 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Trajectory saliency detection using consistency-oriented latent codes from a recurrent auto-encoder
Dec 17, 2020
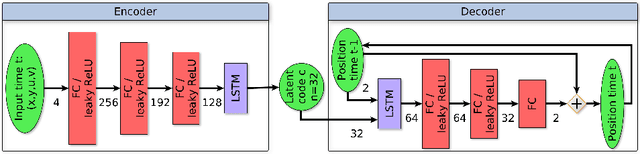
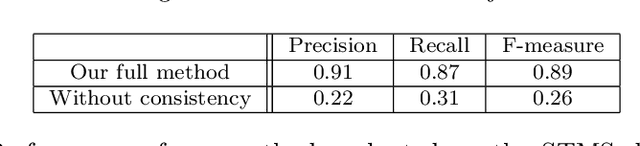
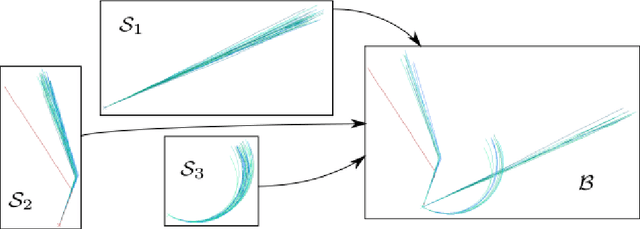
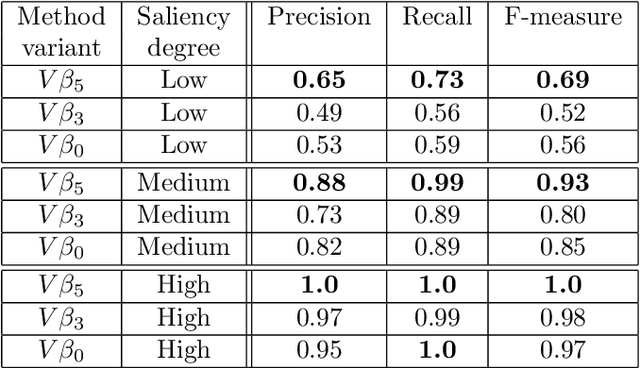
In this paper, we are concerned with the detection of progressive dynamic saliency from video sequences. More precisely, we are interested in saliency related to motion and likely to appear progressively over time. It can be relevant to trigger alarms, to dedicate additional processing or to detect specific events. Trajectories represent the best way to support progressive dynamic saliency detection. Accordingly, we will talk about trajectory saliency. A trajectory will be qualified as salient if it deviates from normal trajectories that share a common motion pattern related to a given context. First, we need a compact while discriminative representation of trajectories. We adopt a (nearly) unsupervised learning-based approach. The latent code estimated by a recurrent auto-encoder provides the desired representation. In addition, we enforce consistency for normal (similar) trajectories through the auto-encoder loss function. The distance of the trajectory code to a prototype code accounting for normality is the means to detect salient trajectories. We validate our trajectory saliency detection method on synthetic and real trajectory datasets, and highlight the contributions of its different components. We show that our method outperforms existing methods on several scenarios drawn from the publicly available dataset of pedestrian trajectories acquired in a railway station (Alahi 2014).
On the Ergodicity, Bias and Asymptotic Normality of Randomized Midpoint Sampling Method
Nov 06, 2020The randomized midpoint method, proposed by [SL19], has emerged as an optimal discretization procedure for simulating the continuous time Langevin diffusions. Focusing on the case of strong-convex and smooth potentials, in this paper, we analyze several probabilistic properties of the randomized midpoint discretization method for both overdamped and underdamped Langevin diffusions. We first characterize the stationary distribution of the discrete chain obtained with constant step-size discretization and show that it is biased away from the target distribution. Notably, the step-size needs to go to zero to obtain asymptotic unbiasedness. Next, we establish the asymptotic normality for numerical integration using the randomized midpoint method and highlight the relative advantages and disadvantages over other discretizations. Our results collectively provide several insights into the behavior of the randomized midpoint discretization method, including obtaining confidence intervals for numerical integrations.
