 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hold Tight and Never Let Go: Security of Deep Learning based Automated Lane Centering under Physical-World Attack
Sep 14, 2020
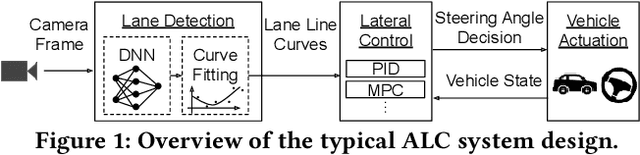


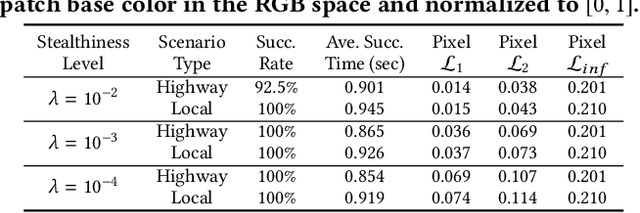
Automated Lane Centering (ALC) systems are convenient and widely deployed today, but also highly security and safety critical. In this work, we are the first to systematically study the security of state-of-the-art deep learning based ALC systems in their designed operational domains under physical-world adversarial attacks. We formulate the problem with a safety-critical attack goal, and a novel and domain-specific attack vector: dirty road patches. To systematically generate the attack, we adopt an optimization-based approach and overcome domain-specific design challenges such as camera frame inter-dependencies due to dynamic vehicle actuation, and the lack of objective function design for lane detection models. We evaluate our attack method on a production ALC system using 80 attack scenarios from real-world driving traces. The results show that our attack is highly effective with over 92% success rates and less than 0.95 sec average success time, which is substantially lower than the average driver reaction time. Such high attack effectiveness is also found (1) robust to motion model inaccuracies, different lane detection model designs, and physical-world factors, and (2) stealthy from the driver's view. To concretely understand the end-to-end safety consequences, we further evaluate on concrete real-world attack scenarios using a production-grade simulator, and find that our attack can successfully cause the victim to hit the highway concrete barrier or a truck in the opposite direction with 98% and 100% success rates. We also discuss defense directions.
Streaming Graph Neural Networks via Continual Learning
Sep 23, 2020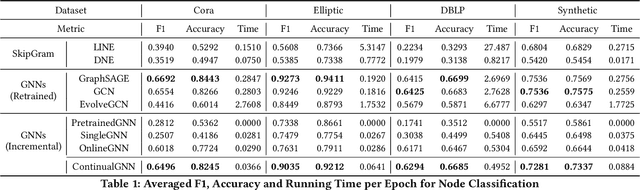
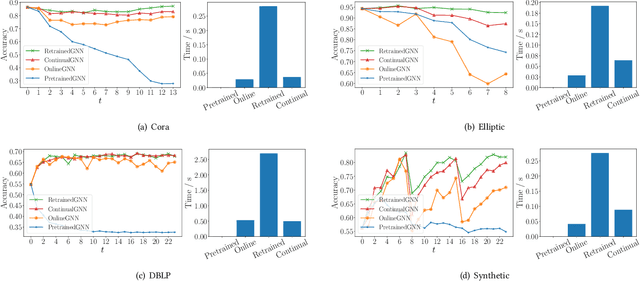
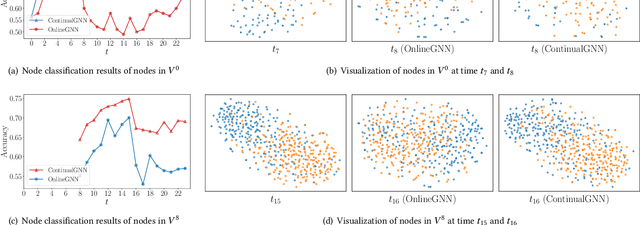
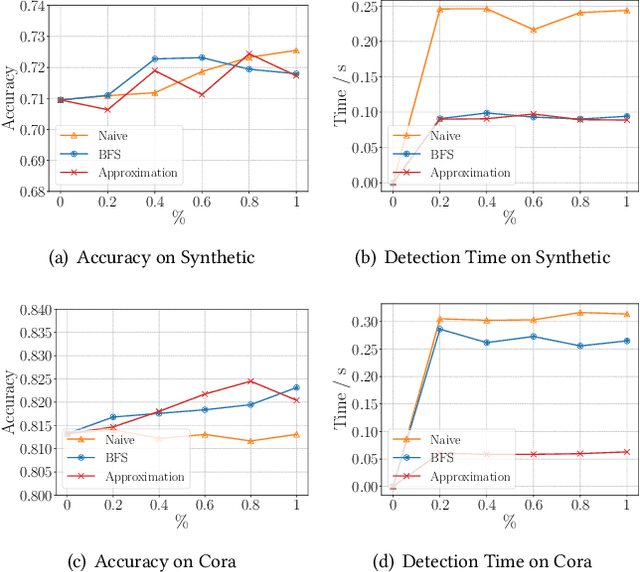
Graph neural networks (GNNs) have achieved strong performance in various applications. In the real world, network data is usually formed in a streaming fashion. The distributions of patterns that refer to neighborhood information of nodes may shift over time. The GNN model needs to learn the new patterns that cannot yet be captured. But learning incrementally leads to the