 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
COVID-CLNet: COVID-19 Detection with Compressive Deep Learning Approaches
Dec 03, 2020
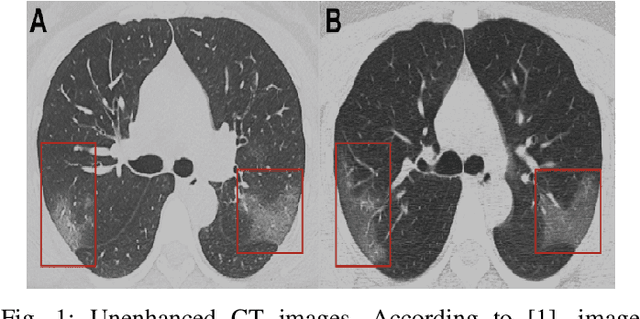
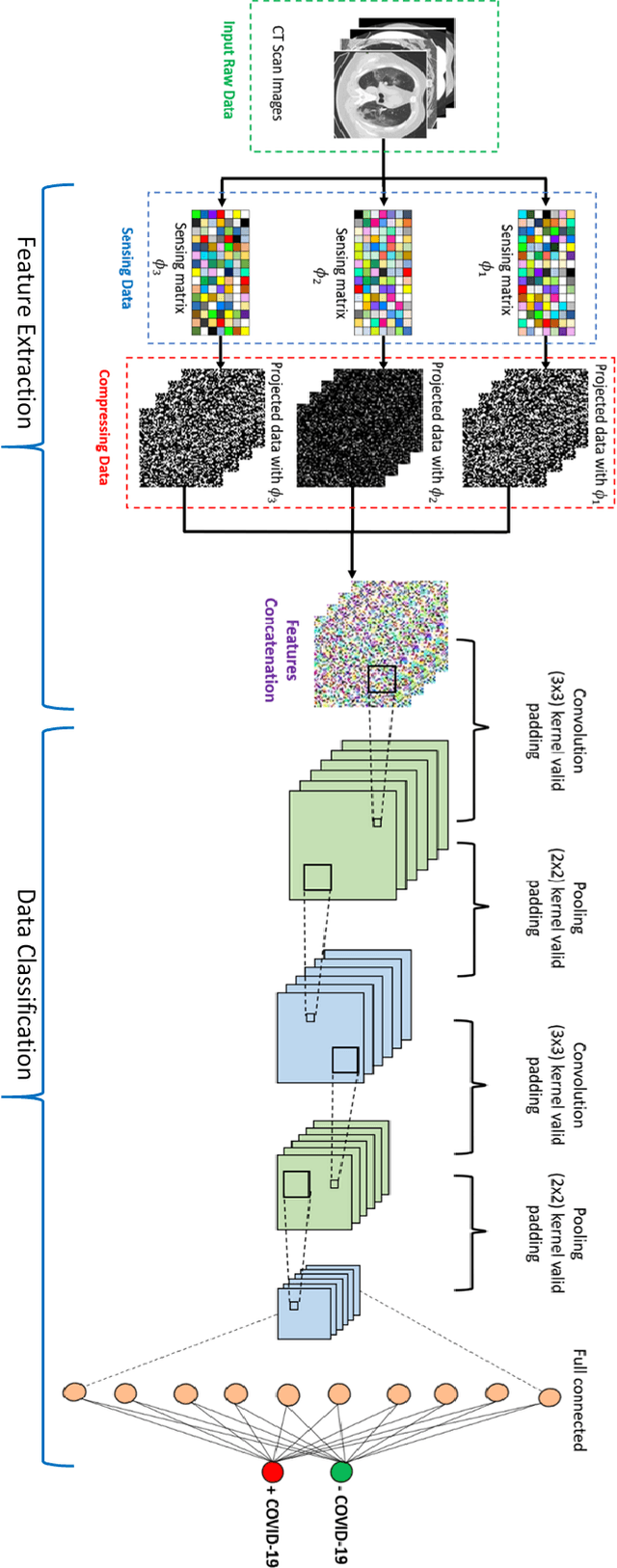

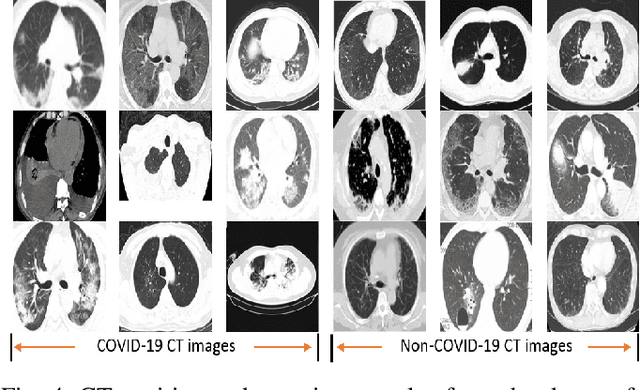
One of the most serious global health threat is COVID-19 pandemic. The emphasis on improving diagnosis and increasing the diagnostic capability helps stopping its spread significantly. Therefore, to assist the radiologist or other medical professional to detect and identify the COVID-19 cases in the shortest possible time, we propose a computer-aided detection (CADe) system that uses the computed tomography (CT) scan images. This proposed boosted deep learning network (CLNet) is based on the implementation of Deep Learning (DL) networks as a complementary to the Compressive Learning (CL). We utilize our inception feature extraction technique in the measurement domain using CL to represent the data features into a new space with less dimensionality before accessing the Convolutional Neural Network. All original features have been contributed equally in the new space using a sensing matrix. Experiments performed on different compressed methods show promising results for COVID-19 detection. In addition, our novel weighted method based on different sensing matrices that used to capture boosted features demonstrates an improvement in the performance of the proposed method.
