 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Near-Optimal Gradient Sparsification Cost for Scalable Distributed Deep Learning
Feb 21, 2024



Communication overhead is a major obstacle to scaling distributed training systems. Gradient sparsification is a potential optimization approach to reduce the communication volume without significant loss of model fidelity. However, existing gradient sparsification methods have low scalability owing to inefficient design of their algorithms, which raises the communication overhead significantly. In particular, gradient build-up and inadequate sparsity control methods degrade the sparsification performance considerably. Moreover, communication traffic increases drastically owing to workload imbalance of gradient selection between workers. To address these challenges, we propose a novel gradient sparsification scheme called ExDyna. In ExDyna, the gradient tensor of the model comprises fined-grained blocks, and contiguous blocks are grouped into non-overlapping partitions. Each worker selects gradients in its exclusively allocated partition so that gradient build-up never occurs. To balance the workload of gradient selection between workers, ExDyna adjusts the topology of partitions by comparing the workloads of adjacent partitions. In addition, ExDyna supports online threshold scaling, which estimates the accurate threshold of gradient selection on-the-fly. Accordingly, ExDyna can satisfy the user-required sparsity level during a training period regardless of models and datasets. Therefore, ExDyna can enhance the scalability of distributed training systems by preserving near-optimal gradient sparsification cost. In experiments, ExDyna outperformed state-of-the-art sparsifiers in terms of training speed and sparsification performance while achieving high accuracy.
MiCRO: Near-Zero Cost Gradient Sparsification for Scaling and Accelerating Distributed DNN Training
Oct 02, 2023



Gradient sparsification is a communication optimisation technique for scaling and accelerating distributed deep neural network (DNN) training. It reduces the increasing communication traffic for gradient aggregation. However, existing sparsifiers have poor scalability because of the high computational cost of gradient selection and/or increase in communication traffic. In particular, an increase in communication traffic is caused by gradient build-up and inappropriate threshold for gradient selection. To address these challenges, we propose a novel gradient sparsification method called MiCRO. In MiCRO, the gradient vector is partitioned, and each partition is assigned to the corresponding worker. Each worker then selects gradients from its partition, and the aggregated gradients are free from gradient build-up. Moreover, MiCRO estimates the accurate threshold to maintain the communication traffic as per user requirement by minimising the compression ratio error. MiCRO enables near-zero cost gradient sparsification by solving existing problems that hinder the scalability and acceleration of distributed DNN training. In our extensive experiments, MiCRO outperformed state-of-the-art sparsifiers with an outstanding convergence rate.
DEFT: Exploiting Gradient Norm Difference between Model Layers for Scalable Gradient Sparsification
Jul 13, 2023



Gradient sparsification is a widely adopted solution for reducing the excessive communication traffic in distributed deep learning. However, most existing gradient sparsifiers have relatively poor scalability because of considerable computational cost of gradient selection and/or increased communication traffic owing to gradient build-up. To address these challenges, we propose a novel gradient sparsification scheme, DEFT, that partitions the gradient selection task into sub tasks and distributes them to workers. DEFT differs from existing sparsifiers, wherein every worker selects gradients among all gradients. Consequently, the computational cost can be reduced as the number of workers increases. Moreover, gradient build-up can be eliminated because DEFT allows workers to select gradients in partitions that are non-intersecting (between workers). Therefore, even if the number of workers increases, the communication traffic can be maintained as per user requirement. To avoid the loss of significance of gradient selection, DEFT selects more gradients in the layers that have a larger gradient norm than the other layers. Because every layer has a different computational load, DEFT allocates layers to workers using a bin-packing algorithm to maintain a balanced load of gradient selection between workers. In our empirical evaluation, DEFT shows a significant improvement in training performance in terms of speed in gradient selection over existing sparsifiers while achieving high convergence performance.
