 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering
Oct 06, 2025Recent multimodal LLMs have shown promise in chart-based visual question answering, but their performance declines sharply on unannotated charts, those requiring precise visual interpretation rather than relying on textual shortcuts. To address this, we introduce ChartAgent, a novel agentic framework that explicitly performs visual reasoning directly within the chart's spatial domain. Unlike textual chain-of-thought reasoning, ChartAgent iteratively decomposes queries into visual subtasks and actively manipulates and interacts with chart images through specialized actions such as drawing annotations, cropping regions (e.g., segmenting pie slices, isolating bars), and localizing axes, using a library of chart-specific vision tools to fulfill each subtask. This iterative reasoning process closely mirrors human cognitive strategies for chart comprehension. ChartAgent achieves state-of-the-art accuracy on the ChartBench and ChartX benchmarks, surpassing prior methods by up to 16.07% absolute gain overall and 17.31% on unannotated, numerically intensive queries. Furthermore, our analyses show that ChartAgent is (a) effective across diverse chart types, (b) achieve the highest scores across varying visual and reasoning complexity levels, and (c) serves as a plug-and-play framework that boosts performance across diverse underlying LLMs. Our work is among the first to demonstrate visually grounded reasoning for chart understanding using tool-augmented multimodal agents.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024



Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations
Nov 20, 2024



State-of-the-art multimodal web agents, powered by Multimodal Large Language Models (MLLMs), can autonomously execute many web tasks by processing user instructions and interacting with graphical user interfaces (GUIs). Current strategies for building web agents rely on (i) the generalizability of underlying MLLMs and their steerability via prompting, and (ii) large-scale fine-tuning of MLLMs on web-related tasks. However, web agents still struggle to automate tasks on unseen websites and domains, limiting their applicability to enterprise-specific and proprietary platforms. Beyond generalization from large-scale pre-training and fine-tuning, we propose building agents for few-shot adaptability using human demonstrations. We introduce the AdaptAgent framework that enables both proprietary and open-weights multimodal web agents to adapt to new websites and domains using few human demonstrations (up to 2). Our experiments on two popular benchmarks -- Mind2Web & VisualWebArena -- show that using in-context demonstrations (for proprietary models) or meta-adaptation demonstrations (for meta-learned open-weights models) boosts task success rate by 3.36% to 7.21% over non-adapted state-of-the-art models, corresponding to a relative increase of 21.03% to 65.75%. Furthermore, our additional analyses (a) show the effectiveness of multimodal demonstrations over text-only ones, (b) shed light on the influence of different data selection strategies during meta-learning on the generalization of the agent, and (c) demonstrate the effect of number of few-shot examples on the web agent's success rate. Overall, our results unlock a complementary axis for developing widely applicable multimodal web agents beyond large-scale pre-training and fine-tuning, emphasizing few-shot adaptability.
FISHNET: Financial Intelligence from Sub-querying, Harmonizing, Neural-Conditioning, Expert Swarms, and Task Planning
Oct 25, 2024



Financial intelligence generation from vast data sources has typically relied on traditional methods of knowledge-graph construction or database engineering. Recently, fine-tuned financial domain-specific Large Language Models (LLMs), have emerged. While these advancements are promising, limitations such as high inference costs, hallucinations, and the complexity of concurrently analyzing high-dimensional financial data, emerge. This motivates our invention FISHNET (Financial Intelligence from Sub-querying, Harmonizing, Neural-Conditioning, Expert swarming, and Task planning), an agentic architecture that accomplishes highly complex analytical tasks for more than 98,000 regulatory filings that vary immensely in terms of semantics, data hierarchy, or format. FISHNET shows remarkable performance for financial insight generation (61.8% success rate over 5.0% Routing, 45.6% RAG R-Precision). We conduct rigorous ablations to empirically prove the success of FISHNET, each agent's importance, and the optimized performance of assembling all agents. Our modular architecture can be leveraged for a myriad of use-cases, enabling scalability, flexibility, and data integrity that are critical for financial tasks.