catastrophic forgetting problem that historical knowledge is overwritten by newly learned knowledge. Therefore, it is important to train GNN model to learn new patterns and maintain existing patterns simultaneously, which few works focus on. In this paper, we propose a streaming GNN model based on continual learning so that the model is trained incrementally and up-to-date node representations can be obtained at each time step. Firstly, we design an approximation algorithm to detect new coming patterns efficiently based on information propagation. Secondly, we combine two perspectives of data replaying and model regularization for existing pattern consolidation. Specially, a hierarchy-importance sampling strategy for nodes is designed and a weighted regularization term for GNN parameters is derived, achieving greater stability and generalization of knowledge consolidation. Our model is evaluated on real and synthetic data sets and compared with multiple baselines. The results of node classification prove that our model can efficiently update model parameters and achieve comparable performance to model retraining. In addition, we also conduct a case study on the synthetic data, and carry out some specific analysis for each part of our model, illustrating its ability to learn new knowledge and maintain existing knowledge from different perspectives.
Medical Imaging and Computational Image Analysis in COVID-19 Diagnosis: A Review
Oct 01, 2020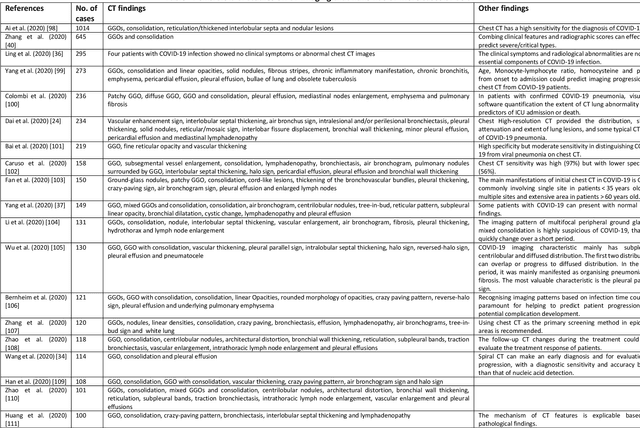
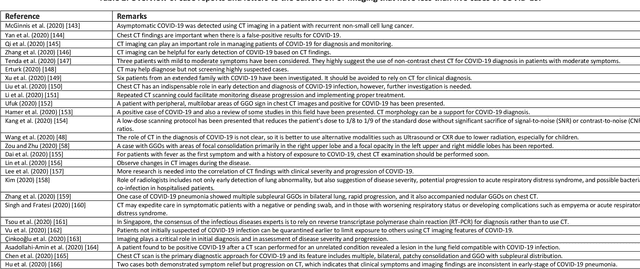

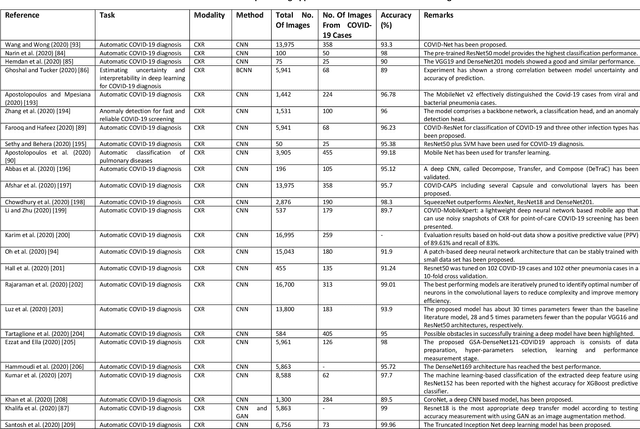
Coronavirus disease (COVID-19) is an infectious disease caused by a newly discovered coronavirus. The disease presents with symptoms such as shortness of breath, fever, dry cough, and chronic fatigue, amongst others. Sometimes the symptoms of the disease increase so much they lead to the death of the patients. The disease may be asymptomatic in some patients in the early stages, which can lead to increased transmission of the disease to others. Many studies have tried to use medical imaging for early diagnosis of COVID-19. This study attempts to review papers on automatic methods for medical image analysis and diagnosis of COVID-19. For this purpose, PubMed, Google Scholar, arXiv and medRxiv were searched to find related studies by the end of April 2020, and the essential points of the collected studies were summarised. The contribution of this study is four-fold: 1) to