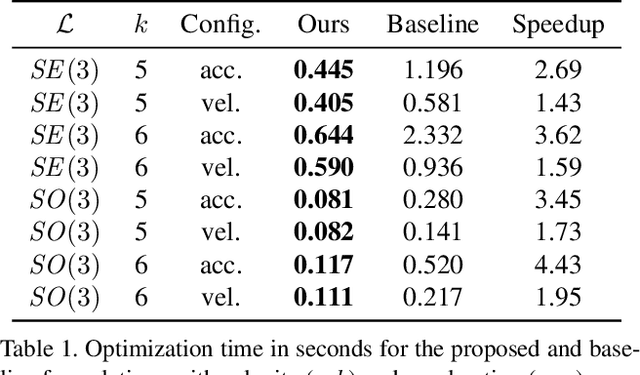


Continuous-time trajectory representation has recently gained popularity for tasks where the fusion of high-frame-rate sensors and multiple unsynchronized devices is required. Lie group cumulative B-splines are a popular way of representing continuous trajectories without singularities. They have been used in near real-time SLAM and odometry systems with IMU, LiDAR, regular, RGB-D and event cameras, as well as for offline calibration. These applications require efficient computation of time derivatives (velocity, acceleration), but all prior works rely on a computationally suboptimal formulation. In this work we present an alternative derivation of time derivatives based on recurrence relations that needs $\mathcal{O}(k)$ instead of $\mathcal{O}(k^2)$ matrix operations (for a spline of order $k$) and results in simple and elegant expressions. While producing the same result, the proposed approach significantly speeds up the trajectory optimization and allows for computing simple analytic derivatives with respect to spline knots. The results presented in this paper pave the way for incorporating continuous-time trajectory representations into more applications where real-time performance is required.
Active Preference-Based Gaussian Process Regression for Reward Learning
Jun 03, 2020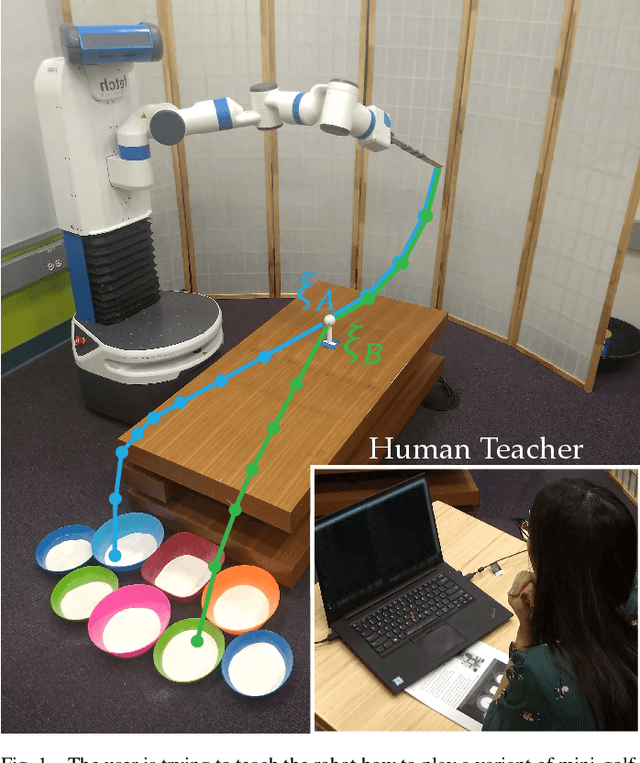
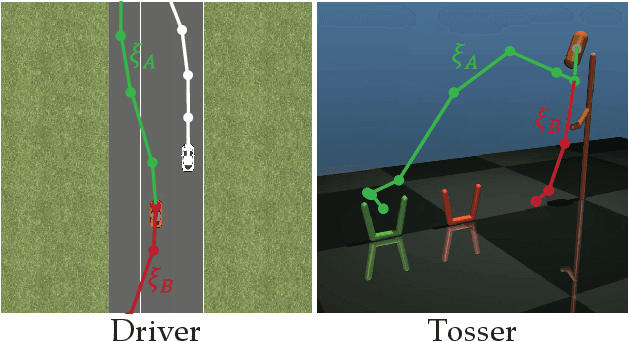
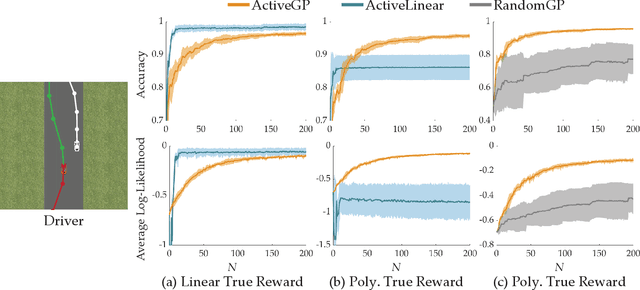
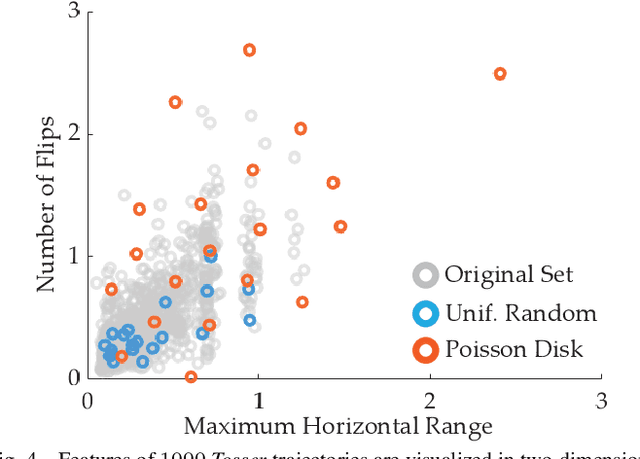
Designing reward functions is a challenging problem in AI and robotics. Humans usually have a difficult time directly specifying all the desirable behaviors that a robot needs to optimize. One common approach is to learn reward functions from collected expert demonstrations. However, learning reward functions from demonstrations introduces many challenges: some methods require highly structured models, e.g. reward functions that are linear in some predefined