Sim2Real Docs: Domain Randomization for Documents in Natural Scenes using Ray-traced Rendering
Dec 16, 2021

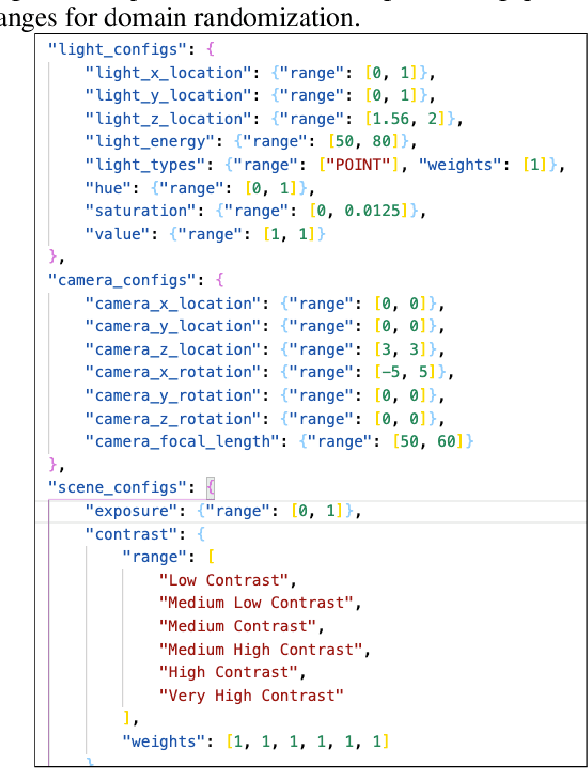
In the past, computer vision systems for digitized documents could rely on systematically captured, high-quality scans. Today, transactions involving digital documents are more likely to start as mobile phone photo uploads taken by non-professionals. As such, computer vision for document automation must now account for documents captured in natural scene contexts. An additional challenge is that task objectives for document processing can be highly use-case specific, which makes publicly-available datasets limited in their utility, while manual data labeling is also costly and poorly translates between use cases. To address these issues we created Sim2Real Docs - a framework for synthesizing datasets and performing domain randomization of documents in natural scenes. Sim2Real Docs enables programmatic 3D rendering of documents using Blender, an open source tool for 3D modeling and ray-traced rendering. By using rendering that simulates physical interactions of light, geometry, camera, and background, we synthesize datasets of documents in a natural scene context. Each render is paired with use-case specific ground truth data specifying latent characteristics of interest, producing unlimited fit-for-task training data. The role of machine learning models is then to solve the inverse problem posed by the rendering pipeline. Such models can be further iterated upon with real-world data by either fine tuning or making adjustments to domain randomization parameters.
Grounded Relational Inference: Domain Knowledge Driven Explainable Autonomous Driving
Feb 23, 2021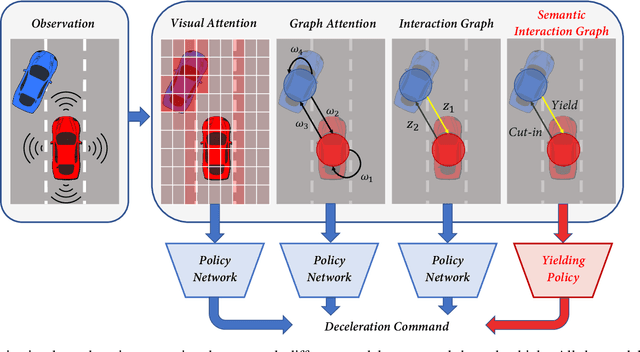
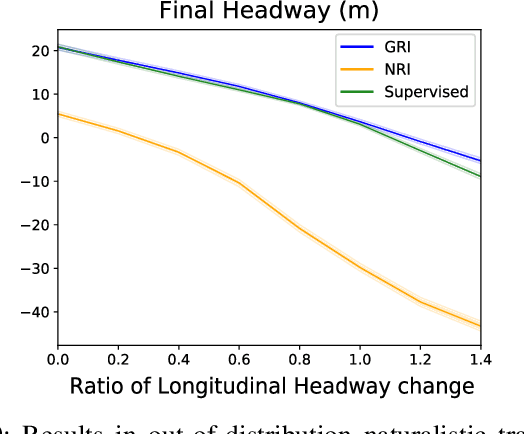
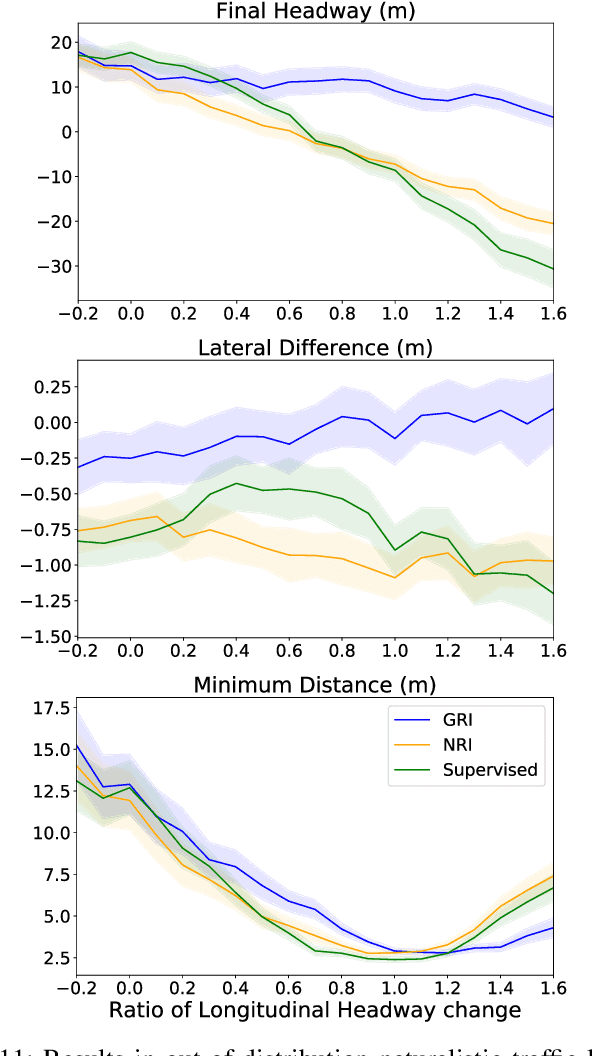
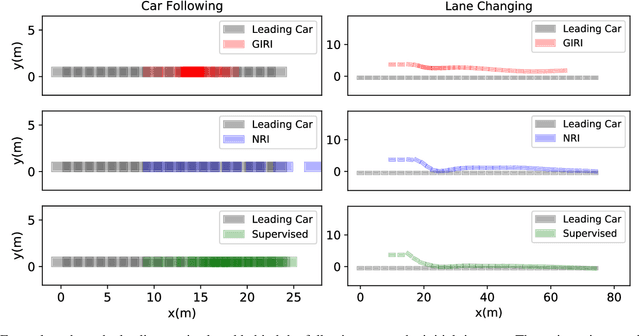