use as a tutorial of the field for both clinicians and technologists, 2) to comprehensively review the characteristics of COVID-19 as presented in medical images, 3) to examine automated artificial intelligence-based approaches for COVID-19 diagnosis based on the accuracy and the method used, 4) to express the research limitations in this field and the methods used to overcome them. COVID-19 reveals signs in medical images can be used for early diagnosis of the disease even in asymptomatic patients. Using automated machine learning-based methods can diagnose the disease with high accuracy from medical images and reduce time, cost and error of diagnostic procedure. It is recommended to collect bulk imaging data from patients in the shortest possible time to improve the performance of COVID-19 automated diagnostic methods.
Spatio-Temporal Graph Scattering Transform
Dec 10, 2020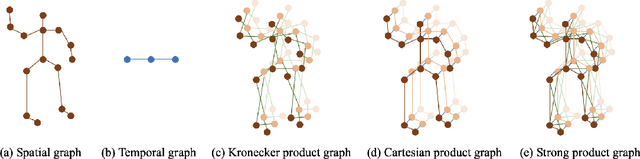
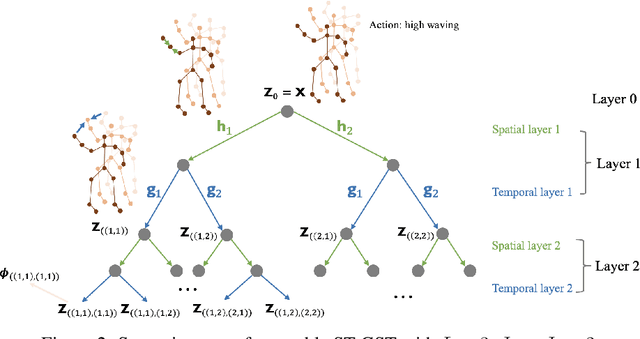

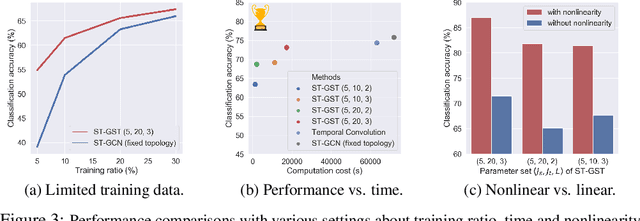
Although spatio-temporal graph neural networks have achieved great empirical success in handling multiple correlated time series, they may be impractical in some real-world scenarios due to a lack of sufficient high-quality training data. Furthermore, spatio-temporal graph neural networks lack theoretical interpretation. To address these issues, we put forth a novel mathematically designed framework to analyze spatio-temporal data. Our proposed spatio-temporal graph scattering transform (ST-GST) extends traditional scattering transforms to the spatio-temporal domain. It performs iterative applications of spatio-temporal graph wavelets and nonlinear activation functions, which can be viewed as a forward pass of spatio-temporal graph convolutional networks without training. Since all the filter coefficients in ST-GST are mathematically designed, it is promising for the real-world scenarios with limited training data, and also allows for a theoretical analysis, which shows that the proposed ST-GST is stable to small perturbations of input signals and structures. Finally, our experiments show that i) ST-GST outperforms spatio-temporal graph convolutional networks by an increase of 35% in accuracy for MSR Action3D dataset; ii) it is better and computationally more efficient to design the transform based on separable spatio-temporal graphs than the joint ones; and iii) the nonlinearity in ST-GST is critical to empirical performance.