Empirical Analysis on Top-k Gradient Sparsification for Distributed Deep Learning in a Supercomputing Environment
Sep 18, 2022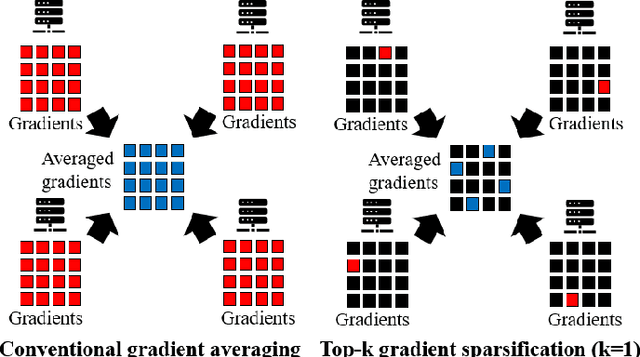
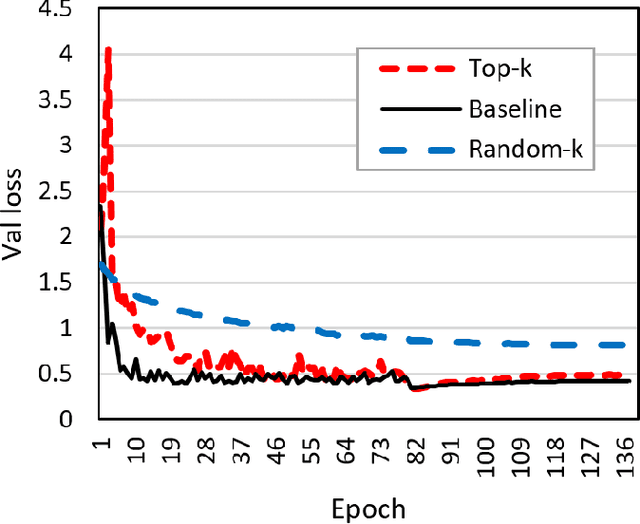
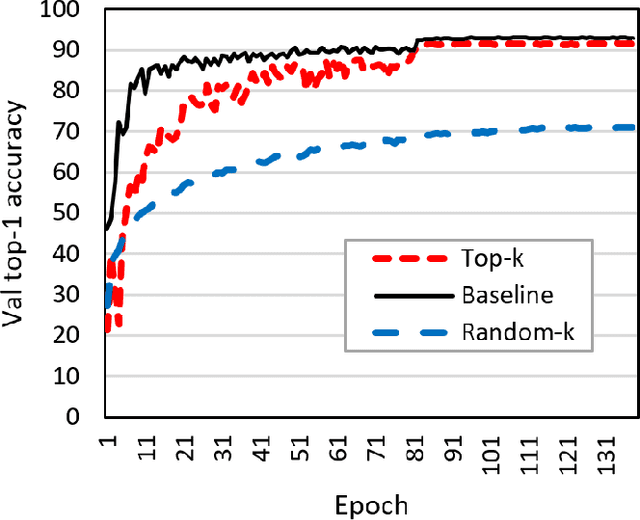
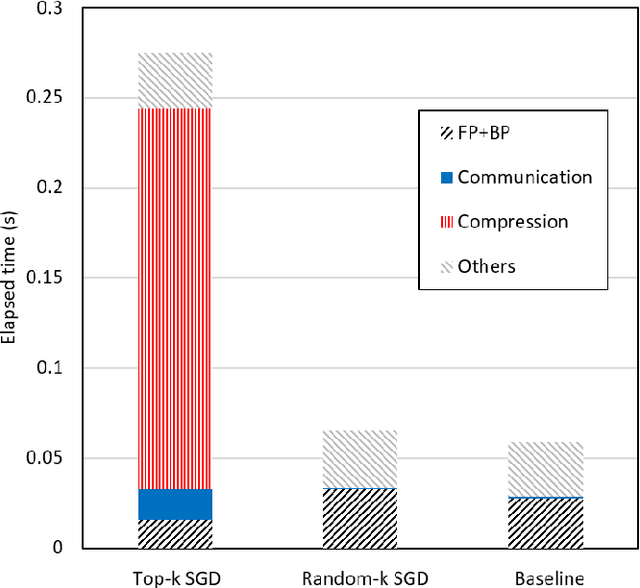
To train deep learning models faster, distributed training on multiple GPUs is the very popular scheme in recent years. However, the communication bandwidth is still a major bottleneck of training performance. To improve overall training performance, recent works have proposed gradient sparsification methods that reduce the communication traffic significantly. Most of them require gradient sorting to select meaningful gradients such as Top-k gradient sparsification (Top-k SGD). However, Top-k SGD has a limit to increase the speed up overall training performance because gradient sorting is significantly inefficient on GPUs. In this paper, we conduct experiments that show the inefficiency of Top-k SGD and provide the insight of the low performance. Based on observations from our empirical analysis, we plan to yield a high performance gradient sparsification method as a future work.
