 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020
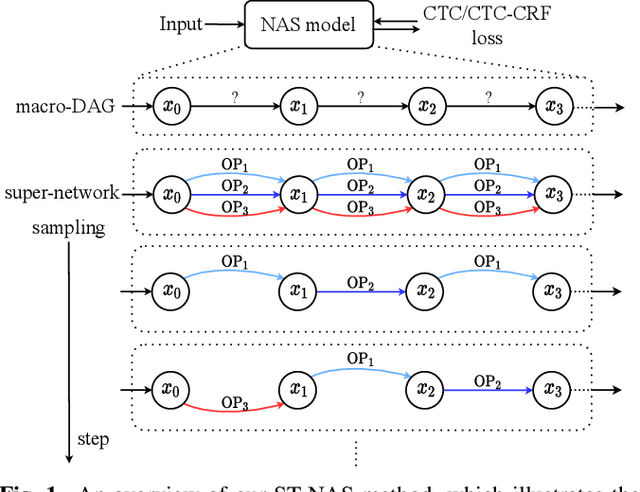
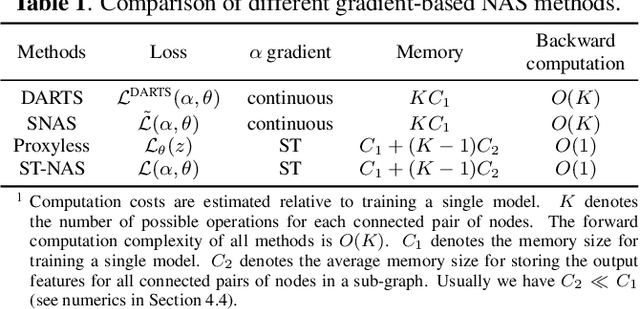
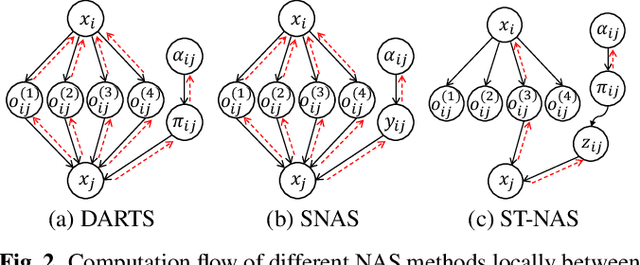
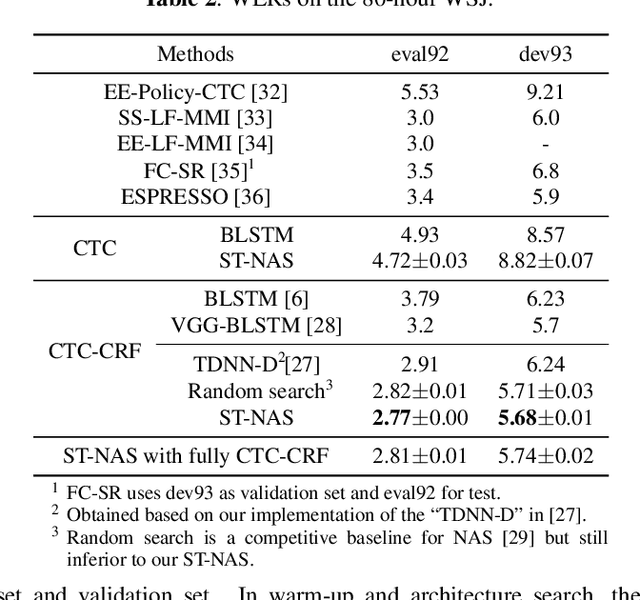
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
Bayesian Learning for Deep Neural Network Adaptation
Dec 14, 2020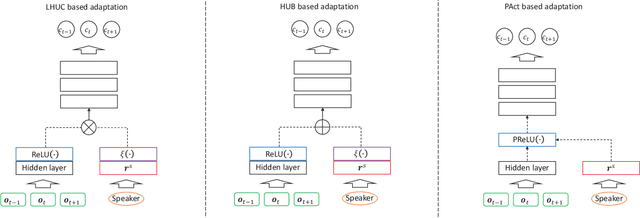
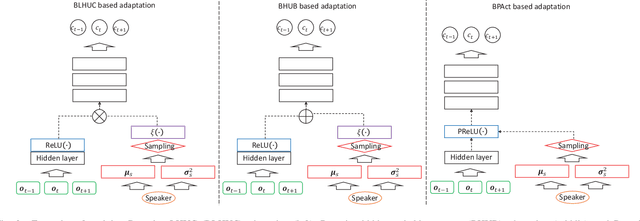
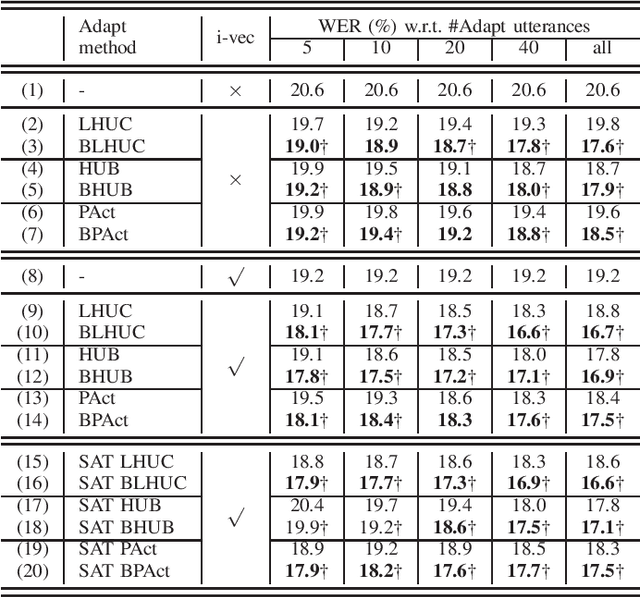

A key task for speech recognition systems is to reduce the mismatch between the training and evaluation data that is often attributable to speaker differences. To this end, speaker adaptation techniques play a vital role to reduce the mismatch. Model-based speaker adaptation approaches often require sufficient amounts of target speaker data to ensure robustness. When the amount of speaker level data is limited, speaker adaptation is prone to overfitting and poor generalization. To address the issue, this paper proposes a full Bayesian learning based DNN speaker adaptation framework to model speaker-dependent (SD) parameter uncertainty given limited speaker specific adaptation data. This framework is investigated in three forms of model based DNN adaptation techniques: Bayesian learning of hidden unit contributions (BLHUC), Bayesian parameterized activation functions (BPAct), and Bayesian hidden unit bias vectors (BHUB). In all three Bayesian adaptation methods, deterministic SD parameters are replaced by latent variable posterior distributions to be learned for each speaker, whose parameters are efficiently estimated using a variational inference based approach. Experiments conducted on 300-hour speed perturbed Switchboard corpus trained LF-MMI factored TDNN/CNN-TDNN systems featuring i-vector speaker adaptation suggest the proposed Bayesian adaptation approaches consistently outperform the adapted systems using deterministic parameters on the NIST Hub5'00 and RT03 evaluation sets in both unsupervised test time speaker adaptation and speaker adaptive training. The efficacy of the proposed Bayesian adaptation techniques is further demonstrated in a comparison against the state-of-the-art performance obtained on the same task using the most recent hybrid and end-to-end systems reported in the literature.
