 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Detection of COVID-19 Using Heart Rate and Blood Pressure: Lessons Learned from Patients with ARDS
Nov 12, 2020
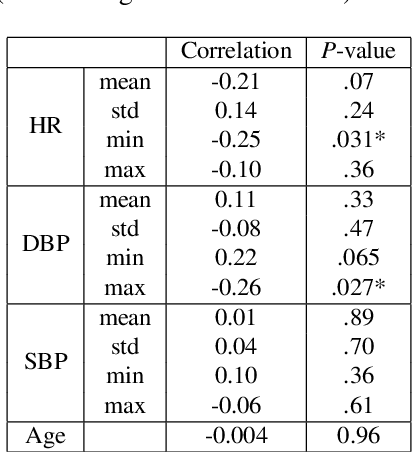
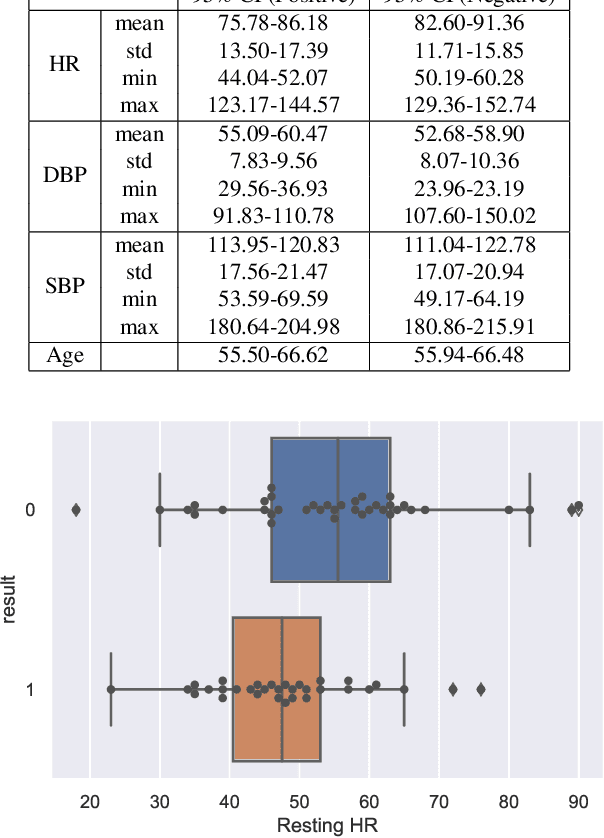
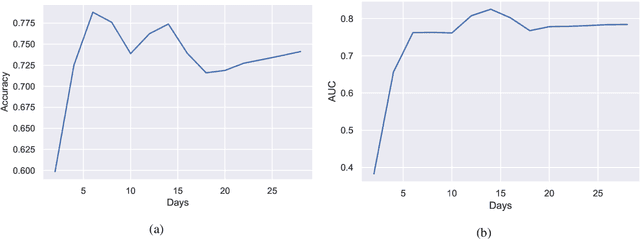
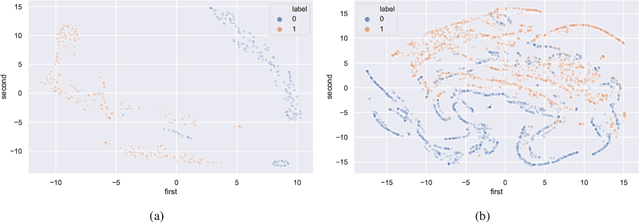
The world has been affected by COVID-19 coronavirus. At the time of this study, the number of infected people in the United States is the highest globally (7.9 million infections). Within the infected population, patients diagnosed with acute respiratory distress syndrome (ARDS) are in more life-threatening circumstances, resulting in severe respiratory system failure. Various studies have investigated the infections to COVID-19 and ARDS by monitoring laboratory metrics and symptoms. Unfortunately, these methods are merely limited to clinical settings, and symptom-based methods are shown to be ineffective. In contrast, vital signs (e.g., heart rate) have been utilized to early-detect different respiratory diseases in ubiquitous health monitoring. We posit that such biomarkers are informative in identifying ARDS patients infected with COVID-19. In this study, we investigate the behavior of COVID-19 on ARDS patients by utilizing simple vital signs. We analyze the long-term daily logs of blood pressure and heart rate associated with 70 ARDS patients admitted to five University of California academic health centers (containing 42506 samples for each vital sign) to distinguish subjects with COVID-19 positive and negative test results. In addition to the statistical analysis, we develop a deep neural network model to extract features from the longitudinal data. Using only the first eight days of the data, our deep learning model is able to achieve 78.79% accuracy to classify the vital signs of ARDS patients infected with COVID-19 versus other ARDS diagnosed patients.