 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Discriminative Graph Learning from Multi-Class Smooth Signals
Jan 01, 2021
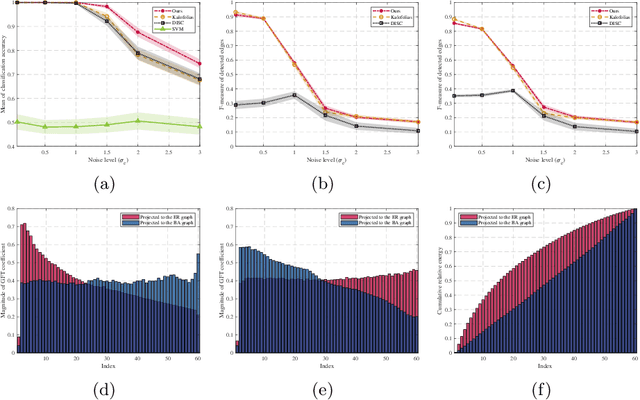
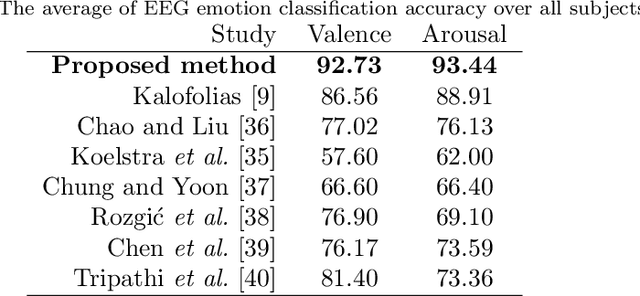
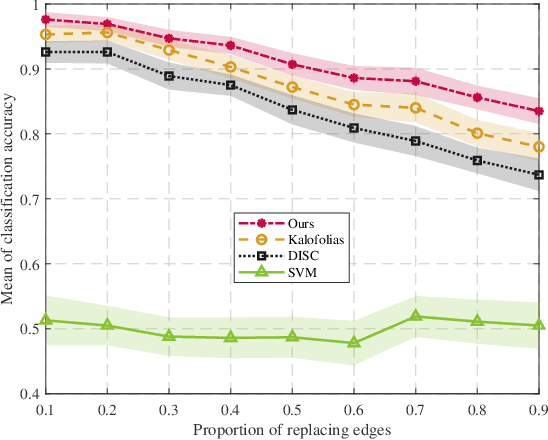
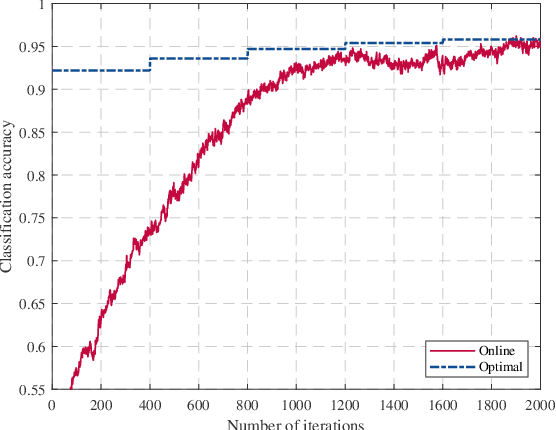
Graph signal processing (GSP) is a key tool for satisfying the growing demand for information processing over networks. However, the success of GSP in downstream learning and inference tasks is heavily dependent on the prior identification of the relational structures. Graphs are natural descriptors of the relationships between entities of complex environments. The underlying graph is not readily detectable in many cases and one has to infer the topology from the observed signals. Firstly, we address the problem of graph signal classification by proposing a novel framework for discriminative graph learning. To learn discriminative graphs, we invoke the assumption that signals belonging to each class are smooth with respect to the corresponding graph while maintaining non-smoothness with respect to the graphs corresponding to other classes. Secondly, we extend our work to tackle increasingly dynamic environments and real-time topology inference. We develop a proximal gradient (PG) method which can be adapted to situations where the data are acquired on-the-fly. Beyond discrimination, this is the first work that addresses the problem of dynamic graph learning from smooth signals where the sought network alters slowly. The validation of the proposed frameworks is comprehensively investigated using both synthetic and real data.