Identifying Properties of Real-World Optimisation Problems through a Questionnaire
Nov 11, 2020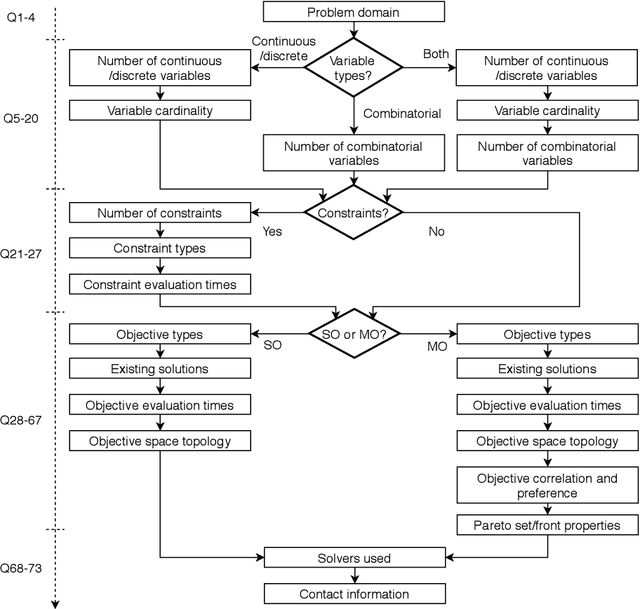
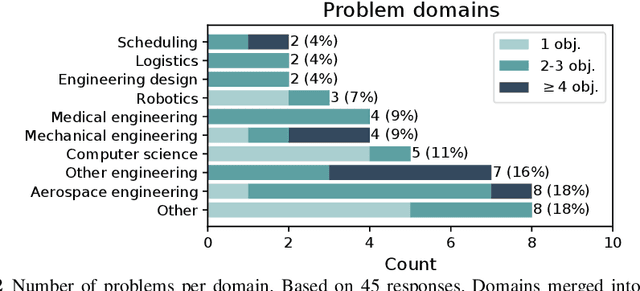
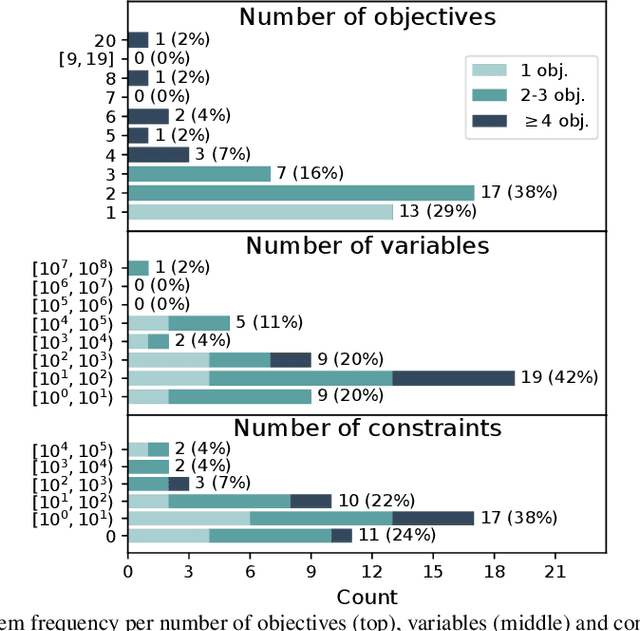
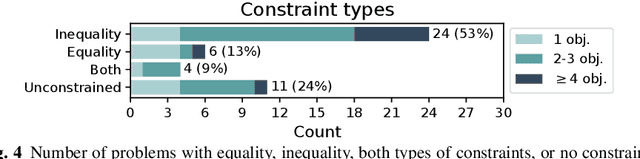
Optimisation algorithms are commonly compared on benchmarks to get insight into performance differences. However, it is not clear how closely benchmarks match the properties of real-world problems because these properties are largely unknown. This work investigates the properties of real-world problems through a questionnaire to enable the design of future benchmark problems that more closely resemble those found in the real world. The results, while not representative, show that many problems possess at least one of the following properties: they are constrained, deterministic, have only continuous variables, require substantial computation times for both the objectives and the constraints, or allow a limited number of evaluations. Properties like known optimal solutions and analytical gradients are rarely available, limiting the options in guiding the optimisation process. These are all important aspects to consider when designing realistic benchmark problems. At the same time, objective functions are often reported to be black-box and since many problem properties are unknown the design of realistic benchmarks is difficult. To further improve the understanding of real-world problems, readers working on a real-world optimisation problem are encouraged to fill out the questionnaire: https://tinyurl.com/opt-survey
An ensemble-based approach by fine-tuning the deep transfer learning models to classify pneumonia from chest X-ray images
Nov 11, 2020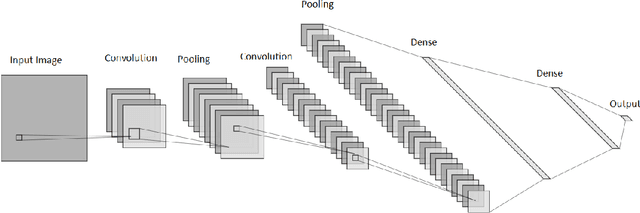
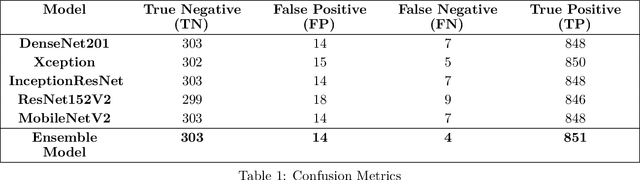
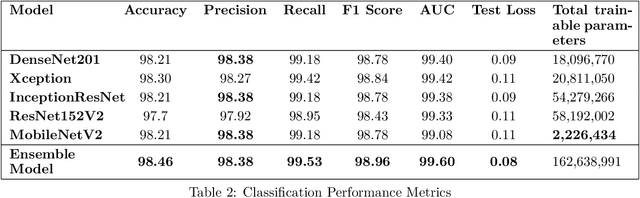
Pneumonia is caused by viruses, bacteria, or fungi that infect the lungs, which, if not diagnosed, can be fatal and lead to respiratory failure. More than 250,000 individuals in the United States, mainly adults, are diagnosed with pneumonia each year, and 50,000 die from the disease. Chest Radiography (X-ray) is widely used by radiologists to detect pneumonia. It is not uncommon to overlook pneumonia detection for a well-trained radiologist, which