Long-Term Prediction of Lane Change Maneuver Through a Multilayer Perceptron
Jun 23, 2020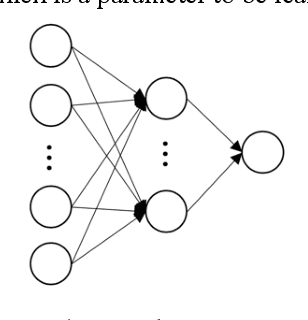
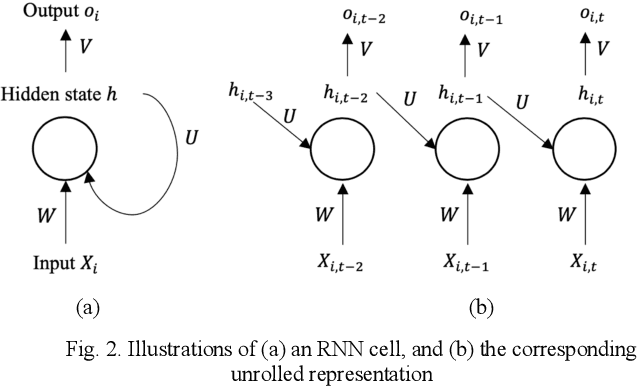
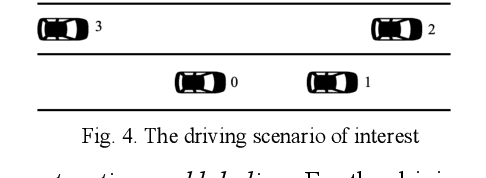
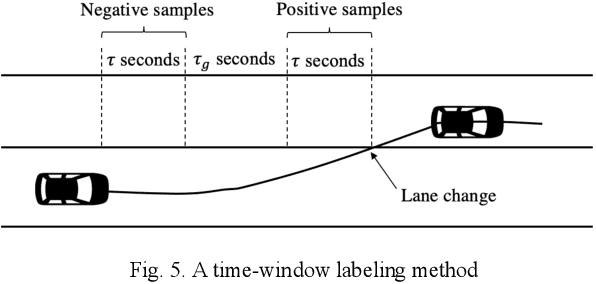
Behavior prediction plays an essential role in both autonomous driving systems and Advanced Driver Assistance Systems (ADAS), since it enhances vehicle's awareness of the imminent hazards in the surrounding environment. Many existing lane change prediction models take as input lateral or angle information and make short-term (< 5 seconds) maneuver predictions. In this study, we propose a longer-term (5~10 seconds) prediction model without any lateral or angle information. Three prediction models are introduced, including a logistic regression model, a multilayer perceptron (MLP) model, and a recurrent neural network (RNN) model, and their performances are compared by using the real-world NGSIM dataset. To properly label the trajectory data, this study proposes a new time-window labeling scheme by adding a time gap between positive and negative samples. Two approaches are also proposed to address the unstable prediction issue, where the aggressive approach propagates each positive prediction for certain seconds, while the conservative approach adopts a roll-window average to smooth the prediction. Evaluation results show that the developed prediction model is able to capture 75% of real lane change maneuvers with an average advanced prediction time of 8.05 seconds.
Goal directed molecule generation using Monte Carlo Tree Search
Oct 30, 2020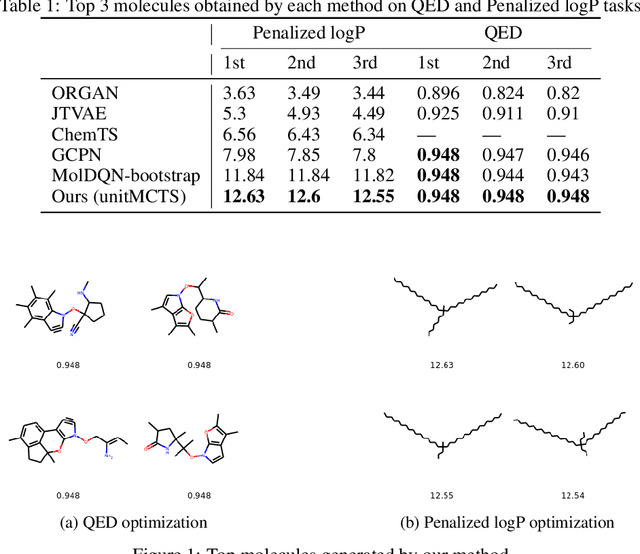
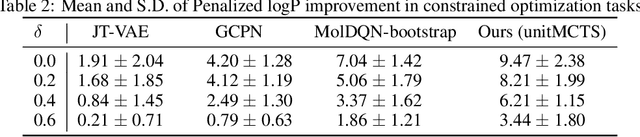
One challenging and essential task in biochemistry is the generation of novel molecules with desired properties. Novel molecule generation remains a challenge since the molecule space is difficult to navigate through, and the generated molecules should obey the rules of chemical valency. Through this work, we propose a novel method, which we call unitMCTS, to perform molecule generation by making a unit change to the molecule at every step using Monte Carlo Tree Search. We show that this method outperforms the recently published techniques on benchmark molecular optimization tasks such as QED and penalized logP. We also demonstrate the usefulness of this method in improving molecule properties while being similar to the starting molecule. Given that there is no learning involved, our method finds desired molecules within a shorter amount of time.