Triplet Entropy Loss: Improving The Generalisation of Short Speech Language Identification Systems
Dec 03, 2020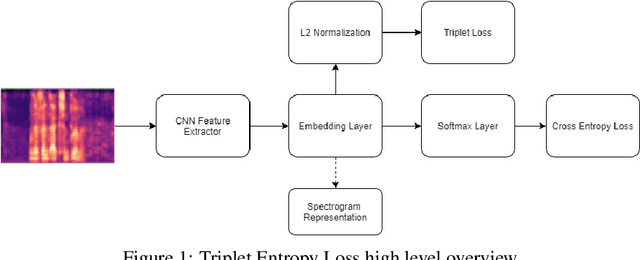
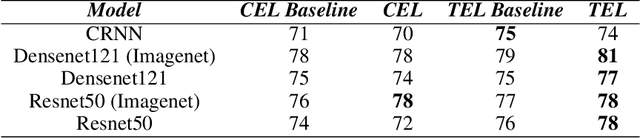
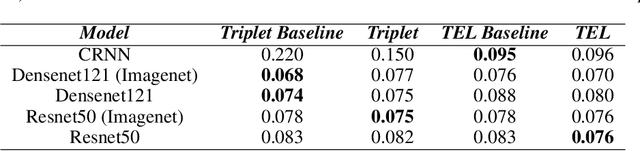
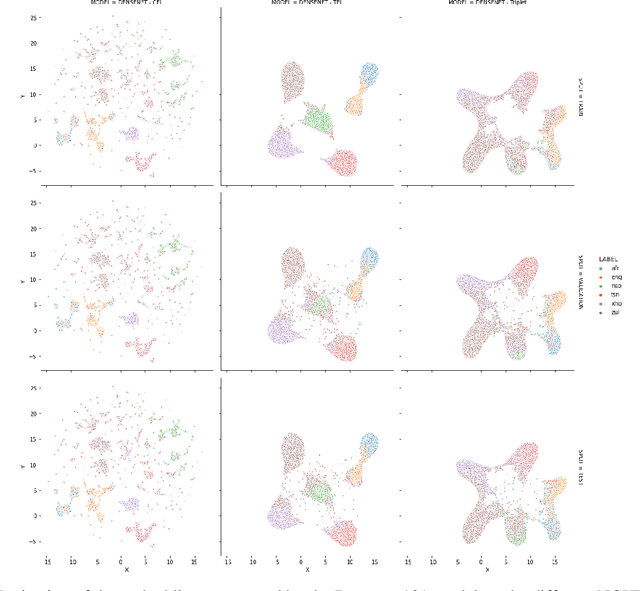
We present several methods to improve the generalisation of language identification (LID) systems to new speakers and to new domains. These methods involve Spectral augmentation, where spectrograms are masked in the frequency or time bands during training and CNN architectures that are pre-trained on the Imagenet dataset. The paper also introduces the novel Triplet Entropy Loss training method, which involves training a network simultaneously using Cross Entropy and Triplet loss. It was found that all three methods improved the generalisation of the models, though not significantly. Even though the models trained using Triplet Entropy Loss showed a better understanding of the languages and higher accuracies, it appears as though the models still memorise word patterns present in the spectrograms rather than learning the finer nuances of a language. The research shows that Triplet Entropy Loss has great potential and should be investigated further, not only in language identification tasks but any classification task.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021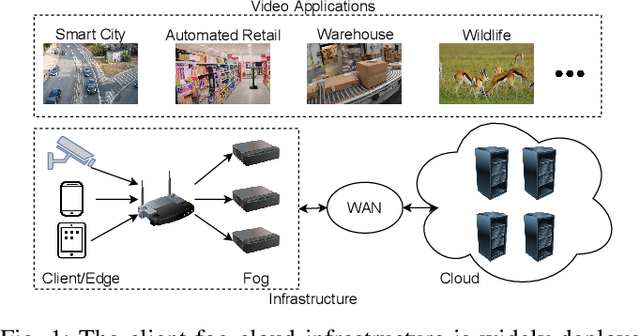
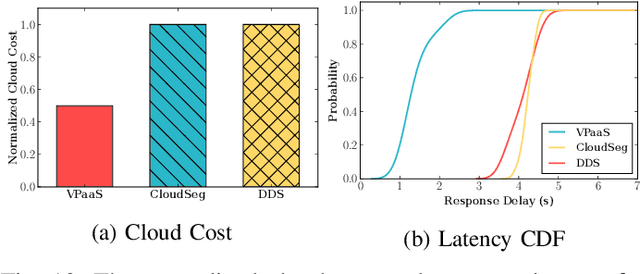