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020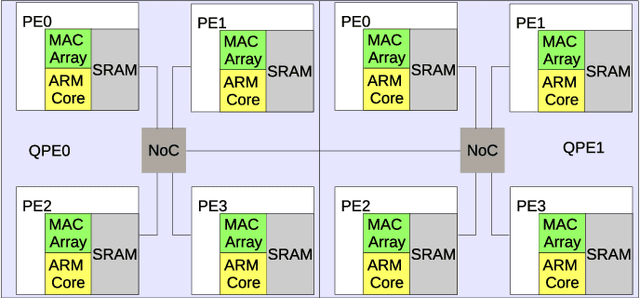
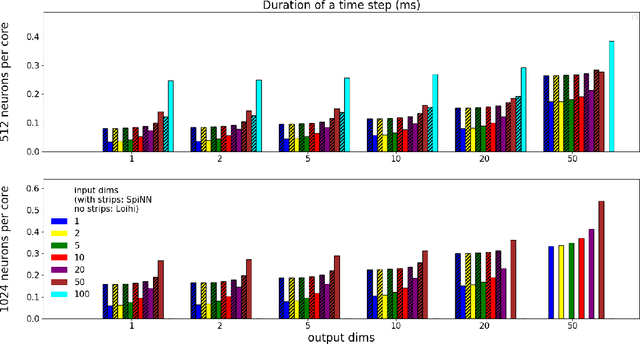
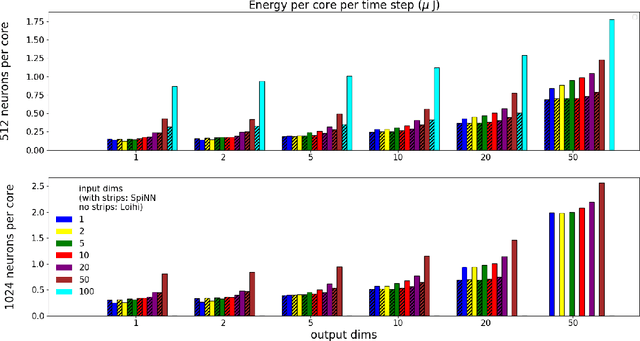
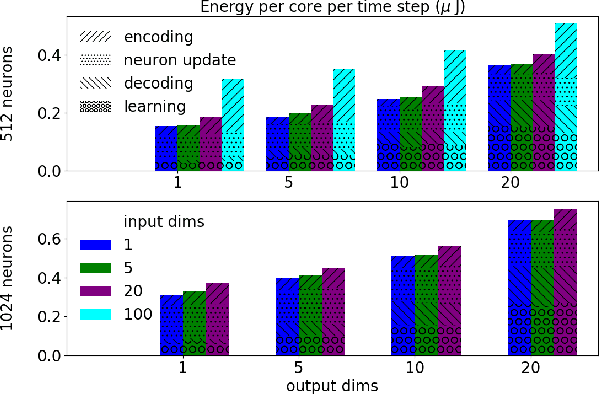
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
Comprehensive Online Network Pruning via Learnable Scaling Factors
Oct 06, 2020



One of the major challenges in deploying deep neural network architectures is their size which has an adverse effect on their inference time and memory requirements. Deep CNNs can either be pruned width-wise by removing filters based on their importance or depth-wise by removing layers and blocks. Width wise pruning (filter pruning) is commonly performed via learnable gates or switches and sparsity regularizers whereas pruning of layers has so far been performed arbitrarily by manually designing a smaller network usually referred to as a student network. We propose a comprehensive pruning strategy that can perform both width-wise as well as depth-wise pruning. This is achieved by introducing gates at different granularities (neuron, filter, layer, block) which are then controlled via an objective function that simultaneously performs pruning at different granularity during each forward pass. Our approach is applicable to wide-variety of architectures without any constraints on spatial dimensions or connection type (sequential, residual, parallel or inception). Our method has resulted in a compression ratio of 70% to 90% without noticeable loss in accuracy when evaluated on benchmark datasets.