Reactive Human-to-Robot Handovers of Arbitrary Objects
Nov 17, 2020
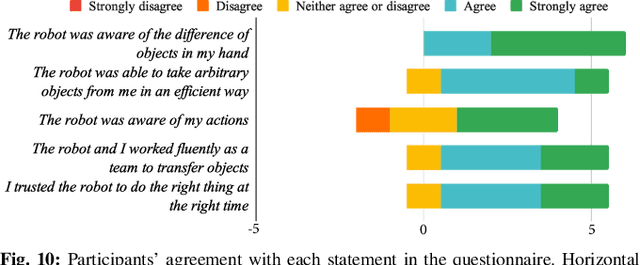
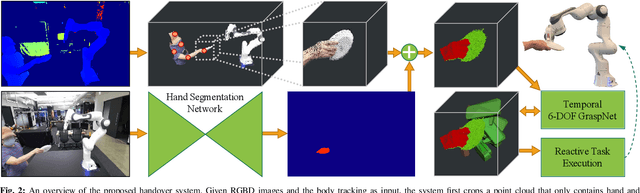

Human-robot object handovers have been an actively studied area of robotics over the past decade; however, very few techniques and systems have addressed the challenge of handing over diverse objects with arbitrary appearance, size, shape, and rigidity. In this paper, we present a vision-based system that enables reactive human-to-robot handovers of unknown objects. Our approach combines closed-loop motion planning with real-time, temporally-consistent grasp generation to ensure reactivity and motion smoothness. Our system is robust to different object positions and orientations, and can grasp both rigid and non-rigid objects. We demonstrate the generalizability, usability, and robustness of our approach on a novel benchmark set of 26 diverse household objects, a user study with naive users (N=6) handing over a subset of 15 objects, and a systematic evaluation examining different ways of handing objects. More results and videos can be found at https://sites.google.com/nvidia.com/handovers-of-arbitrary-objects.
Logic-based Clustering and Learning for Time-Series Data
May 15, 2017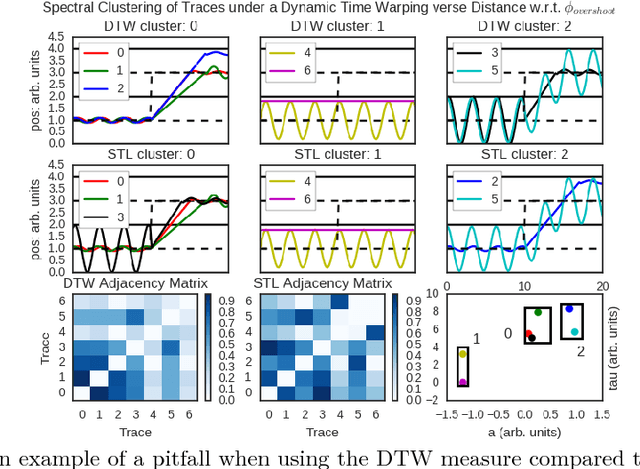
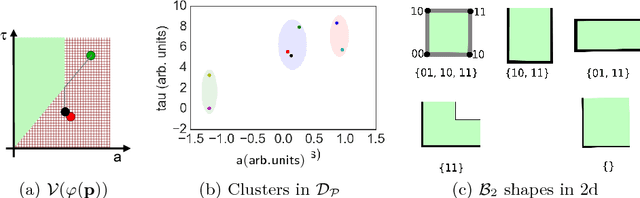
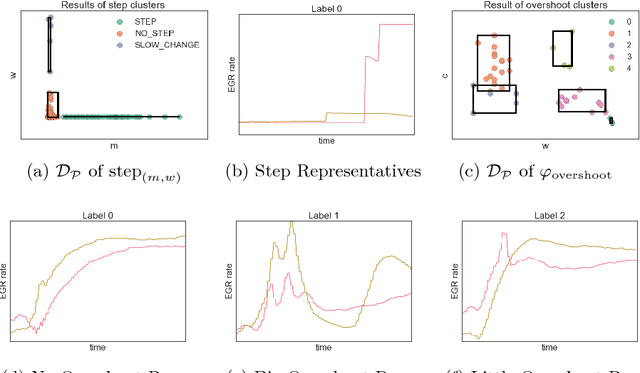
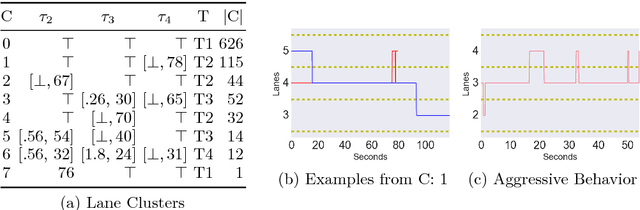
To effectively analyze and design cyberphysical systems (CPS), designers today have to combat the data deluge problem, i.e., the burden of processing intractably large amounts of data produced by complex models and experiments. In this work, we utilize monotonic Parametric Signal Temporal Logic (PSTL) to design features for unsupervised classification of time series data. This enables using off-the-shelf machine learning tools to automatically cluster similar traces