triggers the need for improvement in the diagnosis's accuracy. In this work, we propose using transfer learning, which can reduce the neural network's training time and minimize the generalization error. We trained, fine-tuned the state-of-the-art deep learning models such as InceptionResNet, MobileNetV2, Xception, DenseNet201, and ResNet152V2 to classify pneumonia accurately. Later, we created a weighted average ensemble of these models and achieved a test accuracy of 98.46%, precision of 98.38%, recall of 99.53%, and f1 score of 98.96%. These performance metrics of accuracy, precision, and f1 score are at their highest levels ever reported in the literature, which can be considered a benchmark for the accurate pneumonia classification.
Fusion of Deep and Non-Deep Methods for Fast Super-Resolution of Satellite Images
Aug 03, 2020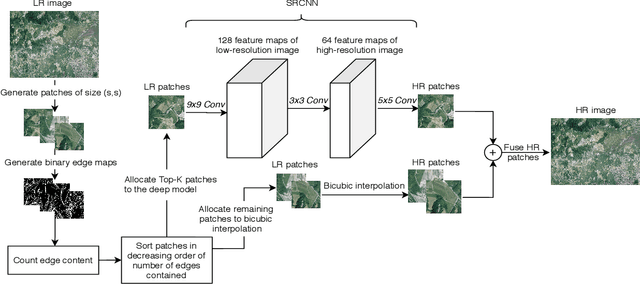
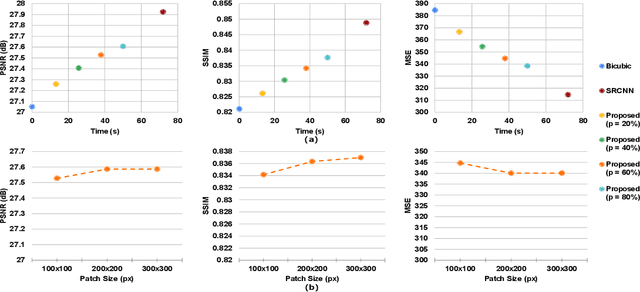

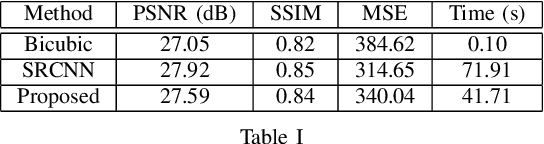
In the emerging commercial space industry there is a drastic increase in access to low cost satellite imagery. The price for satellite images depends on the sensor quality and revisit rate. This work proposes to bridge the gap between image quality and the price by improving the image quality via super-resolution (SR). Recently, a number of deep SR techniques have been proposed to enhance satellite images. However, none of these methods utilize the region-level context information, giving equal importance to each region in the image. This, along with the fact that most state-of-the-art SR methods are complex and cumbersome deep models, the time taken to process very large satellite images can be impractically high. We, propose to handle this challenge by designing an SR framework that analyzes the regional information content on each patch of the low-resolution image and judiciously chooses to use more computationally complex deep models to super-resolve more structure-rich regions on the image, while using less resource-intensive non-deep methods on non-salient regions. Through extensive experiments on a large satellite image, we show substantial decrease in inference time while achieving similar performance to that of existing deep SR methods over several evaluation measures like PSNR, MSE and SSIM.
