 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
2-D Embedding of Large and High-dimensional Data with Minimal Memory and Computational Time Requirements
Feb 04, 2019
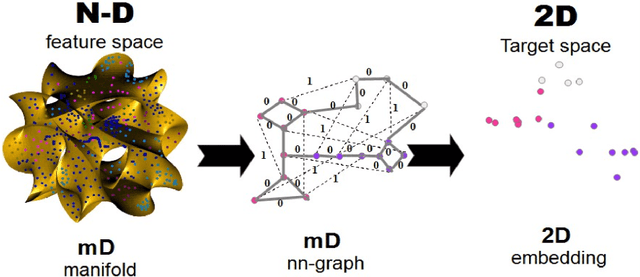

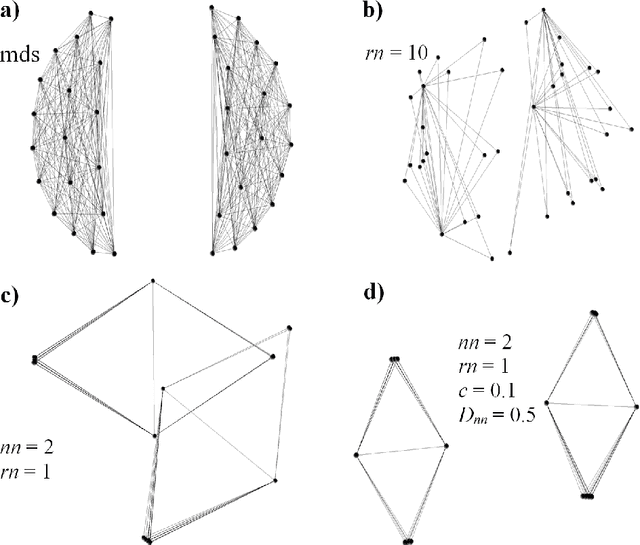

In the advent of big data era, interactive visualization of large data sets consisting of M*10^5+ high-dimensional feature vectors of length N (N ~ 10^3+), is an indispensable tool for data exploratory analysis. The state-of-the-art data embedding (DE) methods of N-D data into 2-D (3-D) visually perceptible space (e.g., based on t-SNE concept) are too demanding computationally to be efficiently employed for interactive data analytics of large and high-dimensional datasets. Herein we present a simple method, ivhd (interactive visualization of high-dimensional data tool), which radically outperforms the modern data-embedding algorithms in both computational and memory loads, while retaining high quality of N-D data embedding in 2-D (3-D). We show that DE problem is equivalent to the nearest neighbor nn-graph visualization, where only indices of a few nearest neighbors of each data sample has to be known, and binary distance between data samples -- 0 to the nearest and 1 to the other samples -- is defined. These improvements reduce the time-complexity and memory load from O(M log M) to O(M), and ensure minimal O(M) proportionality coefficient as well. We demonstrate high efficiency, quality and robustness of ivhd on popular benchmark datasets such as MNIST, 20NG, NORB and RCV1.
Neural Network architectures to classify emotions in Indian Classical Music
Feb 01, 2021
Music is often considered as the language of emotions. It has long been known to elicit emotions in human being and thus categorizing music based on the type of emotions they induce in human being is a very intriguing topic of research. When the task comes to classify emotions elicited by Indian Classical Music (ICM), it becomes much more challenging because of the inherent ambiguity associated with ICM. The fact that a single musical performance can evoke a variety of emotional response in the audience is implicit to the nature of ICM renditions. With the rapid advancements in the field of Deep Learning, this Music Emotion Recognition (MER) task is becoming more and more relevant and robust, hence can be applied to one of the most challenging test case i.e. classifying emotions elicited from ICM. In this paper we present a new dataset called JUMusEmoDB which presently has 400 audio clips (30 seconds each) where 200 clips correspond to happy emotions and the remaining 200 clips correspond to sad emotion. For supervised classification purposes, we have used 4 existing deep Convolutional Neural Network (CNN) based architectures (resnet18, mobilenet v2.0, squeezenet v1.0 and vgg16) on corresponding music spectrograms of the 2000 sub-clips (where every clip was segmented into 5 sub-clips of about 5 seconds each) which contain both time as well as frequency domain information. The initial results are quite inspiring, and we look forward to setting the baseline values for the dataset using this architecture. This type of CNN based classification algorithm using a rich corpus of Indian Classical Music is unique even in the global perspective and can be replicated in other modalities of music also. This dataset is still under development and we plan to include more data containing other emotional features as well. We plan to make the dataset publicly available soon.