Time-Dependent Utility and Action Under Uncertainty
Mar 20, 2013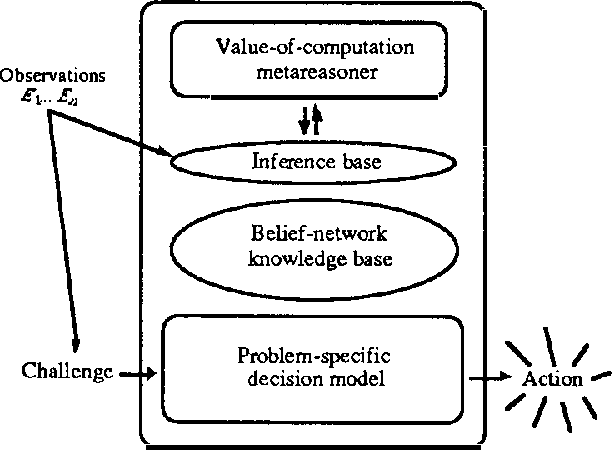
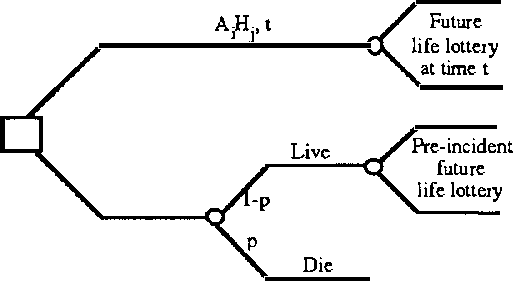
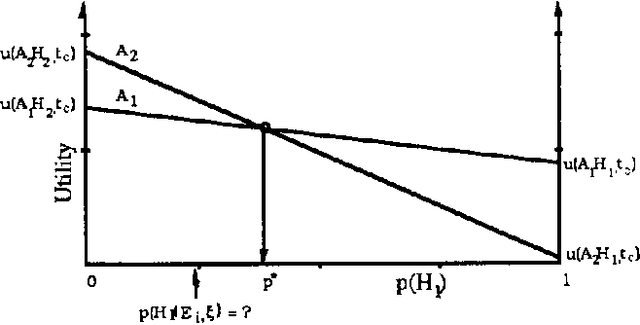
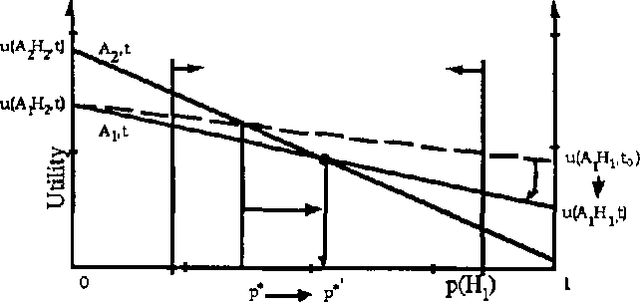
We discuss representing and reasoning with knowledge about the time-dependent utility of an agent's actions. Time-dependent utility plays a crucial role in the interaction between computation and action under bounded resources. We present a semantics for time-dependent utility and describe the use of time-dependent information in decision contexts. We illustrate our discussion with examples of time-pressured reasoning in Protos, a system constructed to explore the ideal control of inference by reasoners with limit abilities.
Occlusion-Aware Search for Object Retrieval in Clutter
Nov 10, 2020

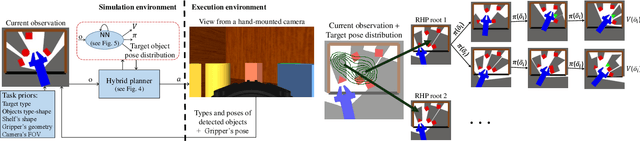

We address the manipulation task of retrieving a target object from a cluttered shelf. When the target object is hidden, the robot must search through the clutter for retrieving it. Solving this task requires reasoning over the likely locations of the target object. It also requires physics reasoning over multi-object interactions and future occlusions. In this work, we present a data-driven approach for generating occlusion-aware actions in closed-loop. We present a hybrid planner that explores likely states generated from a learned distribution over the location of the target object. The search is guided by a heuristic trained with reinforcement learning to evaluate occluded observations. We evaluate our approach in different environments with varying clutter densities and physics parameters. The results validate that our approach can search and retrieve a target object in different physics environments, while only being trained in simulation. It achieves near real-time behaviour with a success rate exceeding 88%.
