 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Full Mediation of Treatment Effects and the Identifiability of Causal Mechanisms
Mar 04, 2026In causal analysis, understanding the causal mechanisms through which an intervention or treatment affects an outcome is often of central interest. We propose a test to evaluate (i) whether the causal effect of a treatment that is randomly assigned conditional on covariates is fully mediated by, or operates exclusively through, observed intermediate outcomes (referred to as mediators or surrogate outcomes), and (ii) whether the various causal mechanisms operating through different mediators are identifiable conditional on covariates. We demonstrate that if both full mediation and identification of causal mechanisms hold, then the conditionally random treatment is conditionally independent of the outcome given the mediators and covariates. Furthermore, we extend our framework to settings with non-randomly assigned treatments. We show that, in this case, full mediation remains testable, while identification of causal mechanisms is no longer guaranteed. We propose a double machine learning framework for implementing the test that can incorporate high-dimensional covariates and is root-n consistent and asymptotically normal under specific regularity conditions. We also present a simulation study demonstrating good finite-sample performance of our method, along with two empirical applications revisiting randomized experiments on maternal mental health and social norms.
Double machine learning for sample selection models
Dec 09, 2020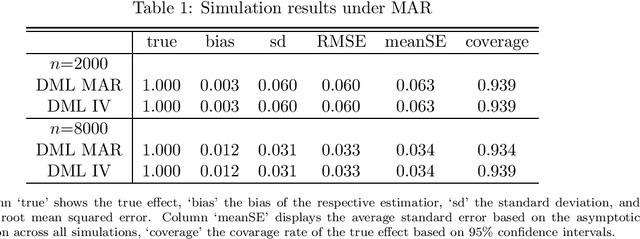
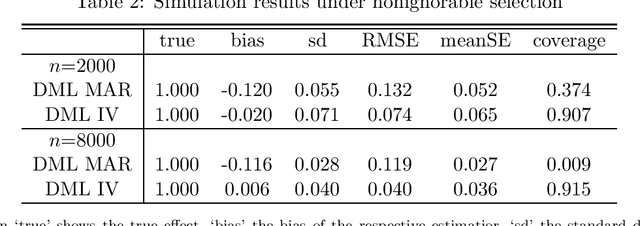
This paper considers treatment evaluation when outcomes are only observed for a subpopulation due to sample selection or outcome attrition/non-response. For identification, we combine a selection-on-observables assumption for treatment assignment with either selection-on-observables or instrumental variable assumptions concerning the outcome attrition/sample selection process. To control in a data-driven way for potentially high dimensional pre-treatment covariates that motivate the selection-on-observables assumptions, we adapt the double machine learning framework to sample selection problems. That is, we make use of (a) Neyman-orthogonal and doubly robust score functions, which imply the robustness of treatment effect estimation to moderate regularization biases in the machine learning-based estimation of the outcome, treatment, or sample selection models and (b) sample splitting (or cross-fitting) to prevent overfitting bias. We demonstrate that the proposed estimators are asymptotically normal and root-n consistent under specific regularity conditions concerning the machine learners. The estimator is available in the causalweight package for the statistical software R.
Evaluating (weighted) dynamic treatment effects by double machine learning
Dec 03, 2020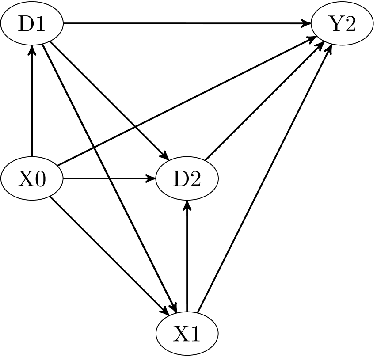

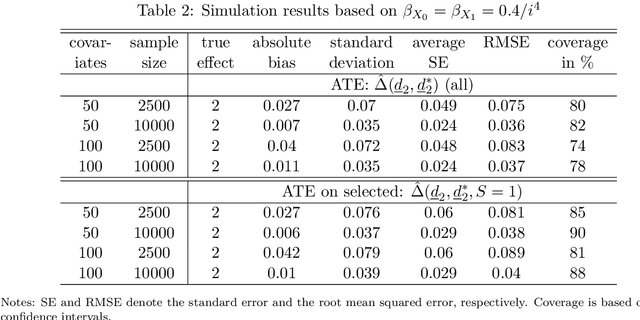

We consider evaluating the causal effects of dynamic treatments, i.e. of multiple treatment sequences in various periods, based on double machine learning to control for observed, time-varying covariates in a data-driven way under a selection-on-observables assumption. To this end, we make use of so-called Neyman-orthogonal score functions, which imply the robustness of treatment effect estimation to moderate (local) misspecifications of the dynamic outcome and treatment models. This robustness property permits approximating outcome and treatment models by double machine learning even under high dimensional covariates and is combined with data splitting to prevent overfitting. In addition to effect estimation for the total population, we consider weighted estimation that permits assessing dynamic treatment effects in specific subgroups, e.g. among those treated in the first treatment period. We demonstrate that the estimators are asymptotically normal and $\sqrt{n}$-consistent under specific regularity conditions and investigate their finite sample properties in a simulation study. Finally, we apply the methods to the Job Corps study in order to assess different sequences of training programs under a large set of covariates.