with respect to a given PSTL formula. We demonstrate how this technique produces interpretable formulas that are amenable to analysis and understanding using a few representative examples. We illustrate this with case studies related to automotive engine testing, highway traffic analysis, and auto-grading massively open online courses.
Efficient Hyperparameter Optimization in Deep Learning Using a Variable Length Genetic Algorithm
Jun 23, 2020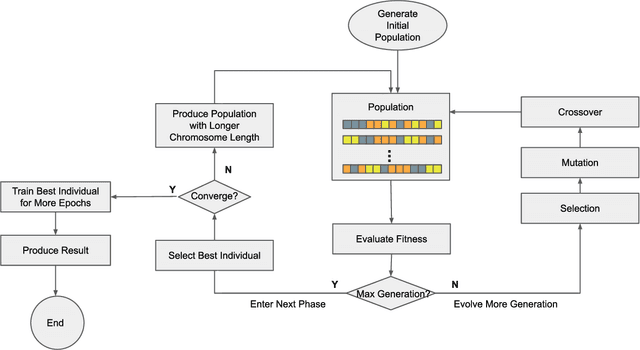
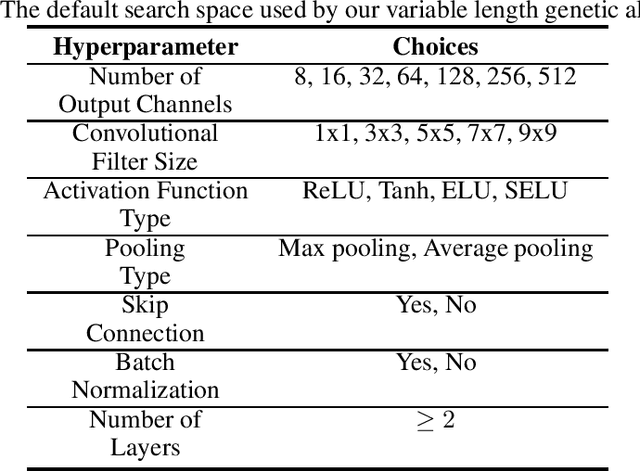

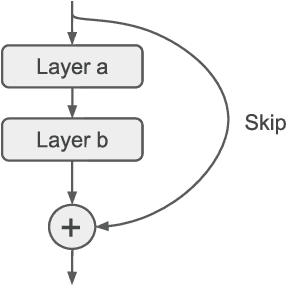
Convolutional Neural Networks (CNN) have gained great success in many artificial intelligence tasks. However, finding a good set of hyperparameters for a CNN remains a challenging task. It usually takes an expert with deep knowledge, and trials and errors. Genetic algorithms have been used in hyperparameter optimizations. However, traditional genetic algorithms with fixed-length chromosomes may not be a good fit for optimizing deep learning hyperparameters, because deep learning models have variable number of hyperparameters depending on the model depth. As the depth increases, the number of hyperparameters grows exponentially, and searching becomes exponentially harder. It is important to have an efficient algorithm that can find a good model in reasonable time. In this article, we propose to use a variable length genetic algorithm (GA) to systematically and automatically tune the hyperparameters of a CNN to improve its performance. Experimental results show that our algorithm can find good CNN hyperparameters efficiently. It is clear from our experiments that if more time is spent on optimizing the hyperparameters, better results could be achieved. Theoretically, if we had unlimited time and CPU power, we could find the optimized hyperparameters and achieve the best results in the future.