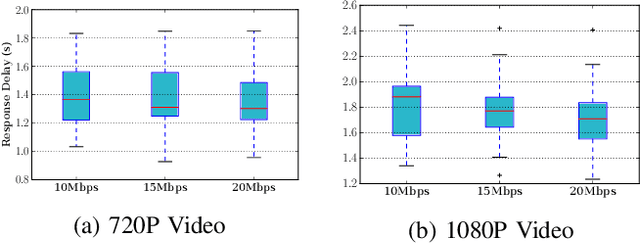
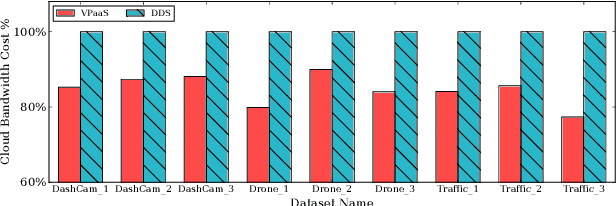
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
EGO-Planner: An ESDF-free Gradient-based Local Planner for Quadrotors
Aug 20, 2020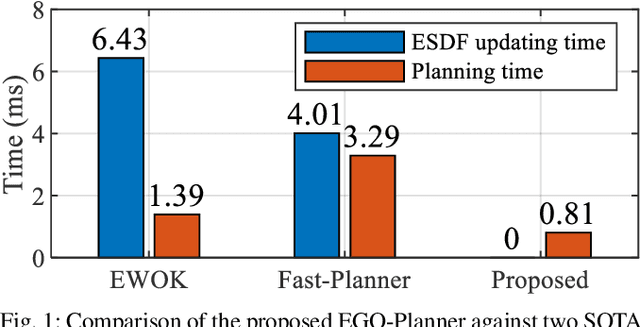


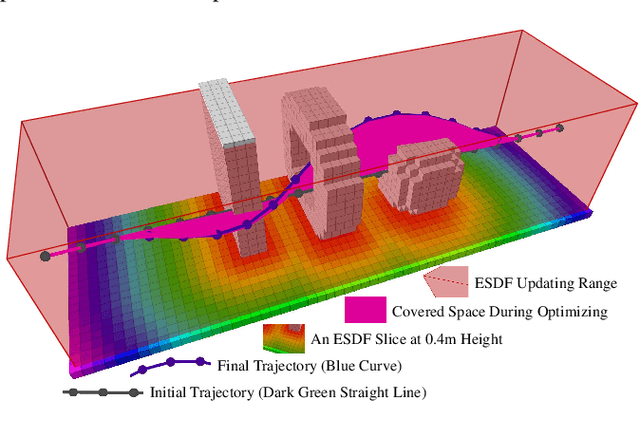
Gradient-based planners are widely used for quadrotor local planning, in which a Euclidean Signed Distance Field (ESDF) is crucial for evaluating gradient magnitude and direction. Nevertheless, computing such a field has much redundancy since the trajectory optimization procedure only covers a very limited subspace of the ESDF updating range. In this paper, an ESDF-free gradient-based planning framework is proposed, which significantly reduces computation time. The main improvement is that the collision term in penalty function is formulated by comparing the colliding trajectory with a collision-free guiding path. The resulting obstacle information will be stored only if the trajectory hits new obstacles, making the planner only extract necessary obstacle information. Then, we lengthen the time allocation if dynamical feasibility is violated. An anisotropic curve fitting algorithm is introduced to adjust higher order derivatives of the trajectory while maintaining the original shape. Benchmark comparisons and real-world experiments verify its robustness and high-performance. The source code is released as ros packages.