set of features, while others adopt less structured reward functions that on the other hand require tremendous amount of data. In addition, humans tend to have a difficult time providing demonstrations on robots with high degrees of freedom, or even quantifying reward values for given demonstrations. To address these challenges, we present a preference-based learning approach, where as an alternative, the human feedback is only in the form of comparisons between trajectories. Furthermore, we do not assume highly constrained structures on the reward function. Instead, we model the reward function using a Gaussian Process (GP) and propose a mathematical formulation to actively find a GP using only human preferences. Our approach enables us to tackle both inflexibility and data-inefficiency problems within a preference-based learning framework. Our results in simulations and a user study suggest that our approach can efficiently learn expressive reward functions for robotics tasks.
Phonological Features for 0-shot Multilingual Speech Synthesis
Aug 06, 2020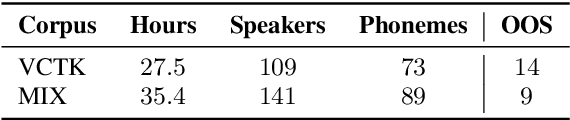


Code-switching---the intra-utterance use of multiple languages---is prevalent across the world. Within text-to-speech (TTS), multilingual models have been found to enable code-switching. By modifying the linguistic input to sequence-to-sequence TTS, we show that code-switching is possible for languages unseen during training, even within monolingual models. We use a small set of phonological features derived from the International Phonetic Alphabet (IPA), such as vowel height and frontness, consonant place and manner. This allows the model topology to stay unchanged for different languages, and enables new, previously unseen feature combinations to be interpreted by the model. We show that this allows us to generate intelligible, code-switched speech in a new language at test time, including the approximation of sounds never seen in training.