Deep Multi-Scale Feature Learning for Defocus Blur Estimation
Sep 24, 2020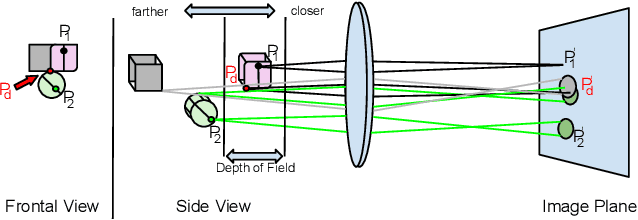
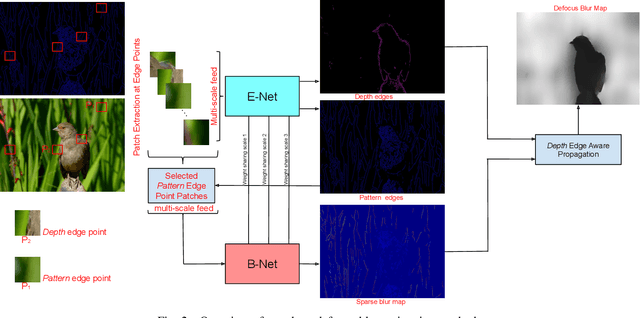

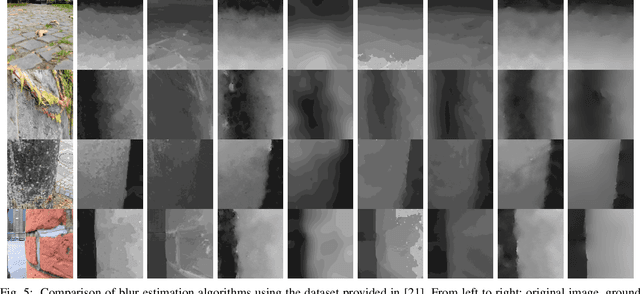
This paper presents an edge-based defocus blur estimation method from a single defocused image. We first distinguish edges that lie at depth discontinuities (called depth edges, for which the blur estimate is ambiguous) from edges that lie at approximately constant depth regions (called pattern edges, for which the blur estimate is well-defined). Then, we estimate the defocus blur amount at pattern edges only, and explore an interpolation scheme based on guided filters that prevents data propagation across the detected depth edges to obtain a dense blur map with well-defined object boundaries. Both tasks (edge classification and blur estimation) are performed by deep convolutional neural networks (CNNs) that share weights to learn meaningful local features from multi-scale patches centered at edge locations. Experiments on naturally defocused images show that the proposed method presents qualitative and quantitative results that outperform state-of-the-art (SOTA) methods, with a good compromise between running time and accuracy.