HDR Denoising and Deblurring by Learning Spatio-temporal Distortion Models
Dec 23, 2020
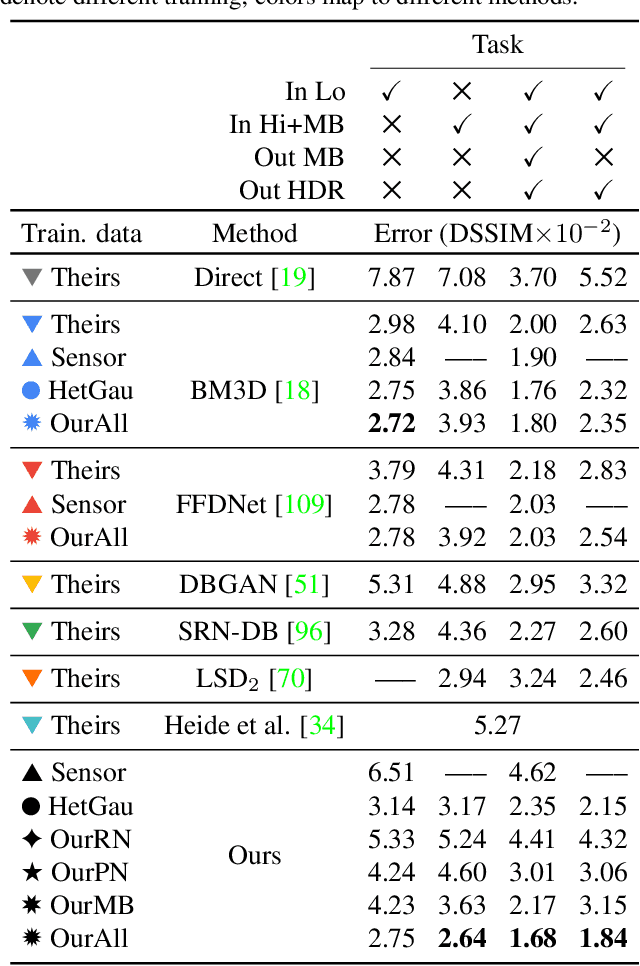
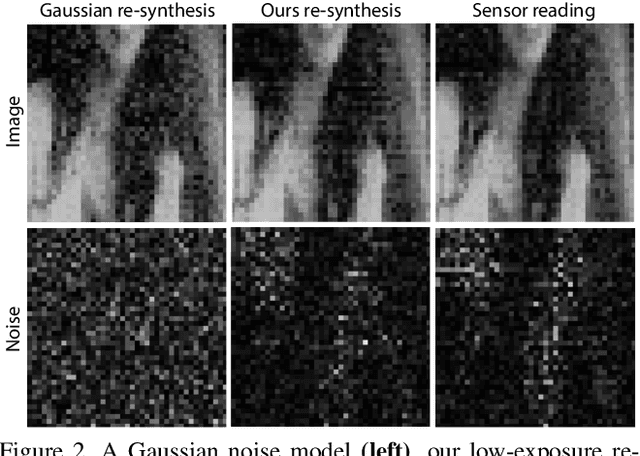
We seek to reconstruct sharp and noise-free high-dynamic range (HDR) video from a dual-exposure sensor that records different low-dynamic range (LDR) information in different pixel columns: Odd columns provide low-exposure, sharp, but noisy information; even columns complement this with less noisy, high-exposure, but motion-blurred data. Previous LDR work learns to deblur and denoise (DISTORTED->CLEAN) supervised by pairs of CLEAN and DISTORTED images. Regrettably, capturing DISTORTED sensor readings is time-consuming; as well, there is a lack of CLEAN HDR videos. We suggest a method to overcome those two limitations. First, we learn a different function instead: CLEAN->DISTORTED, which generates samples containing correlated pixel noise, and row and column noise, as well as motion blur from a low number of CLEAN sensor readings. Second, as there is not enough CLEAN HDR video available, we devise a method to learn from LDR video in-stead. Our approach compares favorably to several strong baselines, and can boost existing methods when they are re-trained on our data. Combined with spatial and temporal super-resolution, it enables applications such as re-lighting with low noise or blur.