A Lightweight Neural Network for Monocular View Generation with Occlusion Handling
Jul 24, 2020
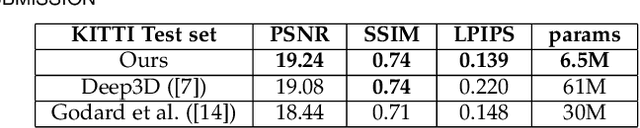
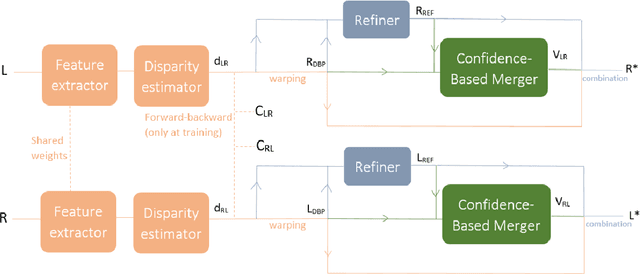
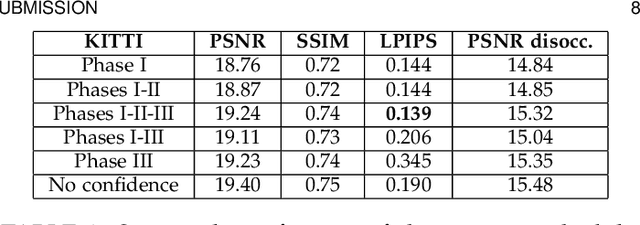
In this article, we present a very lightweight neural network architecture, trained on stereo data pairs, which performs view synthesis from one single image. With the growing success of multi-view formats, this problem is indeed increasingly relevant. The network returns a prediction built from disparity estimation, which fills in wrongly predicted regions using a occlusion handling technique. To do so, during training, the network learns to estimate the left-right consistency structural constraint on the pair of stereo input images, to be able to replicate it at test time from one single image. The method is built upon the idea of blending two predictions: a prediction based on disparity estimation, and a prediction based on direct minimization in occluded regions. The network is also able to identify these occluded areas at training and at test time by checking the pixelwise left-right consistency of the produced disparity maps. At test time, the approach can thus generate a left-side and a right-side view from one input image, as well as a depth map and a pixelwise confidence measure in the prediction. The work outperforms visually and metric-wise state-of-the-art approaches on the challenging KITTI dataset, all while reducing by a very significant order of magnitude (5 or 10 times) the required number of parameters (6.5 M).
Continual Model-Based Reinforcement Learning with Hypernetworks
Sep 25, 2020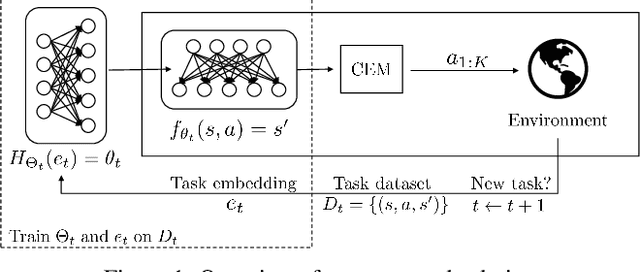

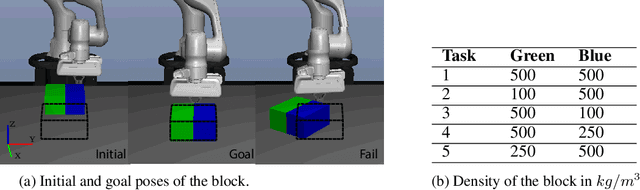