Evaluating (weighted) dynamic treatment effects by double machine learning
Dec 03, 2020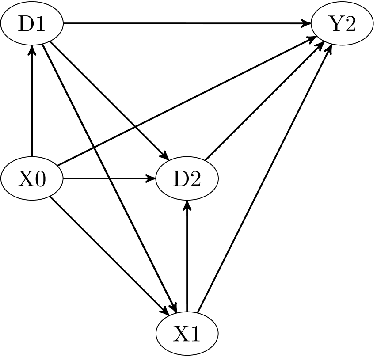

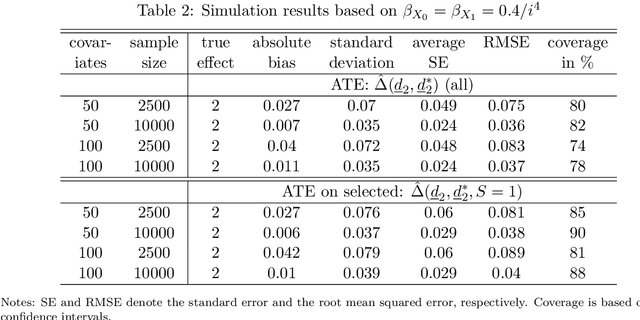

We consider evaluating the causal effects of dynamic treatments, i.e. of multiple treatment sequences in various periods, based on double machine learning to control for observed, time-varying covariates in a data-driven way under a selection-on-observables assumption. To this end, we make use of so-called Neyman-orthogonal score functions, which imply the robustness of treatment effect estimation to moderate (local) misspecifications of the dynamic outcome and treatment models. This robustness property permits approximating outcome and treatment models by double machine learning even under high dimensional covariates and is combined with data splitting to prevent overfitting. In addition to effect estimation for the total population, we consider weighted estimation that permits assessing dynamic treatment effects in specific subgroups, e.g. among those treated in the first treatment period. We demonstrate that the estimators are asymptotically normal and $\sqrt{n}$-consistent under specific regularity conditions and investigate their finite sample properties in a simulation study. Finally, we apply the methods to the Job Corps study in order to assess different sequences of training programs under a large set of covariates.