Combinatorial Pure Exploration with Partial or Full-Bandit Linear Feedback
Jun 14, 2020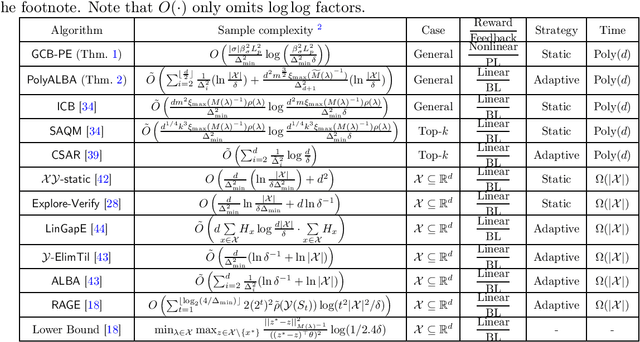
In this paper, we propose the novel model of combinatorial pure exploration with partial linear feedback (CPE-PL). In CPE-PL, given a combinatorial action space $\mathcal{X} \subseteq \{0,1\}^d$, in each round a learner chooses one action $x \in \mathcal{X}$ to play, obtains a random (possibly nonlinear) reward related to $x$ and an unknown latent vector $\theta \in \mathbb{R}^d$, and observes a partial linear feedback $M_{x} (\theta + \eta)$, where $\eta$ is a zero-mean noise vector and $M_x$ is a transformation matrix for $x$. The objective is to identify the optimal action with the maximum expected reward using as few rounds as possible. We also study the important subproblem of CPE-PL, i.e., combinatorial pure exploration with full-bandit feedback (CPE-BL), in which the learner observes full-bandit feedback (i.e. $M_x = x^{\top}$) and gains linear expected reward $x^{\top} \theta$ after each play. In this paper, we first propose a polynomial-time algorithmic framework for the general CPE-PL problem with novel sample complexity analysis. Then, we propose an adaptive algorithm dedicated to the subproblem CPE-BL with better sample complexity. Our work provides a novel polynomial-time solution to simultaneously address limited feedback, general reward function and combinatorial action space including matroids, matchings, and $s$-$t$ paths.
Learning to Factorize and Relight a City
Aug 06, 2020
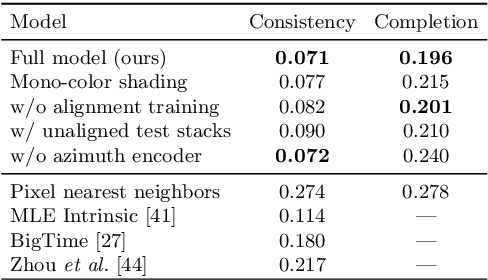


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.
Deep learning method for solving stochastic optimal control problem via stochastic maximum principle
Jul 05, 2020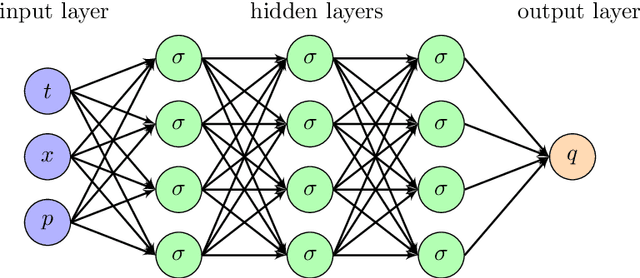

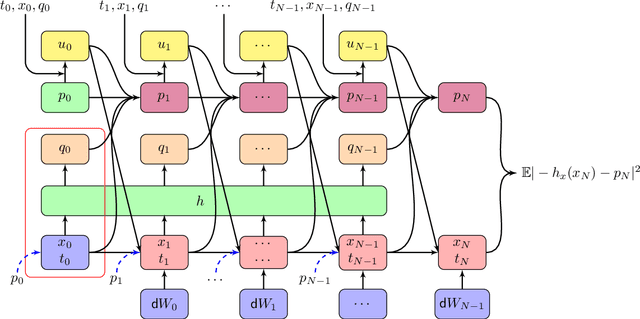
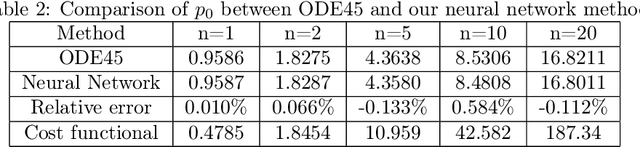
In this paper, we aim to solve the stochastic optimal control problem via deep learning. Through the stochastic maximum principle and its corresponding Hamiltonian system, we propose a framework in which the original control problem is reformulated as a new one. This new stochastic optimal control problem has a quadratic loss function at the terminal time which provides an easier way to build a neural network structure. But the cost is that we must deal with an additional maximum condition. Some numerical examples such as the linear quadratic (LQ) stochastic optimal control problem and the calculation of G-expectation have been studied.