Explainability is essential for autonomous vehicles and other robotics systems interacting with humans and other objects during operation. Humans need to understand and anticipate the actions taken by the machines for trustful and safe cooperation. In this work, we aim to enable the explainability of an autonomous driving system at the design stage by incorporating expert domain knowledge into the model. We propose Grounded Relational Inference (GRI). It models an interactive system's underlying dynamics by inferring an interaction graph representing the agents' relations. We ensure an interpretable interaction graph by grounding the relational latent space into semantic behaviors defined with expert domain knowledge. We demonstrate that it can model interactive traffic scenarios under both simulation and real-world settings, and generate interpretable graphs explaining the vehicle's behavior by their interactions.
Flow-FL: Data-Driven Federated Learning for Spatio-Temporal Predictions in Multi-Robot Systems
Oct 16, 2020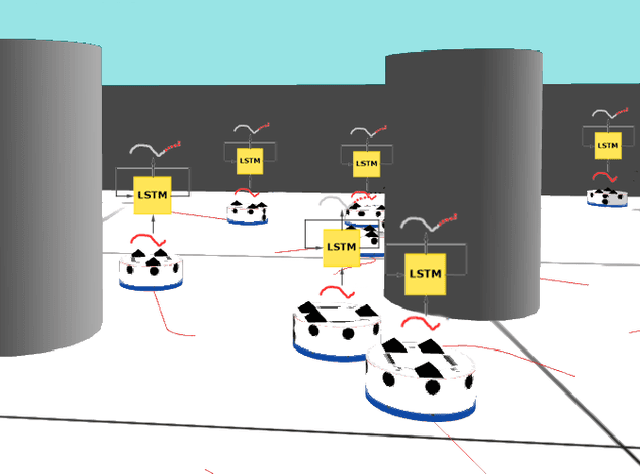
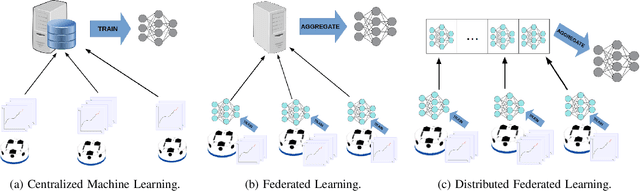
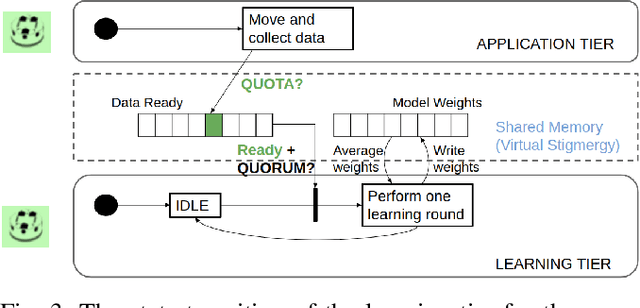
In this paper, we show how the Federated Learning (FL) framework enables learning collectively from distributed data in connected robot teams. This framework typically works with clients collecting data locally, updating neural network weights of their model, and sending updates to a server for aggregation into a global model. We explore the design space of FL by comparing two variants of this concept. The first variant follows the traditional FL approach in which a server aggregates the local models. In the second variant, that we call Flow-FL, the aggregation process is serverless thanks to the use of a gossip-based shared data structure. In both variants, we use a data-driven mechanism to synchronize the learning process in which robots contribute model updates when they collect sufficient data. We validate our approach with an agent trajectory forecasting problem in a multi-agent setting. Using a centralized implementation as a baseline, we study the effects of staggered online data collection, and variations in data flow, number of participating robots, and time delays introduced by the decentralization of the framework in a multi-robot setting.