Analysis of artifacts in EEG signals for building BCIs
Sep 18, 2020
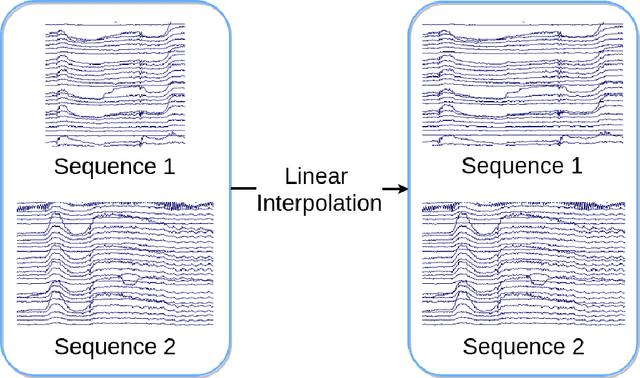

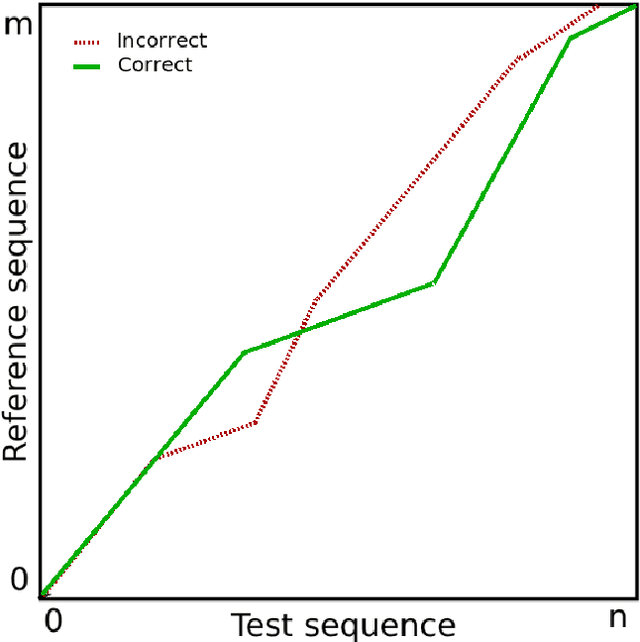
Brain-Computer Interface (BCI) is an essential mechanism that interprets the human brain signal. It provides an assistive technology that enables persons with motor disabilities to communicate with the world and also empowers them to lead independent lives. The common BCI devices use Electroencephalography (EEG) electrical activity recorded from the scalp. EEG signals are noisy owing to the presence of many artifacts, namely, eye blink, head movement, and jaw movement. Such artifacts corrupt the EEG signal and make EEG analysis challenging. This issue is addressed by locating the artifacts and excluding the EEG segment from the analysis, which could lead to a loss of useful information. However, we propose a practical BCI that uses the artifacts which has a low signal to noise ratio. The objective of our work is to classify different types of artifacts, namely eye blink, head nod, head turn, and jaw movements in the EEG signal. The occurrence of the artifacts is first located in the EEG signal. The located artifacts are then classified using linear time and dynamic time warping techniques. The located artifacts can be used by a person with a motor disability to control a smartphone. A speech synthesis application that uses eyeblinks in a single channel EEG system and jaw clinches in four channels EEG system are developed. Word prediction models are used for word completion, thus reducing the number of artifacts required.
LINDT: Tackling Negative Federated Learning with Local Adaptation
Nov 23, 2020
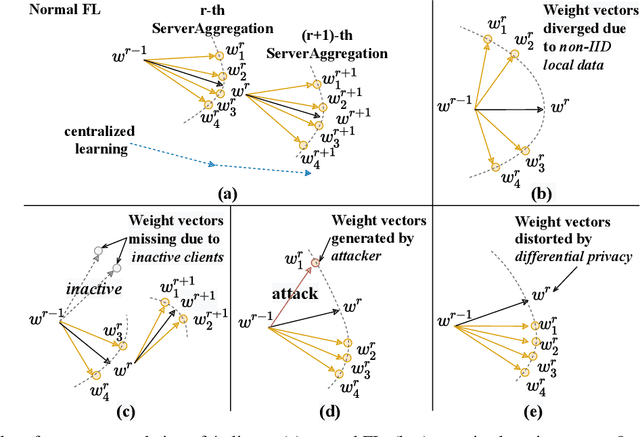
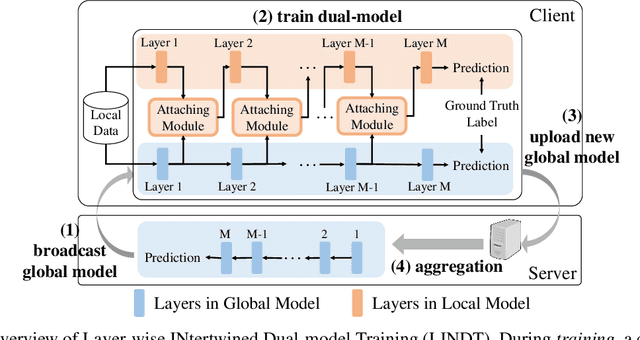

Federated Learning (FL) is a promising distributed learning paradigm, which allows a number of data owners (also called clients) to collaboratively learn a shared model without disclosing each client's data. However, FL may fail to proceed properly, amid a state that we call negative federated learning (NFL). This paper addresses the problem of negative federated learning. We formulate a rigorous definition of NFL and analyze its essential cause. We propose a novel framework called LINDT for tackling NFL in run-time. The framework can potentially work with any neural-network-based FL systems for NFL detection and recovery. Specifically, we introduce a metric for detecting NFL from the server. On occasion of NFL recovery, the framework makes adaptation to the federated model on each client's local data by learning a Layer-wise Intertwined Dual-model. Experiment results show that the proposed approach can significantly improve the performance of FL on local data in various scenarios of NFL.