Multimodal Prototypical Networks for Few-shot Learning
Nov 17, 2020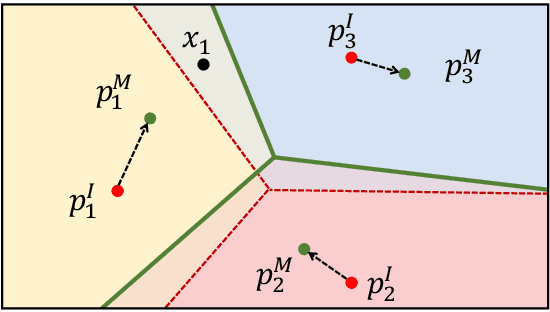
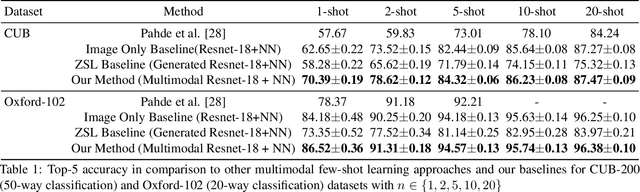
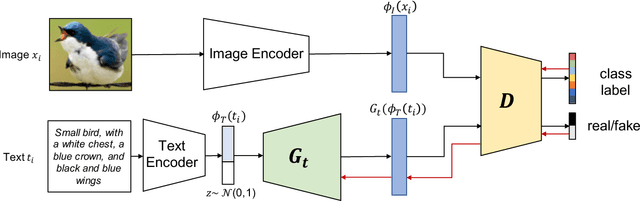
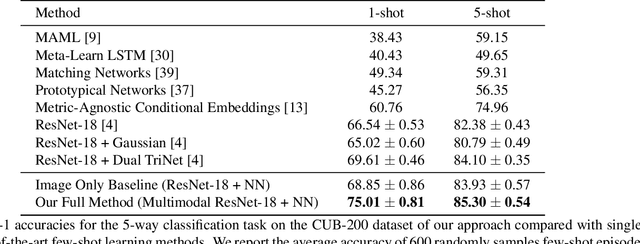
Although providing exceptional results for many computer vision tasks, state-of-the-art deep learning algorithms catastrophically struggle in low data scenarios. However, if data in additional modalities exist (e.g. text) this can compensate for the lack of data and improve the classification results. To overcome this data scarcity, we design a cross-modal feature generation framework capable of enriching the low populated embedding space in few-shot scenarios, leveraging data from the auxiliary modality. Specifically, we train a generative model that maps text data into the visual feature space to obtain more reliable prototypes. This allows to exploit data from additional modalities (e.g. text) during training while the ultimate task at test time remains classification with exclusively visual data. We show that in such cases nearest neighbor classification is a viable approach and outperform state-of-the-art single-modal and multimodal few-shot learning methods on the CUB-200 and Oxford-102 datasets.
