 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Learning Approach for COVID-19 Trend Prediction
Aug 09, 2020
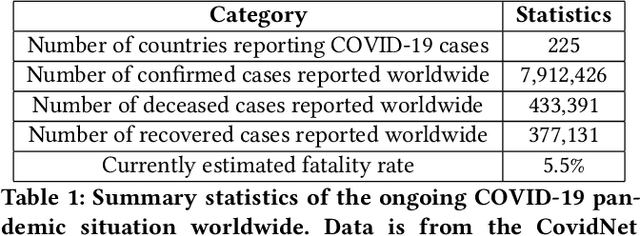
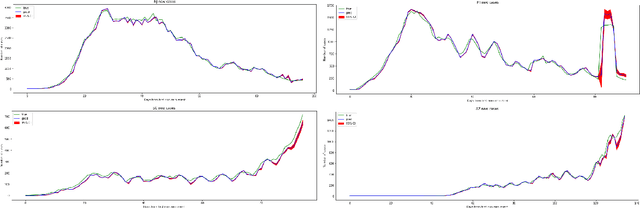
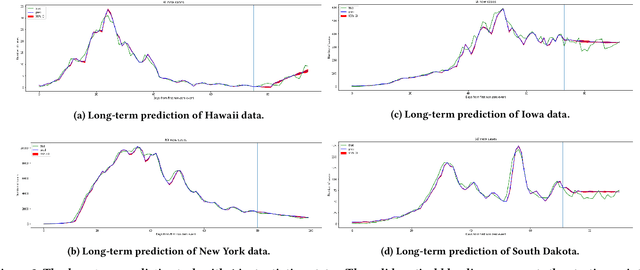
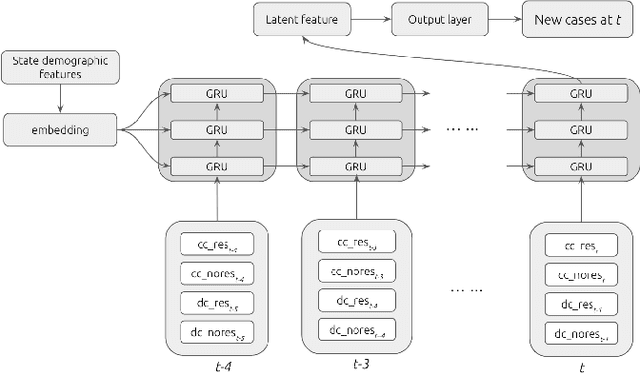
In this work, we developed a deep learning model-based approach to forecast the spreading trend of SARS-CoV-2 in the United States. We implemented the designed model using the United States to confirm cases and state demographic data and achieved promising trend prediction results. The model incorporates demographic information and epidemic time-series data through a Gated Recurrent Unit structure. The identification of dominating demographic factors is delivered in the end.
Pair-view Unsupervised Graph Representation Learning
Dec 11, 2020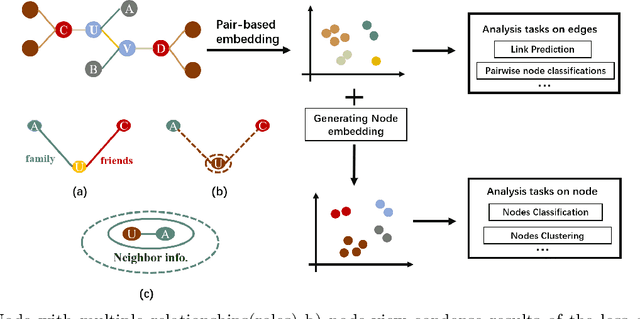
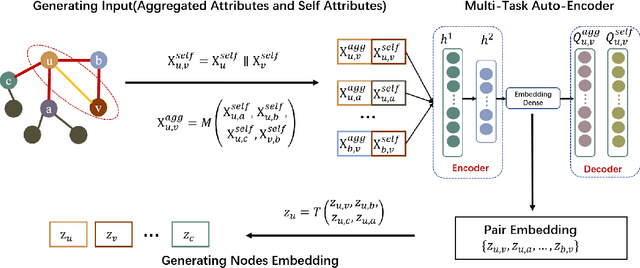
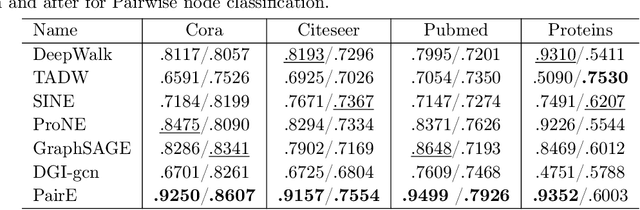
Low-dimension graph embeddings have proved extremely useful in various downstream tasks in large graphs, e.g., link-related content recommendation and node classification tasks, etc. Most existing embedding approaches take nodes as the basic unit for information aggregation, e.g., node perception fields in GNN or con-textual nodes in random walks. The main drawback raised by such node-view is its lack of support for expressing the compound relationships between nodes, which results in the loss of a certain degree of graph information during embedding. To this end, this paper pro-poses PairE(Pair Embedding), a solution to use "pair", a higher level unit than a "node" as the core for graph embeddings. Accordingly, a multi-self-supervised auto-encoder