Effective planning in model-based reinforcement learning (MBRL) and model-predictive control (MPC) relies on the accuracy of the learned dynamics model. In many instances of MBRL and MPC, this model is assumed to be stationary and is periodically re-trained from scratch on state transition experience collected from the beginning of environment interactions. This implies that the time required to train the dynamics model - and the pause required between plan executions - grows linearly with the size of the collected experience. We argue that this is too slow for lifelong robot learning and propose HyperCRL, a method that continually learns the encountered dynamics in a sequence of tasks using task-conditional hypernetworks. Our method has three main attributes: first, it enables constant-time dynamics learning sessions between planning and only needs to store the most recent fixed-size portion of the state transition experience; second, it uses fixed-capacity hypernetworks to represent non-stationary and task-aware dynamics; third, it outperforms existing continual learning alternatives that rely on fixed-capacity networks, and does competitively with baselines that remember an ever increasing coreset of past experience. We show that HyperCRL is effective in continual model-based reinforcement learning in robot locomotion and manipulation scenarios, such as tasks involving pushing and door opening. Our project website with code and videos is at this link http://rvl.cs.toronto.edu/blog/2020/hypercrl/
Real-time Lane Marker Detection Using Template Matching with RGB-D Camera
Jun 05, 2018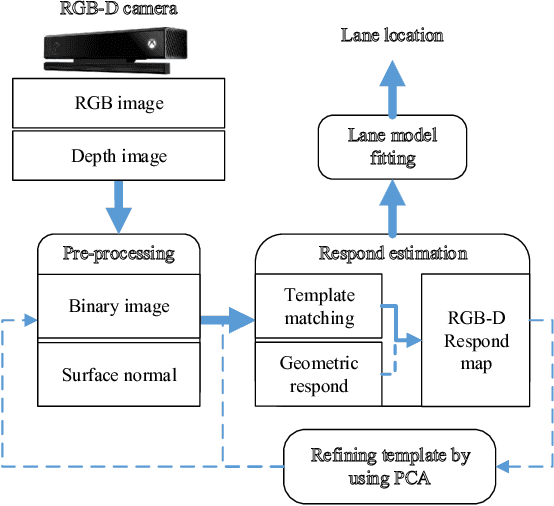



This paper addresses the problem of lane detection which is fundamental for self-driving vehicles. Our approach exploits both colour and depth information recorded by a single RGB-D camera to better deal with negative factors such as lighting conditions and lane-like objects. In the approach, colour and depth images are first converted to a half-binary format and a 2D matrix of 3D points. They are then used as the