SAFCAR: Structured Attention Fusion for Compositional Action Recognition
Dec 03, 2020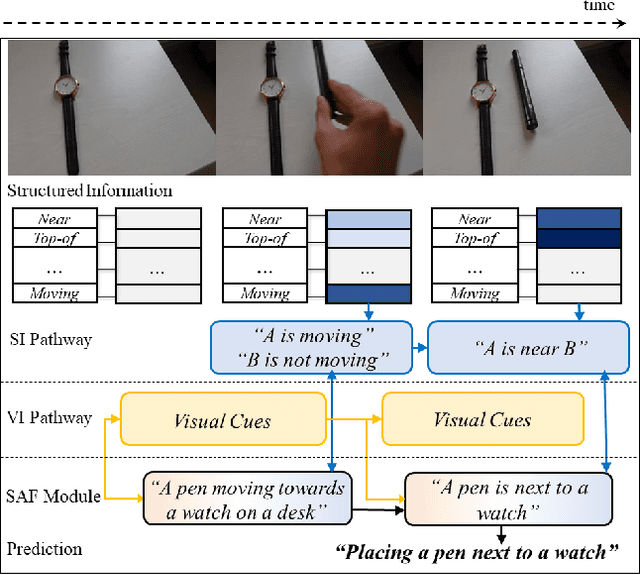
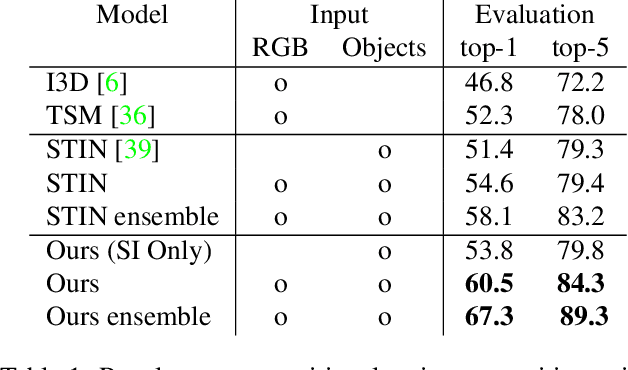
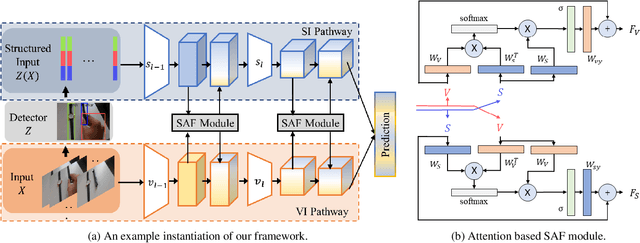
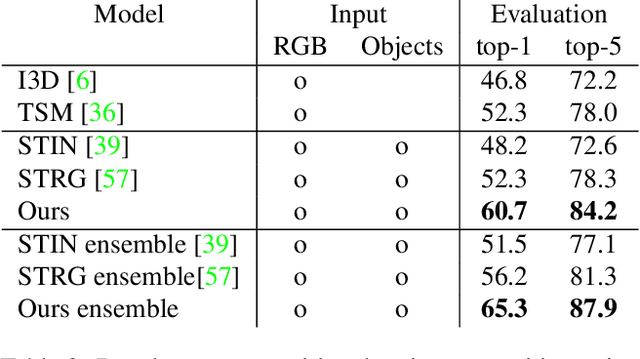
We present a general framework for compositional action recognition -- i.e. action recognition where the labels are composed out of simpler components such as subjects, atomic-actions and objects. The main challenge in compositional action recognition is that there is a combinatorially large set of possible actions that can be composed using basic components. However, compositionality also provides a structure that can be exploited. To do so, we develop and test a novel Structured Attention Fusion (SAF) self-attention mechanism to combine information from object detections, which capture the time-series structure of an action, with visual cues that capture contextual information. We show that our approach recognizes novel verb-noun compositions more effectively than current state of the art systems, and it generalizes to unseen action categories quite efficiently from only a few labeled examples. We validate our approach on the challenging Something-Else tasks from the Something-Something-V2 dataset. We further show that our framework is flexible and can generalize to a new domain by showing competitive results on the Charades-Fewshot dataset.