is designed to fulfill two pretext tasks, to reconstruct the feature distribution for respective pairs and their surrounding context. PairE has three major advantages: 1) Informative, embedding beyond node-view are capable to preserve richer information of the graph; 2) Simple, the solutions provided by PairE are time-saving, storage-efficient, and require the fewer hyper-parameters; 3) High adaptability, with the introduced translator operator to map pair embeddings to the node embeddings, PairE can be effectively used in both the link-based and the node-based graph analysis. Experiment results show that PairE consistently outperforms the state of baselines in all four downstream tasks, especially with significant edges in the link-prediction and multi-label node classification tasks.
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
Sep 29, 2020
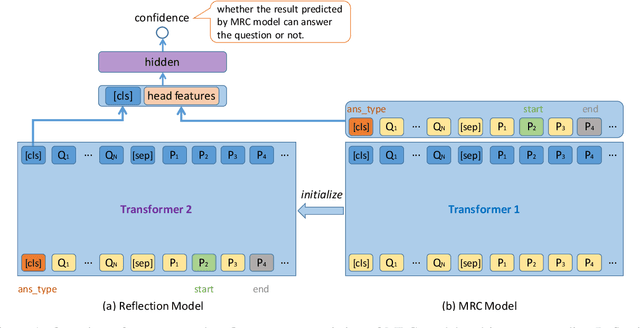

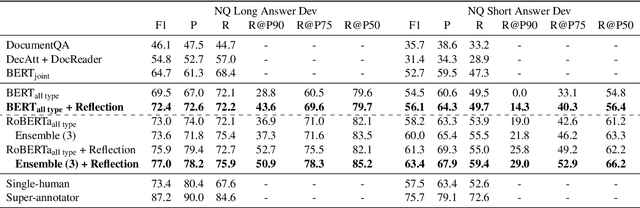
The Natural Questions (NQ) benchmark set brings new challenges to Machine Reading Comprehension: the answers are not only at different levels of granularity (long and short), but also of richer types (including no-answer, yes/no, single-span and multi-span). In this paper, we target at this challenge and handle all answer types systematically. In particular, we propose a novel approach called Reflection Net which leverages a two-step training procedure to identify the no-answer and wrong-answer cases. Extensive experiments are conducted to verify the effectiveness of our approach. At the time of paper writing (May.~20,~2020), our approach achieved the top 1 on both long and short answer leaderboard, with F1 scores of 77.2 and 64.1, respectively.