Temporal Phenotyping using Deep Predictive Clustering of Disease Progression
Jun 15, 2020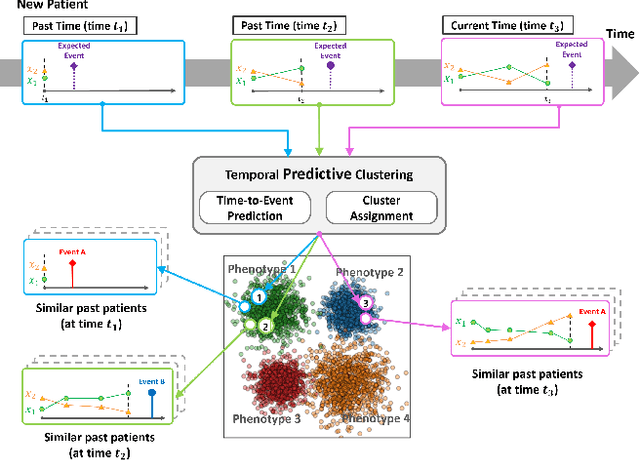
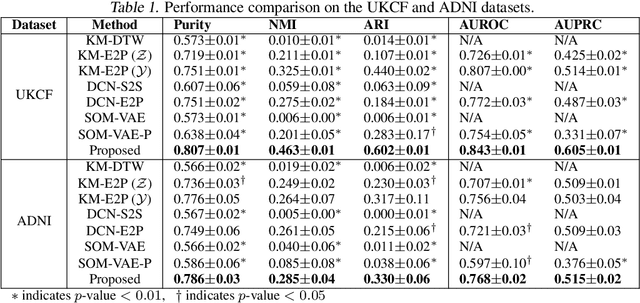
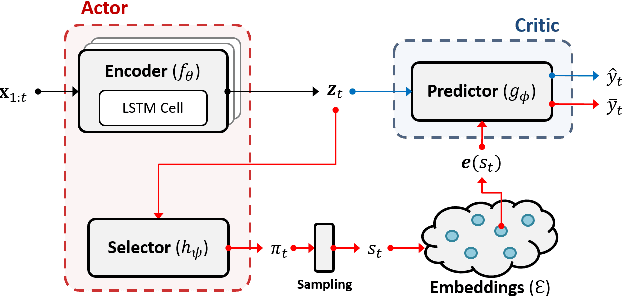
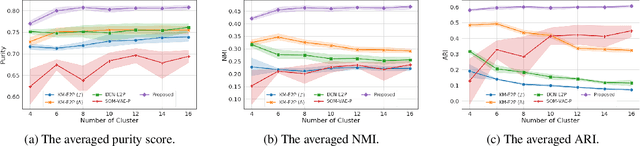
Due to the wider availability of modern electronic health records, patient care data is often being stored in the form of time-series. Clustering such time-series data is crucial for patient phenotyping, anticipating patients' prognoses by identifying "similar" patients, and designing treatment guidelines that are tailored to homogeneous patient subgroups. In this paper, we develop a deep learning approach for clustering time-series data, where each cluster comprises patients who share similar future outcomes of interest (e.g., adverse events, the onset of comorbidities). To encourage each cluster to have homogeneous future outcomes, the clustering is carried out by learning discrete representations that best describe the future outcome distribution based on novel loss functions. Experiments on two real-world datasets show that our model achieves superior clustering performance over state-of-the-art benchmarks and identifies meaningful clusters that can be translated into actionable information for clinical decision-making.
New Closed-form Joint Localization and Synchronization using Sequential TOAs in a Multi-agent System
Jan 30, 2021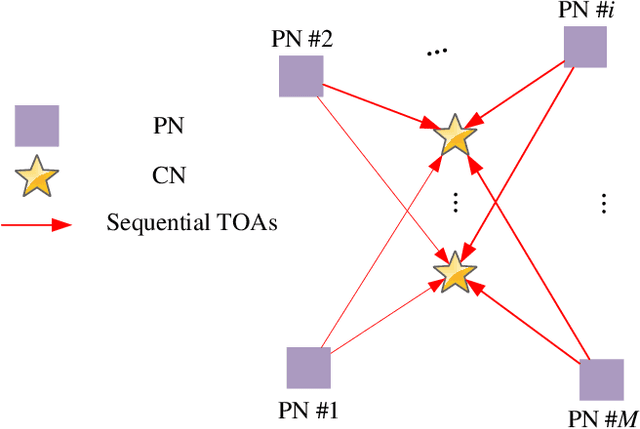
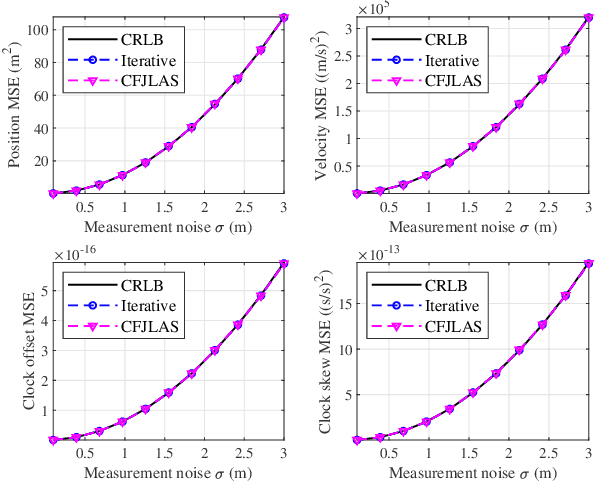
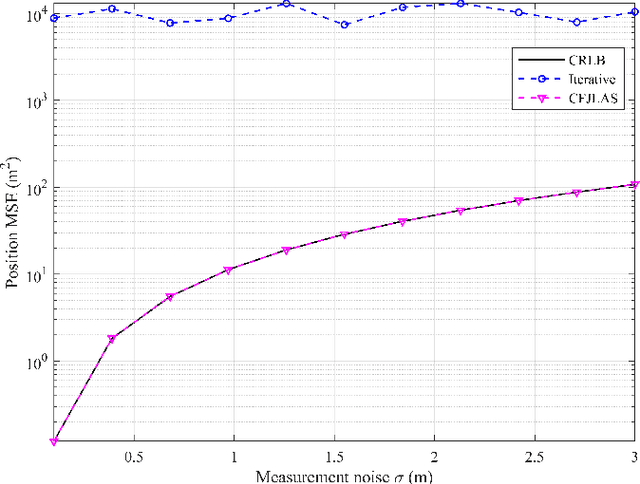
In a multi-agent system (MAS) comprised of parent nodes (PNs) and child nodes (CNs), a relative spatiotemporal coordinate is established by the PNs with known positions. It is an essential technique for the moving CNs to resolve the joint localization and synchronization (JLAS) problem in the MAS. Existing methods using sequential time-of-arrival (TOA) measurements from the PNs' broadcast signals either require a good initial guess or have high computational complexity. In this paper, we propose a new closed-form JLAS approach, namely CFJLAS, which achieves optimal solution