Multi-modal Experts Network for Autonomous Driving
Sep 18, 2020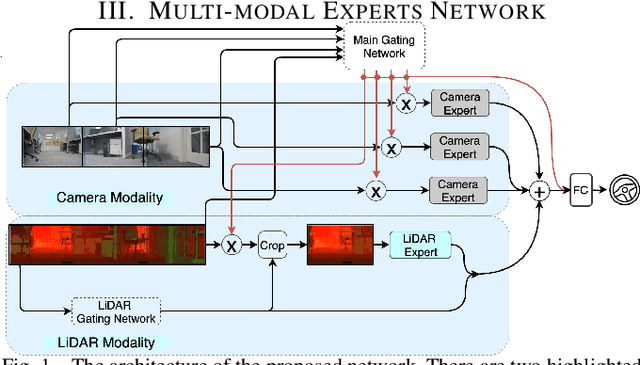
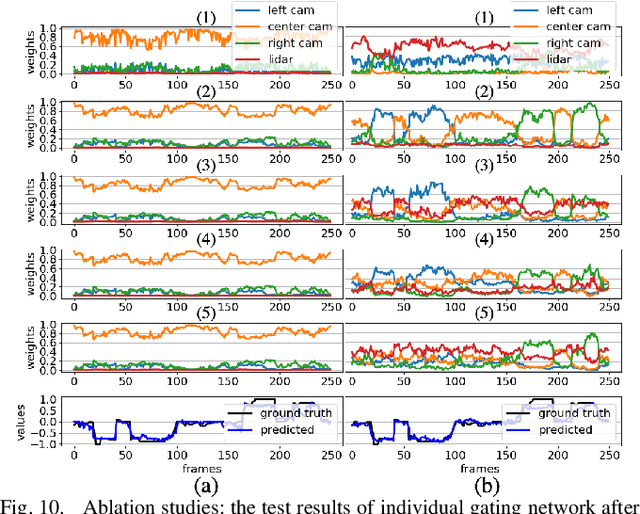
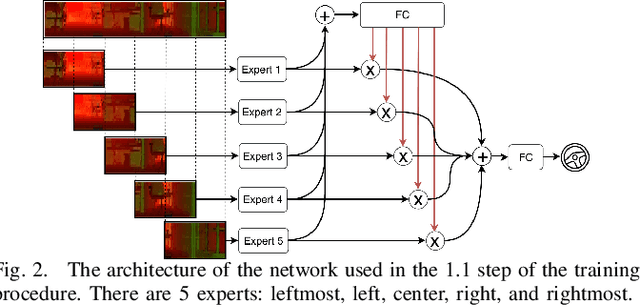
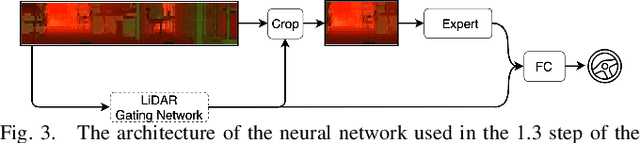
End-to-end learning from sensory data has shown promising results in autonomous driving. While employing many sensors enhances world perception and should lead to more robust and reliable behavior of autonomous vehicles, it is challenging to train and deploy such network and at least two problems are encountered in the considered setting. The first one is the increase of computational complexity with the number of sensing devices. The other is the phenomena of network overfitting to the simplest and most informative input. We address both challenges with a novel, carefully tailored multi-modal experts network architecture and propose a multi-stage training procedure. The network contains a gating mechanism, which selects the most relevant input at each inference time step using a mixed discrete-continuous policy. We demonstrate the plausibility of the proposed approach on our 1/6 scale truck equipped with three cameras and one LiDAR.
* Published at the International Conference on Robotics and Automation (ICRA), 2020
Memory Based Attentive Fusion
Jul 16, 2020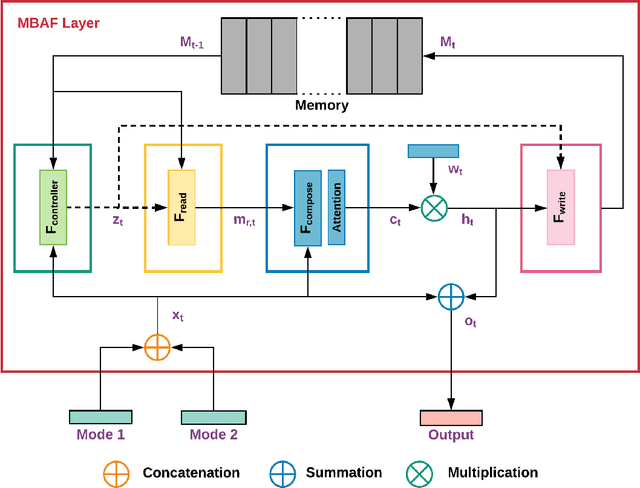
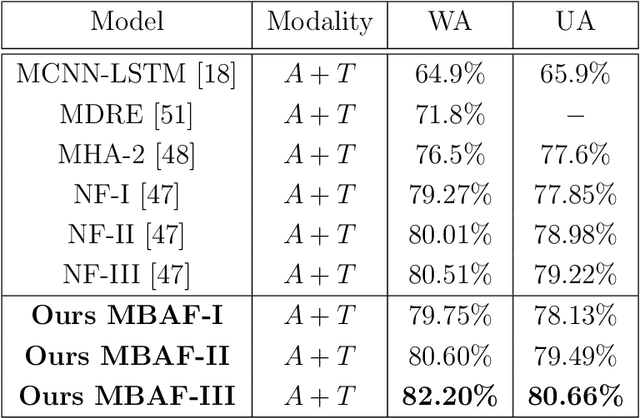
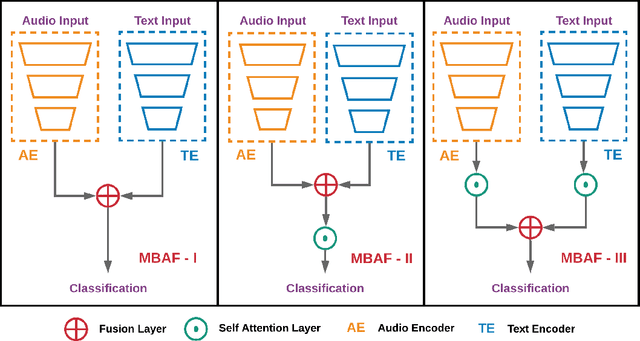
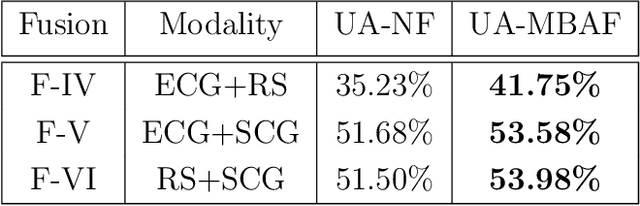
The use of multi-modal data for deep machine learning has shown promise when compared to uni-modal approaches, where fusion of multi-modal features has resulted in improved performance. However, most state-of-the-art methods use naive fusion which processes feature streams from a given time-step and ignores long-term dependencies within the data during fusion. In this paper, we present a novel Memory Based Attentive