Human Engagement Providing Evaluative and Informative Advice for Interactive Reinforcement Learning
Sep 21, 2020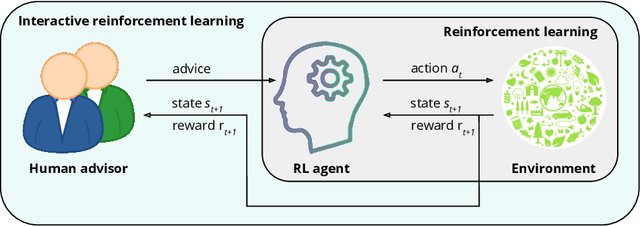

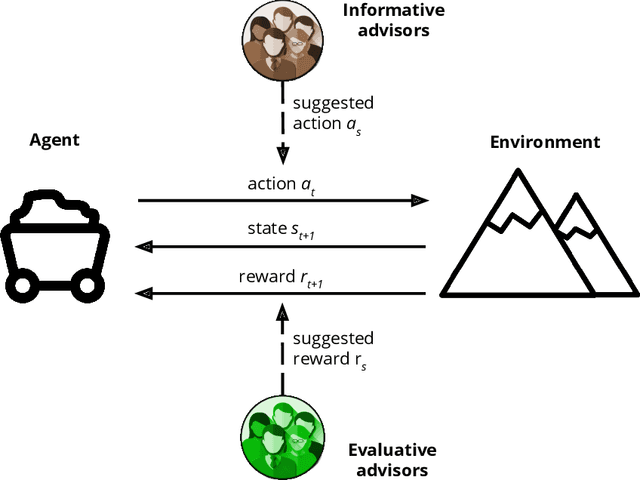
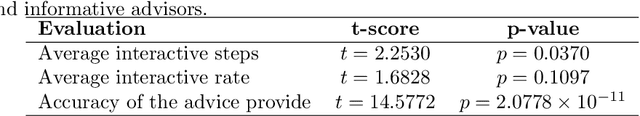
Reinforcement learning is an approach used by intelligent agents to autonomously learn new skills. Although reinforcement learning has been demonstrated to be an effective learning approach in several different contexts, a common drawback exhibited is the time needed in order to satisfactorily learn a task, especially in large state-action spaces. To address this issue, interactive reinforcement learning proposes the use of externally-sourced information in order to speed up the learning process. Up to now, different information sources have been used to give advice to the learner agent, among them human-sourced advice. When interacting with a learner agent, humans may provide either evaluative or informative advice. From the agent's perspective these styles of interaction are commonly referred to as reward-shaping and policy-shaping respectively. Evaluation requires the human to provide feedback on the prior action performed, while informative advice they provide advice on the best action to select for a given situation. Prior research has focused on the effect of human-sourced advice on the interactive reinforcement learning process, specifically aiming to improve the learning speed of the agent, while reducing the engagement with the human. This work presents an experimental setup for a human-trial designed to compare the methods people use to deliver advice in term of human engagement. Obtained results show that users giving informative advice to the learner agents provide more accurate advice, are willing to assist the learner agent for a longer time, and provide more advice per episode. Additionally, self-evaluation from participants using the informative approach has indicated that the agent's ability to follow the advice is higher, and therefore, they feel their own advice to be of higher accuracy when compared to people providing evaluative advice.
A Data-driven Understanding of COVID-19 Dynamics Using Sequential Genetic Algorithm Based Probabilistic Cellular Automata
Aug 27, 2020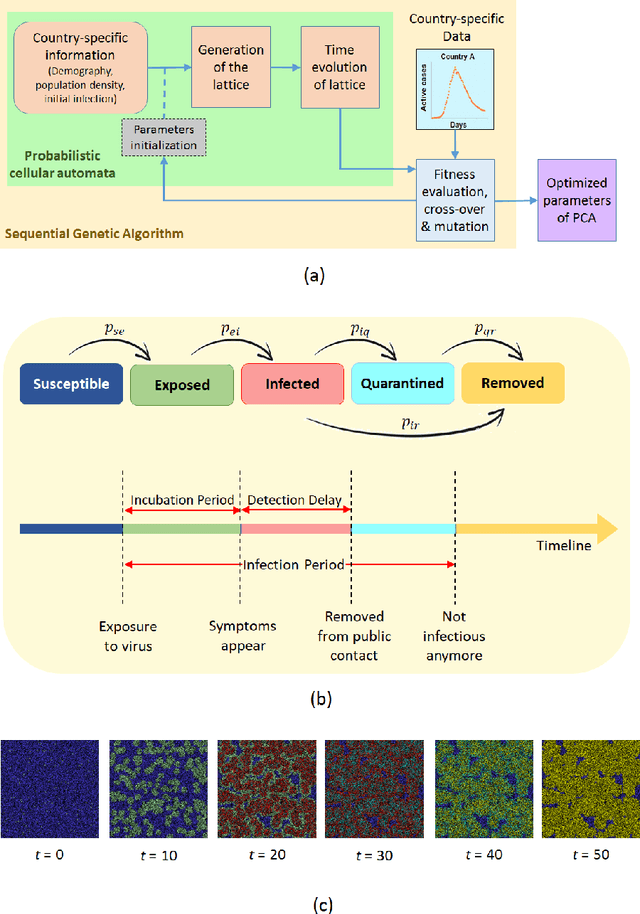

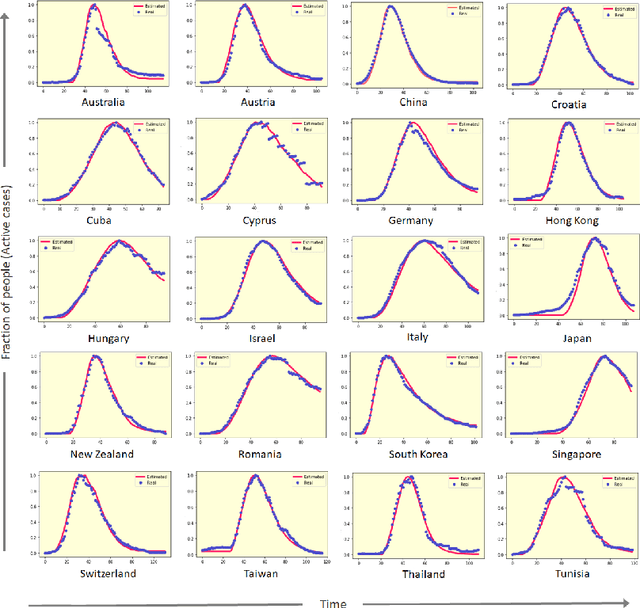