Handling Missing Data in Decision Trees: A Probabilistic Approach
Jun 29, 2020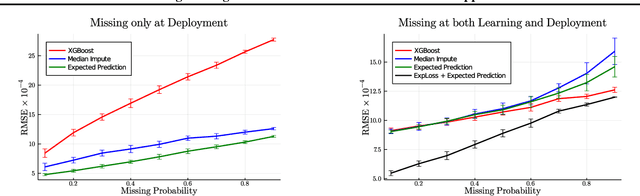

Decision trees are a popular family of models due to their attractive properties such as interpretability and ability to handle heterogeneous data. Concurrently, missing data is a prevalent occurrence that hinders performance of machine learning models. As such, handling missing data in decision trees is a well studied problem. In this paper, we tackle this problem by taking a probabilistic approach. At deployment time, we use tractable density estimators to compute the "expected prediction" of our models. At learning time, we fine-tune parameters of already learned trees by minimizing their "expected prediction loss" w.r.t.\ our density estimators. We provide brief experiments showcasing effectiveness of our methods compared to few baselines.
Apollonius Allocation Algorithm for Heterogeneous Pursuers to Capture Multiple Evaders
Jun 19, 2020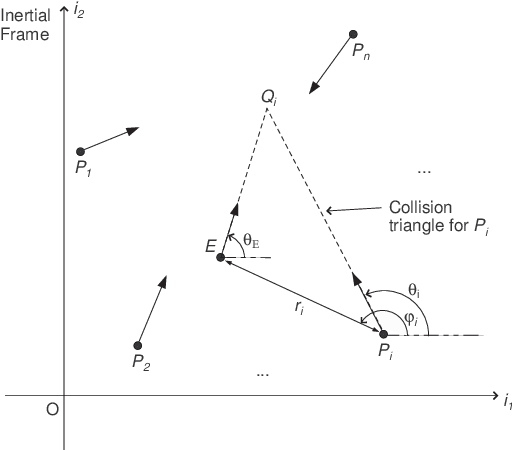
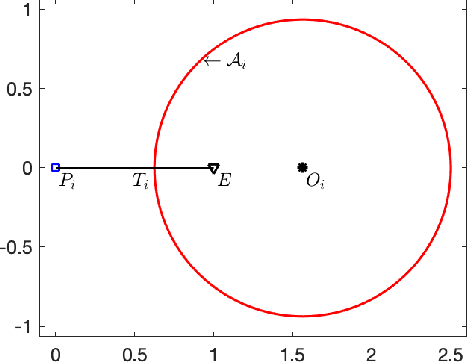
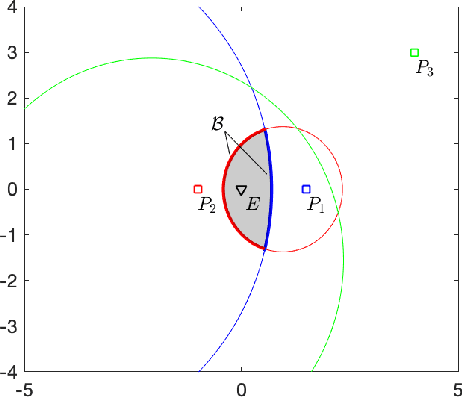
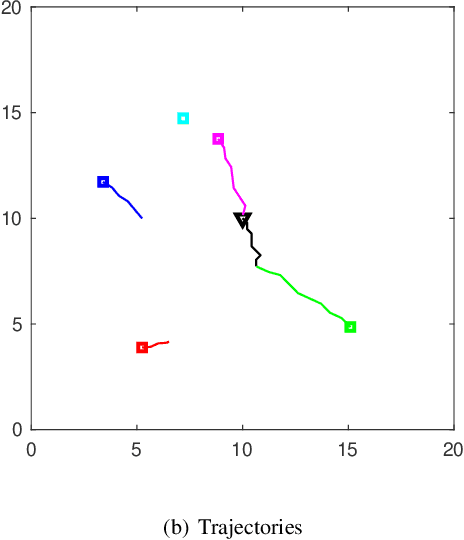
In this paper, we address pursuit-evasion problems involving multiple pursuers and multiple evaders. The pursuer and the evader teams are assumed to be heterogeneous, in the sense that each team has agents with different speed capabilities. The pursuers are all assumed to be following a constant bearing strategy. A dynamic divide and conquer approach, where at every time instant each evader is assigned to a set of pursuers based on the instantaneous positions of all the players, is introduced to solve the multi-agent pursuit problem. In this regard, the corresponding multi-pursuer single-evader problem is analyzed first. Assuming that the evader can follow any strategy, a dynamic task allocation algorithm is proposed for the pursuers. The algorithm is based on the well-known Apollonius circle and allows the pursuers to allocate their resources in an intelligent manner while guaranteeing the capture of the evader in minimum time. The proposed algorithm is then extended to assign pursuers in multi-evader settings that is proven to capture all the evaders in finite time.
