 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer Generation for Questions With Multiple Information Sources in E-Commerce
Nov 27, 2021
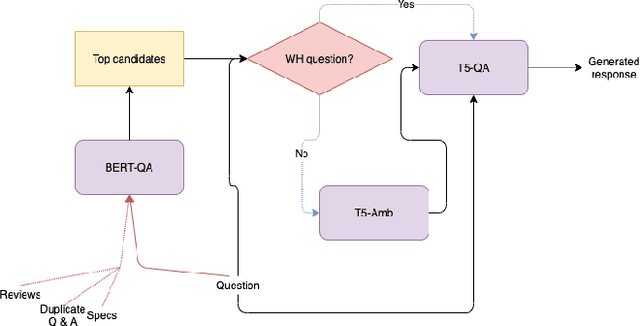
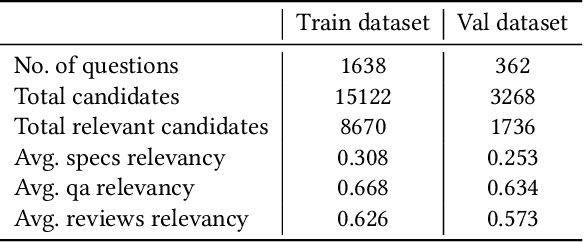
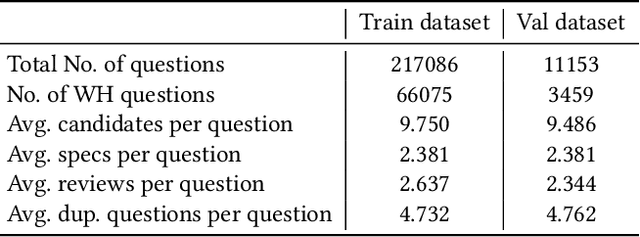
Automatic question answering is an important yet challenging task in E-commerce given the millions of questions posted by users about the product that they are interested in purchasing. Hence, there is a great demand for automatic answer generation systems that provide quick responses using related information about the product. There are three sources of knowledge available for answering a user posted query, they are reviews, duplicate or similar questions, and specifications. Effectively utilizing these information sources will greatly aid us in answering complex questions. However, there are two main challenges present in exploiting these sources: (i) The presence of irrelevant information and (ii) the presence of ambiguity of sentiment present in reviews and similar questions. Through this work we propose a novel pipeline (MSQAP) that utilizes the rich information present in the aforementioned sources by separately performing relevancy and ambiguity prediction before generating a response. Experimental results show that our relevancy prediction model (BERT-QA) outperforms all other variants and has an improvement of 12.36% in F1 score compared to the BERT-base baseline. Our generation model (T5-QA) outperforms the baselines in all content preservation metrics such as BLEU, ROUGE and has an average improvement of 35.02% in ROUGE and 198.75% in BLEU compared to the highest performing baseline (HSSC-q). Human evaluation of our pipeline shows us that our method has an overall improvement in accuracy of 30.7% over the generation model (T5-QA), resulting in our full pipeline-based approach (MSQAP) providing more accurate answers. To the best of our knowledge, this is the first work in the e-commerce domain that automatically generates natural language answers combining the information present in diverse sources such as specifications, similar questions, and reviews data.
Goal directed molecule generation using Monte Carlo Tree Search
Oct 30, 2020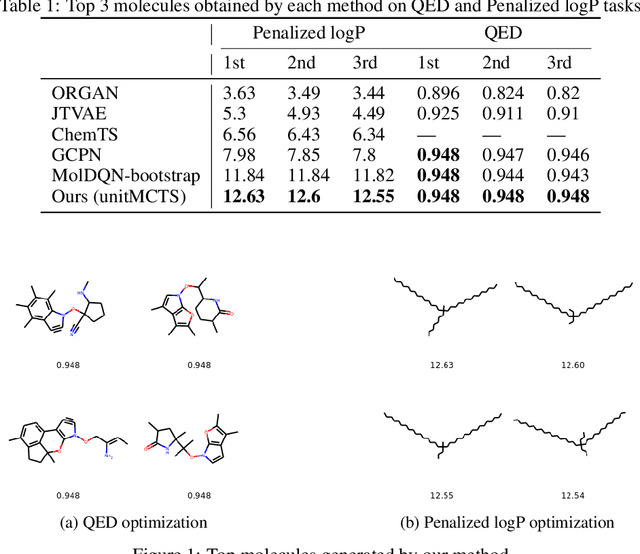
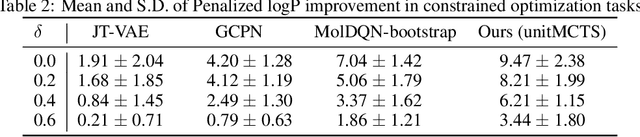
One challenging and essential task in biochemistry is the generation of novel molecules with desired properties. Novel molecule generation remains a challenge since the molecule space is difficult to navigate through, and the generated molecules should obey the rules of chemical valency. Through this work, we propose a novel method, which we call unitMCTS, to perform molecule generation by making a unit change to the molecule at every step using Monte Carlo Tree Search. We show that this method outperforms the recently published techniques on benchmark molecular optimization tasks such as QED and penalized logP. We also demonstrate the usefulness of this method in improving molecule properties while being similar to the starting molecule. Given that there is no learning involved, our method finds desired molecules within a shorter amount of time.