Fusion (MBAF) layer, which fuses modes by incorporating both the current features and long-term dependencies in the data, thus allowing the model to understand the relative importance of modes over time. We define an explicit memory block within the fusion layer which stores features containing long-term dependencies of the fused data. The inputs to our layer are fused through attentive composition and transformation, and the transformed features are combined with the input to generate the fused layer output. Following existing state-of-the-art methods, we have evaluated the performance and the generalizability of the proposed approach on the IEMOCAP and PhysioNet-CMEBS datasets with different modalities. In our experiments, we replace the naive fusion layer in benchmark networks with our proposed layer to enable a fair comparison. Experimental results indicate that MBAF layer can generalise across different modalities and networks to enhance the fusion and improve performance.
Occams Razor for Big Data? On Detecting Quality in Large Unstructured Datasets
Nov 12, 2020

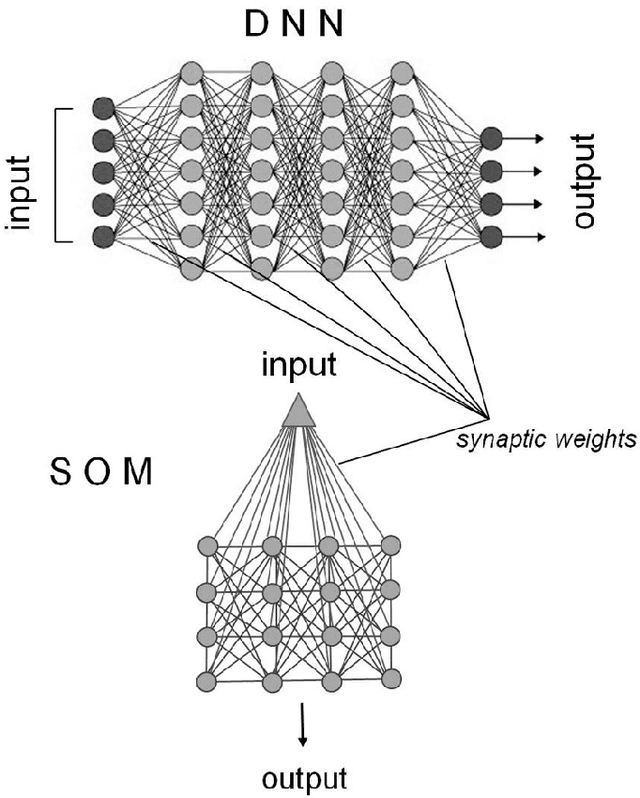
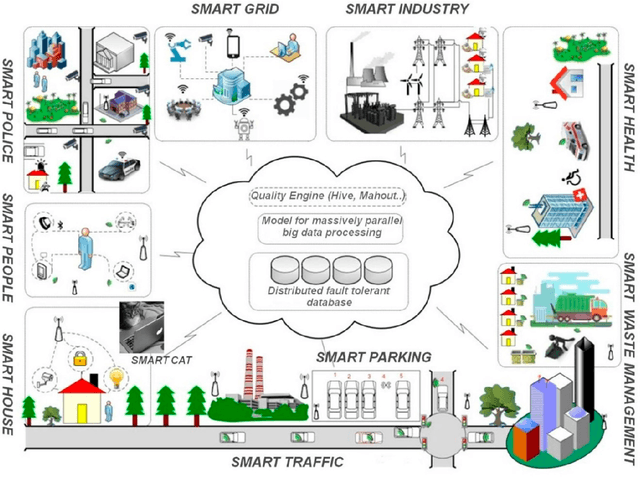
Detecting quality in large unstructured datasets requires capacities far beyond the limits of human perception and communicability and, as a result, there is an emerging trend towards increasingly complex analytic solutions in data science to cope with this problem. This new trend towards analytic complexity represents a severe challenge for the principle of parsimony or Occams Razor in science. This review article combines insight from various domains such as physics, computational science, data engineering, and cognitive science to review the specific properties of big data. Problems for detecting data quality without losing the principle of parsimony are then highlighted on the basis of specific examples. Computational