Recurrent babbling: evaluating the acquisition of grammar from limited input data
Oct 09, 2020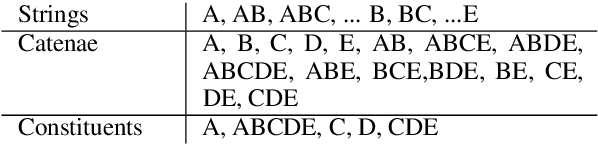

Recurrent Neural Networks (RNNs) have been shown to capture various aspects of syntax from raw linguistic input. In most previous experiments, however, learning happens over unrealistic corpora, which do not reflect the type and amount of data a child would be exposed to. This paper remedies this state of affairs by training a Long Short-Term Memory network (LSTM) over a realistically sized subset of child-directed input. The behaviour of the network is analysed over time using a novel methodology which consists in quantifying the level of grammatical abstraction in the model's generated output (its "babbling"), compared to the language it has been exposed to. We show that the LSTM indeed abstracts new structuresas learning proceeds.
Self-supervised Learning of LiDAR Odometry for Robotic Applications
Nov 10, 2020
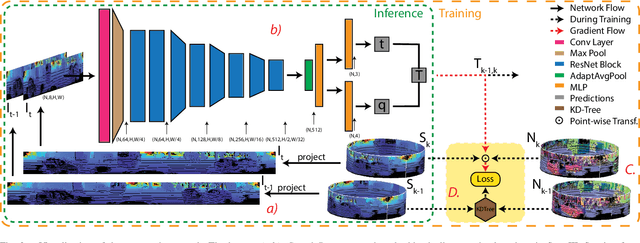


Reliable robot pose estimation is a key building block of many robot autonomy pipelines, with LiDAR localization being an active research domain. In this work, a versatile self-supervised LiDAR odometry estimation method is presented, in order to enable the efficient utilization of all available LiDAR data while maintaining real-time performance. The proposed approach selectively applies geometric losses during training, being cognizant of the amount of information that can be extracted from scan points. In addition, no labeled or ground-truth data is required, hence making the presented approach suitable for pose estimation in applications where accurate ground-truth is difficult to obtain. Furthermore, the presented network architecture is applicable to a wide range of environments and sensor modalities without requiring any network or loss function adjustments. The proposed approach is thoroughly tested for both indoor and outdoor real-world applications through a variety of experiments using legged, tracked and wheeled robots, demonstrating the suitability of learning-based LiDAR odometry for complex robotic applications.
SPAA: Stealthy Projector-based Adversarial Attacks on Deep Image Classifiers
Dec 10, 2020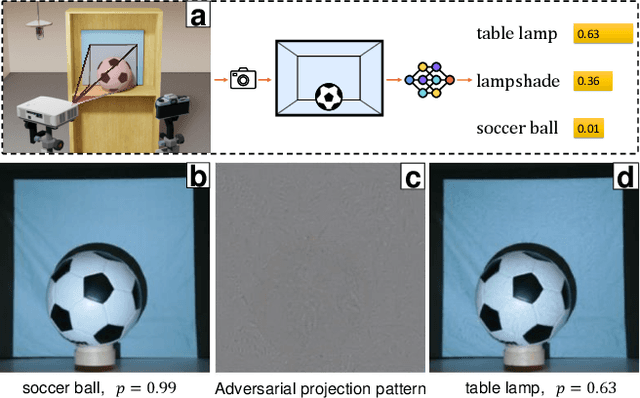
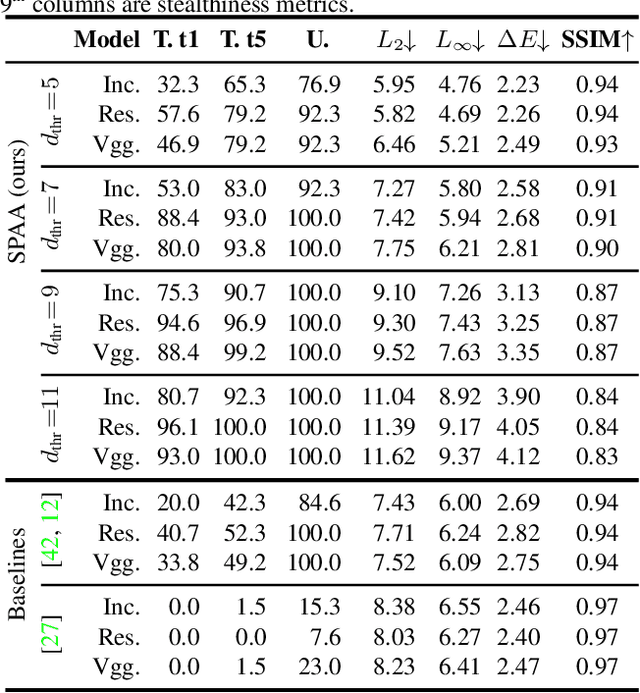

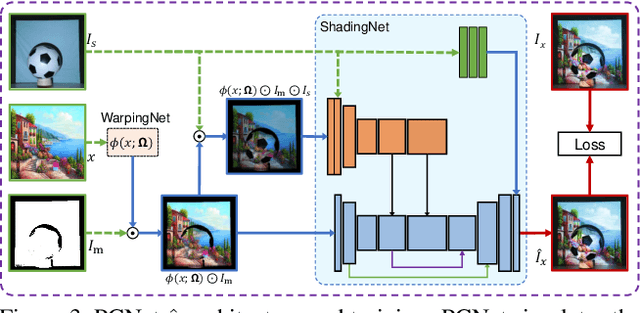