Accelerating Probabilistic Volumetric Mapping using Ray-Tracing Graphics Hardware
Nov 20, 2020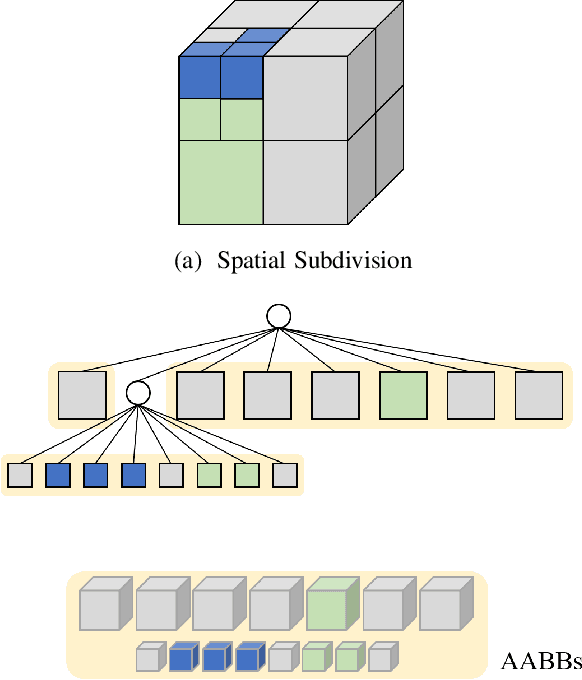
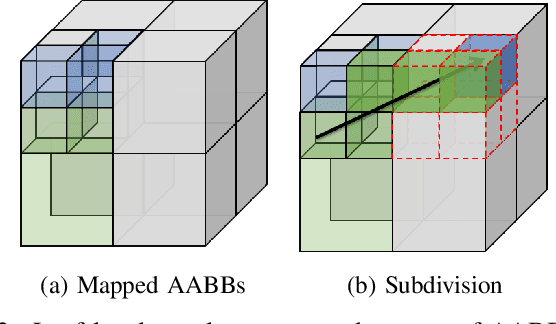
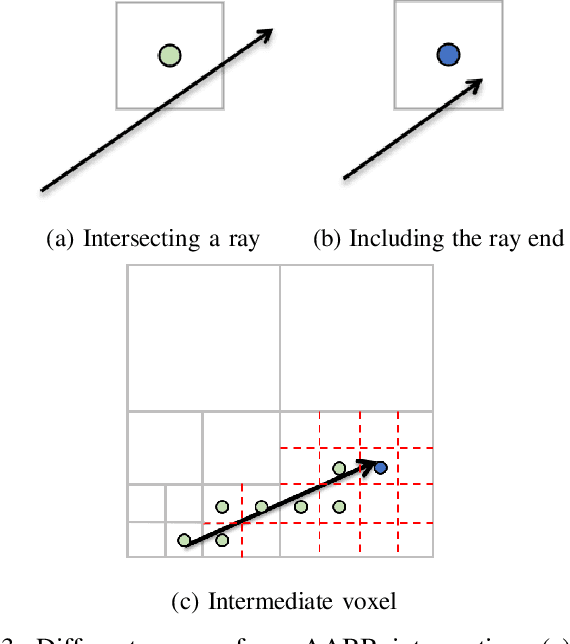
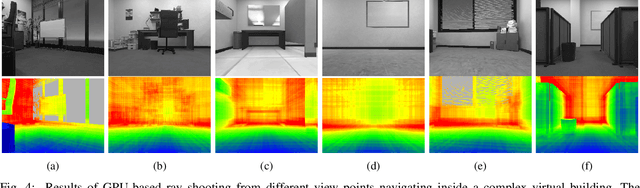
Probabilistic volumetric mapping (PVM) represents a 3D environmental map for an autonomous robotic navigational task. A popular implementation such as Octomap is widely used in the robotics community for such a purpose. The Octomap relies on octree to represent a PVM and its main bottleneck lies in massive ray-shooting to determine the occupancy of the underlying volumetric voxel grids. In this paper, we propose GPU-based ray shooting to drastically improve the ray shooting performance in Octomap. Our main idea is based on the use of recent ray-tracing RTX GPU, mainly designed for real-time photo-realistic computer graphics and the accompanying graphics API, known as DXR. Our ray-shooting first maps leaf-level voxels in the given octree to a set of axis-aligned bounding boxes (AABBs) and employ massively parallel ray shooting on them using GPUs to find free and occupied voxels. These are fed back into CPU to update the voxel occupancy and restructure the octree. In our experiments, we have observed more than three-orders-of-magnitude performance improvement in terms of ray shooting using ray-tracing RTX GPU over a state-of-the-art Octomap CPU implementation, where the benchmarking environments consist of more than 77K points and 25K~34K voxel grids.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 31, 2020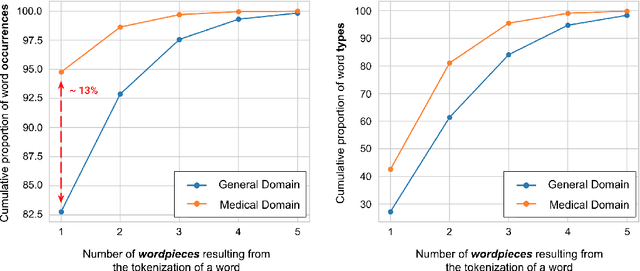

