 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperiorGAT: Graph Attention Networks for Sparse LiDAR Point Cloud Reconstruction in Autonomous Systems
Dec 30, 2025LiDAR-based perception in autonomous systems is constrained by fixed vertical beam resolution and further compromised by beam dropout resulting from environmental occlusions. This paper introduces SuperiorGAT, a graph attention-based framework designed to reconstruct missing elevation information in sparse LiDAR point clouds. By modeling LiDAR scans as beam-aware graphs and incorporating gated residual fusion with feed-forward refinement, SuperiorGAT enables accurate reconstruction without increasing network depth. To evaluate performance, structured beam dropout is simulated by removing every fourth vertical scanning beam. Extensive experiments across diverse KITTI environments, including Person, Road, Campus, and City sequences, demonstrate that SuperiorGAT consistently achieves lower reconstruction error and improved geometric consistency compared to PointNet-based models and deeper GAT baselines. Qualitative X-Z projections further confirm the model's ability to preserve structural integrity with minimal vertical distortion. These results suggest that architectural refinement offers a computationally efficient method for improving LiDAR resolution without requiring additional sensor hardware.
A Graph Attention Network-Based Framework for Reconstructing Missing LiDAR Beams
Dec 13, 2025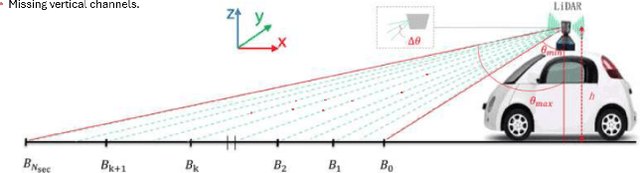
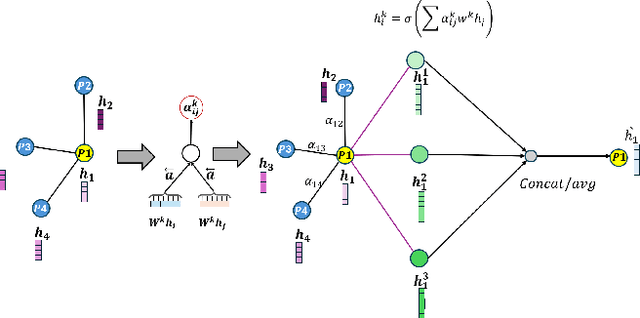
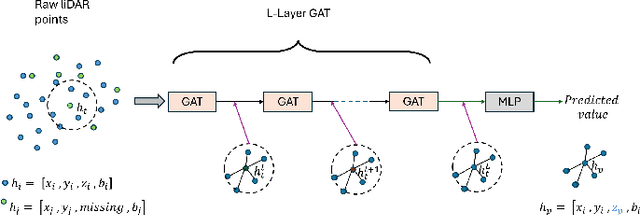
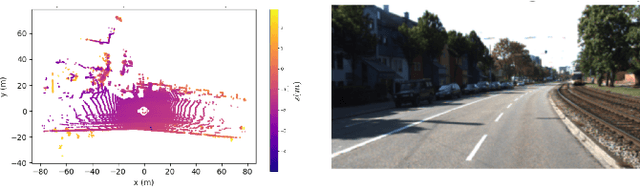
Vertical beam dropout in spinning LiDAR sensors triggered by hardware aging, dust, snow, fog, or bright reflections removes entire vertical slices from the point cloud and severely degrades 3D perception in autonomous vehicles. This paper proposes a Graph Attention Network (GAT)-based framework that reconstructs these missing vertical channels using only the current LiDAR frame, with no camera images or temporal information required. Each LiDAR sweep is represented as an unstructured spatial graph: points are nodes and edges connect nearby points while preserving the original beam-index ordering. A multi-layer GAT learns adaptive attention weights over local geometric neighborhoods and directly regresses the missing elevation (z) values at dropout locations. Trained and evaluated on 1,065 raw KITTI sequences with simulated channel dropout, the method achieves an average height RMSE of 11.67 cm, with 87.98% of reconstructed points falling within a 10 cm error threshold. Inference takes 14.65 seconds per frame on a single GPU, and reconstruction quality remains stable for different neighborhood sizes k. These results show that a pure graph attention model operating solely on raw point-cloud geometry can effectively recover dropped vertical beams under realistic sensor degradation.