Light-based adversarial attacks aim to fool deep learning-based image classifiers by altering the physical light condition using a controllable light source, e.g., a projector. Compared with physical attacks that place carefully designed stickers or printed adversarial objects, projector-based ones obviate modifying the physical entities. Moreover, projector-based attacks can be performed transiently and dynamically by altering the projection pattern. However, existing approaches focus on projecting adversarial patterns that result in clearly perceptible camera-captured perturbations, while the more interesting yet challenging goal, stealthy projector-based attack, remains an open problem. In this paper, for the first time, we formulate this problem as an end-to-end differentiable process and propose Stealthy Projector-based Adversarial Attack (SPAA). In SPAA, we approximate the real project-and-capture operation using a deep neural network named PCNet, then we include PCNet in the optimization of projector-based attacks such that the generated adversarial projection is physically plausible. Finally, to generate robust and stealthy adversarial projections, we propose an optimization algorithm that uses minimum perturbation and adversarial confidence thresholds to alternate between the adversarial loss and stealthiness loss optimization. Our experimental evaluations show that the proposed SPAA clearly outperforms other methods by achieving higher attack success rates and meanwhile being stealthier.
Policy Teaching in Reinforcement Learning via Environment Poisoning Attacks
Nov 21, 2020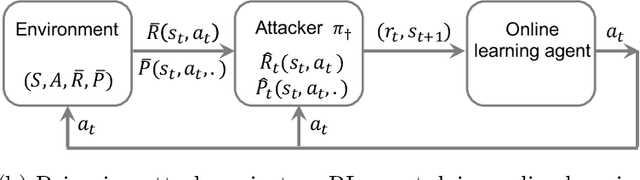
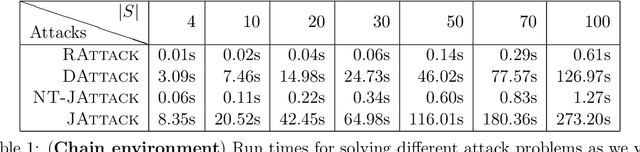
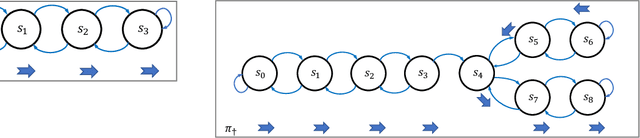
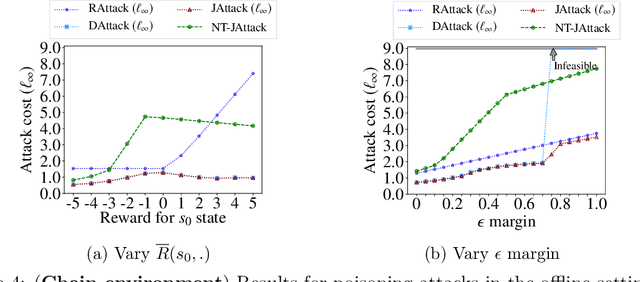
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes reward in infinite-horizon problem settings. The attacker can manipulate the rewards and the transition dynamics in the learning environment at training-time, and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an optimal stealthy attack for different measures of attack cost. We provide lower/upper bounds on the attack cost, and instantiate our attacks in two settings: (i) an offline setting where the agent is doing planning in the poisoned environment, and (ii) an online setting where the agent is learning a policy with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.