A Multi-Task Deep Learning Framework to Localize the Eloquent Cortex in Brain Tumor Patients Using Dynamic Functional Connectivity
Nov 17, 2020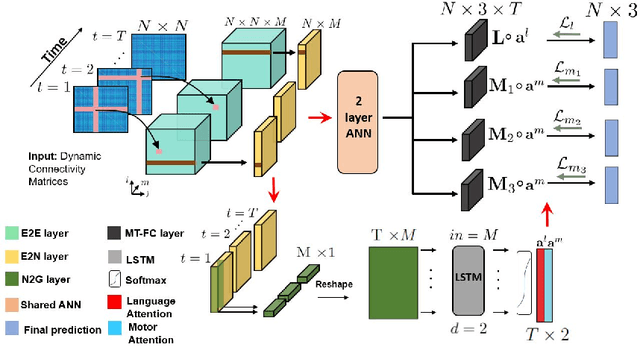
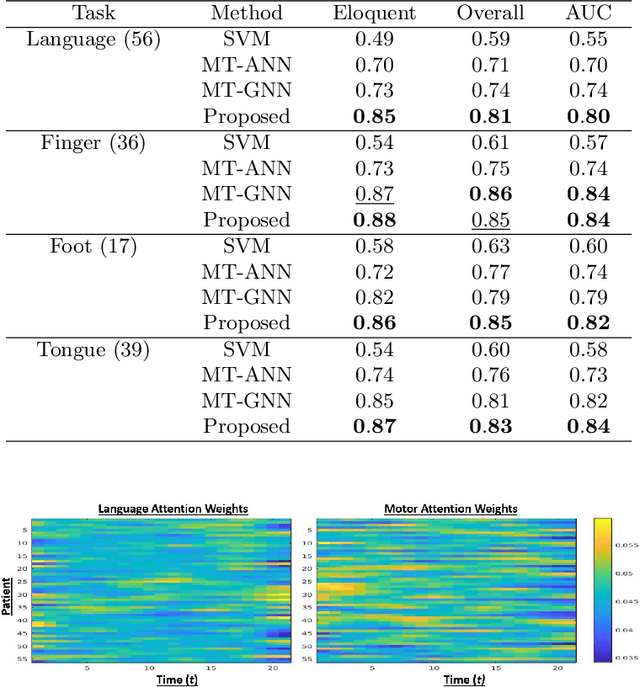
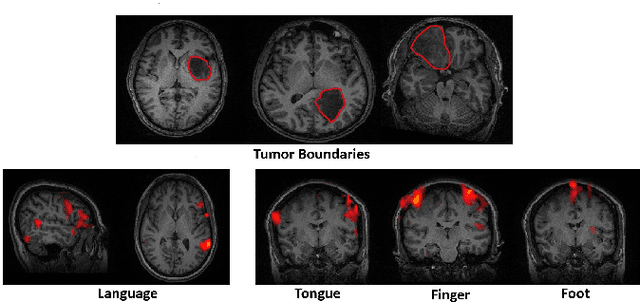
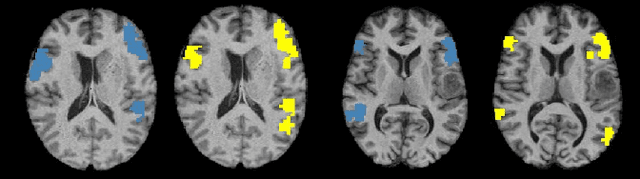
We present a novel deep learning framework that uses dynamic functional connectivity to simultaneously localize the language and motor areas of the eloquent cortex in brain tumor patients. Our method leverages convolutional layers to extract graph-based features from the dynamic connectivity matrices and a long-short term memory (LSTM) attention network to weight the relevant time points during classification. The final stage of our model employs multi-task learning to identify different eloquent subsystems. Our unique training strategy finds a shared representation between the cognitive networks of interest, which enables us to handle missing patient data. We evaluate our method on resting-state fMRI data from 56 brain tumor patients while using task fMRI activations as surrogate ground-truth labels for training and testing. Our model achieves higher localization accuracies than conventional deep learning approaches and can identify bilateral language areas even when trained on left-hemisphere lateralized cases. Hence, our method may ultimately be useful for preoperative mapping in tumor patients.