without initialization, and has low computational complexity. We first linearize the relation between the estimated parameter and the sequential TOA measurement by squaring and differencing the TOA measurement equations. By devising two intermediate variables, we are able to simplify the problem to finding the solution of a quadratic equation set. Finally, we apply a weighted least squares (WLS) step using the residuals of all the measurements to optimize the estimation. We derive the Cramer-Rao lower bound (CRLB), analyze the estimation error, and show that the estimation accuracy of the CFJLAS reaches CRLB under small noise condition. The complexity of the CFJLAS is studied and compared with the iterative method. Simulations in the 2D scene verify that the estimation accuracy of the new CFJLAS method in position, velocity, clock offset, and clock skew all reaches CRLB. Compared with the conventional iterative method, which requires a good initial guess to converge to the correct estimation and has growing complexity with more iterations, the proposed new CFJLAS method does not require initialization, always obtains the optimal solution and has constant low computational complexity.
Curb Your Normality: On the Quality Requirements of Demand Prediction for Dynamic Public Transport
Aug 31, 2020
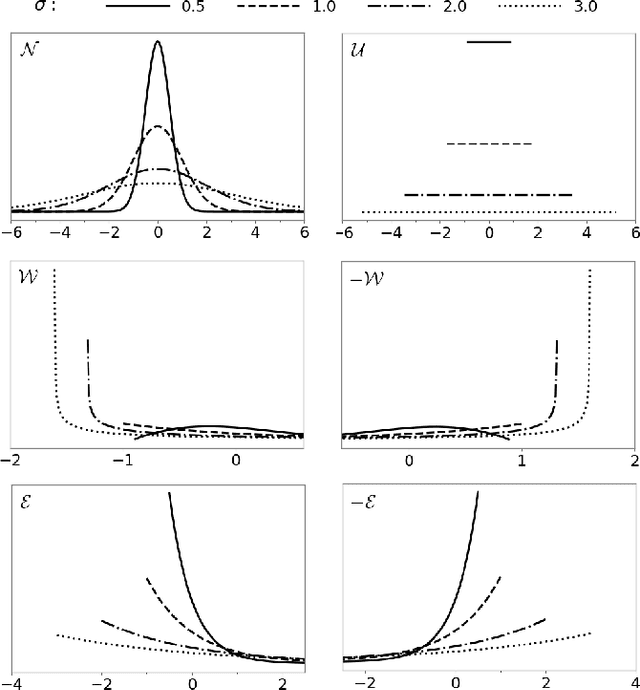
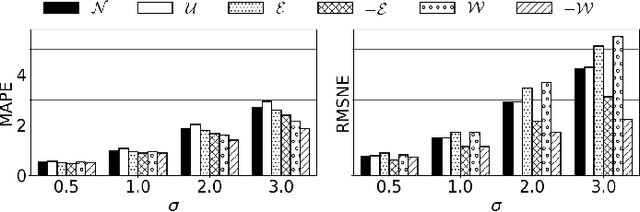
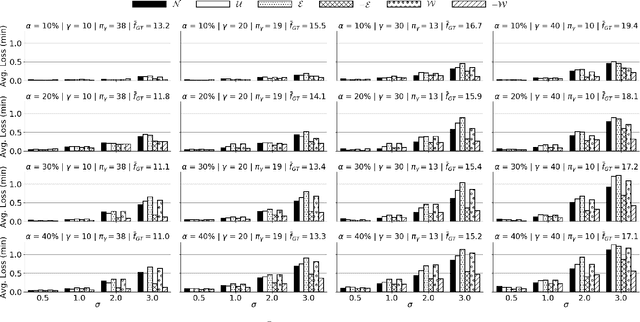
As Public Transport (PT) becomes more dynamic and demand-responsive, it increasingly depends on predictions of transport demand. But how accurate need such predictions be for effective PT operation? We address this question through an experimental case study of PT trips in Metropolitan Copenhagen, Denmark, which we conduct independently of any specific prediction models. First, we simulate errors in demand prediction through unbiased noise distributions that vary considerably in shape. Using the noisy predictions, we then simulate and optimize demand-responsive PT fleets via a commonly used linear programming formulation and measure their performance. Our results