 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Context Sticks: Studying Interference in In-Context Learning
Apr 25, 2026This paper investigates context stickiness in in-context learning (ICL), a phenomenon where earlier examples in a prompt interfere with a transformer's ability to adapt to later tasks. Using synthetic regression tasks over linear and quadratic functions, we examine how models trained under sequential, mixed, and random curricula handle abrupt task switches during inference. By sweeping over structured combinations of misleading linear examples followed by recovery quadratic examples, we quantify how prior context biases prediction error and how quickly models realign. Our results show strong evidence of persistent interference: more preceding linear examples reliably degrade quadratic predictions, while additional quadratic examples reduce error but with diminishing returns. We further find that training curricula significantly modulate resilience, with sequential training on the target function class yielding the fastest recovery, and surprisingly, random training producing the least robust behavior.
Robust Fair Disease Diagnosis in CT Images
Apr 08, 2026Automated diagnosis from chest CT has improved considerably with deep learning, but models trained on skewed datasets tend to perform unevenly across patient demographics. However, the situation is worse than simple demographic bias. In clinical data, class imbalance and group underrepresentation often coincide, creating compound failure modes that neither standard rebalancing nor fairness corrections can fix alone. We introduce a two-level objective that targets both axes of this problem. Logit-adjusted cross-entropy loss operates at the sample level, shifting decision margins by class frequency with provable consistency guarantees. Conditional Value at Risk aggregation operates at the group level, directing optimization pressure toward whichever demographic group currently has the higher loss. We evaluate on the Fair Disease Diagnosis benchmark using a 3D ResNet-18 pretrained on Kinetics-400, classifying CT volumes into Adenocarcinoma, Squamous Cell Carcinoma, COVID-19, and Normal groups with patient sex annotations. The training set illustrates the compound problem concretely: squamous cell carcinoma has 84 samples total, 5 of them female. The combined loss reaches a gender-averaged macro F1 of 0.8403 with a fairness gap of 0.0239, a 13.3% improvement in score and 78% reduction in demographic disparity over the baseline. Ablations show that each component alone falls short. The code is publicly available at https://github.com/Purdue-M2/Fair-Disease-Diagnosis.
Robust Multi-Source Covid-19 Detection in CT Images
Apr 02, 2026Deep learning models for COVID-19 detection from chest CT scans generally perform well when the training and test data originate from the same institution, but they often struggle when scans are drawn from multiple centres with differing scanners, imaging protocols, and patient populations. One key reason is that existing methods treat COVID-19 classification as the sole training objective, without accounting for the data source of each scan. As a result, the learned representations tend to be biased toward centres that contribute more training data. To address this, we propose a multi-task learning approach in which the model is trained to predict both the COVID-19 diagnosis and the originating data centre. The two tasks share an EfficientNet-B7 backbone, which encourages the feature extractor to learn representations that hold across all four participating centres. Since the training data is not evenly distributed across sources, we apply a logit-adjusted cross-entropy loss [1] to the source classification head to prevent underrepresented centres from being overlooked. Our pre-processing follows the SSFL framework with KDS [2], selecting eight representative slices per scan. Our method achieves an F1 score of 0.9098 and an AUC-ROC of 0.9647 on a validation set of 308 scans. The code is publicly available at https://github.com/Purdue-M2/-multisource-covid-ct.