inputs of template matching and geometric feature extraction processes to form a response map so that its values represent the probability of pixels being lane markers. To further improve the results, the template and lane surfaces are finally refined by principal component analysis and lane model fitting techniques. A number of experiments have been conducted on both synthetic and real datasets. The result shows that the proposed approach can effectively eliminate unwanted noise to accurately detect lane markers in various scenarios. Moreover, the processing speed of 20 frames per second under hardware configuration of a popular laptop computer allows the proposed algorithm to be implemented for real-time autonomous driving applications.
Machine Learning Panel Data Regressions with an Application to Nowcasting Price Earnings Ratios
Aug 08, 2020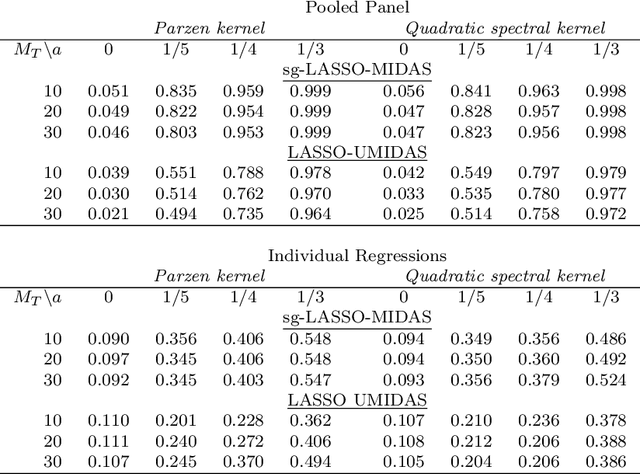
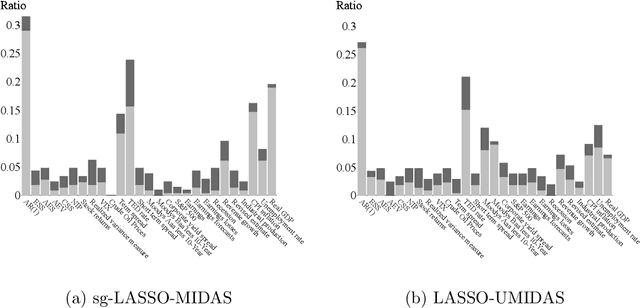
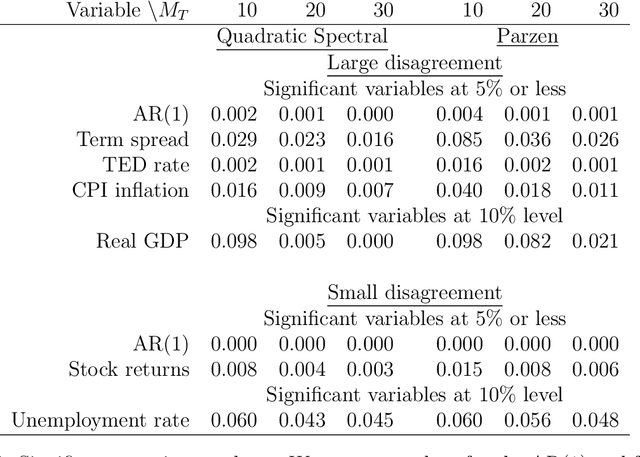
This paper introduces structured machine learning regressions for prediction and nowcasting with panel data consisting of series sampled at different frequencies. Motivated by the empirical problem of predicting corporate earnings for a large cross-section of firms with macroeconomic, financial, and news time series sampled at different frequencies, we focus on the sparse-group LASSO regularization. This type of regularization can take advantage of the mixed frequency time series panel data structures and we find that it empirically outperforms the unstructured machine learning methods. We obtain oracle inequalities for the pooled and fixed effects sparse-group LASSO panel data estimators recognizing that financial and economic data exhibit heavier than Gaussian tails. To that end, we leverage on a novel Fuk-Nagaev concentration inequality for panel data consisting of heavy-tailed $\tau$-mixing processes which may be of independent interest in other high-dimensional panel data settings.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020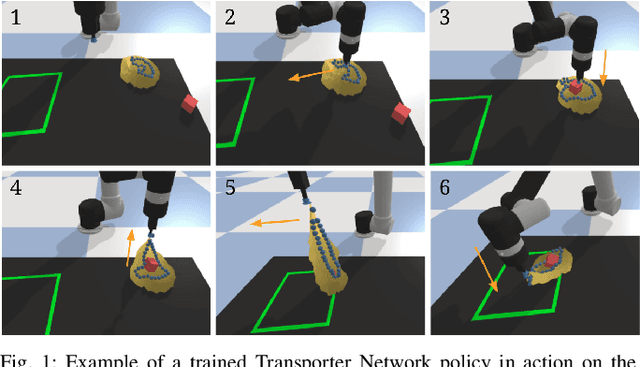