building block approaches for data clustering can help to deal with large unstructured datasets in minimized computation time, and meaning can be extracted rapidly from large sets of unstructured image or video data parsimoniously through relatively simple unsupervised machine learning algorithms. Why we still massively lack in expertise for exploiting big data wisely to extract relevant information for specific tasks, recognize patterns, generate new information, or store and further process large amounts of sensor data is then reviewed; examples illustrating why we need subjective views and pragmatic methods to analyze big data contents are brought forward. The review concludes on how cultural differences between East and West are likely to affect the course of big data analytics, and the development of increasingly autonomous artificial intelligence aimed at coping with the big data deluge in the near future.
Human-Supervised Semi-Autonomous Mobile Manipulators for Safely and Efficiently Executing Machine Tending Tasks
Oct 16, 2020
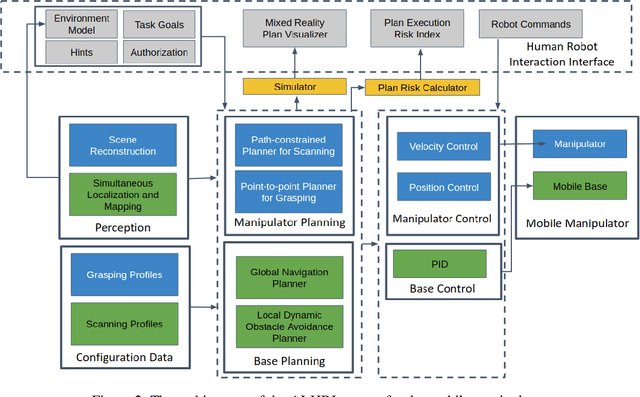
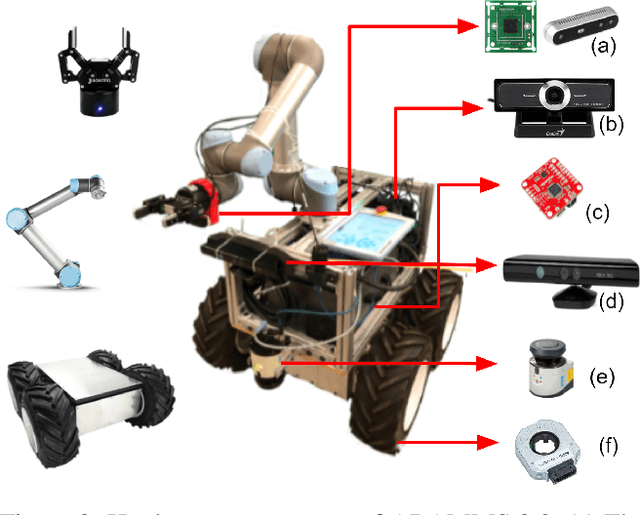
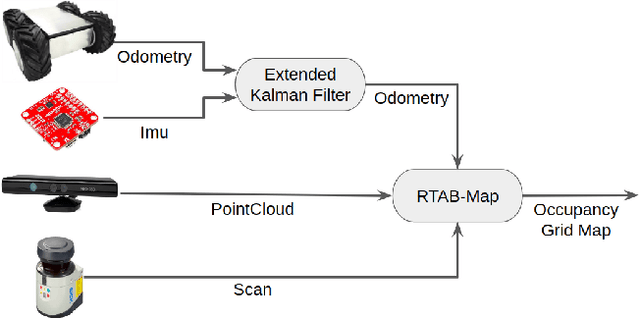
Mobile manipulators can be used for machine tending and material handling tasks in small volume manufacturing applications. These applications usually have semi-structured work environment. The use of a fully autonomous mobile manipulator for such applications can be risky, as an inaccurate model of the workspace may result in damage to expensive equipment. On the other hand, the use of a fully teleoperated mobile manipulator may require a significant amount of operator time. In this paper, a semi-autonomous mobile manipulator is developed for safely and efficiently carrying out machine tending tasks under human supervision. The robot is capable of generating motion plans from the high-level