COVID-19 pandemic is severely impacting the lives of billions across the globe. Even after taking massive protective measures like nation-wide lockdowns, discontinuation of international flight services, rigorous testing etc., the infection spreading is still growing steadily, causing thousands of deaths and serious socio-economic crisis. Thus, the identification of the major factors of this infection spreading dynamics is becoming crucial to minimize impact and lifetime of COVID-19 and any future pandemic. In this work, a probabilistic cellular automata based method has been employed to model the infection dynamics for a significant number of different countries. This study proposes that for an accurate data-driven modeling of this infection spread, cellular automata provides an excellent platform, with a sequential genetic algorithm for efficiently estimating the parameters of the dynamics. To the best of our knowledge, this is the first attempt to understand and interpret COVID-19 data using optimized cellular automata, through genetic algorithm. It has been demonstrated that the proposed methodology can be flexible and robust at the same time, and can be used to model the daily active cases, total number of infected people and total death cases through systematic parameter estimation. Elaborate analyses for COVID-19 statistics of forty countries from different continents have been performed, with markedly divergent time evolution of the infection spreading because of demographic and socioeconomic factors. The substantial predictive power of this model has been established with conclusions on the key players in this pandemic dynamics.
Cost-to-Go Function Generating Networks for High Dimensional Motion Planning
Dec 10, 2020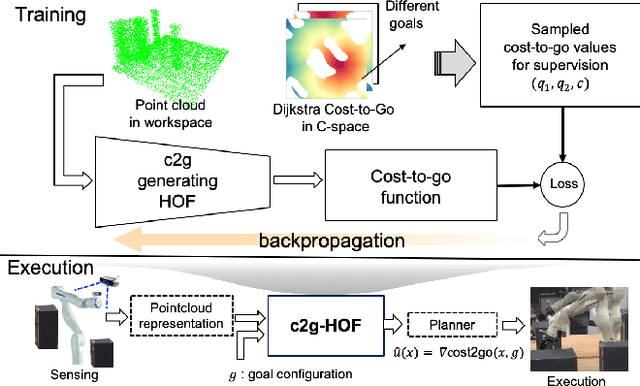
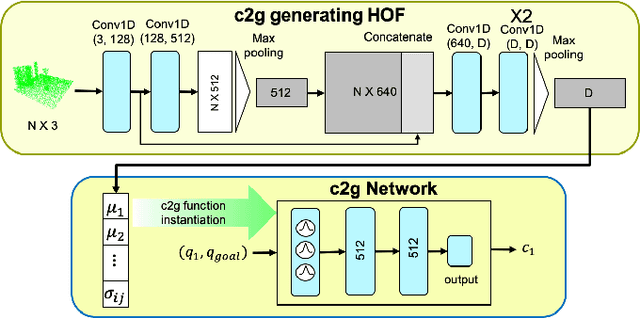
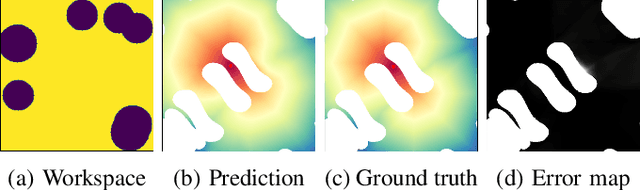
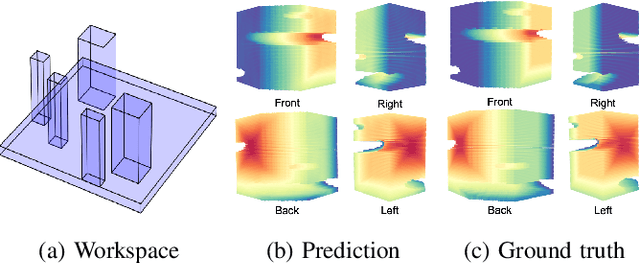
This paper presents c2g-HOF networks which learn to generate cost-to-go functions for manipulator motion planning. The c2g-HOF architecture consists of a cost-to-go function over the configuration space represented as a neural network (c2g-network) as well as a Higher Order Function (HOF) network which outputs the weights of the c2g-network for a given input workspace. Both networks are trained end-to-end in a supervised fashion using costs computed from traditional motion planners. Once trained, c2g-HOF can generate a smooth and continuous cost-to-go function directly from workspace sensor inputs (represented as a