A Multi-Agent Deep Reinforcement Learning Approach for a Distributed Energy Marketplace in Smart Grids
Sep 23, 2020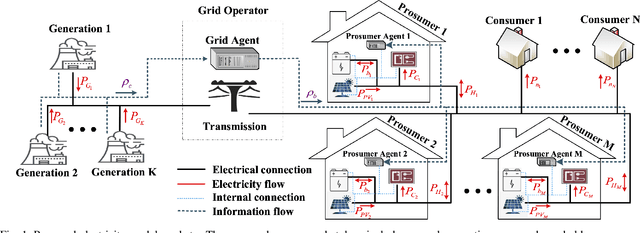
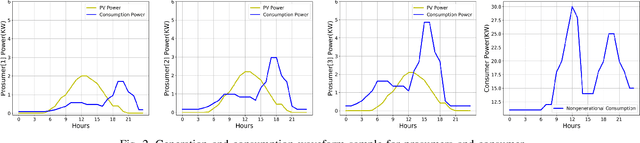
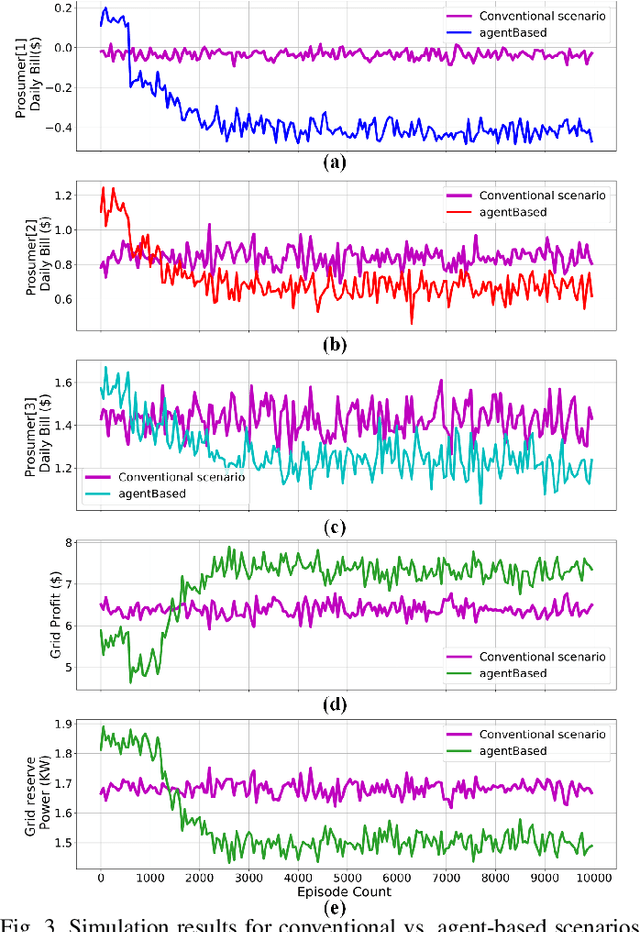
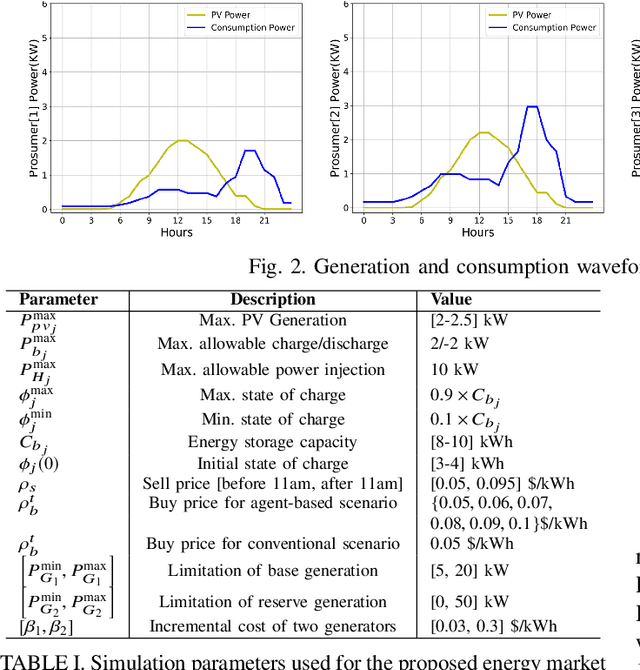
This paper presents a Reinforcement Learning (RL) based energy market for a prosumer dominated microgrid. The proposed market model facilitates a real-time and demanddependent dynamic pricing environment, which reduces grid costs and improves the economic benefits for prosumers. Furthermore, this market model enables the grid operator to leverage prosumers storage capacity as a dispatchable asset for grid support applications. Simulation results based on the Deep QNetwork (DQN) framework demonstrate significant improvements of the 24-hour accumulative profit for both prosumers and the grid operator, as well as major reductions in grid reserve power utilization.