Crossover-SGD: A gossip-based communication in distributed deep learning for alleviating large mini-batch problem and enhancing scalability
Dec 30, 2020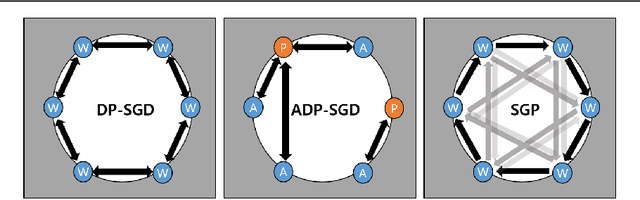
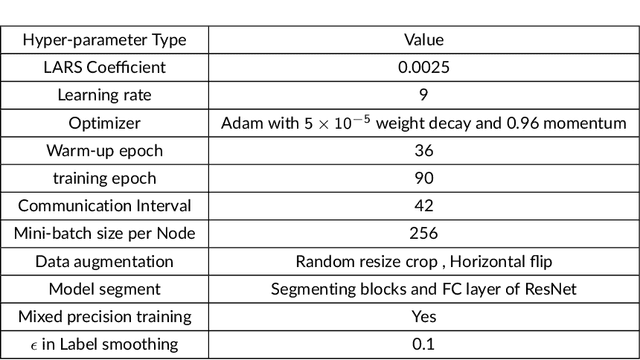
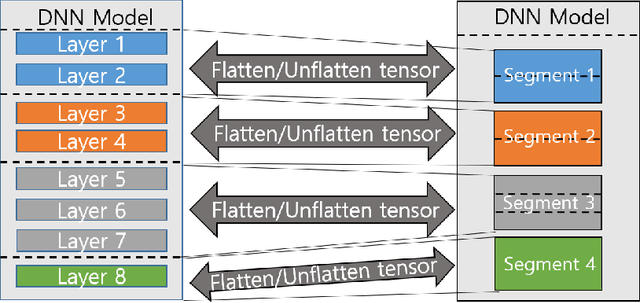
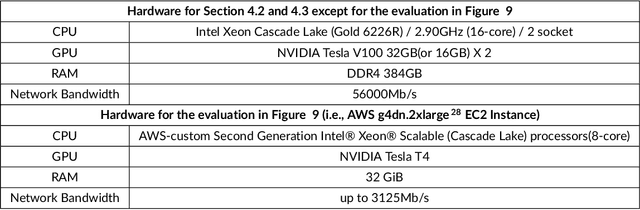
Distributed deep learning is an effective way to reduce the training time of deep learning for large datasets as well as complex models. However, the limited scalability caused by network overheads makes it difficult to synchronize the parameters of all workers. To resolve this problem, gossip-based methods that demonstrates stable scalability regardless of the number of workers have been proposed. However, to use gossip-based methods in general cases, the validation accuracy for a large mini-batch needs to be verified. To verify this, we first empirically study the characteristics of gossip methods in a large mini-batch problem and observe that the gossip methods preserve higher validation accuracy than AllReduce-SGD(Stochastic Gradient Descent) when the number of batch sizes is increased and the number of workers is fixed. However, the delayed parameter propagation of the gossip-based models decreases validation accuracy in large node scales. To cope with this problem, we propose Crossover-SGD that alleviates the delay propagation of weight parameters via segment-wise communication and load balancing random network topology. We also adapt hierarchical communication to limit the number of workers in gossip-based communication methods. To validate the effectiveness of our proposed method, we conduct empirical experiments and observe that our Crossover-SGD shows higher node scalability than SGP(Stochastic Gradient Push).