UniCoMTE: A Universal Counterfactual Framework for Explaining Time-Series Classifiers on ECG Data
Dec 22, 2025Machine learning models, particularly deep neural networks, have demonstrated strong performance in classifying complex time series data. However, their black-box nature limits trust and adoption, especially in high-stakes domains such as healthcare. To address this challenge, we introduce UniCoMTE, a model-agnostic framework for generating counterfactual explanations for multivariate time series classifiers. The framework identifies temporal features that most heavily influence a model's prediction by modifying the input sample and assessing its impact on the model's prediction. UniCoMTE is compatible with a wide range of model architectures and operates directly on raw time series inputs. In this study, we evaluate UniCoMTE's explanations on a time series ECG classifier. We quantify explanation quality by comparing our explanations' comprehensibility to comprehensibility of established techniques (LIME and SHAP) and assessing their generalizability to similar samples. Furthermore, clinical utility is assessed through a questionnaire completed by medical experts who review counterfactual explanations presented alongside original ECG samples. Results show that our approach produces concise, stable, and human-aligned explanations that outperform existing methods in both clarity and applicability. By linking model predictions to meaningful signal patterns, the framework advances the interpretability of deep learning models for real-world time series applications.
Predicting the Stereoselectivity of Chemical Transformations by Machine Learning
Oct 12, 2021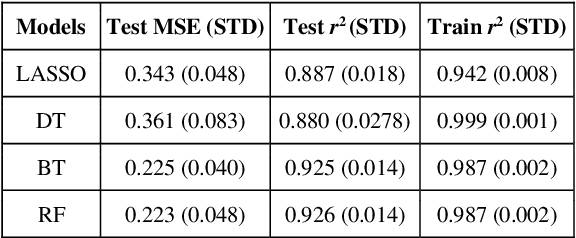
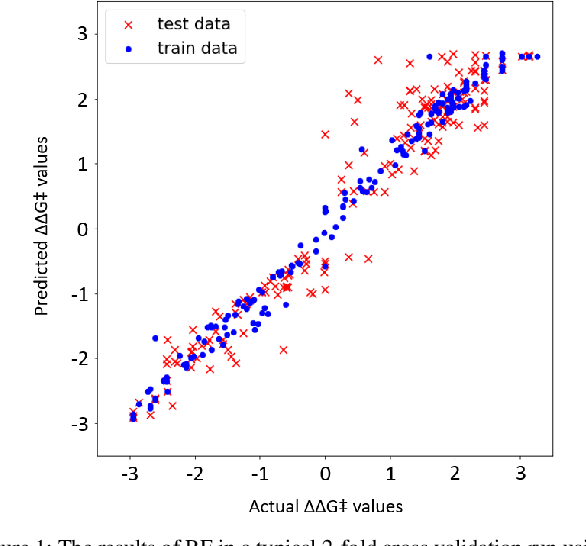
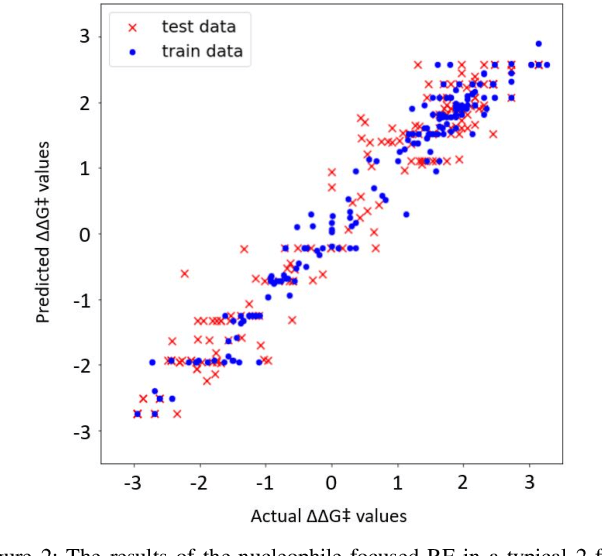
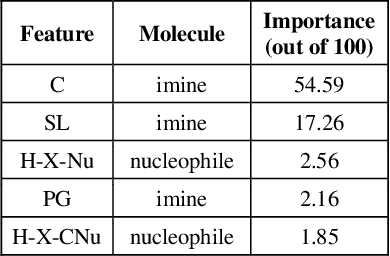
Stereoselective reactions (both chemical and enzymatic reactions) have been essential for origin of life, evolution, human biology and medicine. Since late 1960s, there have been numerous successes in the exciting new frontier of asymmetric catalysis. However, most industrial and academic asymmetric catalysis nowadays do follow the trial-and-error model, since the energetic difference for success or failure in asymmetric catalysis is incredibly small. Our current understanding about stereoselective reactions is mostly qualitative that stereoselectivity arises from differences in steric effects and electronic effects in multiple competing mechanistic pathways. Quantitatively understanding and modulating the stereoselectivity of for a given chemical reaction still remains extremely difficult. As a proof of principle, we herein present a novel machine learning technique, which combines a LASSO model and two Random Forest model via two Gaussian Mixture models, for quantitatively predicting stereoselectivity of chemical reactions. Compared to the recent ground-breaking approach [1], our approach is able to capture interactions between features and exploit complex data distributions, which are important for predicting stereoselectivity. Experimental results on a recently published dataset demonstrate that our approach significantly outperform [1]. The insight obtained from our results provide a solid foundation for further exploration of other synthetically valuable yet mechanistically intriguing stereoselective reactions.