suggest that the optimized performance is mainly affected by the skew of the noise distribution and the presence of infrequently large prediction errors. In particular, the optimized performance can improve under non-Gaussian vs. Gaussian noise. We also obtain that dynamic routing can reduce trip time by at least 23% vs. static routing. This reduction is estimated at 809,000 EUR per year in terms of Value of Travel Time Savings for the case study.
Learning interaction kernels in stochastic systems of interacting particles from multiple trajectories
Jul 30, 2020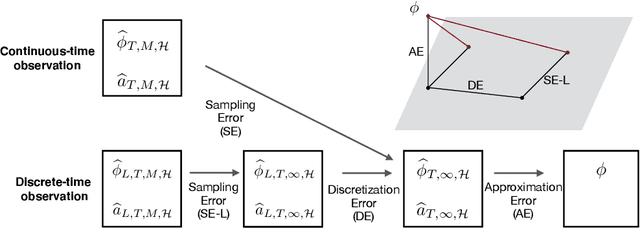
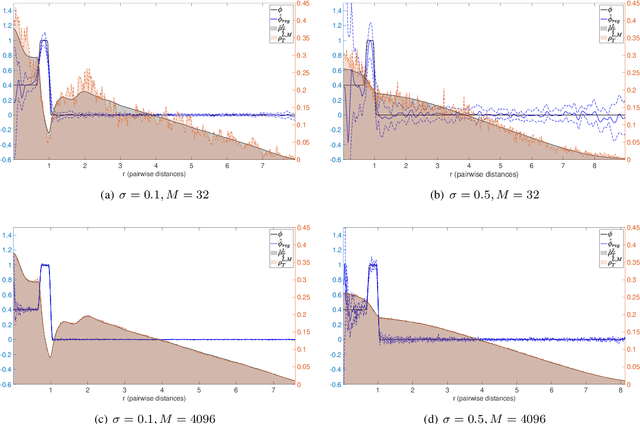

We consider stochastic systems of interacting particles or agents, with dynamics determined by an interaction kernel which only depends on pairwise distances. We study the problem of inferring this interaction kernel from observations of the positions of the particles, in either continuous or discrete time, along multiple independent trajectories. We introduce a nonparametric inference approach to this inverse problem, based on a regularized maximum likelihood estimator constrained to suitable hypothesis spaces adaptive to data. We show that a coercivity condition enables us to control the condition number of this problem and prove the consistency of our estimator, and that in fact it converges at a near-optimal learning rate, equal to the min-max rate of $1$-dimensional non-parametric regression. In particular, this rate is independent of the dimension of the state space, which is typically very high. We also analyze the discretization errors in the case of discrete-time observations, showing that it is of order $1/2$ in terms of the time gaps between observations. This term, when large, dominates the sampling error and the approximation error, preventing convergence of the estimator. Finally, we exhibit an efficient parallel algorithm to construct the estimator from data, and we demonstrate the effectiveness of our algorithm with numerical tests on prototype systems including stochastic opinion dynamics and a Lennard-Jones model.