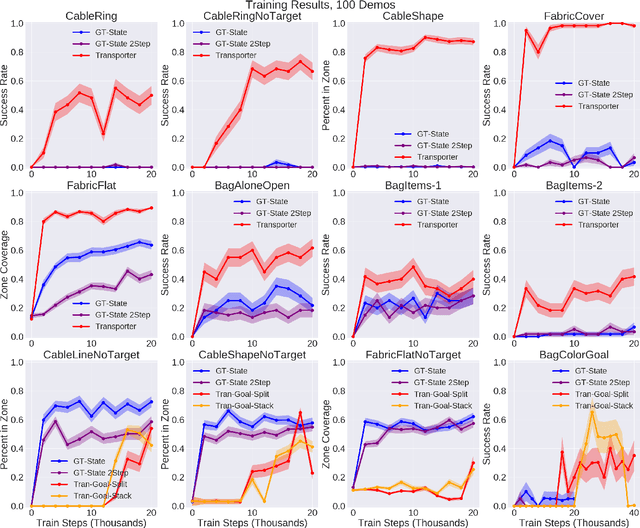
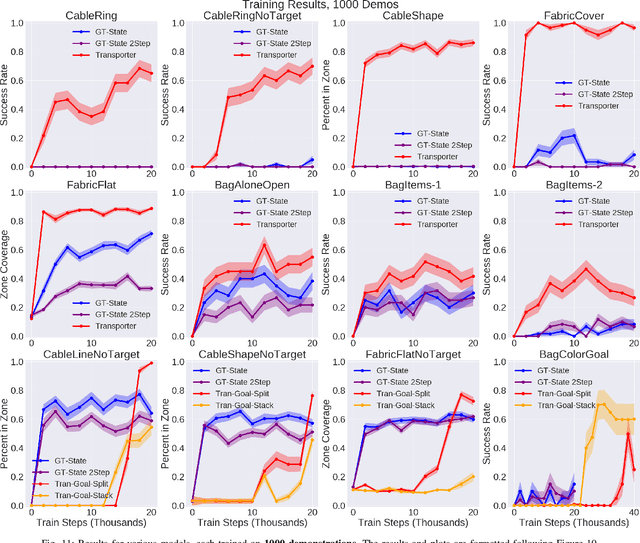
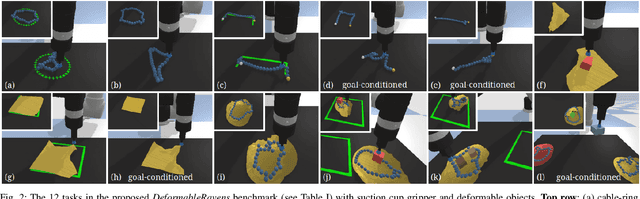
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
ResNet-like Architecture with Low Hardware Requirements
Sep 15, 2020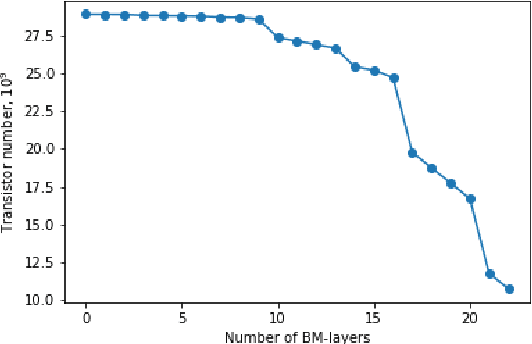
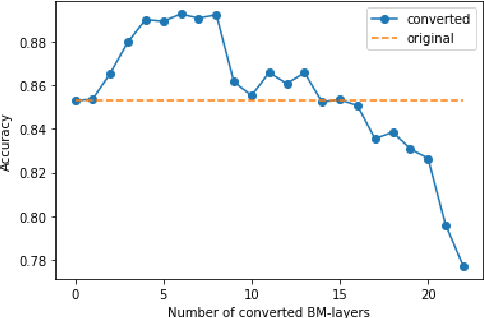
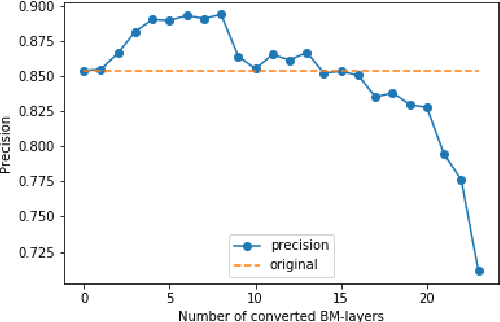
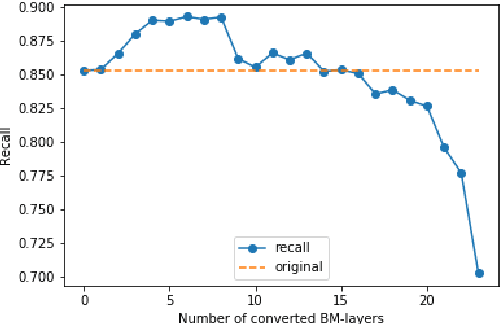
One of the most computationally intensive parts in modern recognition systems is an inference of deep neural networks that are used for image classification, segmentation, enhancement, and recognition. The growing popularity of edge computing makes us look for ways to reduce its time for mobile and embedded devices. One way to decrease the neural network inference time is to modify a neuron model to make it moreefficient for computations on a specific device. The example ofsuch a model is a bipolar morphological neuron model. The bipolar morphological neuron is based on the idea of replacing multiplication with addition and maximum operations. This model has been demonstrated for simple image classification with LeNet-like architectures [1]. In the paper, we introduce a bipolar morphological ResNet (BM-ResNet) model obtained from a much more complex ResNet architecture by converting its layers to bipolar morphological ones. We apply BM-ResNet to image classification on MNIST and CIFAR-10 datasets with only a moderate accuracy decrease from 99.3% to 99.1% and from 85.3% to 85.1%. We also estimate the computational complexity of the resulting model. We show that for the majority of ResNet layers, the considered model requires 2.1-2.9 times fewer logic gates for implementation and 15-30% lower latency.