LaHAR: Latent Human Activity Recognition using LDA
Nov 23, 2020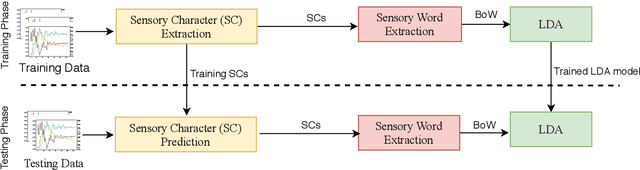

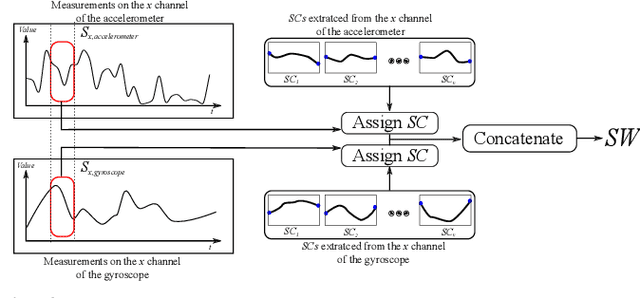
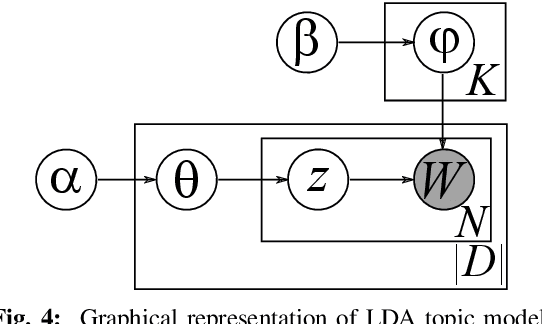
Processing sequential multi-sensor data becomes important in many tasks due to the dramatic increase in the availability of sensors that can acquire sequential data over time. Human Activity Recognition (HAR) is one of the fields which are actively benefiting from this availability. Unlike most of the approaches addressing HAR by considering predefined activity classes, this paper proposes a novel approach to discover the latent HAR patterns in sequential data. To this end, we employed Latent Dirichlet Allocation (LDA), which is initially a topic modelling approach used in text analysis. To make the data suitable for LDA, we extract the so-called "sensory words" from the sequential data. We carried out experiments on a challenging HAR dataset, demonstrating that LDA is capable of uncovering underlying structures in sequential data, which provide a human-understandable representation of the data. The extrinsic evaluations reveal that LDA is capable of accurately clustering HAR data sequences compared to the labelled activities.