Approximate Solutions to a Class of Reachability Games
Nov 01, 2020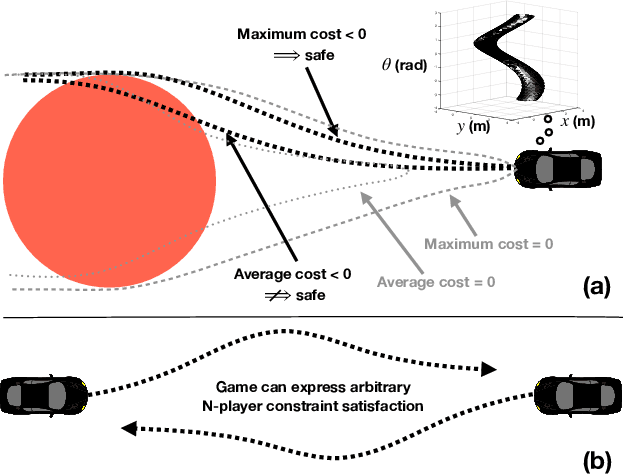
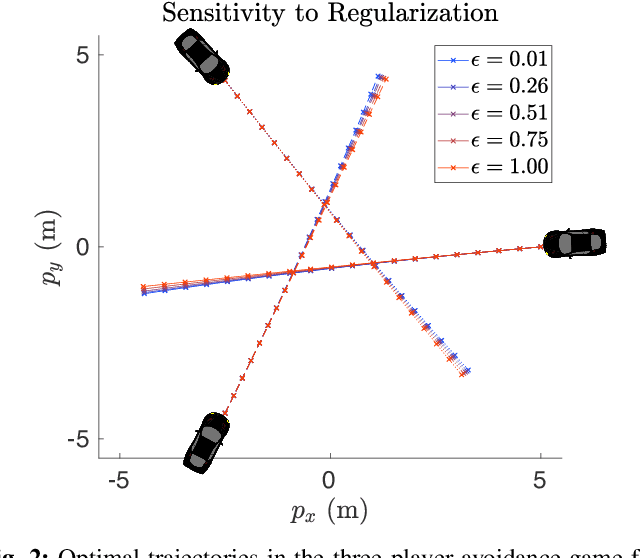
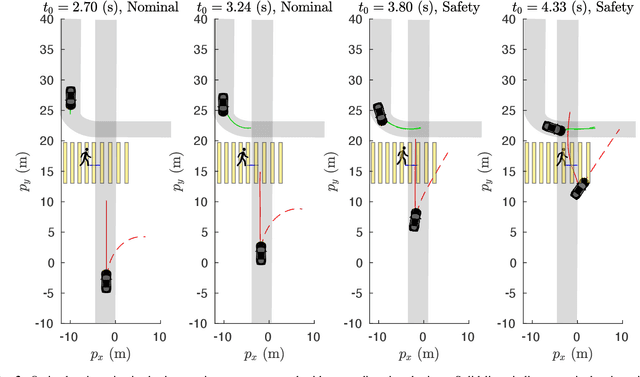
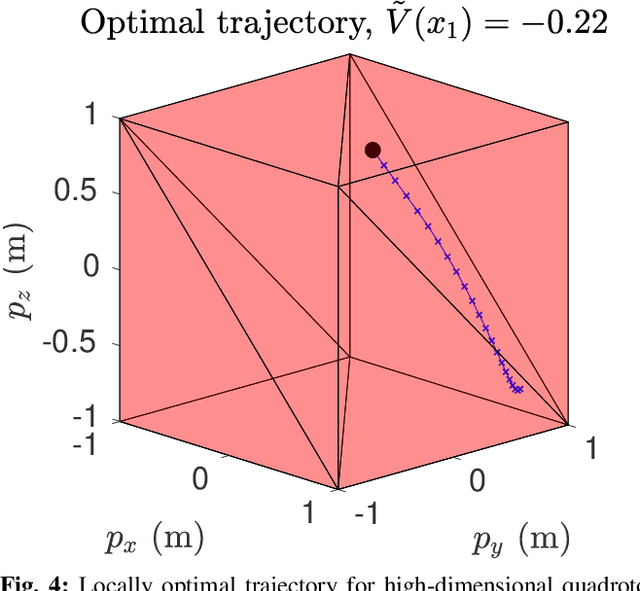
In this paper, we present a method for finding approximate Nash equilibria in a broad class of reachability games. These games are often used to formulate both collision avoidance and goal satisfaction. Our method is computationally efficient, running in real-time for scenarios involving multiple players and more than ten state dimensions. The proposed approach forms a family of increasingly exact approximations to the original game. Our results characterize the quality of these approximations and show operation in a receding horizon, minimally-invasive control context. Additionally, as a special case, our method reduces to local optimization in the single-player (optimal control) setting, for which a wide variety of efficient algorithms exist.