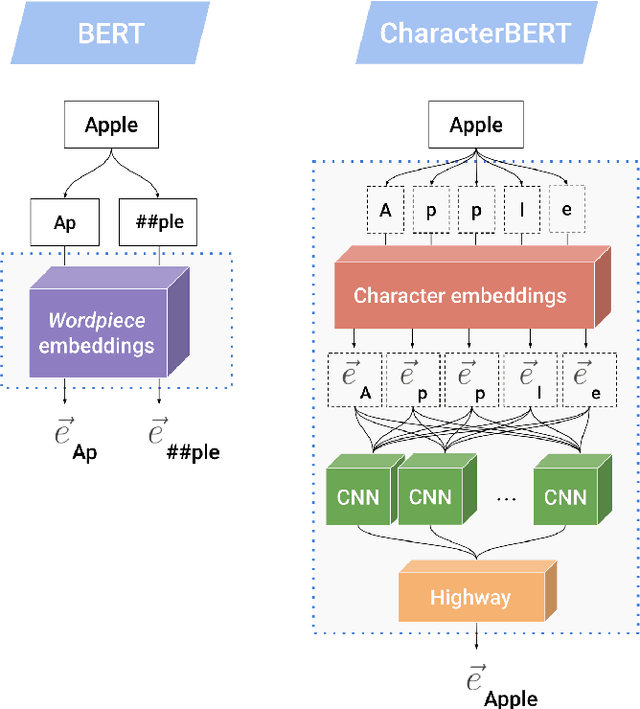
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system despite it not being intrinsically linked to the notion of Transformers. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
A spectral algorithm for robust regression with subgaussian rates
Jul 12, 2020
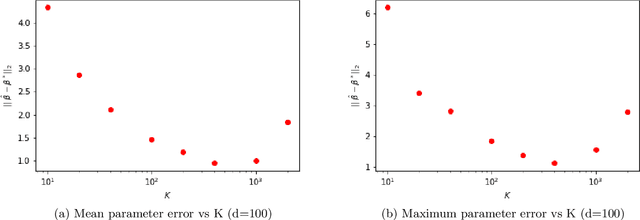
We study a new linear up to quadratic time algorithm for linear regression in the absence of strong assumptions on the underlying distributions of samples, and in the presence of outliers. The goal is to design a procedure which comes with actual working code that attains the optimal sub-gaussian error bound even though the data have only finite moments (up to $L_4$) and in the presence of possibly adversarial outliers. A polynomial-time solution to this problem has been recently discovered but has high runtime due to its use of Sum-of-Square hierarchy programming. At the core of our algorithm is an adaptation of the spectral method introduced for the mean estimation problem to the linear regression problem. As a by-product we established a connection between the linear regression problem and the furthest hyperplane problem. From a stochastic point of view, in addition to the study of the classical quadratic and multiplier processes we introduce a third empirical process that comes naturally in the study of the statistical properties of the algorithm.