point cloud in 3D or an image in 2D). At inference time, the weights of the c2g-network are computed very efficiently and near-optimal trajectories are generated by simply following the gradient of the cost-to-go function. We compare c2g-HOF with traditional planning algorithms for various robots and planning scenarios. The experimental results indicate that planning with c2g-HOF is significantly faster than other motion planning algorithms, resulting in orders of magnitude improvement when including collision checking. Furthermore, despite being trained from sparsely sampled trajectories in configuration space, c2g-HOF generalizes to generate smoother, and often lower cost, trajectories. We demonstrate cost-to-go based planning on a 7 DoF manipulator arm where motion planning in a complex workspace requires only 0.13 seconds for the entire trajectory.
Simple and optimal methods for stochastic variational inequalities, I: operator extrapolation
Nov 15, 2020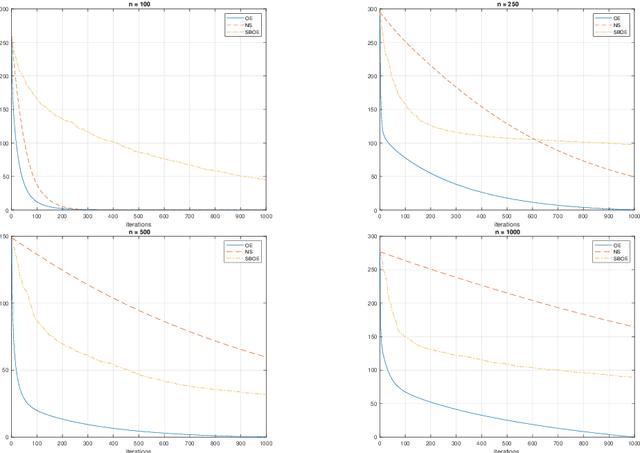
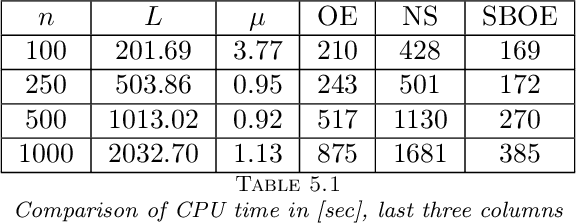

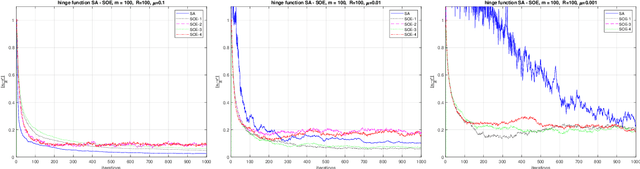
In this paper we first present a novel operator extrapolation (OE) method for solving deterministic variational inequality (VI) problems. Similar to the gradient (operator) projection method, OE updates one single search sequence by solving a single projection subproblem in each iteration. We show that OE can achieve the optimal rate of convergence for solving a variety of VI problems in a much simpler way than existing approaches. We then introduce the stochastic operator extrapolation (SOE) method and establish its optimal convergence behavior for solving different stochastic VI problems. In particular, SOE achieves the optimal complexity for solving a fundamental problem, i.e., stochastic smooth and strongly monotone VI, for the first time in the literature. We also present a stochastic block operator extrapolations (SBOE) method to further reduce the iteration cost for the OE method applied to large-scale deterministic VIs with a certain block structure. Numerical experiments have been conducted to demonstrate the potential advantages of the proposed algorithms. In fact, all these algorithms are applied to solve generalized monotone variational inequality (GMVI) problems whose operator is not necessarily monotone. We will also discuss optimal OE-based policy evaluation methods for reinforcement learning in a companion paper.