COVID-CLNet: COVID-19 Detection with Compressive Deep Learning Approaches
Dec 03, 2020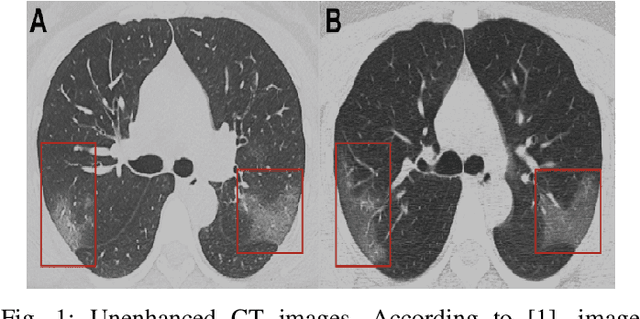
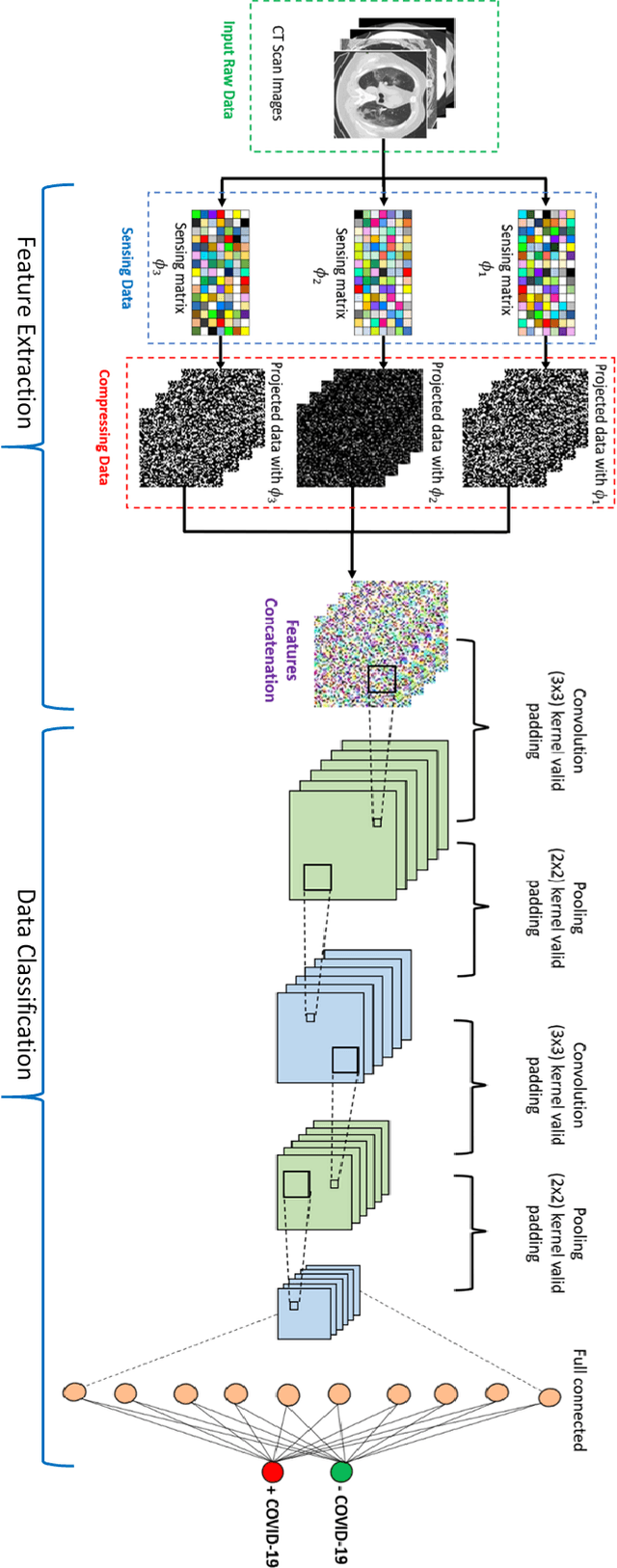

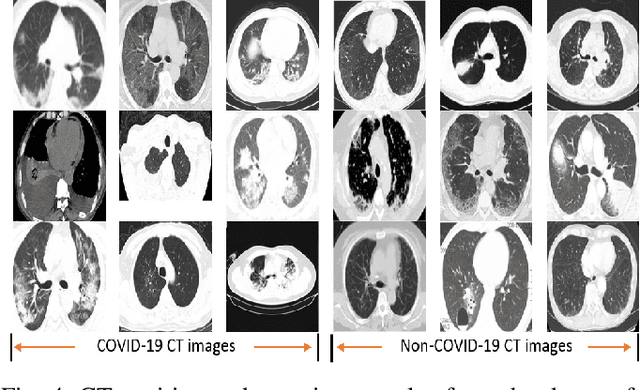
One of the most serious global health threat is COVID-19 pandemic. The emphasis on improving diagnosis and increasing the diagnostic capability helps stopping its spread significantly. Therefore, to assist the radiologist or other medical professional to detect and identify the COVID-19 cases in the shortest possible time, we propose a computer-aided detection (CADe) system that uses the computed tomography (CT) scan images. This proposed boosted deep learning network (CLNet) is based on the implementation of Deep Learning (DL) networks as a complementary to the Compressive Learning (CL). We utilize our inception feature extraction technique in the measurement domain using CL to represent the data features into a new space with less dimensionality before accessing the Convolutional Neural Network. All original features have been contributed equally in the new space using a sensing matrix. Experiments performed on different compressed methods show promising results for COVID-19 detection. In addition, our novel weighted method based on different sensing matrices that used to capture boosted features demonstrates an improvement in the performance of the proposed method.