task description and presenting simulation results to the human for approval. The human operator can authorize the robot to execute the automatically generated plan or provide additional input to the planner to refine the plan. If the level of uncertainty in some parts of the workspace model is high, then the human can decide to perform teleoperation to safely execute the task. Our preliminary user trials show that non-expert operators can quickly learn to use the system and perform machine tending tasks.
DeepIntent: ImplicitIntent based Android IDS with E2E Deep Learning architecture
Oct 16, 2020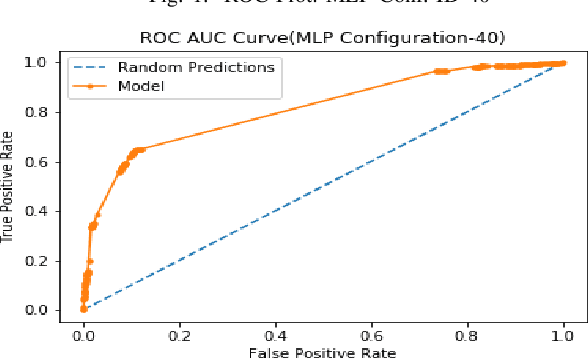

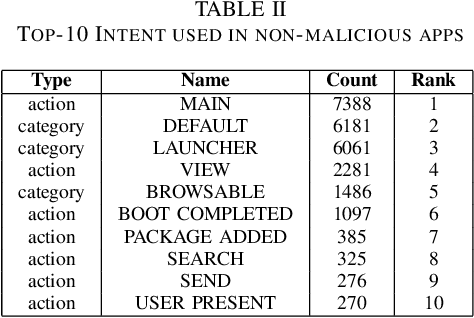
The Intent in Android plays an important role in inter-process and intra-process communications. The implicit Intent that an application could accept are declared in its manifest and are amongst the easiest feature to extract from an apk. Implicit Intents could even be extracted online and in real-time. So far neither the feasibility of developing an Intrusion Detection System solely on implicit Intent has been explored, nor are any benchmarks available of a malware classifier that is based on implicit Intent alone. We demonstrate that despite Intent is implicit and well declared, it can provide very intuitive insights to distinguish malicious from non-malicious applications. We conducted exhaustive experiments with over 40 different end-to-end Deep Learning configurations of Auto-Encoders and Multi-Layer-Perceptron to create a benchmark for a malware classifier that works exclusively on implicit Intent. Using the results from the experiments we create an intrusion detection system using only the implicit Intents and end-to-end Deep Learning architecture. We obtained an area-under-curve statistic of 0.81, and accuracy of 77.2% along with false-positive-rate of 0.11 on Drebin dataset.