On the Feasibility of Real-Time 3D Hand Tracking using Edge GPGPU Acceleration
Apr 30, 2018

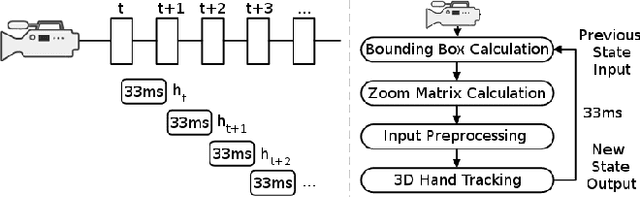
This paper presents the case study of a non-intrusive porting of a monolithic C++ library for real-time 3D hand tracking, to the domain of edge-based computation. Towards a proof of concept, the case study considers a pair of workstations, a computationally powerful and a computationally weak one. By wrapping the C++ library in Java container and by capitalizing on a Java-based offloading infrastructure that supports both CPU and GPGPU computations, we are able to establish automatically the required server-client workflow that best addresses the resource allocation problem in the effort to execute from the weak workstation. As a result, the weak workstation can perform well at the task, despite lacking the sufficient hardware to do the required computations locally. This is achieved by offloading computations which rely on GPGPU, to the powerful workstation, across the network that connects them. We show the edge-based computation challenges associated with the information flow of the ported algorithm, demonstrate how we cope with them, and identify what needs to be improved for achieving even better performance.
Bespoke Neural Networks for Score-Informed Source Separation
Sep 29, 2020In this paper, we introduce a simple method that can separate arbitrary musical instruments from an audio mixture. Given an unaligned MIDI transcription for a target instrument from an input mixture, we synthesize new mixtures from the midi transcription that sound similar to the mixture to be separated. This lets us create a labeled training set to train a network on the specific bespoke task. When this model applied to the original mixture, we demonstrate that this method can: 1) successfully separate out the desired instrument with access to only unaligned MIDI, 2) separate arbitrary instruments, and 3) get results in a fraction of the time of existing methods. We encourage readers to listen to the demos posted here: https://git.io/JUu5q.
Adversarial Attacks Against Deep Learning Systems for ICD-9 Code Assignment
Sep 29, 2020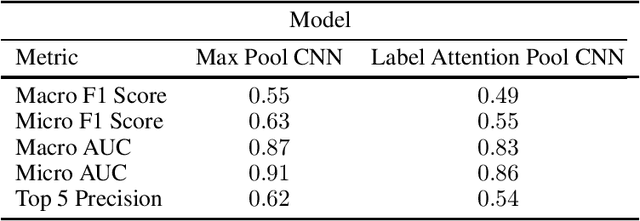
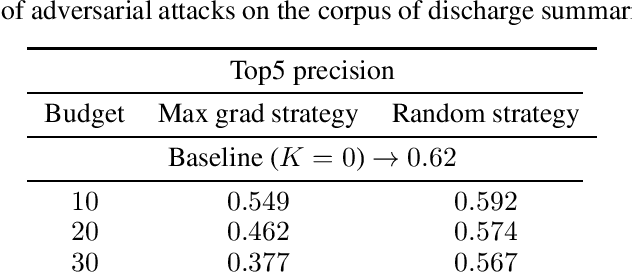

Manual annotation of ICD-9 codes is a time consuming and error-prone process. Deep learning based systems tackling the problem of automated ICD-9 coding have achieved competitive performance. Given the increased proliferation of electronic medical records, such automated systems are expected to eventually replace human coders. In this work, we investigate how a simple typo-based adversarial attack strategy can impact the performance of state-of-the-art models for the task of predicting the top 50 most frequent ICD-9 codes from discharge summaries. Preliminary results indicate that a malicious adversary, using gradient information, can craft specific perturbations, that appear as regular human typos, for less than 3% of words in the discharge summary to significantly affect the performance of the baseline model.