Nonlinear MPC for Collision Avoidance and Controlof UAVs With Dynamic Obstacles
Aug 03, 2020



This article proposes a Novel Nonlinear Model Predictive Control (NMPC) for navigation and obstacle avoidance of an Unmanned Aerial Vehicle (UAV). The proposed NMPC formulation allows for a fully parametric obstacle trajectory, while in this article we apply a classification scheme to differentiate between different kinds of trajectories to predict future obstacle positions. The trajectory calculation is done from an initial condition, and fed to the NMPC as an additional input. The solver used is the nonlinear, non-convex solver Proximal Averaged Newton for Optimal Control (PANOC) and its associated software OpEn (Optimization Engine), in which we apply a penalty method to properly consider the obstacles and other constraints during navigation. The proposed NMPC scheme allows for real-time solutions using a sampling time of 50 ms and a two second prediction of both the obstacle trajectory and the NMPC problem, which implies that the scheme can be considered as a local path-planner. This paper will present the NMPC cost function and constraint formulation, as well as the methodology of dealing with the dynamic obstacles. We include multiple laboratory experiments to demonstrate the efficacy of the proposed control architecture, and to show that the proposed method delivers fast and computationally stable solutions to the dynamic obstacle avoidance scenarios.
* 8 pages, 10 figures
Multi-Label Classification Using Link Prediction
Nov 11, 2020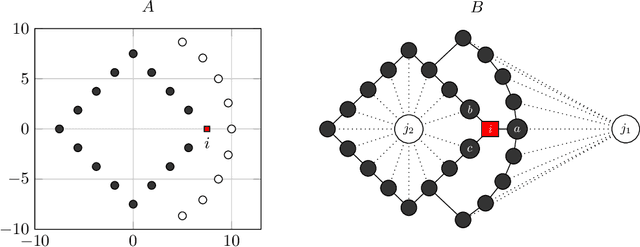
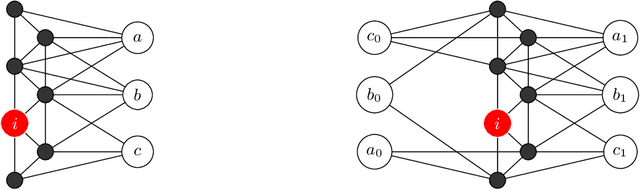

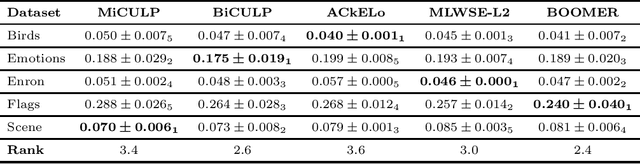
Solving classification with graph methods has gained huge popularity in recent years. This is due to the fact that the data can be intuitively modeled with graphs to utilize high level features to aid in solving the classification problem. CULP which is short for Classification Using Link Prediction is a graph-based classifier. This classifier utilizes the graph representation of the data and transforms the problem to that of link prediction where we try to find the link between an unlabeled node and the proper class node for it. CULP proved to be highly accurate classifier and it has the power to predict the labels in near constant time. A variant of the classification problem is multi-label classification which tackles this problem for multi-label data where an instance can have multiple labels associated to it. In this work, we extend the CULP algorithm to address this problem. Our proposed extensions conveys the powers of CULP and its intuitive representation of the data in to the multi-label domain and in comparison to some of the cutting edge multi-label classifiers, yield competitive results.