Flow-FL: Data-Driven Federated Learning for Spatio-Temporal Predictions in Multi-Robot Systems
Oct 16, 2020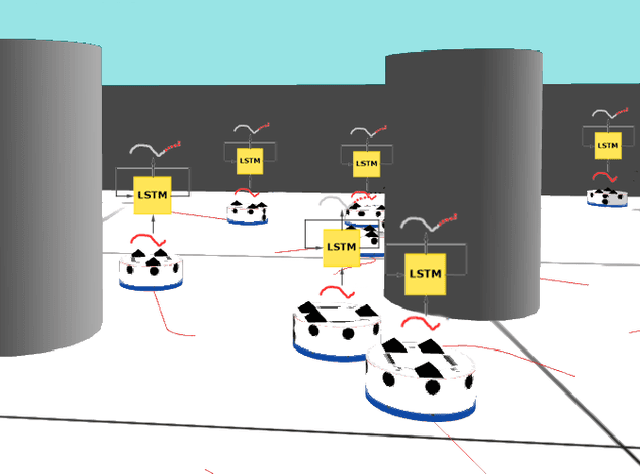
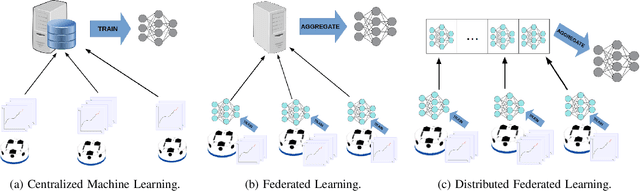
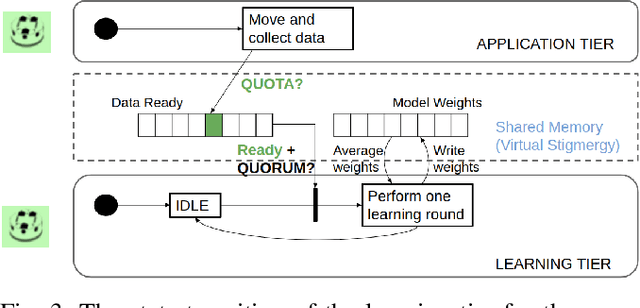
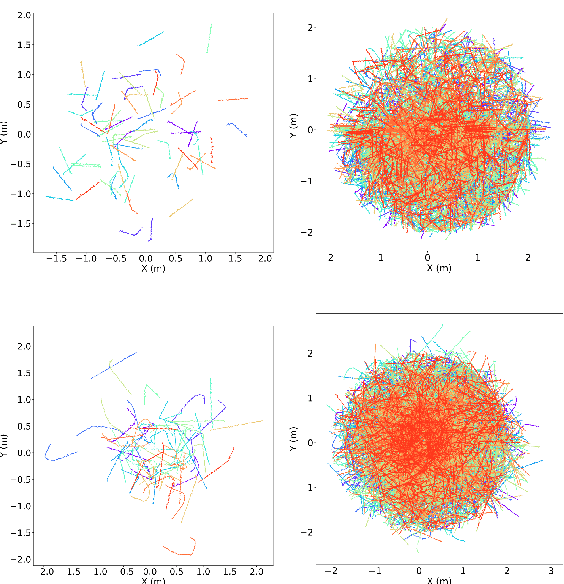
In this paper, we show how the Federated Learning (FL) framework enables learning collectively from distributed data in connected robot teams. This framework typically works with clients collecting data locally, updating neural network weights of their model, and sending updates to a server for aggregation into a global model. We explore the design space of FL by comparing two variants of this concept. The first variant follows the traditional FL approach in which a server aggregates the local models. In the second variant, that we call Flow-FL, the aggregation process is serverless thanks to the use of a gossip-based shared data structure. In both variants, we use a data-driven mechanism to synchronize the learning process in which robots contribute model updates when they collect sufficient data. We validate our approach with an agent trajectory forecasting problem in a multi-agent setting. Using a centralized implementation as a baseline, we study the effects of staggered online data collection, and variations in data flow, number of participating robots, and time delays introduced by the decentralization of the framework in a multi-robot setting.