EvaLDA: Efficient Evasion Attacks Towards Latent Dirichlet Allocation
Dec 09, 2020

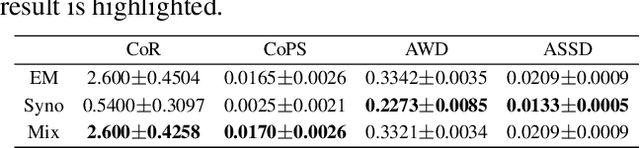

As one of the most powerful topic models, Latent Dirichlet Allocation (LDA) has been used in a vast range of tasks, including document understanding, information retrieval and peer-reviewer assignment. Despite its tremendous popularity, the security of LDA has rarely been studied. This poses severe risks to security-critical tasks such as sentiment analysis and peer-reviewer assignment that are based on LDA. In this paper, we are interested in knowing whether LDA models are vulnerable to adversarial perturbations of benign document examples during inference time. We formalize the evasion attack to LDA models as an optimization problem and prove it to be NP-hard. We then propose a novel and efficient algorithm, EvaLDA to solve it. We show the effectiveness of EvaLDA via extensive empirical evaluations. For instance, in the NIPS dataset, EvaLDA can averagely promote the rank of a target topic from 10 to around 7 by only replacing 1% of the words with similar words in a victim document. Our work provides significant insights into the power and limitations of evasion attacks to LDA models.
Collaborative Tracking and Capture of Aerial Object using UAVs
Oct 04, 2020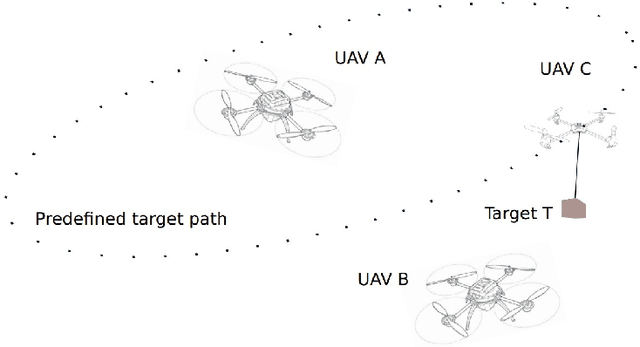

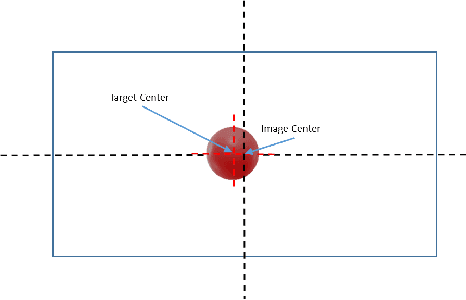
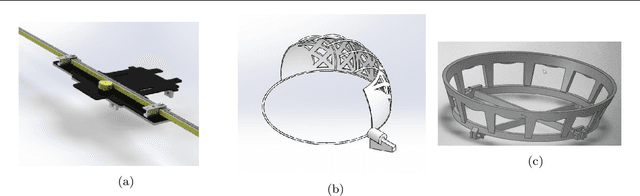
This work details the problem of aerial target capture using multiple UAVs. This problem is motivated from the challenge 1 of Mohammed Bin Zayed International Robotic Challenge 2020. The UAVs utilise visual feedback to autonomously detect target, approach it and capture without disturbing the vehicle which carries the target. Multi-UAV collaboration improves the efficiency of the system and increases the chance of capturing the ball robustly in short span of time. In this paper, the proposed architecture is validated through simulation in ROS-Gazebo environment and is further implemented on hardware.