A Deep Learning Approach for COVID-19 Trend Prediction
Aug 09, 2020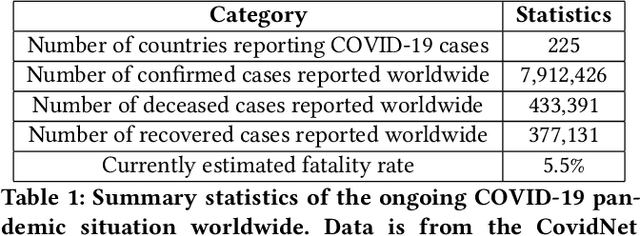
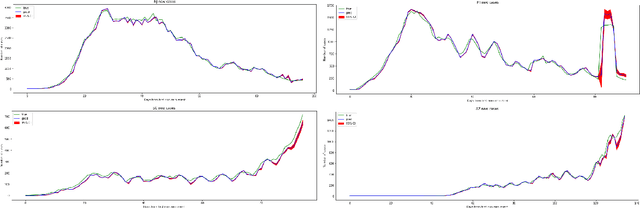
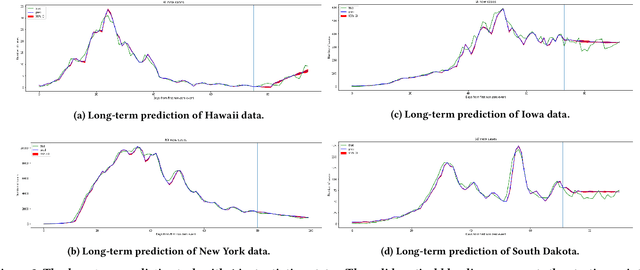
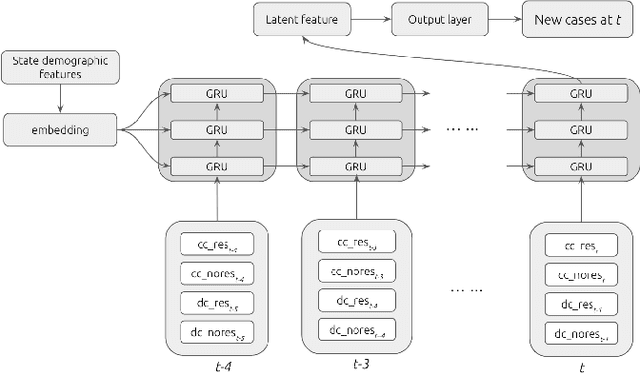
In this work, we developed a deep learning model-based approach to forecast the spreading trend of SARS-CoV-2 in the United States. We implemented the designed model using the United States to confirm cases and state demographic data and achieved promising trend prediction results. The model incorporates demographic information and epidemic time-series data through a Gated Recurrent Unit structure. The identification of dominating demographic factors is delivered in the end.