Crossover-SGD: A gossip-based communication in distributed deep learning for alleviating large mini-batch problem and enhancing scalability
Dec 30, 2020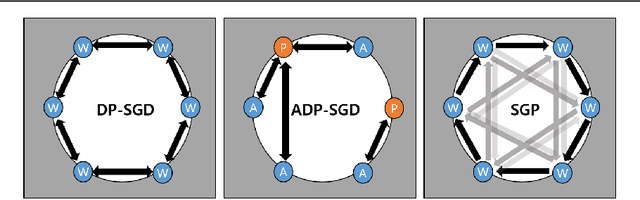
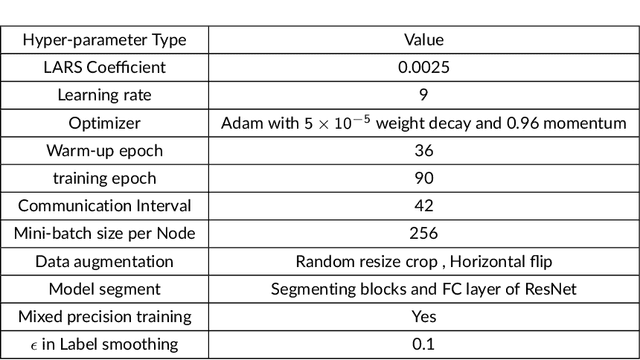
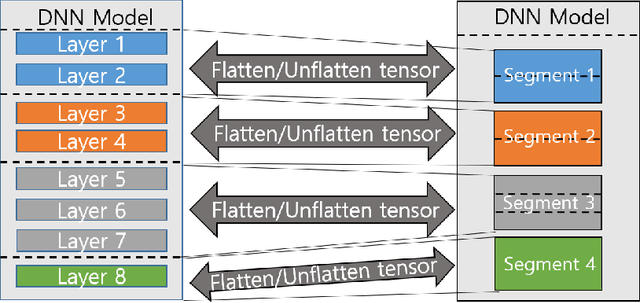
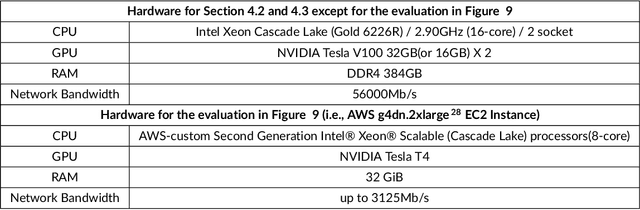
Distributed deep learning is an effective way to reduce the training time of deep learning for large datasets as well as complex models. However, the limited scalability caused by network overheads makes it difficult to synchronize the parameters of all workers. To resolve this problem, gossip-based methods that demonstrates stable scalability regardless of the number of workers have been proposed. However, to use gossip-based methods in general cases, the validation accuracy for a large mini-batch needs to be verified. To verify this, we first empirically study the characteristics of gossip methods in a large mini-batch problem and observe that the gossip methods preserve higher validation accuracy than AllReduce-SGD(Stochastic Gradient Descent) when the number of batch sizes is increased and the number of workers is fixed. However, the delayed parameter propagation of the gossip-based models decreases validation accuracy in large node scales. To cope with this problem, we propose Crossover-SGD that alleviates the delay propagation of weight parameters via segment-wise communication and load balancing random network topology. We also adapt hierarchical communication to limit the number of workers in gossip-based communication methods. To validate the effectiveness of our proposed method, we conduct empirical experiments and observe that our Crossover-SGD shows higher node scalability than SGP(Stochastic Gradient Push).