Joint Optimization of Trajectory, Propulsion and Thrust Powers for Covert UAV-on-UAV Video Tracking and Surveillance
Dec 22, 2020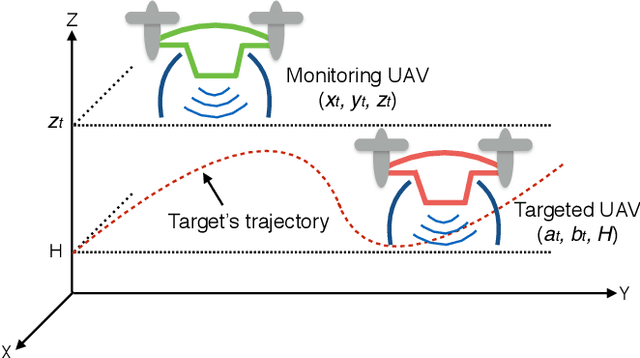
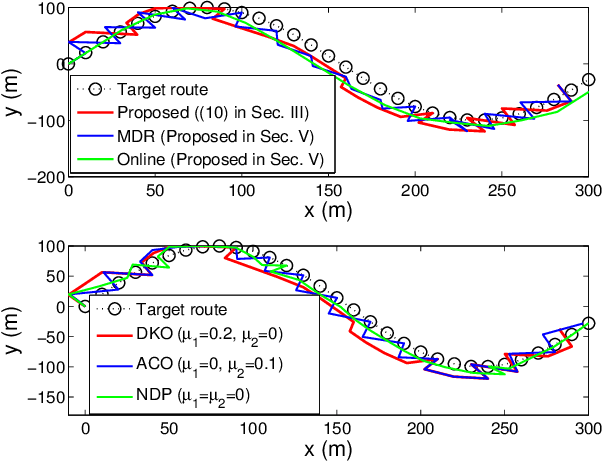
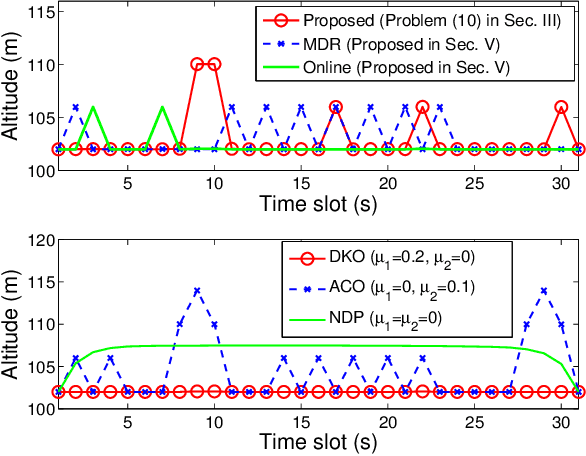
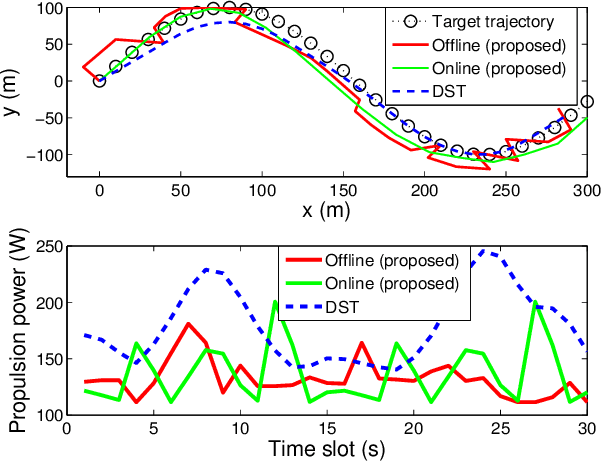
Autonomous tracking of suspicious unmanned aerial vehicles (UAVs) by legitimate monitoring UAVs (or monitors) can be crucial to public safety and security. It is non-trivial to optimize the trajectory of a monitor while conceiving its monitoring intention, due to typically non-convex propulsion and thrust power functions. This paper presents a novel framework to jointly optimize the propulsion and thrust powers, as well as the 3D trajectory of a solar-powered monitor which conducts covert, video-based, UAV-on-UAV tracking and surveillance. A multi-objective problem is formulated to minimize the energy consumption of the monitor and maximize a weighted sum of distance keeping and altitude changing, which measures the disguising of the monitor. Based on the practical power models of the UAV propulsion, thrust and hovering, and the model of the harvested solar power, the problem is non-convex and intangible for existing solvers. We convexify the propulsion power by variable substitution, and linearize the solar power. With successive convex approximation, the resultant problem is then transformed with tightened constraints and efficiently solved by the proximal difference-of-convex algorithm with extrapolation in polynomial time. The proposed scheme can be also applied online. Extensive simulations corroborate the merits of the scheme, as compared to baseline schemes with partial or no disguising.